

背景
抖音很早就接入 CocoaPods 进行依赖管理了,项目前期抖音只有几十个组件,业务代码也基本在壳工程内,CocoaPods 可以满足业务研发的需求,但是随着业务的不断迭代,代码急剧膨胀,同时抖音工程也在进行架构优化,比如工程组件化改造,组件的数量和复杂度不断增加:组件(Pod)数量增加到 400+ ,子组件(Subspec)数量增加到 1500+ ,部分复杂组件的描述文件(podspec)膨胀到 1000+ 行,这导致了依赖管理流程(主要是 Pod Install)的效率不断下降,同时也导致了 Xcode 检索和构建效率下降。
除了效率下降外,我们也开始遇到一些 CocoaPods 潜在的稳定性问题,比如在 CI/CD 任务并发执行的环境下 Pod Install 出现大量失败,这些问题已经严重影响了我们的研发效率。在超大工程、复杂依赖、快速迭代的背景下,CocoaPods 已经不能很好地支撑我们的研发流程了。
反馈最多就是 Pod Install 慢,经常会有同学反馈 Pod Install 流程慢,涉及到决议流程慢,依赖下载慢、Pods 工程生成慢等
本地 Source 仓库没更新,经常导致找不到 Specification,Pod Install 失败
依赖组件多,循环依赖报错,但是难以找到循环链路
依赖组件多,User 工程复杂度,导致 Pod Install 后 Xcode 工程索引慢,卡顿严重
依赖组件多,工程构建出现不符合预期的失败问题,比如 Arguments Too Long
研发流程上,有部分研发同学本地误清理了 CocoaPods 缓存,导致工程编译或者链接失败
组件拆分后,新添加文件必须 Pod Install 后才可以被其他组件访问,这拖慢了研发效率
我们开始尝试在 0 侵入、不影响现有研发流程的前提下,改造 CocoaPods 做来解决我们遇到的问题,并且取得了一些收益。在介绍我们的优化前,我们会先对 CocoaPods 做一些介绍, 我们以 CocoaPods 1.7.5 为例来做说明依赖管理的核心流程「Pod Install」
Pod Install
我们以一个 MVP 工程「iOSPlayground」为例子来说明,iOSPlayground 工程是怎么组织的:
我们在 Podfile 中为 Target「iOSPlayground」引入 SDWebImage 以及 SDWebImage 的两个 Coder,并声明这些组件的版本约束
