
导读: 如今,在电子商务、物联网等领域,推荐系统扮演着越来越重要的地位。如何根据用户的历史行为和项目的特征信息,判断用户对商品是否感兴趣成了重要的研究问题之一。日前,第四范式提出了全新的深度神经网络表数据分类模型——深度稀疏网络 ( Deep Sparse Network,又名 NON ),被机器学习顶会 SIGIR 2020 收录。本次分享将带你全面了解 NON 模型的提出动机、整体结构、局部特点以及突出贡献。
01 背景介绍
首先对推荐系统和深度学习进行简单的介绍。什么是推荐系统?什么是深度学习?
1. Recommendation system ( 推荐系统 )
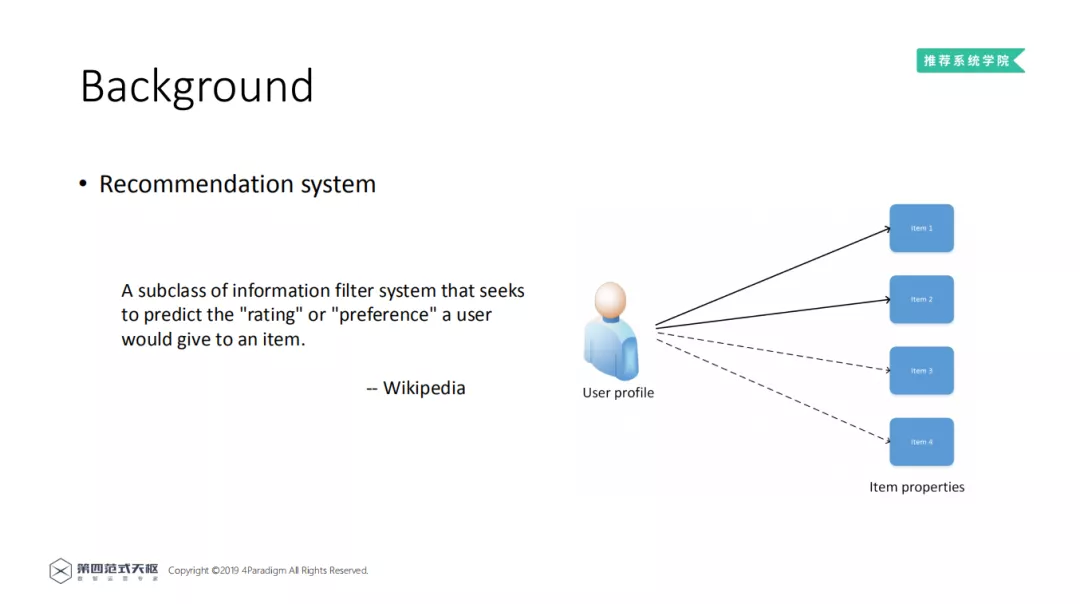
维基百科给出对于推荐系统的定义:推荐系统是一个过滤系统,推荐系统的目标是预测用户对给定物品的评分或者喜好度,然后根据评分或者喜好度推荐给用户对应的物品。
以右图为例,通过 user profile 和 item properties,预测用户对 item1-4 的打分,预测用户的最后选择 item 1 和 item 2,然后推荐给用户。在现实生活中的应用, 不同的应用软件会向用户推荐商品、电影、书籍、视频等。
2. Deep Learning ( 深度学习 )
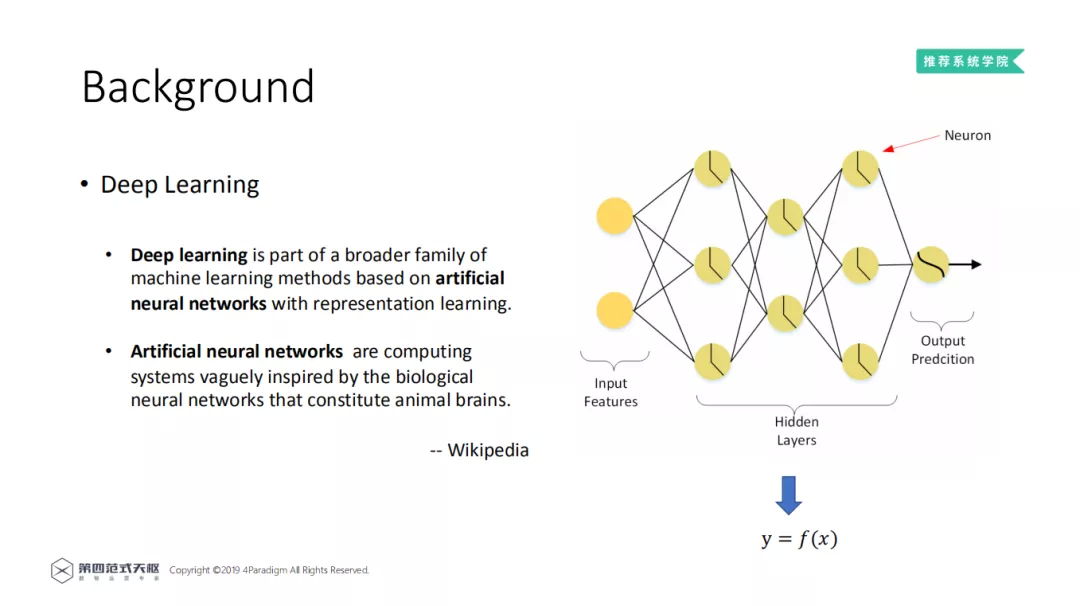
维基百科对深度学习的介绍:
深度学习是机器学习的分支,一种基于人工神经网络的表征学习方法;
神经网络是受到生物神经网络的启发,从而构建的计算系统。
一个简单的神经网络分为三个部分: 输入特征,隐藏层,预测层 。对于全连接的神经网络结构,每一层的神经元都是以前一层所有的输出作为输入。然后每个神经元都有一个非线性的函数,对输出值做一个非线性的变化。有一种说法,只要神经网络的层数够深,它就能拟合或者逼近任何一种函数。这种说法表达了神经网络强大的表征能力,也说明了神经网络主要功能之一,即学习输入到输出的函数变换。
