

导读: 本次分享的主题为开放域对话系统:现状和未来。将系统地介绍开放域对话系统最前沿的技术,包括知识对话生成、基于强化学习的可控对话、大规模预训练对话模型等等,以及展开对开放域对话系统未来发展的讨论。
01 对话系统分类
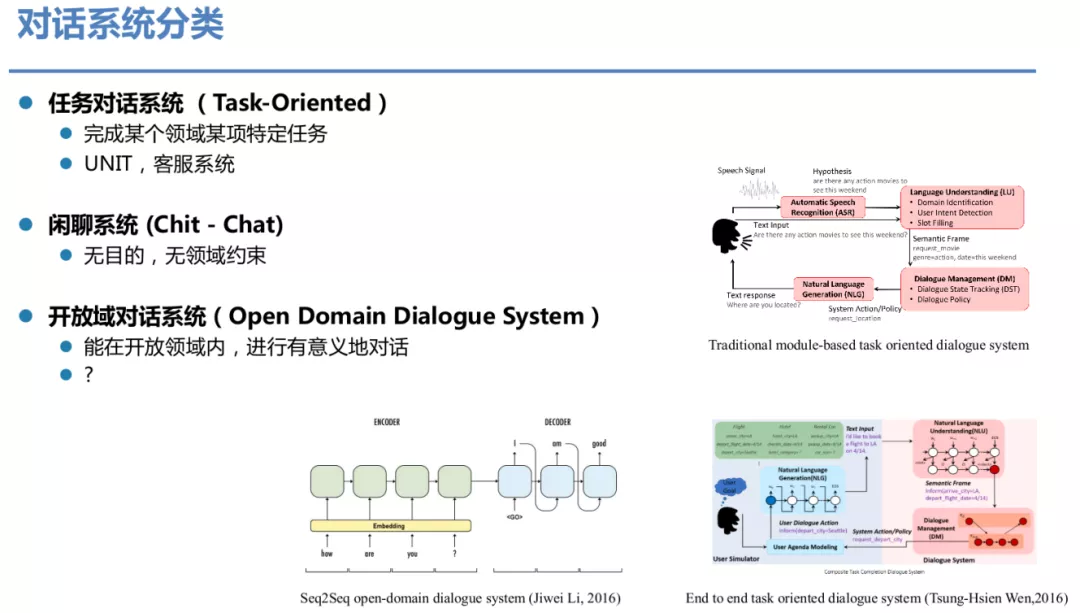
对话系统大致可分为两大类,一类为任务型对话系统,主要为了完成某个领域的某项特定任务,比如百度的 UNIT、客服系统等都属于任务型对话系统,一般采取传统的模块化的技术方案;第二类是闲聊系统,一般无目的、无领域约束。随着技术的发展,开放域对话系统也被提出了越来越高的要求,即能够在开放域内进行有意义的对话,而不是完全的闲聊。而不管是开放域的对话,还是任务型对话,通过端到端的模型建模已经越来越成为主流方案。
