
引子
说到机器学习最酷的分支,非 Deep learning 和 Reinforcement learning 莫属(以下分别简称 DL 和 RL)。这两者不仅在实际应用中表现的很酷,在机器学习理论中也有不俗的表现。 DeepMind 工作人员合两者之精髓,在 Stella 模拟机上让机器自己玩了 7 个 Atari 2600 的游戏,结果是玩的冲出美洲,走向世界,超越了物种的局限。不仅战胜了其他机器人,甚至在其中 3 个游戏中超越了人类游戏专家。噢,忘记说了,Atari 2600 是 80 年代风靡美国的游戏机,当然你现在肯定不会喜欢了。长成什么样子?玩玩当下最火的 flappy bird 吧!

闲话少叙,来看看准备工作吧。首先是一台 Atari 2600,估计是研发人员从爹妈的废物处理箱中翻箱倒柜的找出来的。等会,都生锈了是怎么回事儿?电池也装不上的说!淡定……由 Stella 倾情打造了模拟机,甚至还有为学术界专门贡献的 Arcade Learning Environment,妈妈再也不用担心我的科研了。输入信息就是模拟器当前画面,输出为可供选择的摇杆和按钮“A-B-B-A- 上 - 上 - 下 - 下”,学术点说就是当前状态下合法的操作集合。目的呢,当然是赢得游戏,分数多多益善。
然后就是玩游戏了。作为很酷很酷的科学家,肯定不会亲手玩游戏咯,当然一方面也是怕老板发现。不过,想要机器玩游戏,先得想清楚人类是怎么玩游戏的:
- 首先,游戏开始,停留在初始时刻。然后,游戏场景开始变换,玩家眼睛捕捉到画面的变化,将视觉信号传递回脑皮层进行处理。
- 之后,脑皮层将视觉信号转换为游戏的语义信息,通过经验指导,将语义信息与应该进行的操作做映射,之后是将映射后得到的操作信号传递到身体,如手指动作。操作结束后,游戏场景进入下一帧,玩家得到一定的回报,如越过关隘,或者吃到金币。如此循环,直到游戏结束。
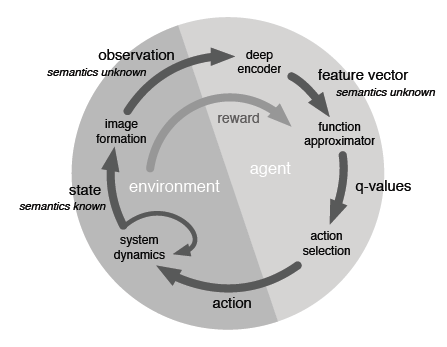
仔细想想这个过程,发生在游戏内部的那些事情是玩家所不用考虑的,玩家能够覆盖的只是上述游戏循环的右半段。即输入视觉信号,输出手指动作。而手指动作到下一帧场景,以及玩家得到回报是游戏内部的过程。
既然了解了人类玩家的操作过程,并分解出实际需要玩家的部分内容,下一步就是让机器替代人类玩家了。为了区分,通常称机器玩家为 agent。与人类玩家的操作类似,agent 需要负责:
- 由上一帧回报信号学习到玩游戏的知识,即经验(什么场景下需要什么操作)
- 视觉信号的处理与理解(降维,高层特征抽取)
- 根据经验以及高层的视觉特征,选择合理的经验(动作)
- 动作反馈到游戏,即玩家手动的部分
所以说,游戏都是越玩越好的,人类玩家如此,agent 亦如此。既然已经刻画出来操作步骤,随着 DL 和 RL 的发展,实操也不是什么难题嘛。下面,首先看看 RL 是如何促进 agent 的学习。之后会讲到 DL 是如何合理的安插到 RL 的学习框架中,并如何起到作用的。然后,会强调一下这两者在游戏 agent 操作中的难点,以及如何解决实际问题。最后,来看看 agent 游戏玩的到底如何。总结涉及对 RL 的升华。
Reinforcement Learning
RL 其实就是一个连续决策的过程。传统的机器学习中的 supervised learning 就是给定一些标注数据,这些标注作为 supervisor,学习一个好的函数,来对未知数据作出很好的决策。但是有时候你不知道标注是什么,即一开始不知道什么是“好”的结果,所以 RL 不是给定标注,而是给一个回报函数,这个回报函数决定当前状态得到什么样的结果(“好”还是“坏”)。 其数学本质是一个马尔科夫决策过程。最终的目的是决策过程中整体的回报函数期望最优。