02 相关工作
可以将推荐系统分为以下四类,简单介绍基于内容的推荐算法、基于协同过滤的推荐算法、混合推荐算法,重点介绍基于模型的推荐算法。在介绍基于模型的推荐时,先给出了一些浅层的推荐算法,之后介绍了一些基于深度学习的推荐算法。
Contented based:
基于内容的推荐算法。主要根据用户的浏览记录,或者购买记录,向用户推荐与其浏览记录或者购买记录相似的物品。
Collaborative Filter:
基于协同过滤的推荐算法。主要根据拥有相同经验或者相同群体的喜好,为用户推荐感兴趣的资讯或者物品。例如用户 A 和用户 B 相似,就可以把用户 B 喜欢的物品推荐给用户 A。协同过滤算法还可以分为基于用户的协同算法和基于物品的协同算法。
Hybrid:
混合推荐算法,将不同的算法混合使用。可以在不同阶段使用不同的推荐算法,也可以对多个推荐算法进行不同的处理,然后将多个推荐算法的结果耦合,将最终结果推荐给用户。
Model Based:
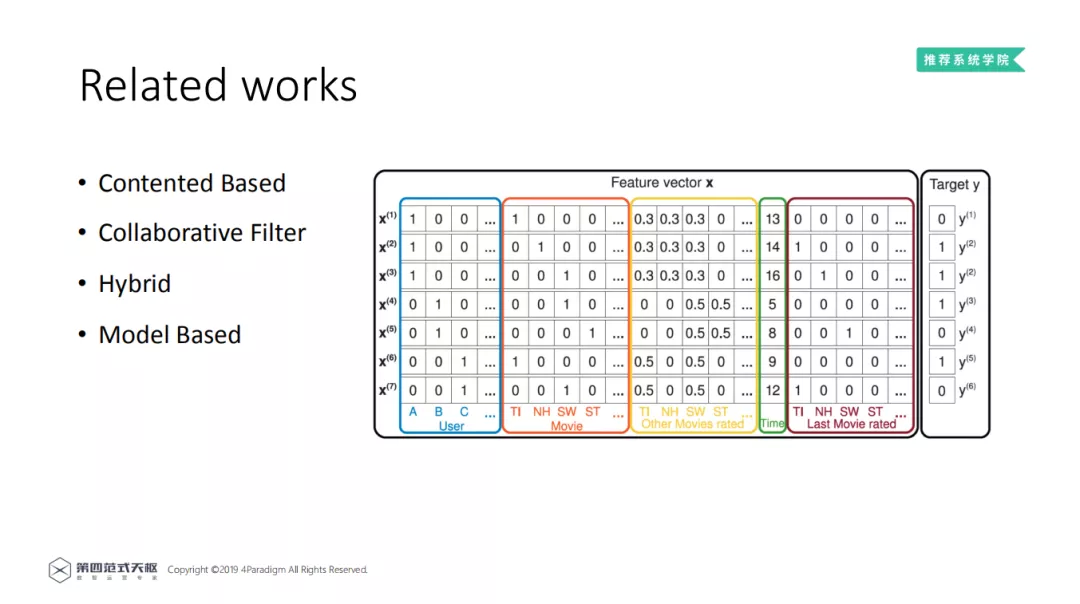
基于模型的推荐算法。将用户的 profile 和物品的 properties 作为特征,用机器学习模型,来预测用户对物品的喜好程度。在推荐系统中,经常会用到点击率 ( CTR ) 来表示喜好程度。点击率表示用户点击物品的概率,点击率越高说明用户对该物品的喜好程度越高。
在上图中给出了一个例子,表示用户对电影的点击率。其中每一行是一个样本,每一列是不同的特征,表示用户的属性,电影的特征,以及用户的一些历史行为记录。在每一条样本中,0 表示用户没有点击对应的 movie,1 表示点击对应电影。那么此时问题已经转化为二分类问题。
接下来介绍下基于模型的常见方法:
1. 浅层的基于模型的方法