然后执行 Pod install 命令 bundle exec pod install,CocoaPods 开始为你构建多依赖的开发环境;整个 Pod Install 流程最核心的就是 ::Pod::Installer 类,Pod Install 命令会初始化并配置 Installer,然后执行 install! 流程,install! 流程主要包括 6 个环节

下面会对这 5 个流程做一些简单分析,为了简单起见,我们会忽略一些细节。
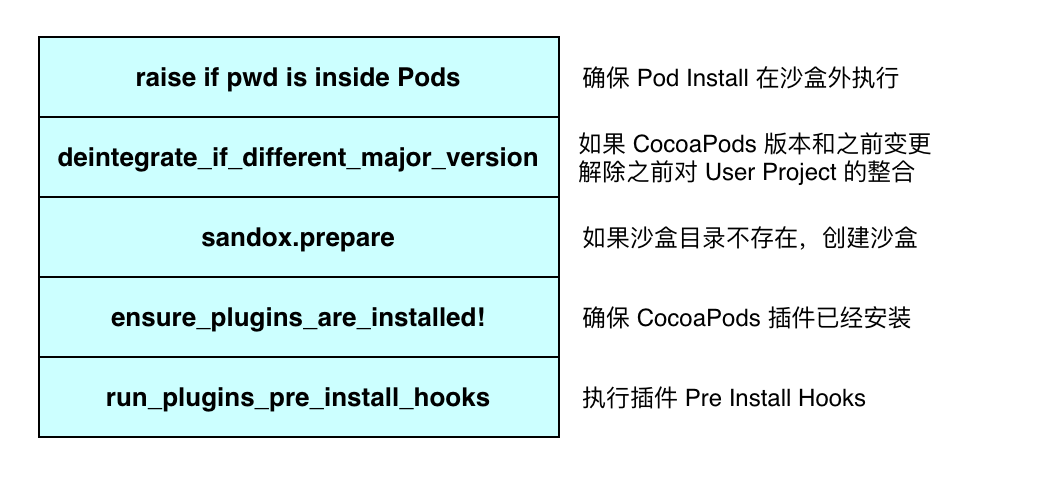
准备阶段
这个流程主要是在 Pod Install 前做一些环境检查,并且初始化 Pod Install 的执行环境。
依赖分析
这个流程的主要目标是分析决议出所有依赖的版本,这里的依赖包括 Podfile 中引入的依赖,以及依赖本身引入的依赖,为 Downloader 和 Generator 流程做准备。

这个过程的核心是构建 Molinillo 决议的环境:准备好 Specs 仓库,分析 Podfile 和 Podfile.lock,然后进行 Molinillo 决议,决议过程是基于 DAG(有向无环图)的,可以参考下图,按照最优顺序依次进行决议直到最后决议出所有节点上依赖的版本和来源。
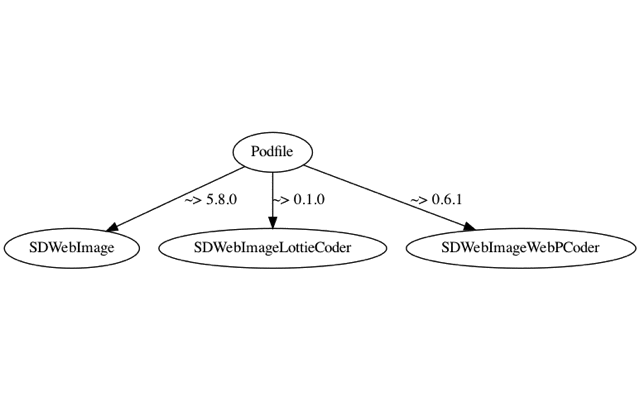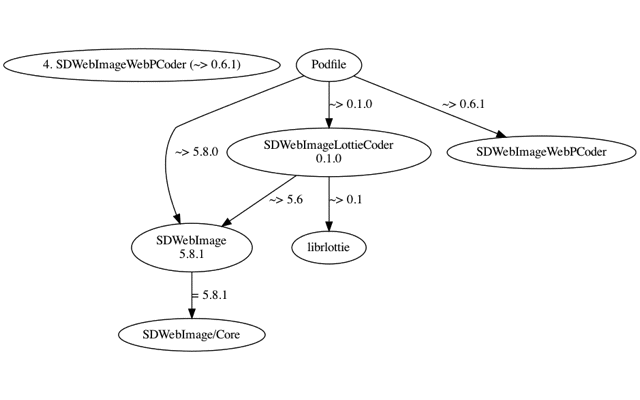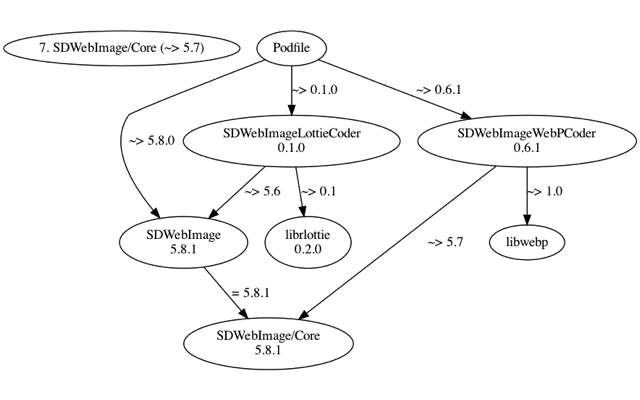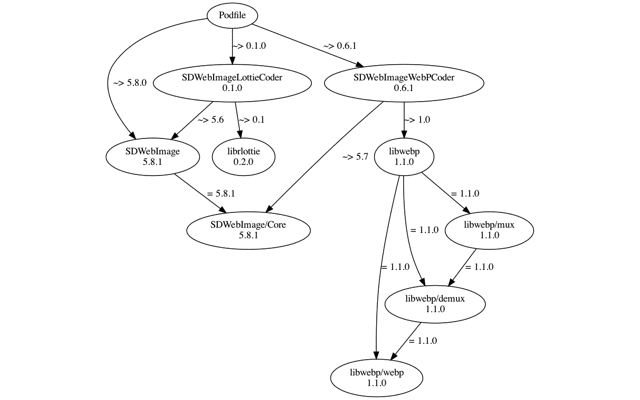
iOSPlayground 工程最后决议出的依赖列表是:
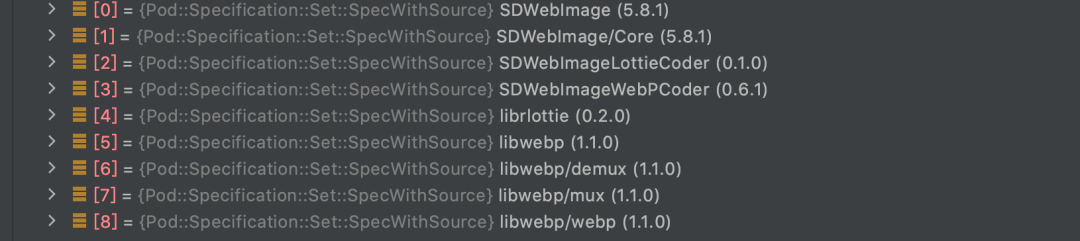
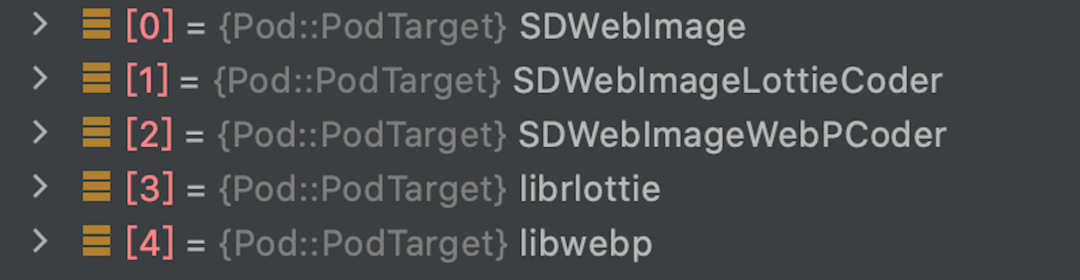
基于最后决议的结果我们就可以获取 Specifications、生成 Aggregate Targets 和 Pod Targets。
Aggregate Targets:

Pod Targets:
依赖下载
这个流程的目标是下载依赖,下载前会根据依赖分析的结果 specifications 和 sandbox_state 生成需要下载的 Pods 列表,然后串行下载所有依赖。这里只描述 Cache 开启的情况,具体流程可以参考下图:
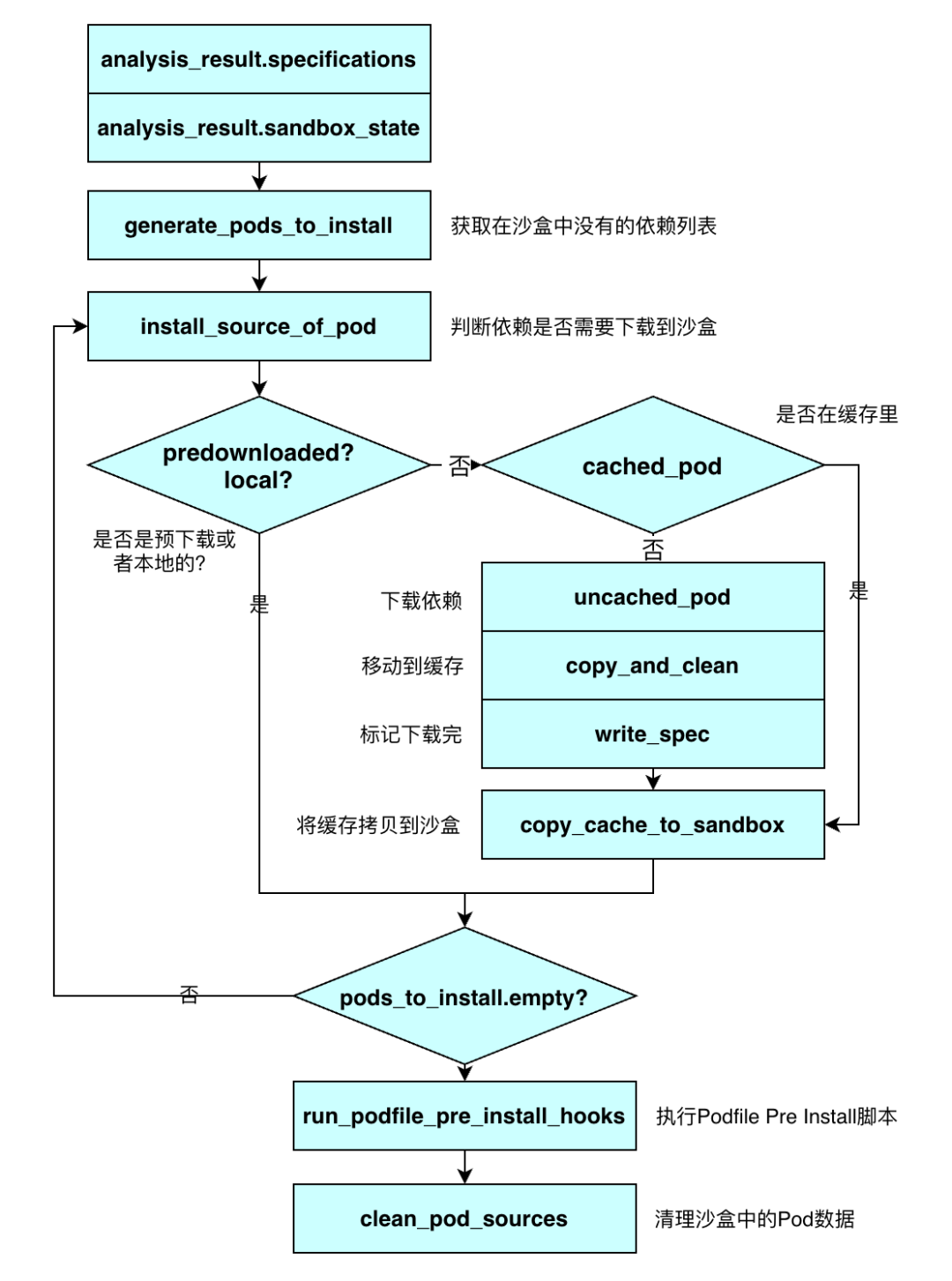