02 端到端对话生成
1. 对话系统的新机遇
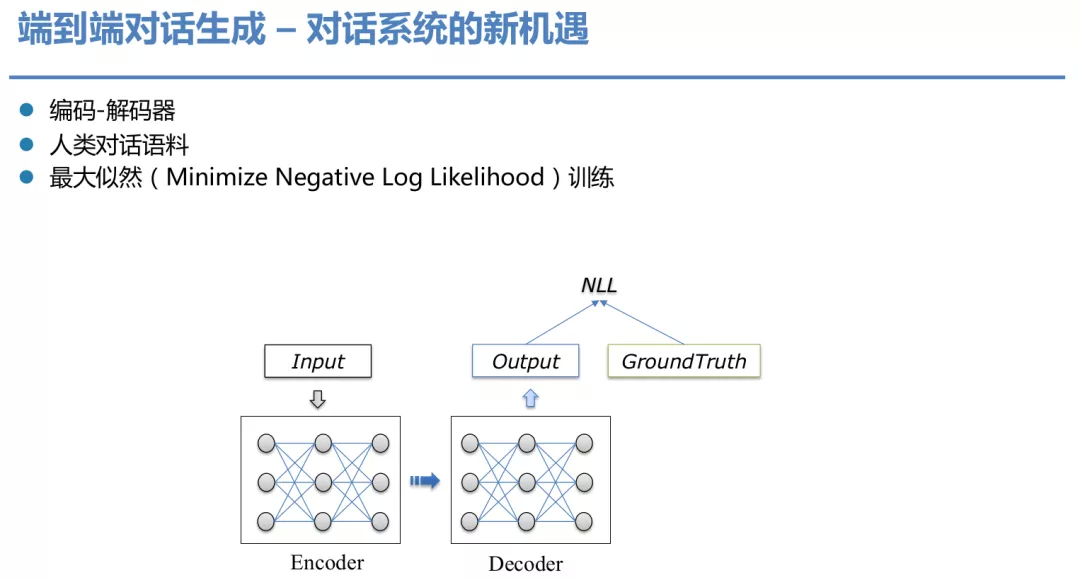
端到端的对话生成一般会有编码器和解码器,编码器输入上文信息,解码器会解码出回复 ( Response ),训练数据可以是人类对话语料,通过通过最小化预测的结果在真实标签上的似然 ( Minimize Negative Log Likelihood ) 来进行训练。
2. 端到端对话生成的挑战
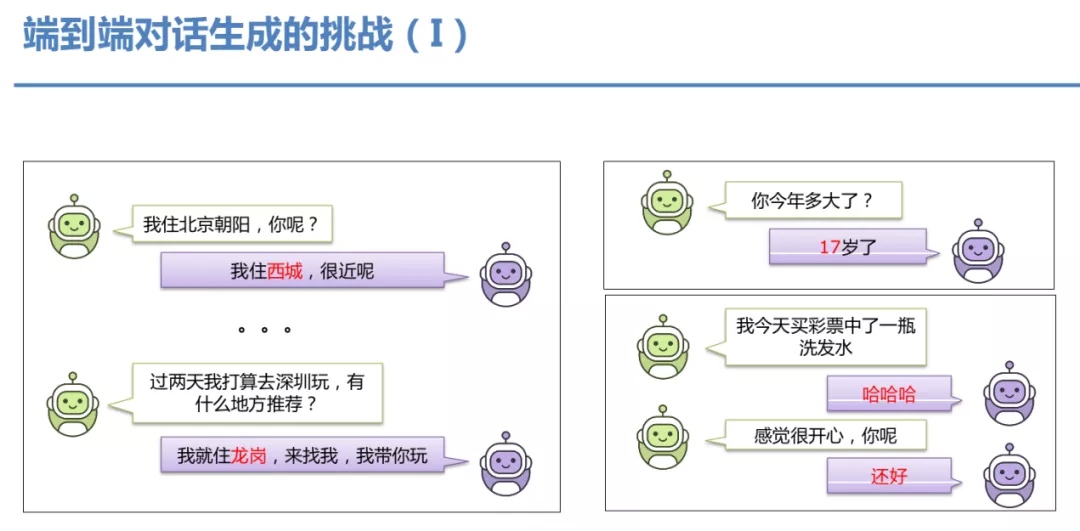
在目前的端到端对话模型中,经常出现很多 badcase:包括出现上下文逻辑冲突;背景有关的一些信息,比如年龄其实不可控;安全回复居多,对话过程显得很无聊。
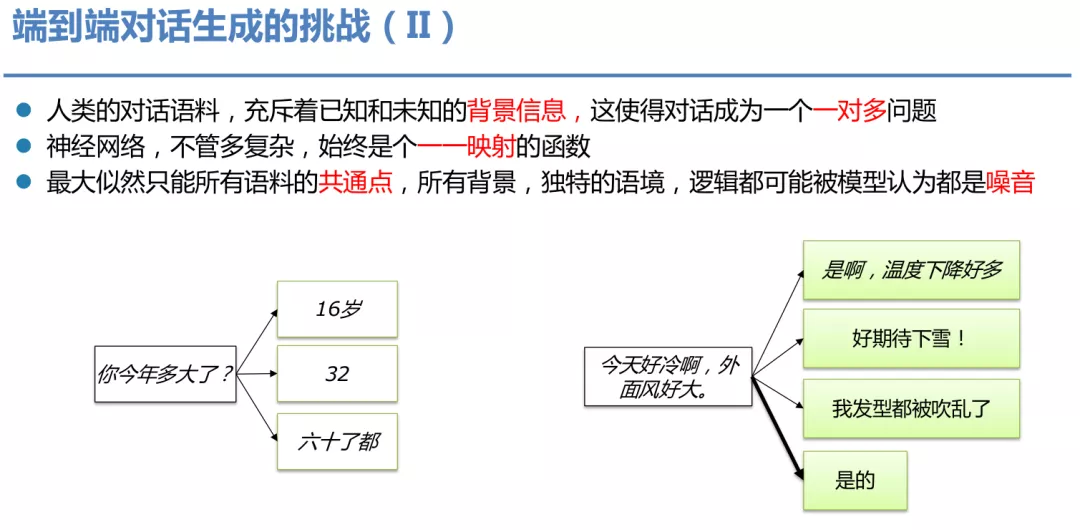