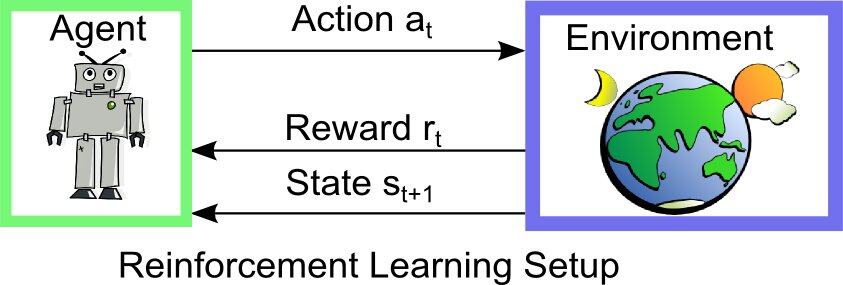
来看看一些关键元素:
- 状态集合 S:S 是一个状态集合,其中每一个元素都代表一个状态。在游戏的场景中,状态 S 就是某一时刻采集到的视觉信号。
- 动作集合 A:A 中包含所有合法操作。如 flappy bird 中点击一下屏幕,temple run 中的上下左右等指动。
- 状态转移概率 P:P 是一个概率的集合,其中每一项都表示着一个跳转的概率。例如,在当前状态 s 下,进行操作 a 转移到下一个状态的概率。
- 回报函数 R:R 是一个映射,跟状态转移概率 P 有点联系,R 说明的是,在当前状态 s 下,选择操作 a,将会得到怎样的回报。需要注意的是,这里的回报不一定是即时回报,如棋牌游戏中,棋子移动一次可能会立刻吃掉对方的棋子,也可能在好多步之后才产生作用。
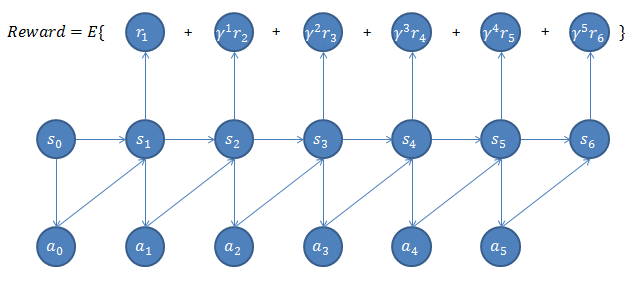
回报函数有一些小小的 tricky。
首先,RL 的过程是一种随机过程,意即整个决策的过程都是有概率特性的,每一步的选择都不是确定的,而是在一个概率分布中采样出来的结果。因此,整个回报函数是一种沿时间轴进行的时序 / 路径积分。依据贝叶斯定理,开局时刻不确定性是最大的,开局基本靠猜,或者一些现有的先验知识。随着游戏的不断进行接近终点,局势会逐渐晴朗,预测的准确性也会增高。深蓝对战国际象棋大师卡斯帕罗夫的时候,开局就是一些经典的开局场景,中局不断预测,多考虑战略优势,局势逐渐明朗,因此这时候一般会出现未结束就认输的情况。终局通常就是一些战术上的考量,如何更快的将军等。类似地,在 RL 中,回报函数的时序 / 路径积分中,每一步的回报都会乘上一个 decay 量,即回报随着游戏的进行逐渐衰减。此举也有另一些意味:如何最快的找到好的结果,例如在无人直升机中,花费最小的时间找到最优的控制策略,剩下的就是微调。
接下来,当这一切都确定了,剩下的事情就是寻找一种最优策略(policy)。所谓策略,就是状态到动作的映射。我们的目的是,找到一种最优策略,使得遵循这种策略进行的决策过程,得到的全局回报最大。所以,RL 的本质就是在这些信号下找到这个最佳策略。
众所周知动态规划,其中一条理论基石就来自 Bellman 公式。Bellman 公式告诉我们,在一种序列求解的过程中,如果一个解的路径是最优路径,那么其中的每个分片都是当前的最佳路径,即子问题的最优解合起来就是全局最优解。回报函数的最大化就服从 Bellman 公式,这是非常棒的性质,表示着我们可以不断迭代求解问题。旅行商问题就不服从 Bellman 公式,因此它是 NP-hard 问题。
于是,RL 的学习分为两个方面,两方面相互交织,最终得到结果。这是一种典型的 Expectation-Maximization 算法的过程。EM 算法在机器学习中是相当经典的算法,大量的机器学习优化都使用这个方法。
如下图所示的一种 EM 算法求解 RL 的示例:

该示例代码取自 Spark Summit 2013,由 Adobe 的 Nedim Lipka 介绍了 RL 在市场策略(网页个性化展示)上的应用。这里抛开具体的应用语义,以及分布式算法,来简单分析 RL 优化过程中 EM 算法的一般过程。
这里,是一个函数,这个函数以当前状态 s 为参数,返回一个动作 a,这个动作是一个概率分布,代表着在当前状态 s 下,转移到任意另外一个状态的概率是多少。假设我们有三个状态,那么这个动作分布可能是这个样子的:
另外,是一个价值函数,即我们从 s 这个状态出发,直到无穷大的遍历,能获得的最大回报的期望。价值函数其实就是在策略为,初始状态为 s 情况下的回报函数。另外,是一个即时(immediate)回报函数,即从状态 s 出发,经过 a 这个动作的作用,走到这个状态获得的回报是多少。例如用户在某个页面上浏览,点了一个广告,到了广告商的页面,广告商付给该网站 1 块钱。
价值函数,其中表示当前动作下面的转移概率,表示当前动作下的即时回报函数,是从 s 转移到之后,所能得到最大的期望价值。
这个函数优化有个问题,那就是和都是未知的,而这两个量是相互纠缠的,计算需要最大化,而计算需要对最好的进行积分。所以这是个典型的 Expectation-Maximization 算法。代码中第一部分就是 EM 算法中的 Expectation,第二部分就是 EM 算法的 Maximization 部分。
那么为什么第一部分会有迭代呢?那是因为大家记得随机游走,都不是游走一次就能结束的。整个转移链想达到稳定状态,需要多次迭代才可以。这就类似于 Gibbs sampling 算法,必须多次迭代才能收敛。这里也是,计算 Expectation 需要让整体的网络达到稳定状态。其中符号 delta 代表着前后两次迭代差距是否足够小,因此判断是否收敛。
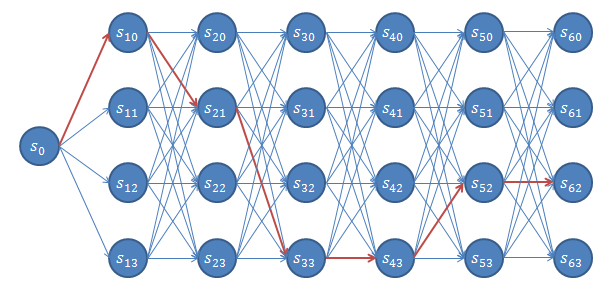
(数据的结构,数据图的网络相依,类似与随机游走)
总结一下,说白了,RL 就是一个 supervised random walk(可以参考斯坦福大学 Jure Leskovec 教授的论文 _Supervised Random Walk_)。传统的 random walk 是按照固定的转移概率随便(采样)游走,RL 就是在随机游走的每一步,都选择一个能使回报函数最大化的方向走,即选择一个当前状态下最好的 action。而 RL 游走的这个网络,是由状态 S 为点集,动作 A 为边集,状态转移概率 P 为边权重的有向无环图(DAG)。状态转移概率 P 不是不变的,而是随着 agent 在这个网络中的步进,不断变的更加正确,符合现实世界的分布。这个 DAG,就是一种混沌的网络状态。
澄清一些概念,Reward 是一次 action 得到的 payoff,Return 是一序列 reward 的函数,如 discounting sum。上述两个是目标,而下面的 value function 是要学习的函数。Value function 是状态的函数,或者是“状态 - 动作”这个序对的函数。来预测在给定状态(或者给定“状态 - 动作”)下 agent 能表现多好。有多好,表明的是在这点的 expected reward,即在这点所能看到的未来最大期望收益。Approximator,关键是泛化能力,在有限的状态 - 动作子集上获得的经验,如何扩展到全部的状态和动作上?使用动态规划这种“查找表”的方式,是有局限的,而且这个局限不仅仅是内存上的(硬件上的)。Off-policy 是指不需要一个 policy 查找表之类的,而是直接求最大化 reward 的那个 action。
Deep Learning in RL
Deep 在何处?换句话说,因为 DL 参与的 RL 与传统的 RL 有何不同,从而要引入 DL?我们在前面介绍 RL 的过程中,处理的是状态。而实际上,很多时候状态是连续的、复杂的、高维的。不像之前介绍中说的 4 个状态就可以了。实际上,假设我们有 128*128 的画面,那么状态的数目是指数级增长的,即有 2^(128*128) 中可能存在的状态,这个数字是 1.19e+4932,这可是个天文数字!游戏画面连续存在,就算按照每秒 30 帧来算,一局游戏玩下来,啥都不用干了。处理数据的速度根本跟不上游戏画面变化的速度,更不用说那些高清的游戏。实际上,DeepMind 现在也就能玩玩 Atari 这种爸爸辈的游戏吧。