CocoaPods 会根据 Pod 来源选择合适的下载器,如果是 HTTP 地址,使用 CURL 进行下载;如果是 Git 地址,使用 Git 进行拉取;CocoaPods 也支持 SVN/HG/SCP 等方式。
iOSPlayground 工程的下载流程:
Pods 校验
这个阶段主要是检查 Pod 描述文件 Speification、Pod Targets 和 Aggregate Targets 配置是否正确,从而保证 Pod Install 后可以进行正确构建,一般包括四个流程的检查。

Pods 工程生成
这个流程的目标是生成 Pods 工程,根据依赖决议的结果 Pod Targets 和 Aggregate Targets,生成 Pods 工程,并生成工程中 Pod Targets 和 Aggregate Targets 对应的 Native Targets。
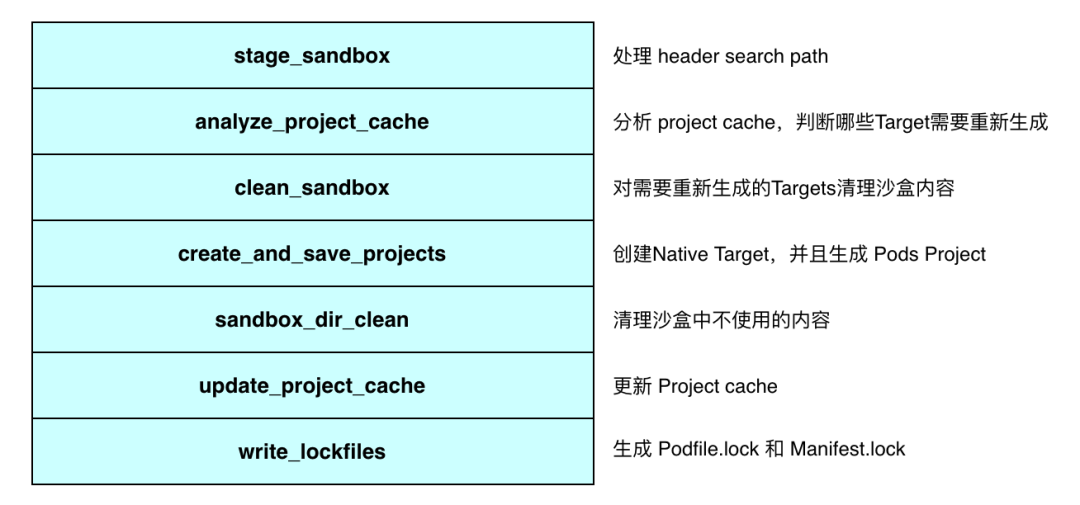
CocoaPods 提供两种 Project 的生成策略:Single Project Generator 和 Multiple Project Generator,Single Project Generator 是指只生成 Pods/Pods.xcodeproj,Native Pod Target 属于 Pods.xcodeproj;Multiple Project 是 CocoaPods 1.7.0 引入的新功能,不只会生成 Pods/Pods.xcodeproj,并且会为每一个 Pod 单独生成 Xcode Project,Pod Native Target 属于独立的 Pod Xcode Project,Pod Xcode Project 是 Pods.xcodeproj 的子工程,相比 Single Project Generator,会有性能优势。这里我们以 Single Project 为例,来说明 Pods.xcodeproj 生成的一般流程。
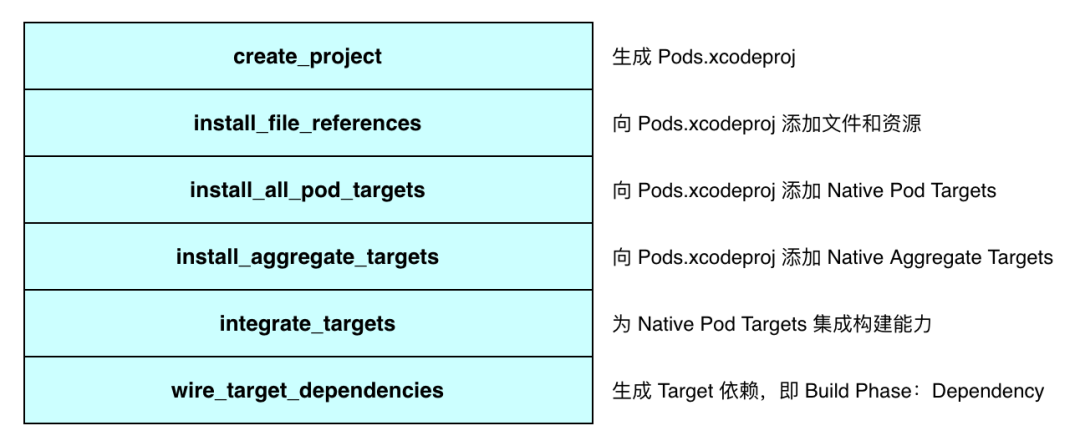
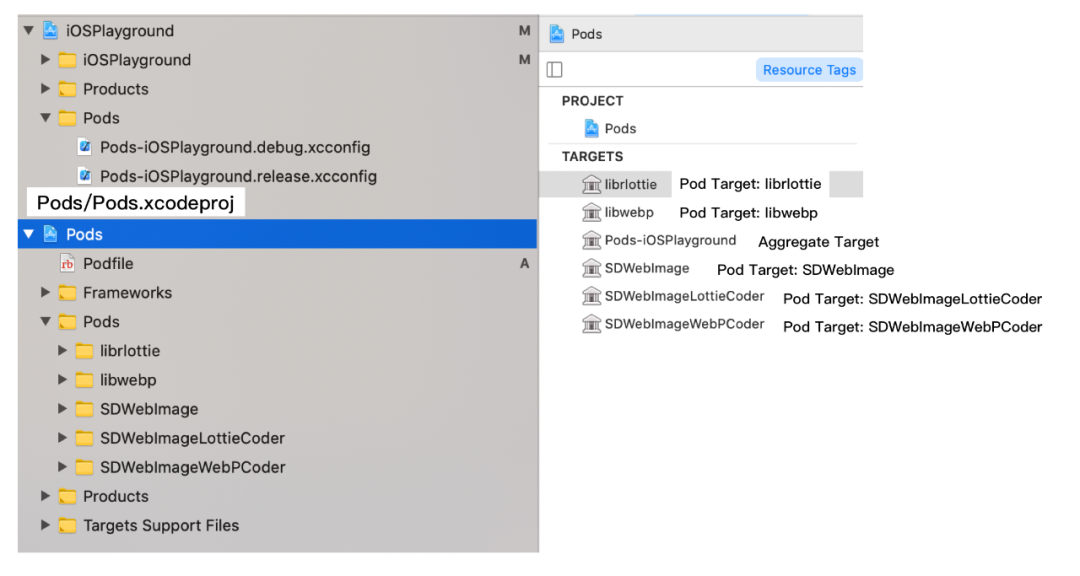
iOSPlayground 工程在 Single Project Generator 下生成的工程结构:
User 工程整合
这个流程的目标是将 Pods.xcodeproj 整合到 User.xcodeproj 上,将 User Target 整合到 CocoaPods 的依赖环境中,从而在后续的构建流程生效:
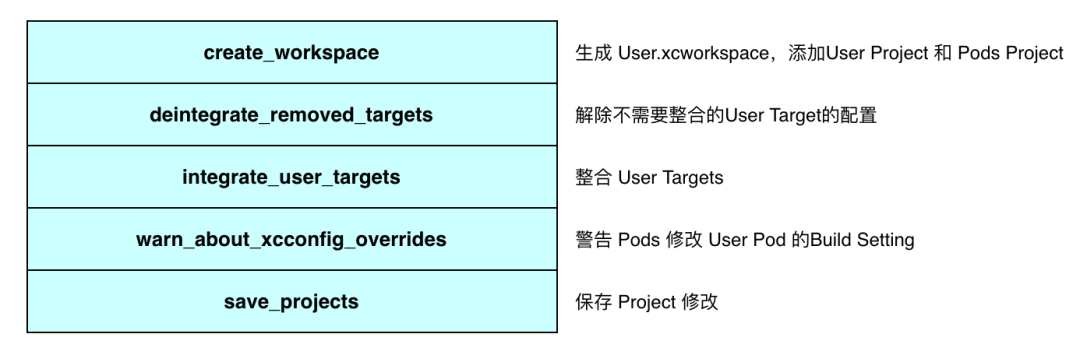
User Target 的整合一般包括 Xcconfig 整合、Target 整合、动态库整合和资源整合等:
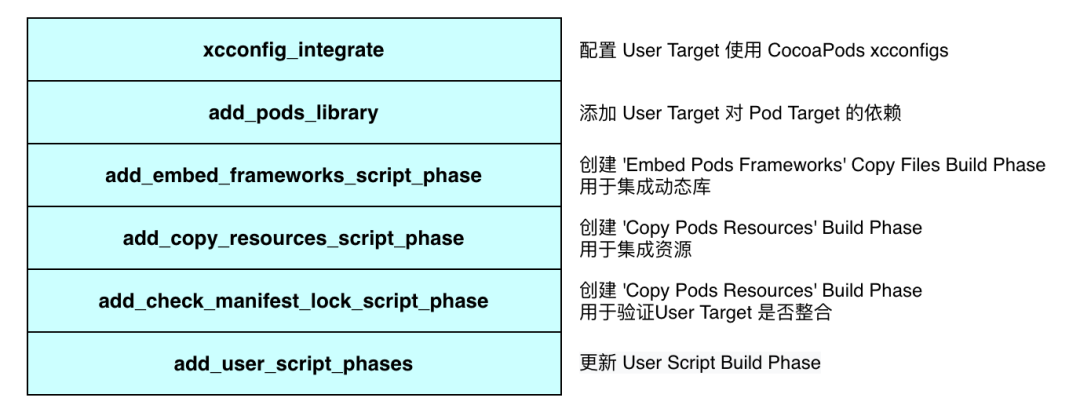
User 工程构建
Pod Install 执行完成后,就将 User Target 整合到了 CocoaPods 环境中。User Target 依赖 Aggregate Target,Aggregate Target 依赖所有 Pod Targets,Pod Targets 按照 Pod 描述文件(Podspec)中的依赖关系进行依赖,这些依赖关系保证了编译顺序
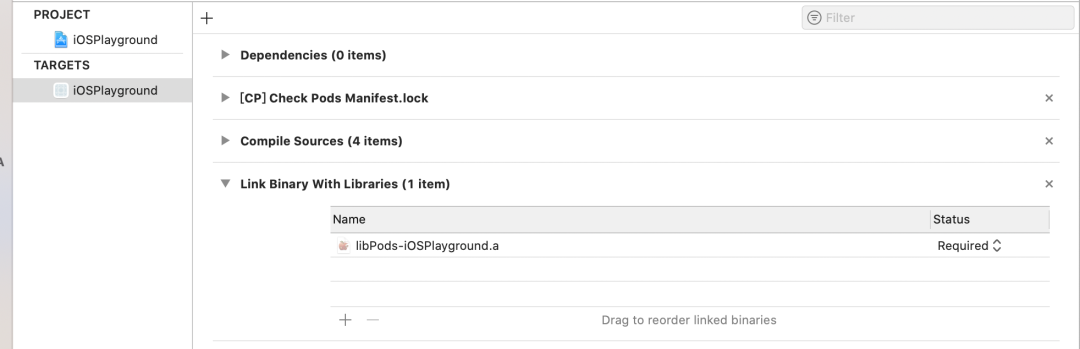
iOSPlayground 工程中 User Target: iOSPlayground 依赖了 Aggregate Target 的产物 libPods-iOSPlayground.a
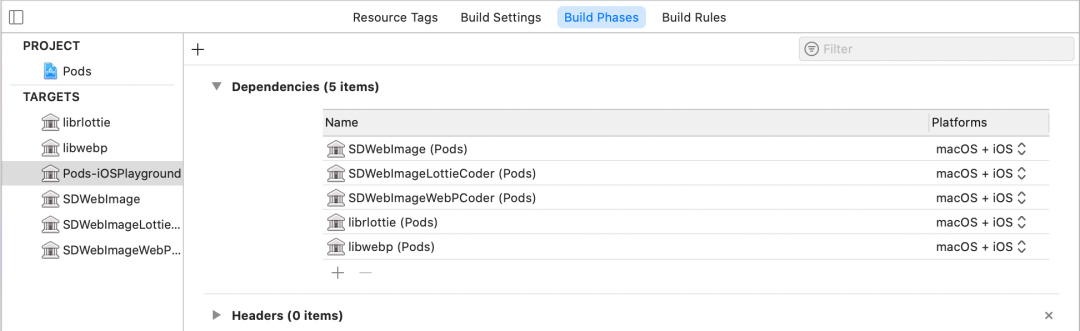
iOSPlayground 工程中 Aggregate Target: Pod-iOSPlayground 依赖了了所有 Pod Targets
编译完成后,就开始进行链接、资源整合、动态库整合、APP 签名等操作,直到最后生成完整 APP。Xcode 提供了 Build Phases 方便我们查看和编辑构建流程配置,同时我们也可以通过构建日志查看整个 APP 的构建流程:

如何评估
我们需要建立一些数据指标来进行衡量我们的优化结果,CocoaPods 内置了 ruby-prof(https://ruby-prof.github.io/) 工具。ruby-prof 是一个 Ruby 程序性能分析工具,可以用于测量程序耗时、对象分配以及内存占用等多种数据指标,提供了 TXT、HTML、CallGrind 三种格式。首先安装 ruby-prof,然后设置环境变量 COCOAPODS_PROFILE 为性能测试文件的地址,Pod Install 执行完成后会输出性能指标文件 ruby-prof 提供的数据是我们进行 CocoaPods 效能优化的重要参考,结合这部分数据我们可以很方便地分析方法堆栈的耗时以及其他性能指标。
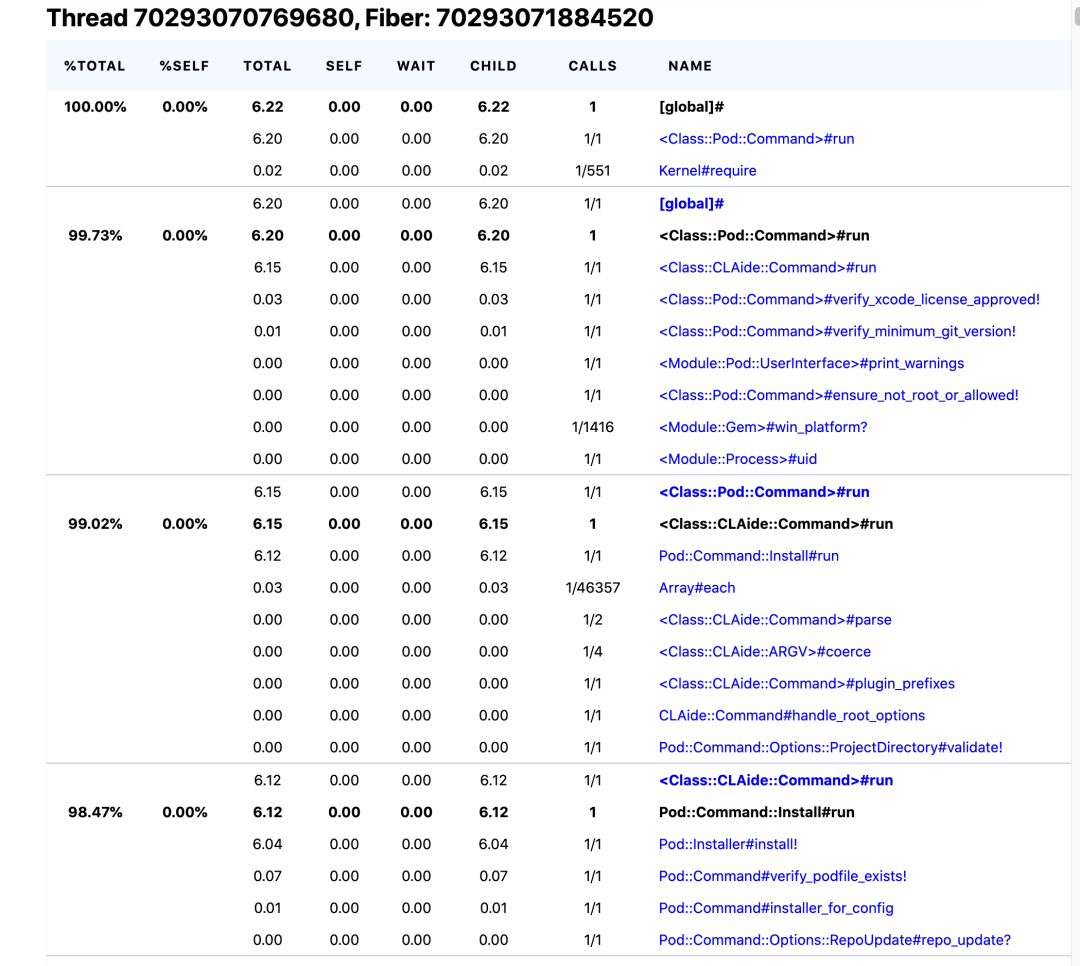