首先,是一些比较浅层的推荐方法,例如 LR、FM、FFM 等。逻辑回归算法 ( Logistic Regression,LR ) 是推荐系统的常用方法之一。将用户的浏览记录和项目的信息、离散特征,通过 one-hot 编码;将数值类特征归一化,或者通过分桶技术,进行离散化;然后通过 LR 模型进行训练。LR 模型很稳定, 但是缺乏学习高阶特征的能力,尤其是特征间的交互。而 FM 模型和 FFM 模型则将高度的离散特征通过 embedding,转化为低维的稠密向量。然后用稠密向量的内积表示特征之间的交互特征。
上图展示了 embedding 的过程,Categorical Field xi是高维稀疏离散特征,通过 one-hot 表示,只有一元为 1,其他都是 0。因为 xi的 one-hot 表示只有一元为 1,通过矩阵乘法,取出 Wi矩阵的 xi列,得到对应低维的稠密向量。LR、FM 和 FFM 三种模型取得了较好的效果,但由于它们的结构较浅,其表达能力也受到了限制。
2. 基于深度学习的方法

基于深度学习的推荐方法,以其中两个典型的模型为例:DNN 模型和 Wide&Deep 模型。
DNN 模型。DNN 方法使用了 Embedding 技术,将离散和数值特征 Embedding 到低维的稠密向量。然后和将稠密向量和数值特征拼接,作为 DNN 的输入,然后直接预测输出。
Wide&Deep 模型。Wide&Deep 方法,对比 DNN 方法。增加了 Wide 的部分,即专家手工设计的高阶特征。然后把高阶特征和 DNN 学到的特征拼接,作为模型的输入,预测最终的点击率。
其他深度学习的方法借鉴了 Wide&Deep 的模式。例如,在 DeepFM 模型中,将专家手工设计的部分 ( Wide 部分 ) 替换成了 FM;在 xDeepFM 模型中, 将 Wide 部分替换成了 CNN;在 AutoInt 模型中,将 Wide 部分替换成 self-attention 的网络。