无奈,因此求助于 DL。注意,在此之前有很多人工特征处理,但很明显,一旦引入了人类的活动,就无法做成一种集成性的系统了,只能成为实验室的二维画面玩具。人类为什么玩游戏玩的好呢?因为人脑非常善于处理高维数据,并飞快的从中抽取模式。现在由 DL 来替代这块短板。
DL 现在有两种经典形式,由 Hinton、LeCun 和 Yoshida 等人(原谅我不能一一列举大牛们)逐步完善。DL 作为机器学习界的明星方法,早已耳熟能详。但是兹事体大,还是稍微提一下两种经典形式吧。首先说明的是,两种形式在深层架构上很类似,但是在每层的处理上有所不用。依据多种神经网络之不同,DL 分类如下:
- 第一个差别就是单层网络的不同,分为 Auto-encoder 和 Restricted Boltzmann Machine;
- 第二就是深层架构之不同,如何安排深层架构,是直接堆叠,还是通过卷积神经网络?
- 第三就是最高两层分类 / 识别层的不同安排,不同的高两层安排代表了不同的学习形式,是生成模型,还是判别模型?
- 第四是不同的激活函数选择,常见的是 sigmoid 函数,但也有通过 Rectified Linear Unit 增强学习能力的,甚至还有 convex 函数的选择,如 DSN。
所谓 Q-learning
初始化的时候需要设置 DL 与 RL 的起始参数,例如 episode(其表述一种天然存在分割的序列,如玩游戏,总会遇到终局。一个 episode 就是这样一个天然的分割。)设置为零,初始化策略,以及初始化空的 replay memory。
之后就是在一个个 episode 中进行探索。简单来讲,就是累计 4 帧游戏画面,经过些许预处理(裁剪、白化)之后,算作当前状态。之后根据现有的策略,选择一个最大化全局回报动作。在 ALE 模拟器中执行这个动作,收获下面 4 帧画面,以及此次回报。并将本次探索的结果存入 replay memory。
接下来就是进行新的策略(模型)学习。首先从 replay memory 中采样几组探索结果,分别根据一阶的 Bellman 公式求解理论回报值,最为标注信息。之后使用标注信息来优化 CNN,通过 SGD 进行优化。
要明确的是,不同的 episode 之间有哪些变量是共用的呢?有哪些是新 eposide 中置零,重新开始的呢?很显然,function approximator,即我们的神经网络是维持不变的,因为 CNN 在这里出现的本意就是随着样本数目、迭代数目不断增加,优化的越来越好。剩下的,replay memory 也是不变的,因为 replay memory 算是一个资源池,也就是传统意义上的数据。数据收集越来越多,但是不会丢弃。至于其他的,像学到的 policy,以及 reward 等都是要重新开始的。
以上介绍的过程就是 Q-learning 的一般过程。通常来说,Q-learning 是 model-free 的,什么意思呢?就是说使用 Q-learning 的 RL 过程在计算 value function(即 Q-function)的时候,不需要和环境进行交互。而上文中提到的动态规划方法,是需要跟环境交互才能计算最优回报的。通过使用一个称作 Q-function 的函数,可以完全避免计算最优回报的时候和环境交互。这个 Q-function 通常又被称作 function approximator.