但是 Ruby-prof 工具是 Ruby 方法级别,难以细粒度地查看实际 Pod Instal 过程中各个具体流程的耗时,可以作为数据参考,但是难以作为效率优化结果的标准。同时我们也需要一套体系来衡量 Pod Install 各个流程的耗时,基于这个诉求,我们自研了 CocoaPods 的 Profiler,并且在远端搭建了数据监控体系:
Profiler 可以在本地打印各阶段耗时,也可以下钻到详细的流程
install! consume : 5.376132s prepare consume : 0.002049s resolve_dependencies consume : 4.065177s download_dependencies consume : 0.001196s validate_targets consume : 0.037846s generate_pods_project consume : 0.697412s integrate_user_project consume : 0.009258s
Profiler 会把数据上传到平台,方便进行数据可视化
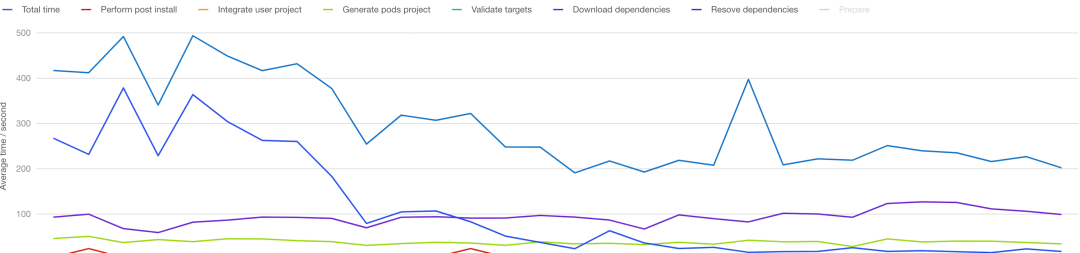
Profiler 除了上传 Pod Install 各个耗时指标以外,也会上传失败情况和错误日志,这些数据会被用于衡量稳定性优化的效果。
优化实践
对 Pod Install 的执行流程有了一定的了解后,基于 Ruby 语言的提供的动态性,我们开始尝试在 0 侵入、不影响现有研发流程的前提下,改造 CocoaPods 做来解决我们遇到的问题,并且取得了一些收益。
Source 更新
按需更新
我们知道 CocoaPods 在进行依赖版本决议的时候,会从本地 Source 仓库(一般是多个 Git 仓库)中查找符合版本约束的 Podspecs,如果本地仓库中没有符合要求的,决议会失败。仓库中没有 Podspec 分为几种情况:
本地 Source 仓库没有更新,和远程 Source 仓库不同步
远程 Source 仓库没有发布符合版本约束的 Podspec
原因 2 是符合预期的;原因 1 是因为研发同学没有主动更新本地 source repo 仓库,可以在 pod install 后添加 --repo-update 参数来强制更新本地仓库,但是每次都加上这个参数会导致 Pod Install 执行效率下降,尤其是对包含多个 source repo 的工程。
怎么做可以避免这个问题,同时保证研发效率?