模型训练时用到的训练数据都是人类的对话语料,往往充斥着已知和未知的背景信息,使得对话成为一个"一对多"的问题,比如图中问年龄和聊天气,回答包括不同的人针对同样的问题产生的不同的回复。但是神经网络无论多复杂,它始终是一个一一映射的函数。最大似然只能学到所有语料的共通点,所有背景,独特语境都可能被模型认为是噪音,这样会让模型去学习那些最简单出现频率高的句子,比如"是的"之类的回复,我们称之为安全回复。
3. 对话语料的局限性

我们看到的对话语料只是冰山的一角,实际上对话语料中潜藏着很多个人属性、生活常识、知识背景、价值观/态度、对话场景、情绪装填、意图等信息,这些潜藏的信息没有出现在语料,建模它们是十分困难的。
03 百度 NLP:做有知识、可控的对话生成方案
接下来会围绕多样性对话生成、知识对话生成、自动化评价和对话流控制、大规模和超大规模隐空间对话生成模型 4 个模块展开。
1. 多样性对话生成
① 多映射机制的端到端生成模型
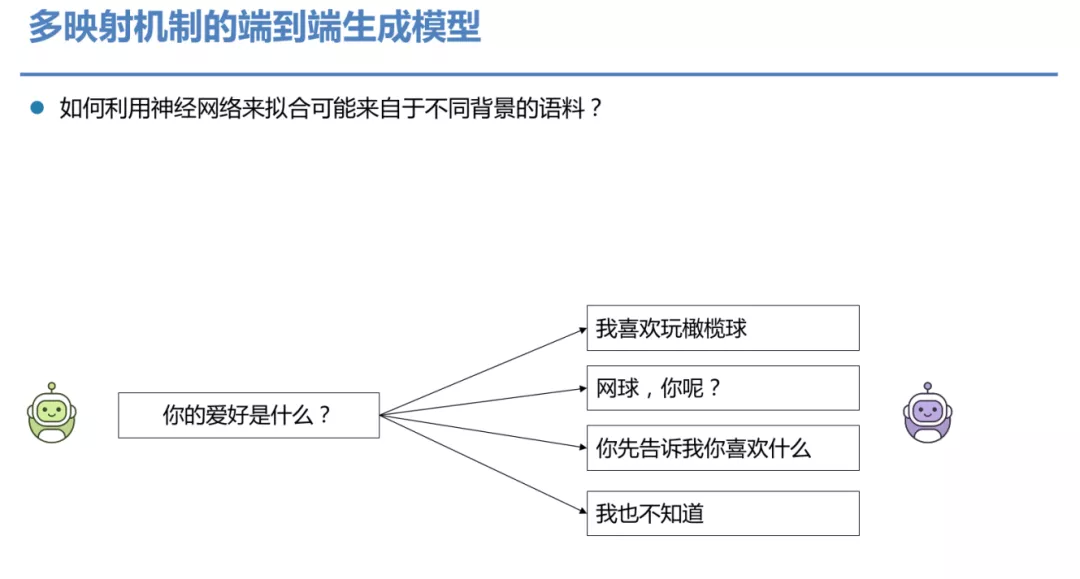
刚才提到了一对多的问题。那我们如何利用神经网络来拟合可能来自于不同背景的语料,而且能够把这些信息都捕捉下来?直接端到端的建模肯定是有问题的,因为我们刚才说了神经网络是一对一的映射。
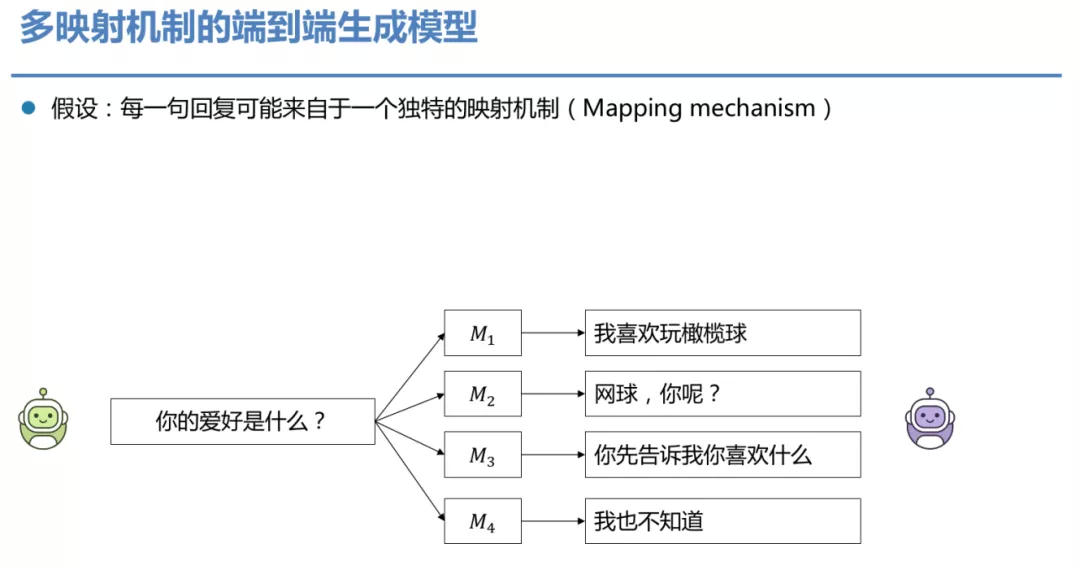
所以我们设想一种方案是每一句回复可能来自于一个独特的映射机制 ( Mapping mechanism ),这里用 M1到 M4表示。如果给定某种映射机制,就可确定最终的回复,消除了回复过程中的不确定性。