在推荐系统中还有一类方法,基于用户的兴趣, 使用了用户的历史行为数据,例如 DIN、DSIN,但是这类方法不在本次讨论范围之内。
3. 上述方法存在的问题

首先,现有方法直接融合不同特征域的向量表示,而未显式地考虑域内信息。我们将"每个特征域内的不同特征值,均属于同一个特征域"记为域内信息。对于每个特征域中的特征,它们的内在属性是都属于同一个特征域。以在线广告场景为例,假设特征域 “advertiser_id” 和 “user_id” 分别表示广告商和用户的 ID,则特征域 “advertiser_id” ( “user_id” ) 中的不同的广告商 ID ( 用户 ID ) 都属于广告商 ( 用户 ) 这个特征域。此外,特征域有自己的含义,如 “advertiser_id” 和 “user_id” 分别代表广告主和用户,而不管域内特征的具体取值。
其次,大多数现有方法使用预定义的特征域交互操作组合 ( 如 DNN、FM ),而未考虑输入数据。事实上,预定义的操作组合并不适用于所有的数据,而是应该根据数据选择不同的操作,以获得更好的分类效果。如上图所示:
Wide&Deep 中的 Operations 使用了 Linear 和 DNN;
DeepFM 使用了 FM 和 DNN;
xDeepFM 使用了 CIN、Linear 和 DNN;
AutoInt 中使用了 self-attention 和 DNN。
同时他们在预测时,都是将不同的结果通过线性求和关联起来,没有考虑非线性的关系,即现有方法忽略了特征域交互操作 ( 如 DNN 和 FM ) 的输出之间的非线性。
03 NON 模型详细讲解
接下来为大家全面介绍 Network on Network。
1. NON 模型整体结构
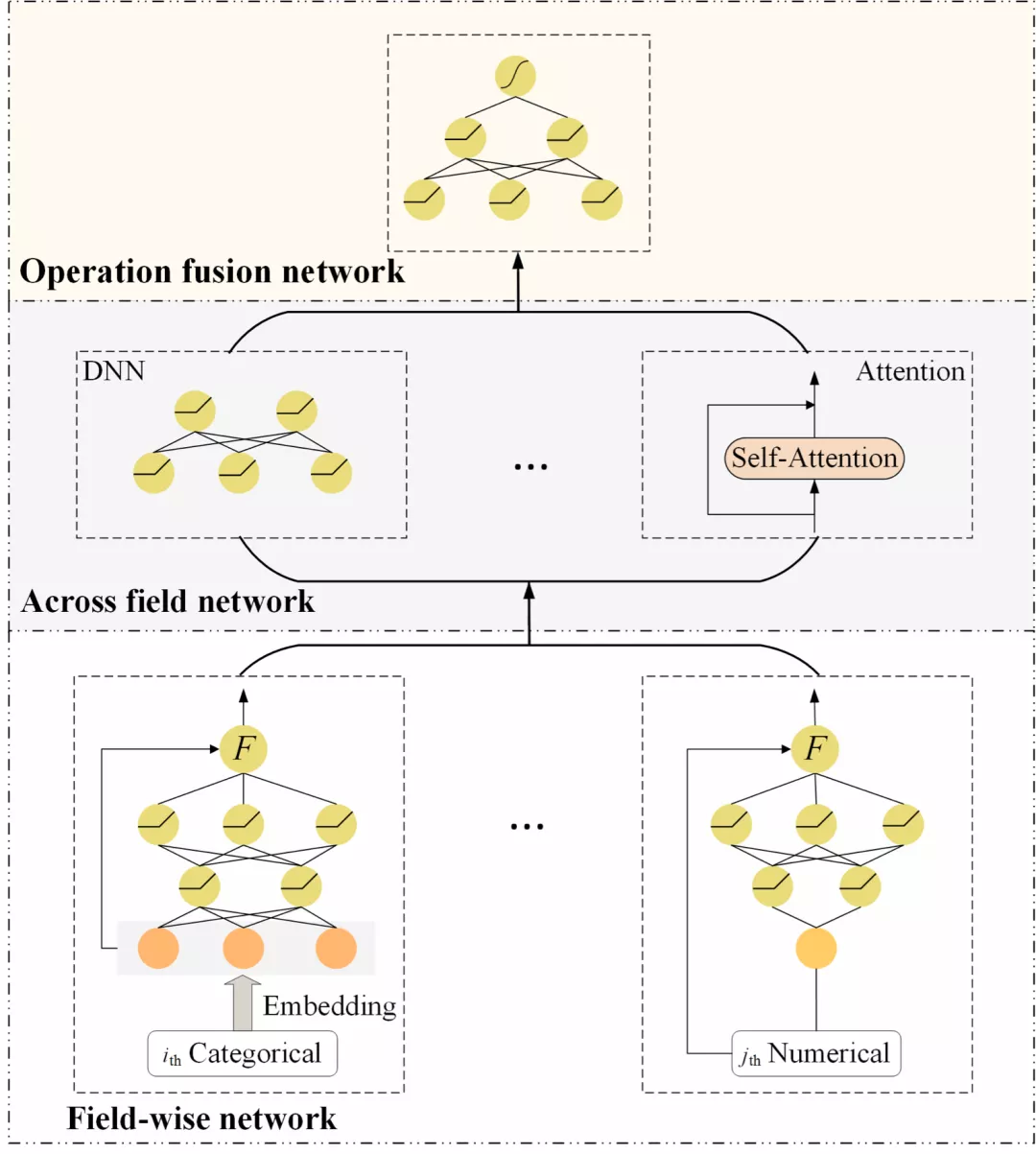
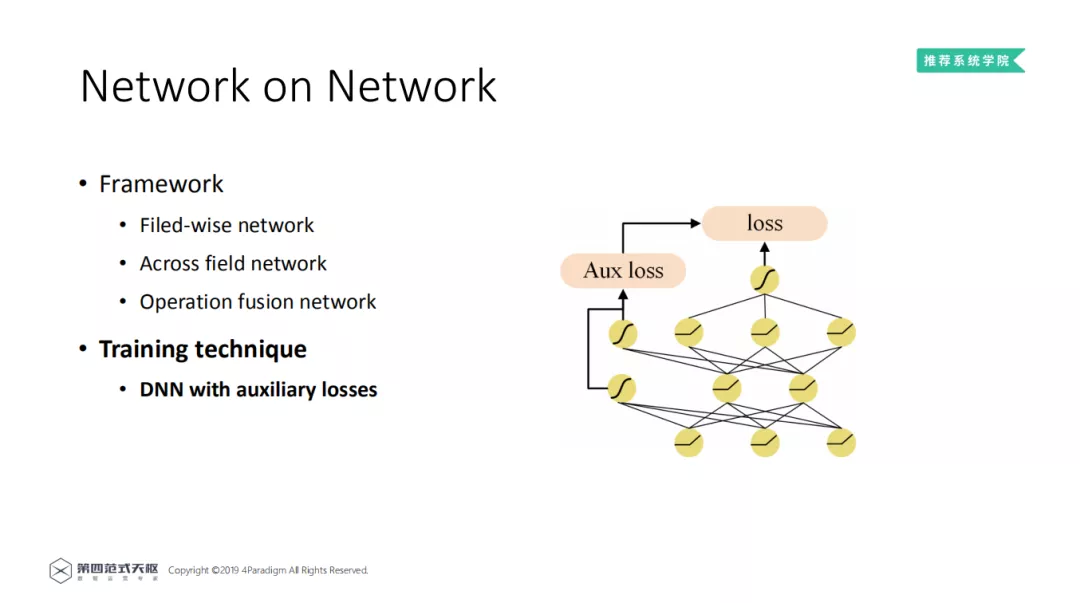