不主动更新仓库,如果找不到 Podspec,再自动更新仓库
不更新所有仓库,按需更新部分仓库
如果有新增组件,找不到 Podspec 后,自动更新所有仓库
如果部分更新后依然失败,自动更新所有仓库;这种情况出现在隐式依赖新增的情况
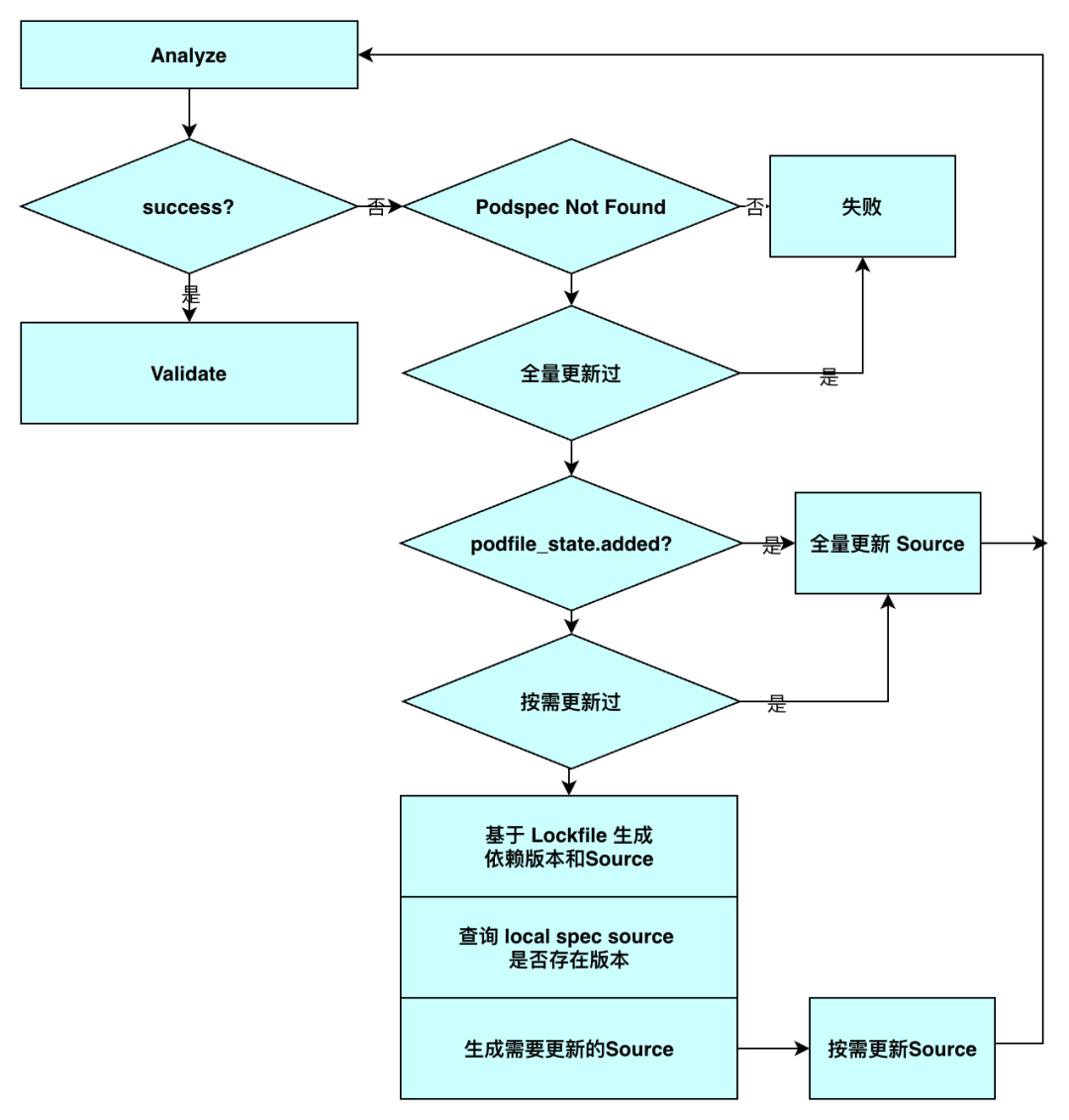
仓库按需更新,是指基于 Podfile.lock 查找哪些依赖的版本不在所属的仓库内,标记该依赖所属的仓库为需要更新,循环执行,检查所有依赖,获取到所有需要更新的仓库,更新所有标记为需要更新的仓库。
这样研发同学不需要关心本地 Source 仓库是否更新,仓库会按照最佳方式自动和远程同步。
更新同步
在仓库更新流程中也会出现并发问题,比如在抖音的 CI 环境上构建任务是并发执行的,在某些情况下多个任务会同时更新本地 source 仓库,Git 仓库会通过锁同步机制强制并发更新失败,这就导致了 CI 任务难以并发执行。如何解决并发导致的失败问题?
最简单的方式就是避免并发,一个机器同时只能执行一个任务,但是这会导致 CI 执行效率下降。
不同任务间进行 source 仓库隔离,CocoaPods 默认提供了这种机制,可以通过环境变量 CP_REPOS_DIR 的设置来自定义 source 仓库的根目录,但是 source 仓库隔离后,会导致同一个仓库占用多份磁盘,同时在需要更新的场景下,需要更新两次,这会影响到 CI 执行效率。
方案 1 和方案 2 一定程度保证了任务的稳定性,但是影响了研发效率,更好的方式是只在需要同步的地方串行,不需要同步的地方并发执行。一个自然而然的想法就是使用锁,不同 CocoaPods 任务是不同的 Ruby 进程,在进程间做同步可以使用文件锁。通过文件锁机制,我们保证了只有一个任务在更新仓库。
CocoaPods 仓库更新流程流程遇到的问题,本质是由于使用了本地的 Git 仓库来管理导致,在 CocoaPods 1.9.0 + ,引入 CDN Source 的概念,抖音也在尝试向 CDN Source 做迁移。
依赖决议
简化决议
CocoaPods 的依赖版本决议流程是基于 Molinillo 的,Molinillo 是基于 DAG 来进行依赖解析的,通过构建图可以方便的进行依赖关系查找、依赖环查找、版本降级等。但是使用图来进行解析是有成本的,实际上大部分的本地依赖决议场景并不需要这么复杂,Podfile.lock 中的版本就是决议后的版本,大部分的研发流程直接使用 Podfile.lock 进行线性决议就可以,这可以大幅加快决议速度。
Specification 缓存
依赖分析流程中,CocoaPods 需要获取满足约束的 Specifications,1.7.5 上的流程是获取一个组件的所有版本的 Specifications 并缓存,然后从 Specifications 中筛选出满足约束的 Specifications。对于复杂的项目来说,往往对一个依赖的约束来自于多个组件,比如 A 依赖 F(>=0),B 依赖 F (>=0),在分析完 A 对 F 的依赖后,在处理 B 对 F 的依赖时,还是需要进行一次全量比较。通过优化 Specification 缓存层可以减少这部分耗时,直接返回。
优化后:
CocoaPods 1.8.0 开始也引入了这个优化,但是 1.8.0 中并没有重载 Pod::Requirement 的 eql? 方法,这会导致使用 Pod::Requirement 对象做 Key 的情况下,没有办法命中缓存,导致缓存失效了,我们重载 eql? 生效决议缓存,加速了 Molinillo 决议流程,获得了很大的性能提升:
循环依赖发现
当出现循环依赖时,CocoaPods 会报错,但报错信息只有谁和谁之间存在循环依赖,比如:
There is a circular dependency between A/S1 and D/S1
随着工程的复杂度提高,对于复杂的循环依赖关系,比如 A/S1 -> B -> C-> D/S2 -> D/S1 -> A/S1, 基于上面的信息我们很难找到真正的链路,而且循环依赖往往不止一条,subspec、default spec 等设置也提高了问题定位的复杂度。我们优化了循环依赖的报错,当出现循环依赖的时候,比如 A 和 D 之间有
环,我们会查找 A -> D/S1 之前所有的路径,并打印出来:
There is a circular dependency between A/S1 and D/S1 Possible Paths:A/S1 -> B -> C-> D/S2 -> D/S1 -> A/S1 A/S1 -> B -> C -> C2 -> D/S2 -> D/S1 -> A/S1 A/S1 -> B -> C -> C3 -> C2 -> D/S2 -> D/S1 -> A/S1
沙盒分析缓存
SandboxAnalyzer 主要用于分析沙盒,通过决议结果和沙盒内容判断哪些 Pods 需要删除哪些 Pods 需要重装,但是在分析过程中,存在大量的重复计算,我们缓存了 sandbox analyzer 计算的中间结果,使 sandbox analyzer 流程耗时减少 60%。
依赖下载
大型项目往往要引入几百个组件,一旦组件发布新版本或者没有命中缓存就会触发组件下载,依赖下载慢也成为大型项目反馈比较集中的问题。
依赖并发下载
CocoaPods 一个很明显的问题就是依赖是串行下载的,串行下载难以达到带宽峰值,而且下载过程除了网络访问,还会进行解压缩、文件准备等,这些过程中没有进行网络访问,如果把下载并行是可以提高依赖下载效率的。我们将抖音的下载过程优化为并发操作,下载流程总时间减少了 60%以上。
HTTP API 下载
CocoaPods 支持多种下载方式的,比如 Git、Http 等。一般组件以源码发布,会使用 Git 地址作为代码来源,但是 Git 下载是比 Http 下载慢的,一是 Git 下载需要做额外的处理和校验,速度和稳定性要低于 HTTP 下载,二是在组件是通过 Git 和 Commit 指明 source 发布的情况下,Git 下载页会克隆仓库的日志 GitLog, 对于开发比较频繁的项目,日志大小要远大于仓库实际大小,这会导致组件下载时间变长。我们基于 Gitlab API 将 Git 地址转化为 HTTP 地址进行下载,就可以加快这部分组件的下载速度了。