② 相关工作
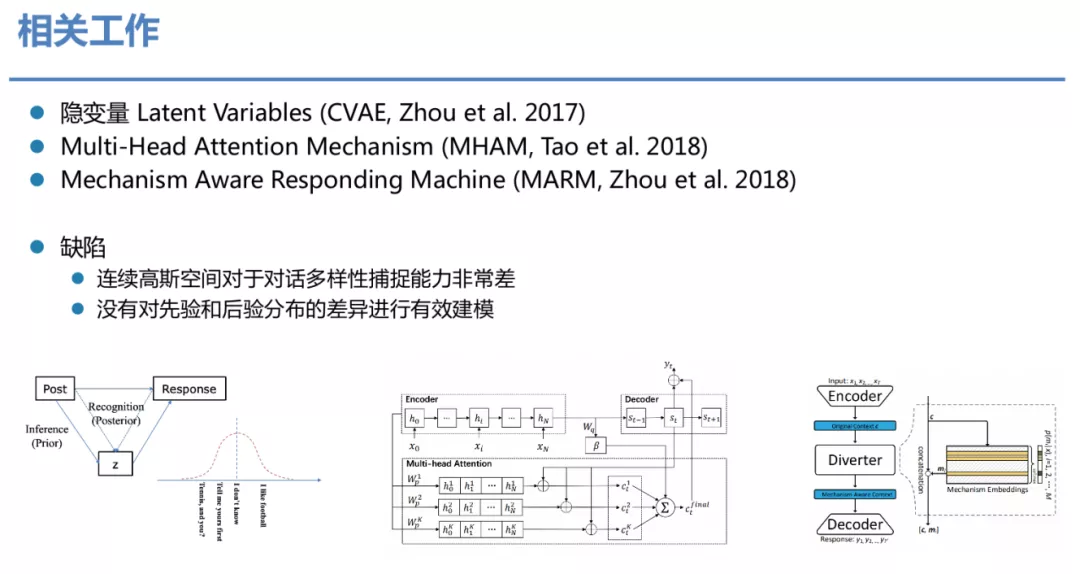
这样的类似工作也有很多,不过都存在一些弊端。比如 CVAE 用了连续的高斯空间,对于对话多样性捕捉能力非常差;而 MHAM 和 MARM 没有对先验和后验的分布差异进行有效的建模。
③ 问题
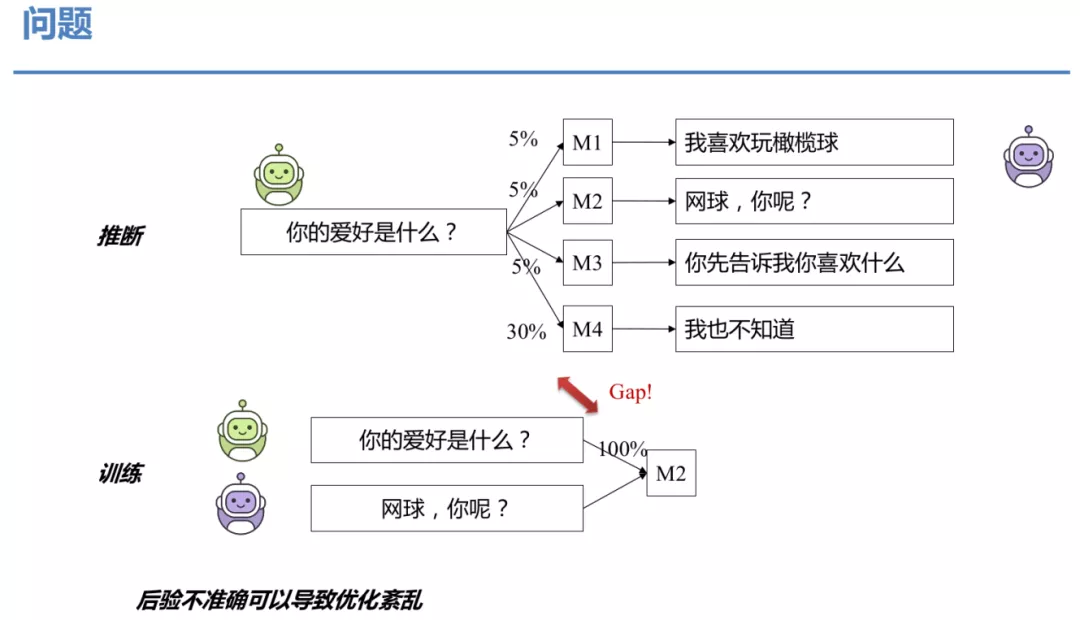
那什么是先验和后验的分布差异呢?例如,一句上文可能对应 4 种不同的回复,假设回复都是合理的。在推断时,我们有 5%的概率选择第一个,5%的概率选择第二个,5%的概率选择第三个,30%的概率选择第四个,按照概率采样,采到任何一个都是合理的。但是当我们训练时,比如这里,我们拿到的是 M2 的映射产生的回复,这时训练必须精确的选 M2,在推断和训练时对映射机制的选择是存在差异的,这会导致优化的过程乱掉。