为了解决上述问题,第四范式提出了深度稀疏网络 ( NON ),它由三部分组成:底层为域内网络 ( Field-wise Network ) 中层为域间网络 ( Across Field Network ),顶层为融合网络 ( Operation Fusion Network )。域内网络为每个特征域使用一个 DNN 来捕获域内信息;域间网络包含了大部分已有的 Operation,采用多种域间交互操作来刻画特征域间潜在的相互作用;最后融合网络利用 DNN 的非线性,对所选特征域交互操作的输出进行深度融合,得到最终的预测结果。
2. Field-wise network
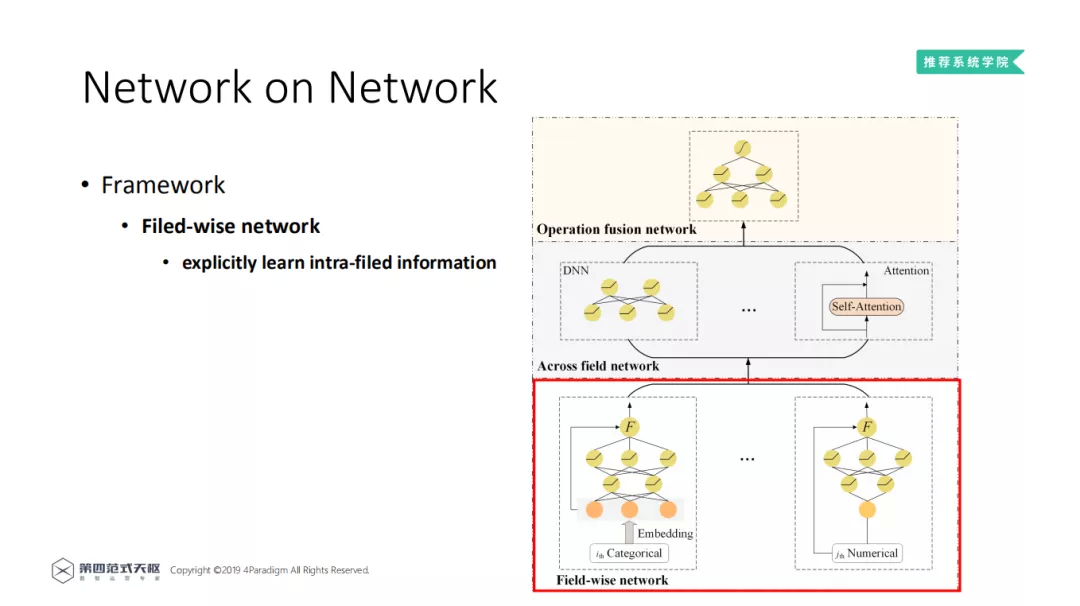
每一个特征 Field 都和一个 NN 网络相连,其中类别特征先进行 Embedding 操作,而数值型特征直接通过 NN 网络。通过 NN 网络强大的学习能力,显示地学习特征域内信息。鉴于 DNN 的强大的表达能力,特征域内信息可以被充分地学习。还有一点需要注意,在模型中还加入了一个 Gate Function,将 NN 的输出和输入耦合起来,常见的 Gate Function 包括 concatenation、element-wise product 以及其他更加复杂的操作。对于 Field-wise network 的详细分析将在实验中介绍。
3. Across field network
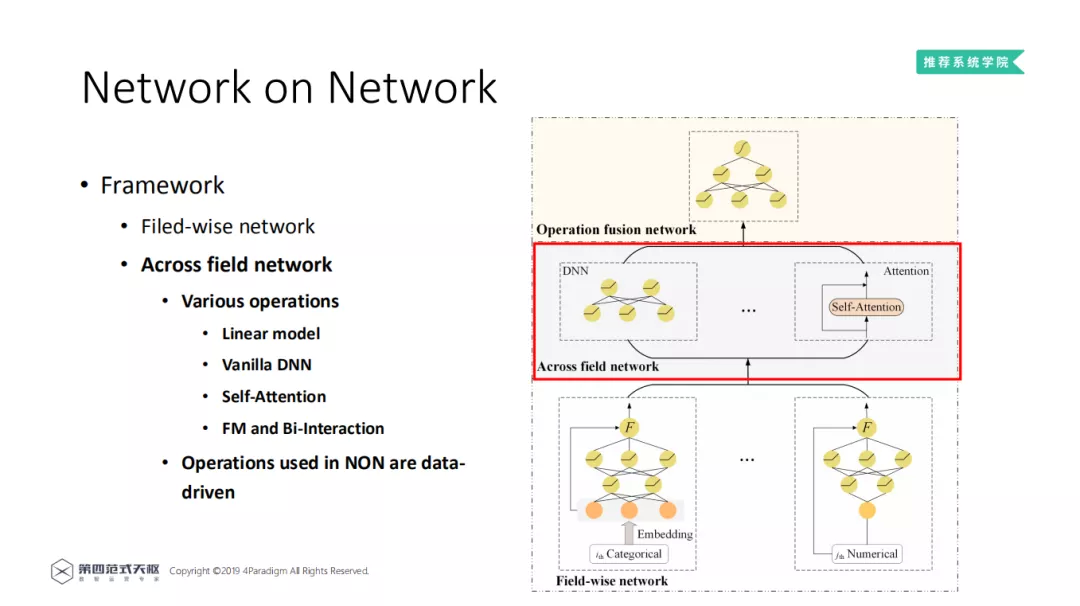
在域间网络 ( Across field network ) 中,利用已有的 Operation,来学习特征之间的 Interaction,这些 Operation 都是以 Field-wise network 的输出为输入。常见的特征域交互操作包括 LR、DNN、FM、Bi-Interaction 和多头自注意网络等。