沙盒软连接
CocoaPods 在安装依赖的时候,会在沙箱 Pods 目录下查找对应依赖,如果对应依赖不存在,则会将缓存中的依赖文件拷贝到沙箱 Pods 目录下。对于本地有多个工程的情况,Pods 目录占用磁盘就会更多。同时,将缓存拷贝到沙箱也会耗时,对于抖音工程,如果所有的内容都要从缓存拷贝到沙箱,大概需要 60s 左右。我们使用软连接替换拷贝,直接通过链接缓存中的 Pod 内容来使用依赖,而不是将缓存拷贝到 Pods 沙箱目录中,从而减少这部分磁盘占用,同时减少拷贝的时间。
缓存有效检查
在抖音使用 CocoaPods 的过程中,尤其是 CI 并发环境,存在缓存中文件不全的情况,缺少部分文件或者整个文件夹,这会导致编译失败或者运行存在问题。CocoaPods 本身有保证 Pods 缓存有效的机制:
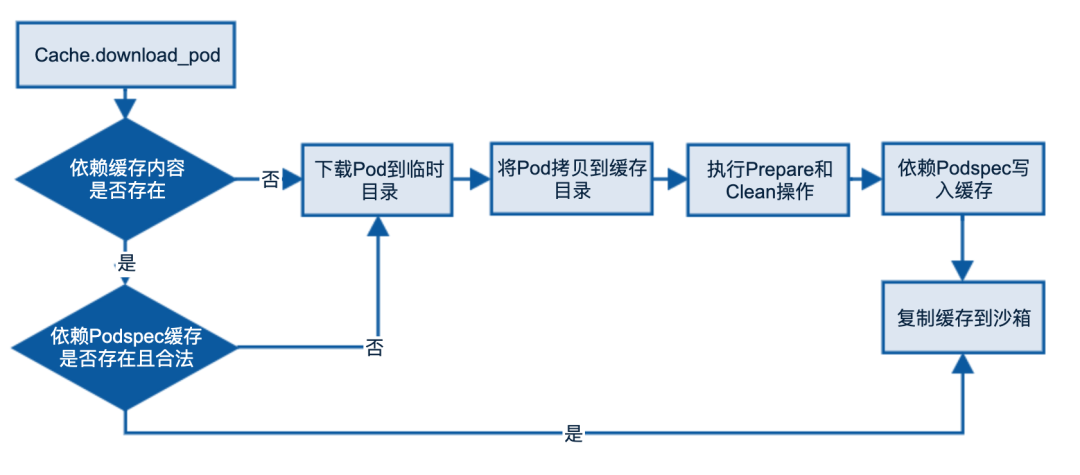
依赖Podspec写入缓存 这一步实际上是为了保证整个缓存流程是有效的:
但是在 依赖Podspec写入缓存 中,CoocoPods 存在 BUG。path.sub_ext('.podspec.json')会导致部分版本信息被错误地识别为后缀名,比如 XXX 0.1.8-5cd57.podspec.json 版本写入到缓存中变为 0.1.podspec.json, 丢失了小版本和内容标示信息,会导致了整个 Pod 缓存有效性校验失效。比如 XXX 0.1.8 缓存执行成功,XXX 0.1.9 在缓存 copy、prepare 的流程被取消,实际上很大概率上 XXX 0.1.9 的缓存是不完整的,但是下次执行的时候,缓存目录存在,Podspec 存在(0.1.podspec.json),不完整的缓存被判定为有效,使用了错误的缓存,导致了编译失败。
修改 path_for_spec 逻辑,保证依赖 Podspec 缓存写入到正确的文件 0.1.8-5cd57.podspec.json,而不是 0.1.podspec.json。
依赖下载同步
在缓存下载的环境,依然会出现并发问题,我们通过对 Pod 下载流程加文件锁的机制来保证并发下下载任务的稳定。
Pods 工程生成
增量安装
CocoaPods 在 1.7.0+ 提供了新的 Pods Project 的生成策略:Multiple Project Generator。通过开启多 Project「generate_multiple_pod_projects」,可以提高 Xcode 工程的检索速度。在开启多 Project 的基础上,我们可以开启增量安装「incremental_installation」,这样在 Pods 工程生成的时候,会基于上次 Pod Install 的缓存按需生成部分 Pod Target 而不会全量生成所有 Pod Target,对二次 Pod Install 的执行效率改善很明显,以抖音为例,二次 Pod Install (增量)是首次 Pod Install (全量)的 40%左右。这个是 CocoaPods 的 Feature,就不展开说明了。
单 Target/Configuration 安装
大部分工程会包含多个业务 Target 和 Build Configuration,Pod Install 会对所有的 Target 进行安装,对所有的 Build Configuration 进行配置。但是实际本地开发过程中一般只会使用一个 Build Configuration 下的一个 Target,其他 Target 和 Configuratioins 的依赖安装实际上是冗余操作。比如有些依赖只有某几个 Target 有,如果全量安装,即使不使用这些 Target,也要下载和集成这些依赖。抖音工程包括多个业务 Target 和多个构建 Build Configuration,不同业务 Target 之间依赖的差集有几十个,只对特定 Target 和特定的 Configuration 进行集成能够获得比较明显的优化,这个方案落地后:
Pod Install 安装依赖数量减少,决议时间、Pod 工程生成时间减少;
单 Target/Configuration 下 Pod 工程复杂度减少, Xcode 索引速度改善明显,以抖音为例子,索引耗时减少了 60%;
可以为每个 Target、每个 Configuration 配置独立的依赖版本;
每个 Target 的编译隔离,避免了其他 Target 的依赖影响当前 Target 的编译。
Pod 是全量 Target 安装,在编译的时候并没有对非当前 Target 的依赖做完整的隔离,而是在链接的时候做了隔离,但是 OC 的方法调用是消息转发机制的,因此没有链接指定库的问题被延迟到了运行时才能发现 (unrecognized selector)。使用单 Target 的方式可以提前发现这个类问题。
缓存 FileAccessors
在 Pods 工程生成流程中有三个流程会比较耗时,这些数据每次 Pod Install 都需要重新生成:
Pod 目录下的文件和目录列表,需要对目录下的所有节点做遍历;
Pod 目录下的动态库列表,需要分析二进制格式,判断是否为动态库;
Pod 文件的访问策略缓存 glob_cache,这个 glob_cache 是用于访问组件仓库中不同类型文件的,比如 source files、headers、frameworks、bundles 等。
但其实这些数据对固定版本的依赖都是唯一的,如果可以缓存一份就可以避免二次生成导致的额外耗时,我们补充了这个缓存层,以抖音为例子,使 Pod Clean Install 减少了 36%,Pod No-clean Install 减少了 42%。
添加 FileAccessors 缓存层后,在效率上获得提升的同时,在稳定性上也获得了提升。因为在本地记录了 Pod 完整的文件结构,因此我们可以对 Pod 的内容做检查,避免 Pod 内容被删除导致构建失败。比如研发同学误删了缓存中的二进制库,CocoaPods 默认是难以发现的,需要延迟到链接阶段报 Symbol Not Found 的错误,但是基于 FileAccessors 缓存层,我们可以在 Pod Install 流程对 Pod 内容做检查,提前暴露出二进制库缺失,触发重新下载。