④ 解决方案
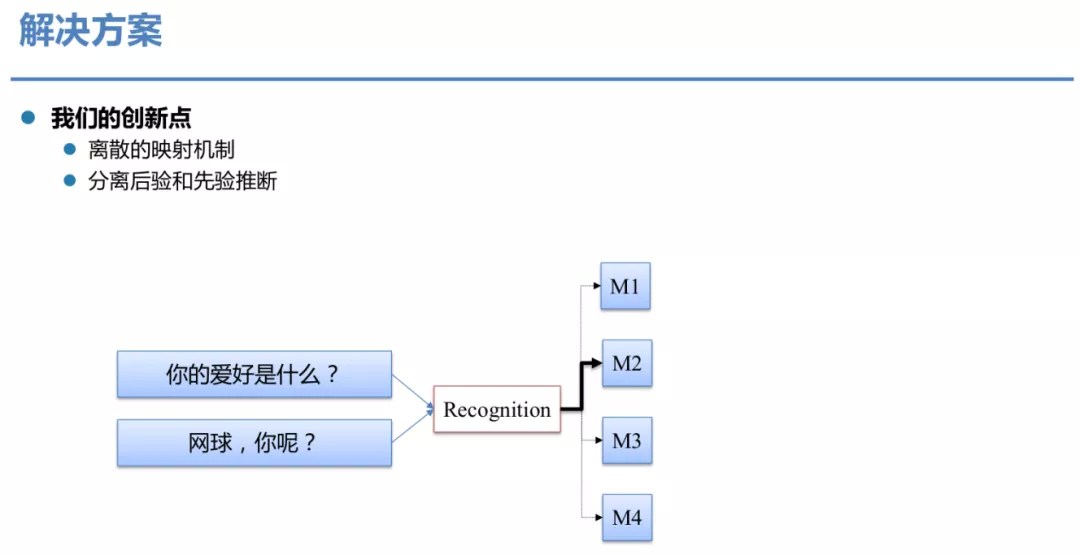
我们的创新点有两个,一是用了离散的映射机制,二是分离了先验和后验的推断。
⑤ 模型结构
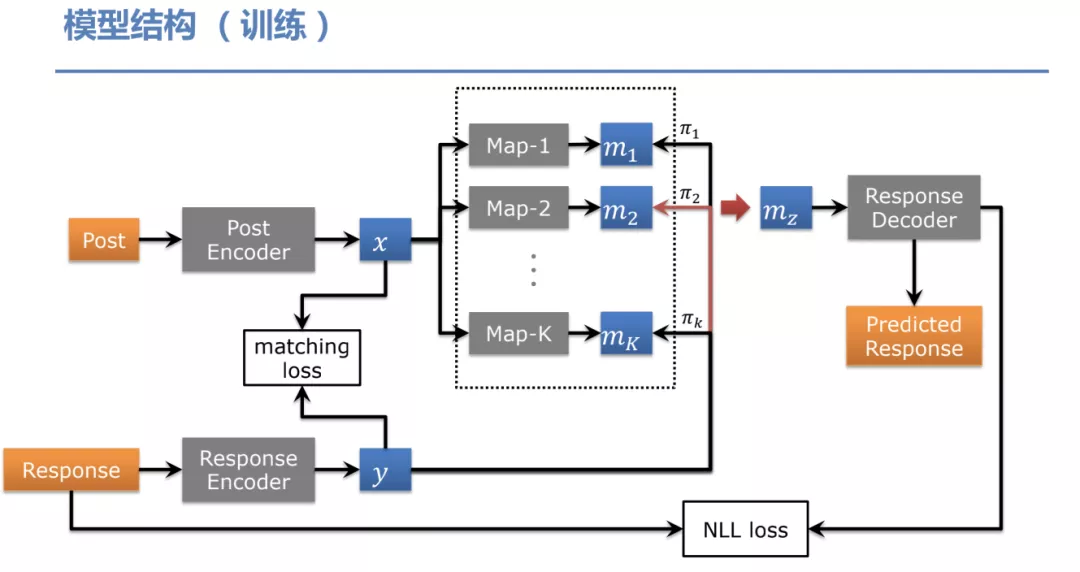
训练: 上图为训练阶段的模型结构,Post 为对话的上文,Response 为最终的回复,我们把 Post 和 Response 分别编码为两个向量 x 和 y。我们在中间加了一层多映射机制,就是图中的 Map-1 到 Map-K。这 K 个映射机制有不同的参数,我们通过 Gumbel-Softmax 来选择映射机制 M。这个采样过程我们使用了 Response,我们称为后验选择。