NON 在设计上,兼容目前大部分学术上提出的 Operation。在实际应用中,NON 将 Operation 作为超参数,在训练过程中根据数据进行选择。现有方法中,域间交互操作的方式是用户事先指定的。而在深度稀疏网络中,可以通过数据,自适应地选择最合适的操作组合,即在深度稀疏网络中,操作组合的选择是数据驱动的。
4. Operation fusion network
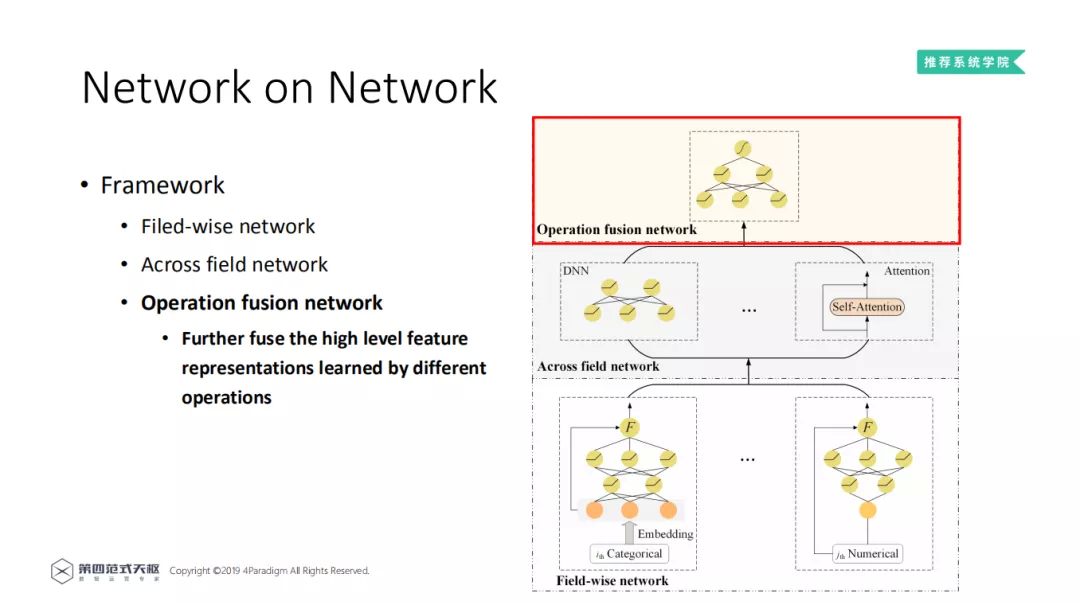
在融合网络 ( Operation fusion network ) 中,将域间网络层的输出拼接作为 NN 的输入,并利用 NN 的非线性,学习不同 Operation 的高阶特征表示。
需要注意一点,NON 网络设计的特别深,所以在训练过程中,很容易出现梯度消散的现象,导致模型效果变差。受到 GoogLeNet 的启发,在模型训练过程中引入了辅助损失。在 DNN 的每一层都加入了一条路径,连接到最终的损失上,缓解了梯度消散问题。经测试,该方案不仅能够增加模型最终预测效果,也使得模型能在更短的时间内,取得更好的效果。如下图所示。
至此模型介绍结束,接下来将分析实验结果。
04 NON 模型实验结果分析
1. DNN with auxiliary losses
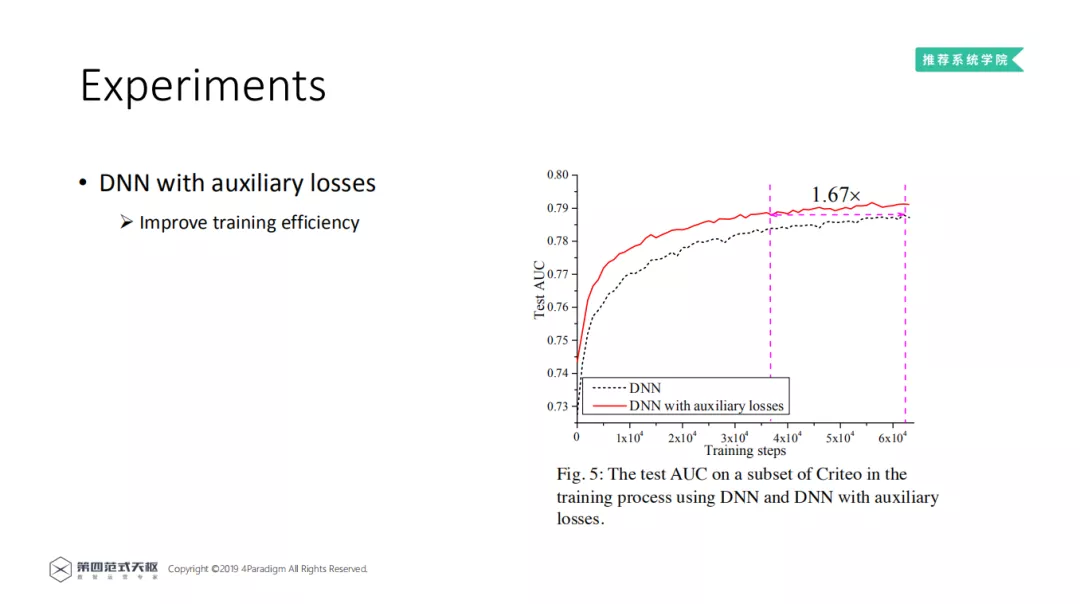
这是在 Criteo 的采样数据集上的实验结果,图中的横坐标是训练的轮次,纵坐标是 AUC。从图上可以看出,通过添加辅助损失,训练效率明显提升。在同等 AUC 的情况下,产生了 1.67 倍的加速。本文之后的所有关于 NON 的训练都是通过添加辅助函数的方式进行训练的。
2. Ablation study of NON
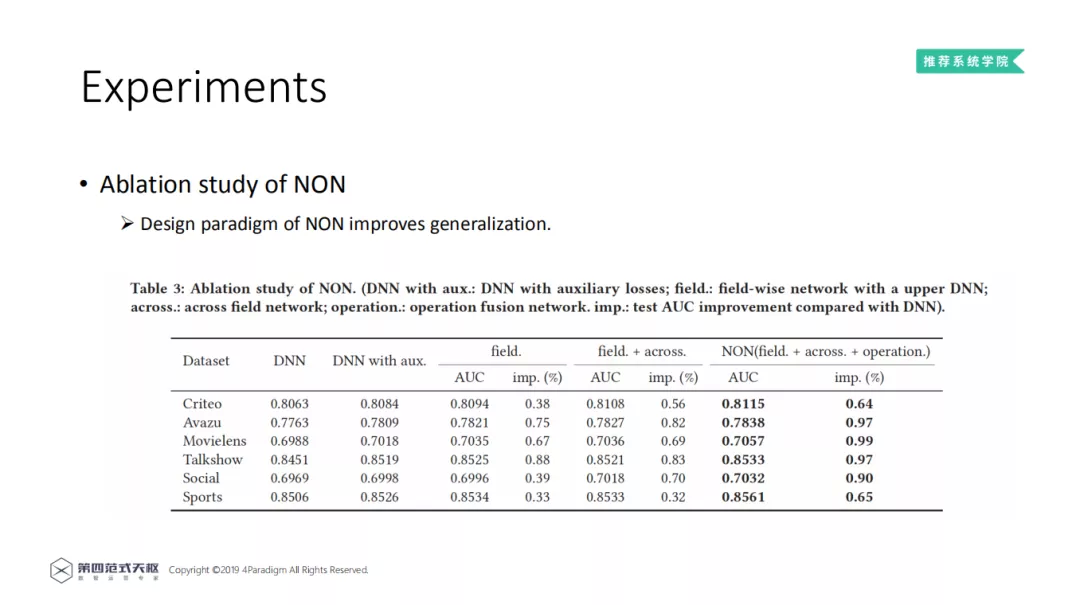