细数挑战
很多问题都是看起来简单,实操过程中困难重重,因此,做任何事情都要“in the wild”,否则只是在外围打转,没有深度,因此词句缺乏力量,从而写不出有力的篇章。(作者躺枪)
首先是如何将整个过程构成闭环,在实时的游戏中进行持续学习和决策。可以肯定的是,一般情况下,游戏进行画面计算的时间是相当短的,然而 DL 编码出特征,并用 RL 找出策略这个过程要长的多。因此,游戏运行的每一帧都要停下来看看 agent 算完了没有。如果这是一个流处理系统,那么整套系统的性能就被压死在这里。在实验环境中,我们当然可以容忍 agent 慢慢玩,但是这样是无法与人类玩家力拼的。DeepMind 的科学家们也没给出太好的解决方案,只是设置了一个 k 值,意即每出 k 帧动画才判决一次。细想一下会出很多问题,如 agent 在这 k 帧就不幸挂掉了,负分滚粗。这点还是期待更佳性能,或者更轻量的解决方案。正所谓,性能性需求不如功能性需求优先,但是,当性能性需求在这种情况下变成了一种功能性需求,那就必须解决了。
相比于有监督学习,RL 的另一大挑战是没有大量标注数据。首先要澄清一点,就是 DL 在前面的 pre-train 的过程中不需要标注数据,不代表整个 DL 过程中不需要标注数据。恰恰相反的是,只要有充分的标注数据,DL 是可以抛开前面的 pre-train 而直接计算的。RL 每一次计算的时候是不知道一个具体的 label 来表明对错的,只能得到一个叫做标量回报的信号,这个信号通常都是稀疏的,有噪声的,尤其重要的一点,是有延迟的。延迟,表明的是当前动作和回报之间的延迟,游戏得分可能依赖于之前所有的状态和动作,而一个动作所得到的反馈很可能到数千步之后才能展现出来(如围棋,这也是战略性游戏和战术性游戏的差别)。可以在本文游戏结果一节中看到,对于战略性游戏,agent 表现还是非常差的。
还有一个问题是机器学习算法都是有数据分布独立性的假设的,IID 是一个很重要的性质,如果数据之间是有关联的,那么计算出来的模型就是有偏向的。但是 RL 中的数据通常是一个前后严重相依的序列。并且随着 policy 的学习,数据分布倾向于不同,严重影响回归器的使用。可想而知,当前情况下的状态会影响下一次的动作选择,而下一次动作选择的不同会影响下一帧画面,下一帧画面又会影响下下次动作的选择。犹如一个长长的链条,让状态和动作纠缠不清。怎么破 IID 的问题?DeepMind 学习 Long-Ji Lin 93 年用来控制机器人运动的大作,通过使用 replay memory,存储过去一段时间内的“状态 - 动作 - 新状态 - 回报”序列,并进行随机采样以打破依赖,以及用过去的动作做平滑。
历史局限性也严重制约这 agent 的能力,局限性嘛,就是眼光看不到未来,正如当年葡王拒绝了当地人哥伦布的远航,而西班牙女王伊莎贝拉则是拿出自己的首饰珠宝让哥伦布出海。这里的历时局限性是指在当前阶段只能看到游戏的一部分画面,无法掌控全局。从而产生一个更严重的问题,就是富者更富的马太效应难以调和,agent 选择的动作会偏向一定的画面,而这种画面会使得 agent 在这个偏向上持续增强。例如,当前时刻最大化回报的操作是向左移动,因此 agent 选择向左移动,所以左侧的画面会被更多的看到,左侧画面占据大量的训练样本席位,从而控制进一步的学习。这种情况下,强烈的正反馈的循环会让 agent 迅速陷入局部最优值,甚至直接发散开。(John 和 Benjamin 在 97 年的 automatic control 上对此有所论述。)通过 replay memory 会让更多的历史样本参与训练,从而冲淡马太效应带来的影响。
最后是 Bellman 公式的局限性。根据前文叙述的 RL 用法,我们可以很 happy 的看到求解未来的回报是一个可以动态规划的过程,因此 Bellman 公式大杀四方,可以快速得到最大未来回报的结果。可惜的是,这种计算看似很好的解决问题,实则不然。这种情况下预测只针对当前最优路径这一单条路径的情况进行计算,不具备泛化能力。比如对当前数据做个分类器,可以轻轻松松达到 100% 的正确性,但是这个 100% 的分类器用在其他数据上甚至不如随机分类的结果。这种情况的解决办法是,使用一个自定义的 function 来模拟这个最大回报。这里的函数就可以任意选择了,例如有些人选用简单的线型函数,有些人则选用更加复杂的函数,如这里使用的卷积神经网络。之前的做法是,给我当前的策略、 状态,以及动作的选择作为输入,通过动态规划计算出未来的回报。现在则是给定这些输入,直接输送到神经网络中计算出未来的回报。