然后我们把选择的 mapping mechism 用来生成我们的回复。在训练过程中,我们除了用 NLLLoss ( negative log likelihood loss ) 外,还用了一个 matching loss,这个 loss 的目标是为了辅助整个后验选择网络的训练,特别是 Response encoder 这一块。
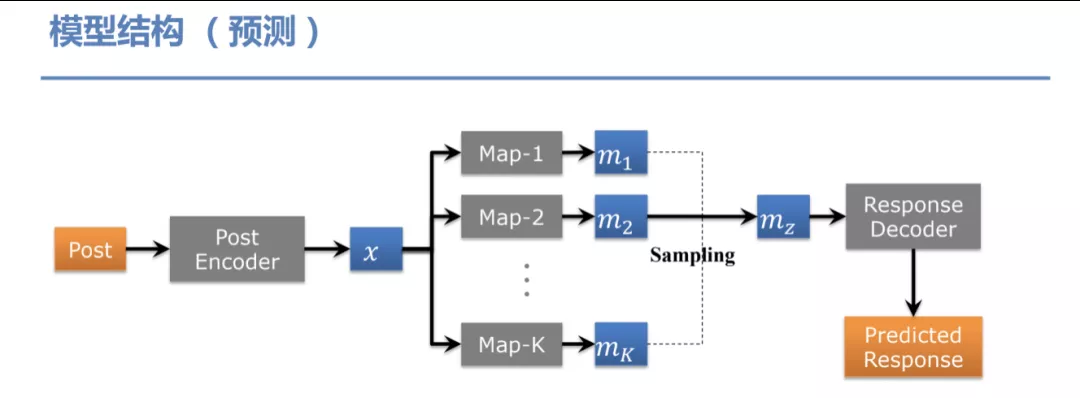
预测: 在推断时模型结构有部分差异,因为在推断时是没有 Response 的,这时我们就任意选择一个 Map 来生成回复。
⑥ 实验结论
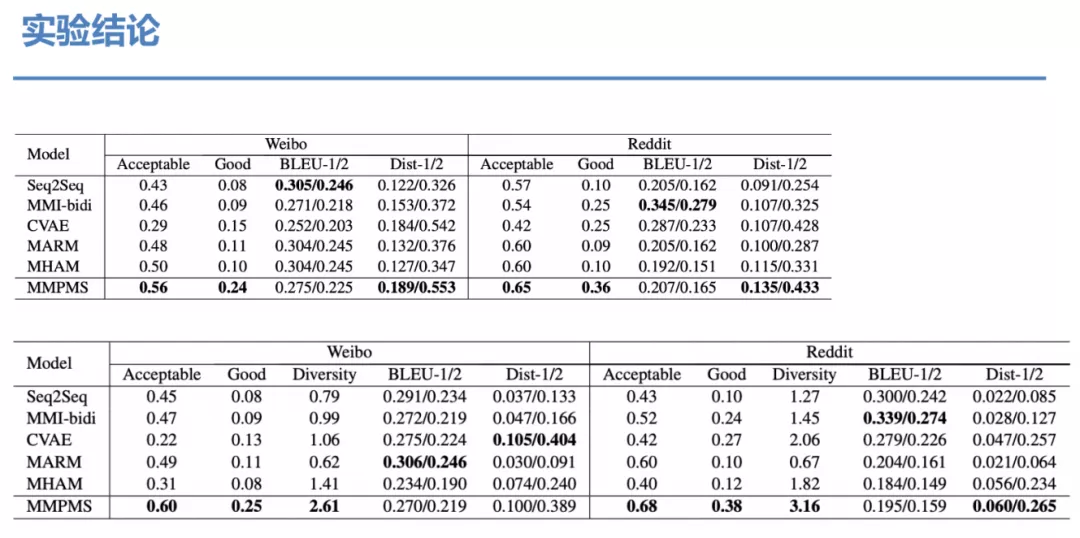
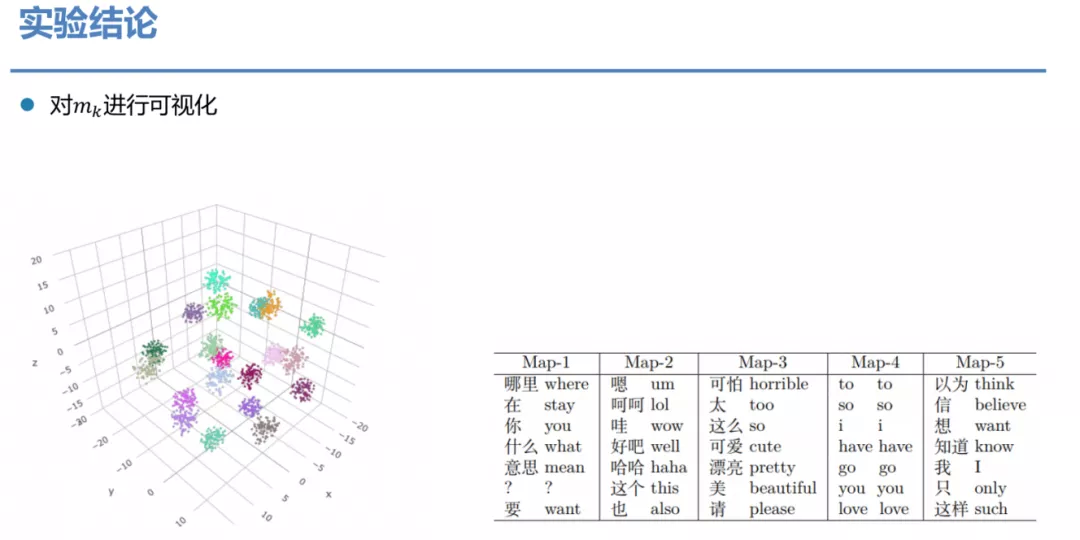