在 NON 消融学习中,展示 NON 每一个模块的作用。从左到右:第一列数据集;第二列,只有 DNN;第三列,增加辅助损失的 DNN,和 DNN 比较,添加了辅助损失可以提高性能;第四列,添加了 Field-wise Network,从结果看出,域内网络捕获的域内信息有助于提高模型的泛化性能;第五列,加入了 Across field network,结果有所提升;第六列,完整的 NON 模型,取得了最好的结果。可以看出随着 NON 不同的组件堆叠,模型的预测效果持续增长。
3. Study of field-wise network
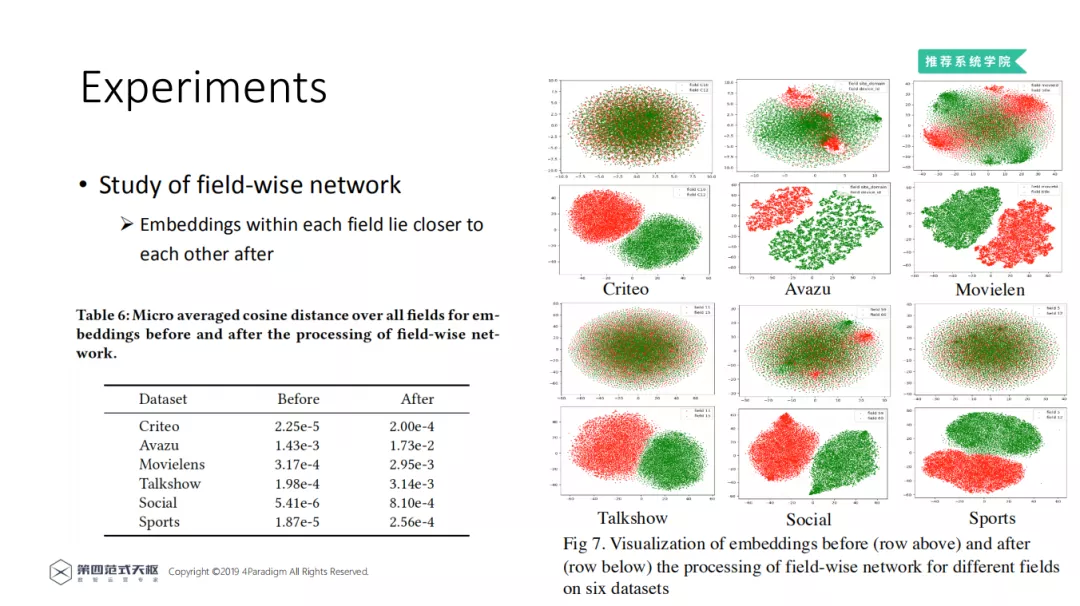
从定性和定量的角度分析 Field-wise network 的结果。右图是不同特征域 Embedding 的可视化展示。第一行是通过 Field-wise network 之前,第二行是通过 Field-wise network 之后。不同的颜色表示不同 Field 中的 Embedding。通过对 Field-wise network 处理前后特征值对应的向量进行可视化的比较,可以看出经过 Field-wise network 后,每个 Field 内的特征在向量空间中更加接近,不同 Field 间的特征也更容易区分。
左侧的表格展示了所有的 Field 内部的 Embedding 平均余弦相似度 ( 数值越大,相似度越高 )。Field-wise network 可以使余弦距离提高一到两个量级,即能有效地捕获每个域内特征的相似性。
4. Study of operations
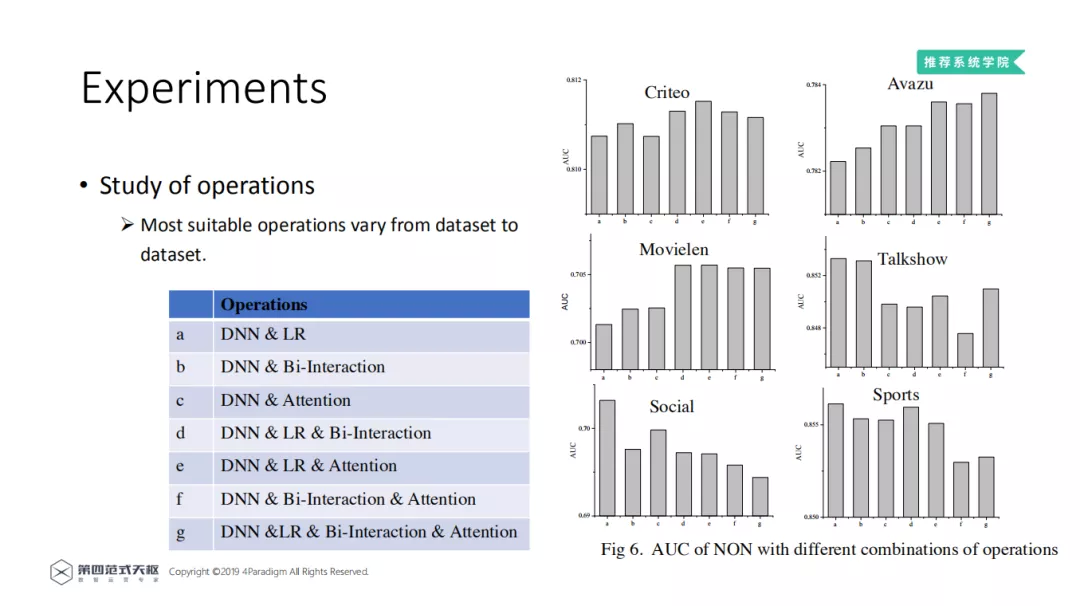