致命一击
游戏准备
DeepMind 工作人员最终用这个 DRL 玩了 7 个 Atari 游戏,分别是激光骑士(Beam Rider),打砖块(Breakout),摩托大战(Enduro),乓(Pong),波特 Q 精灵(Q*bert),深海游弋(Seaquest),太空侵略者(Space Invaders)。玩这些游戏的过程中呢,用的网络深层架构、学习算法,甚至是超参设置都是完全一样的,这充分说明了该方法的有效性,以及泛化能力。(当然,也说明了 DeepMind 的小伙伴们懒得去调一手好参。)当然,有一点肯定是把不同的游戏修改了的,那就是得分。不同的游戏得分、算分的情况很不相同,导致处理起来很麻烦。因此,玩游戏的过程中,每得到一个正分就加一,得到一个负分(滚粗)就给个减一。通过这种做法让不同的游戏都融合在一个框架内,不会因为奇怪的得分、给分方法导致出现计算上的困难。
注意我们的 Arcade Learning Environment 模拟器,跟 agent 配合起来会有一些问题,因为 ALE 把游戏画面一帧一帧计算出来很快,超过了 agent 的计算判决时间,所以导致游戏玩起来一卡一卡的(这点不像棋牌类游戏,可以给出思考时间),因为设置 ALE 出 k 帧才让 agent 判决一次,这样才能保证玩起来不是那么的卡。在本组实验中,k 通常设置为 4。
传统的有监督学习过程中,评测是简单确定的,给定了测试集,就可以对现有模型给出一个评价。然而,RL 的评测是很困难的。最自然的评测莫过于计算游戏的结果,或者几次游戏结果的均值,甚至是训练过程中周期性的分数统计。但是,这种做法会有很大的噪声,因为策略上权重的微小扰动可能造成策略扫过的状态大不相同(回顾一下,状态来自游戏画面,不同的动作选择会导致下一帧画面的变化,这个效应累计起来变化是巨大的。)。因此,DeepMind 选择了更加稳定的评价策略,即直接使用动作的价值函数,累加每一步操作 agent 可以得到的折扣回报。
实际操练
首先一些预处理是必不可少的,虽然论文本身标榜基本无预处理。但是显然,DeepMind 的玩家们更倾向于直接使用现成的 Deep Neural Network(Hinton 2012 年做 ImageNet 分类用到的卷积神经网络,并使用了 GPU 加速),而不是自己从头开始。正所谓“做像罗马人做的事一样的事情”,为了直接使用“罗马人”开发的 DL,首先做的是降维处理,将 RGB 三色图变换成灰度图,其次是做了一些裁剪,将原图像由 210×160 采样成 110×84 的图像,并最终裁剪成 84×84 的图像。最终是每 4 帧图像合在一起当作一次训练的样本。
网络架构方面,输入是 84×84×4 的像素,第一层神经元是 16 个 8×8 的过滤器,第二层是 32 个 4×4 的过滤器,最后一层是与 256 个 rectifier 单元的全连接,输出层是与单一输出与下层的全连接的线性函数。DeepMind 称这种与 RL 结合使用的卷积神经网络为 Deep Q-Network.

对照最左侧的 Q-value 评价曲线,与右侧“深海巡弋”相对照。点 A 时刻有一个敌军出现在屏幕最左侧,此时 Q-value 升高,B 点时刻升高到峰值,因为我们发射的鱼雷就要击中敌军。击溃敌军潜艇之后,Q-value 降低。说明 DeepMind 的 DRL 是可以感知图片语义的。
最终的评测对象中包含了 Sarsa 算法,Contingency 算法,本算法,以及人类专家。前两个算法都使用了人工合成的 features。人类玩家的结果是玩每个游戏两小时之后取得所有成成绩的中位数。最终对比结果显示,首先是本算法远胜于所有人工合成 features 的方法,其次是本方法还在打砖块、摩托大战和乓上得分超过人类玩家,在激光骑士上能跟人类玩家比部落下风。但是本算法在波特 Q 精灵、深海游弋和太空侵略者三个游戏上还离人类专家相去甚远。因为这三个游戏比另外的游戏需要更多的深思熟虑,即策略链条上的每一次抉择都可能会对长时间后的结果造成影响,而前三个游戏前后之间关联度小,前面操作造成的影响不易传播到后面的策略中,因此效果会更好。
飞翔吧,小鸟!