提高编译并发度
Pod Target 的依赖关系会保证 Target 按顺序编译,但是会导致 Target 编译的并发度下降,一定程度上降低了编译效率。其实生成静态库的 Pod Target 不需要按顺序进行编译,因为静态库编译不依赖产物,只是在最后进行链接。通过移除静态库的 Pod Target 对其他 Target 的依赖,可以提高整体的编译效率。

在 Multi Project 下,「Dependency Subproject」会导致索引混乱,移除静态库的 Pod Target 对其他 Target 的依赖后,我们也可以删除 Dependent Pod Subproject,减少 Xcode 检索问题。
Arguments Too Long
超大型工程在编译时稳定性降低,往往会因为工程放置的目录长产生一些未定义错误,其中错误比较大的来源就是 Arguments Too Long,表现为:
Build operation failed without specifying any errors ;Verify final result code for completed build operation
根本原因是依赖数目过多导致编译/链接/打包流程的环境变量总数过多,从而导致命令长度超过 Unix 的限制,在构建流程中表现为各种不符合预期的错误,具体可以见https://github.com/CocoaPods/CocoaPods/issues/7383。
其实整个构建流程的环境变量主要来源于系统 和 Build Settings,系统环境一般是固定的,影响比较大的就是 Build Settings 里的配置,其中影响最大的是:
编译参数
GCC_PREPROCESSOR_MACRO 预编译宏
HEADER_SEARCH_PATHS 头文件查找路径
链接参数
FRAMEWORK_SEARCH_PATHS FRAMEWORK 查找路径
LIBRARY_SEARCH_PATHS LIBRARY 查找路径
OTHER_LDFLAGS 用于声明连接参数,包括静态库名称
一个比较直接的解决方案就是缩短工程目录路径长度来临时解决这个问题,但如果要彻底解决,还是要彻底优化 Build Setting 参数的复杂度,减少依赖数量可能会比较难,一个比较好的思路就是优化参数的组织方式。
GCC_PREPROCESSOR_MACRO,在壳工程拆分掉业务代码后,注入到 User Target 的预编译宏可以逐步废弃;
HEADER_SEARCH_PATHS 会引入所有头文件的目录作为 Search Path,这部分长度会随着 Pod 数目的增加不断增长,导致构建流程变量过长,从而让阻塞打包。我们基于 HMAP 将 Header Search Path 合并成一个来减少 Header Search Path 的复杂度。除了用于优化参数长度外,这个优化的主要用途是可以减少 header 的查找复杂度,从而提高编译速度,我们在后续的系列文章会介绍。
链接参数:FRAMEWORK_SEARCH_PATHS、LIBRARY_SEARCH_PATHS、OTHER_LDFLAGS 声明是为了给链接器提供可以查找的静态库列表。OTHER_LDFLAG S 提供 filelist 的方式来声明二进制路径列表,filelist 中是实际要参与链接的静态库路径,这样我们就可以三个参数简化为 filelist 声明,从而减少了链接参数长度。除了用于优化参数长度外,这个优化的主要用途是可以减少静态库的查找复杂度,从而提高链接速度,我们在后续的系列文章会介绍。
研发流程
新增文件
组件化的一个目标是业务代码按架构设计拆分成组件 Pod。但如果在一个组件中新增文件,比如在组件 A 中新增文件,依赖组件 A 的组件 B 是不能直接访问新增文件的头文件的,需要重新执行 Pod Install,这样会影响整体的研发效率。
为什么组件 B 不能够访问组件 A 的新增文件?在 Pod Install 后,组件 A 公共访问的头文件被索引在 Pods/Headers/Public/A/ 目录下,组件 B 的 HEADER_SEARCH_PATH 中配置了 Pods/Headers/Public/A/,因此就可以在组件 B 的代码里引入组件 A 的头文件。新增头文件的头文件没有在目录中索引,所以组件 B 就访问不到了。只需要在添加文件后,建立新增头文件的索引到 Pods/Headers/Public/A/目录下,就可以为组件 B 提供组件 A 新增文件的访问能力,这样就不需要重新 Pod Install 了。
Lockfile 生成
在依赖管理的部分场景中,我们只需要进行依赖决议,重新生成 Podfile.lock,但通过 Pod Install 生成是需要执行依赖下载及后续流程的,这些流程是比较耗时的,为了支持 Podfile.lock 的快速生成,可以对 install 命令做了简化,在依赖决议后就可以直接生成 Podfile.lock:
总结
CocoaPods 的整体优化方案以 RubyGem 「seer-optimize」 的方式输出,对 CocoaPods 代码 0 侵入,只要接入 seer-optimize 就可以生效,目前在字节内部已经被十几个产品线使用了:抖音、头条、西瓜、火山、多闪、瓜瓜龙等,执行效率和稳定性上都获得了明显的效果。比如抖音接入 optimize 开启相关优化后,全量 Pod Install 耗时减少 50%,增量 Pod Install 平均耗时减少 65%。
seer-optimize 是抖音 iOS 工程化解决方案 Seer 的的一部分,Seer 致力于解决客户端在依赖管理和研发流程中遇到的问题,改善研发效率和稳定性,后续会逐步开源,以改善 iOS 的研发体验。
本文转载自:字节跳动技术团队(ID:toutiaotechblog)

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论