对 Operation 的学习,就是对 Across field network 层的学习。这一部分做了两个实验。在 Across field network,深度稀疏网络将不同的交互操作视为超参数,并根据在具体数据验证集上的效果,选择最适合的交互操作。其中,DNN 被视为必选,而其他操作 ( LR、Bi-Interaction 和 multi-head self-attention ) 被视为可选。第二个试验,通过固定域间网络中的操作组合来进行更多验证。横坐标是不同的组合,纵坐标是 AUC。可以看出没有一个操作组合能够在所有数据集上都取得最优效果,这表明了根据数据选择操作组合的必要性。
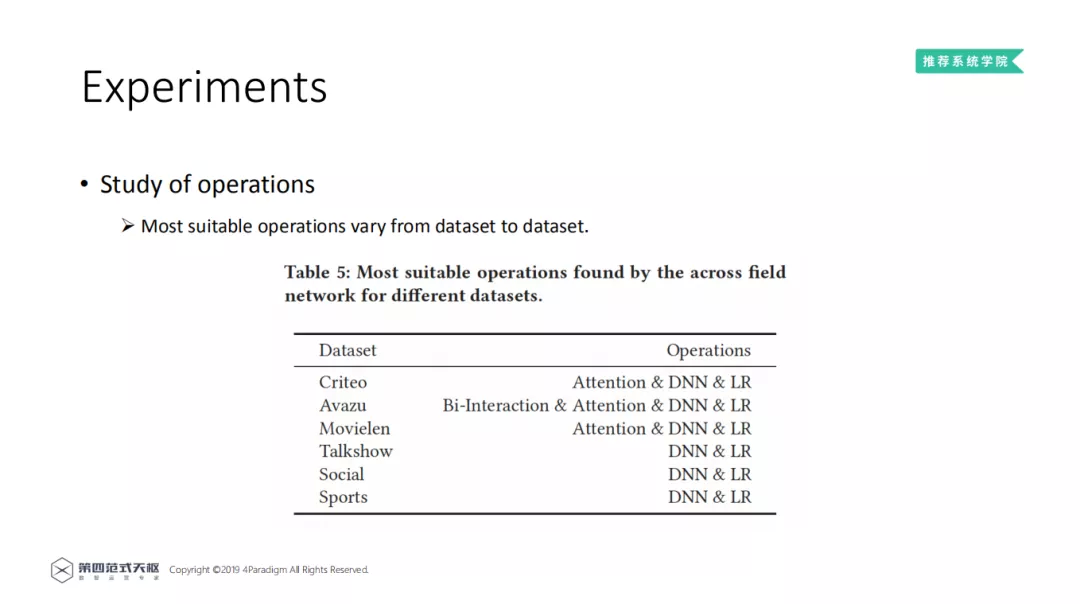
上表列出了在不同数据集上表现好的 Operation 组合,可以看到 DNN 和 LR 都有,可能是因为 LR 的稳定性很好。同时,从结果可以看出来,大数据集倾向于选择容量大、复杂的操作组合;小数据集倾向于轻量、简单的操作组合。再一次证明需要对不同的数据集需要选择不同的 Operation 组合。
5. Comparison with SOTAs
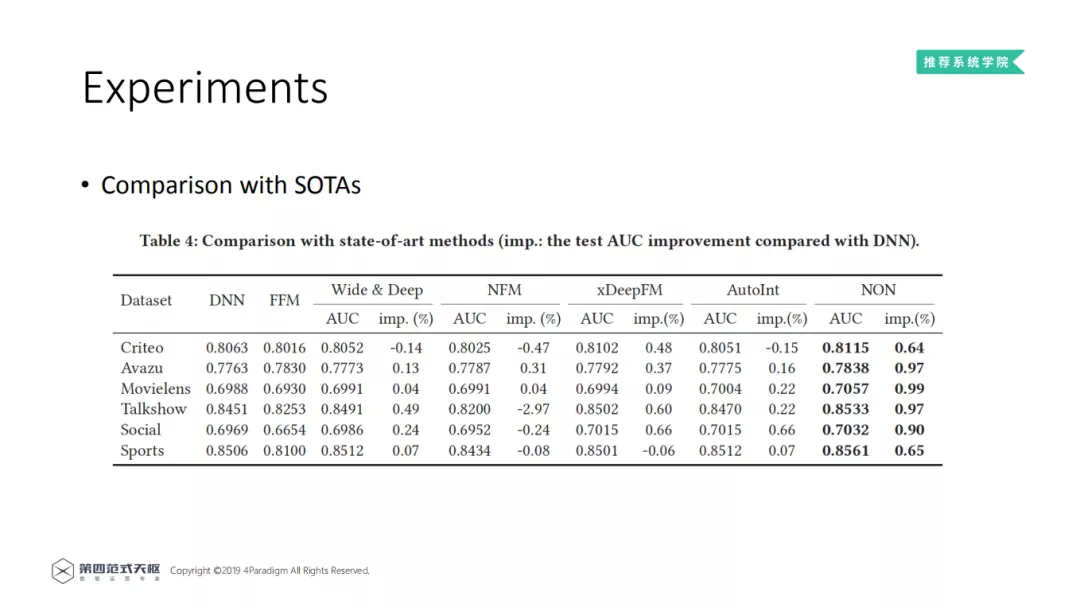
和当前的 SOTA 模型进行比较。与 FFM、DNN、Wide&Deep、NFM、xDeepFM、AutoInt 等模型相比,深度稀疏网络在实验数据集上均能获得最好的结果,AUC 可提高 0.64%~0.99%,结果说明 NON 模型设计的有效性。其次,看一些细节,在 Talkshow 数据集上,NFM 模型的效果退步,说明网络不一定越复杂越来,需要进行仔细的设计,才能获得较好的结果。结果证明了 NON 模型设计范式的有效性。
今天的分享就到这里,谢谢大家。
作者介绍:
周浩博士,第四范式研究员。
周浩,第四范式研究员,复旦大学博士。主要研究方向为自动机器学习、深度学习在推荐系统中的应用,相关研究成果发表在 KDD/SIGIR 上。
本文来自 DataFunTalk
原文链接:

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论