由 DRL 看世界
“看看你自己的生活,你的职业选择、你与配偶的邂逅、你被迫离开故土、你面临的背叛、你突然的致富或潦倒,这些事有多少是按照计划发生的?”正如塔勒布在《黑天鹅》中提到的,世界是随机的。纳特•西尔弗也保持这种观点:预测一直都不是简单的问题。复杂动力系统的预测困难来自三个方面,一是微观结构的易变性,稀疏性导致缺少显著的统计特征;二是复杂动力系统的混沌性,简单的微扰会带来巨大的变化;三是人类行为的因变性,导致数据分布改变影响预测模型。而不同的目的导向也导致了不同的不同的预测结果。除了天气预报,鲜见较准确的预测系统。
只不过此随机并非完全随机的,而是某种程度上可预测的随机。因为依据状态的不同,动作的选择并不是一个均匀分布。所谓一花一世界,一叶一菩提,RL 正如现实世界的一个缩影。正是由于 RL 和 DL 对世界和人类高度的拟真性,笔者才感觉这俩是机器学习中最有趣的部分。苏格拉底说“认识你自己”,尼采也有言“离每个人最远的,就是他自己”,RL 和 DL 像两位不懈的巨人,在人类认识自我,认识环境的道路上渐行渐远。
笔者一直对随机过程保持敬畏之心。当然原因之一也是笔者曾差点“随机过程随机过”,但是,抛开那些“只是更善于阐述而已,甚至只是更善于用复杂的数学模型把你弄晕而已”的故弄玄虚,随机过程支撑整个世界,贝叶斯点睛你的生活。
结构之美
一篇 DRL 引出了三种结构,这些结构都是美不胜收的。分别是“模型的结构”“数据的结构”以及“模型和数据的结构”。要注意的是,这里都只是画出了结构的一部分,还有其他大块的部分没体现在图中。
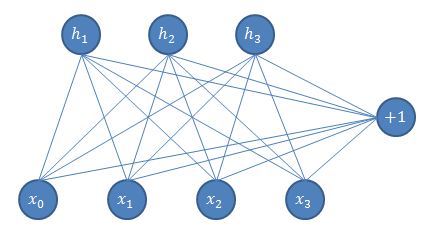
(模型的结构,图为 DL 中的受限波尔特兹曼自动机)
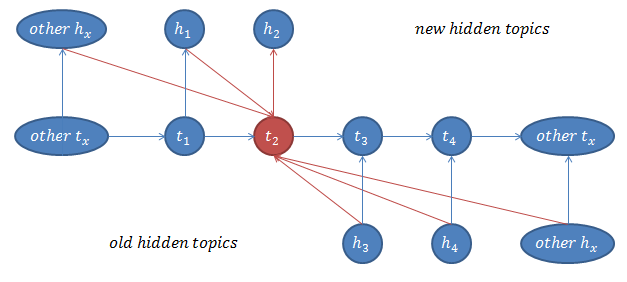
(模型和数据的结构,Gibbs sampling 的网络相依,节点为隐含变量和观测变量)
参考文献
- Playing Atari with Deep Reinforcement Learning
- Residual Algorithms: Reinforcement Learning with Function Approximation
- Bayesian Learning of Recursively Factored Environments
- The Arcade Learning Environment: An Evaluation Platform for General Agents
- CS229 Lecture notes: Reinforcement Learning and Control
- Rectified Linear Units Improve Restricted Boltzmann Machines
- An Analysis of Temporal-Difference Learning with Function Approximation
- Deep Auto-Encoder Neural Networks in Reinforcement Learning
- On optimization methods for deep learning
- Technical Note: Q-Learning
- Towards Distributed Reinforcement Learning for Digital Marketing with Spark
作者简介
尹绪森,Intel 实习生,熟悉并热爱机器学习相关内容,对自然语言处理、推荐系统等有所涉猎。目前致力于机器学习算法并行、凸优化层面的算法优化问题,以及大数据平台性能调优。对 Spark、Mahout、GraphLab 等开源项目有所尝试和理解,并希望从优化层向下,系统层向上对并行算法及平台做出贡献。
感谢吴甘沙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论