如果我们对中间的产生的隐状态 mk进行可视化会发现其实不同 Map 会有区分非常明显。每一个 Map 都有自己独特的功能,学到了语义空间上的多样性。
⑦ 更多问题需要解决

上述模型虽然解决了一部分多样性问题,但还是存在上下文重复,逻辑冲突不一致的问题。
2. 知识对话生成
① 知识引入
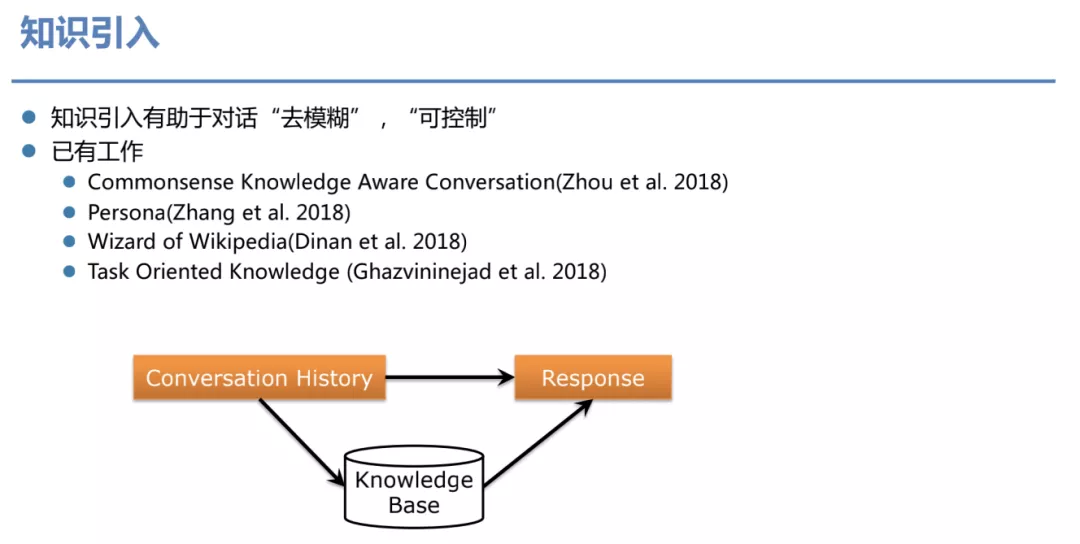
通过知识引入有助于对话"去模糊"、“可控制”。
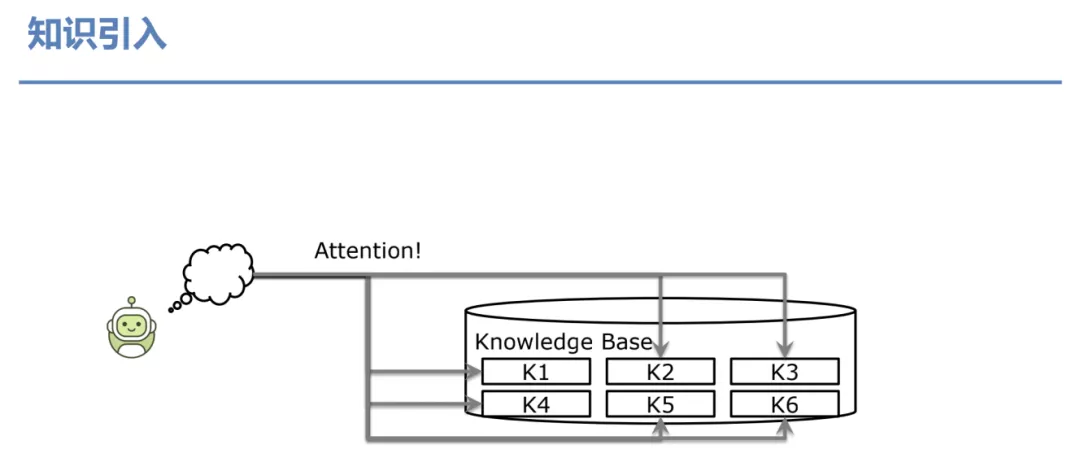
在基于知识的对话系统中,假设我们有一个 Knowledge Base,里面有很多条知识,但是我们只会选择其中的部分知识来用,所以常规做法是引入 attention 来进行知识的选择。
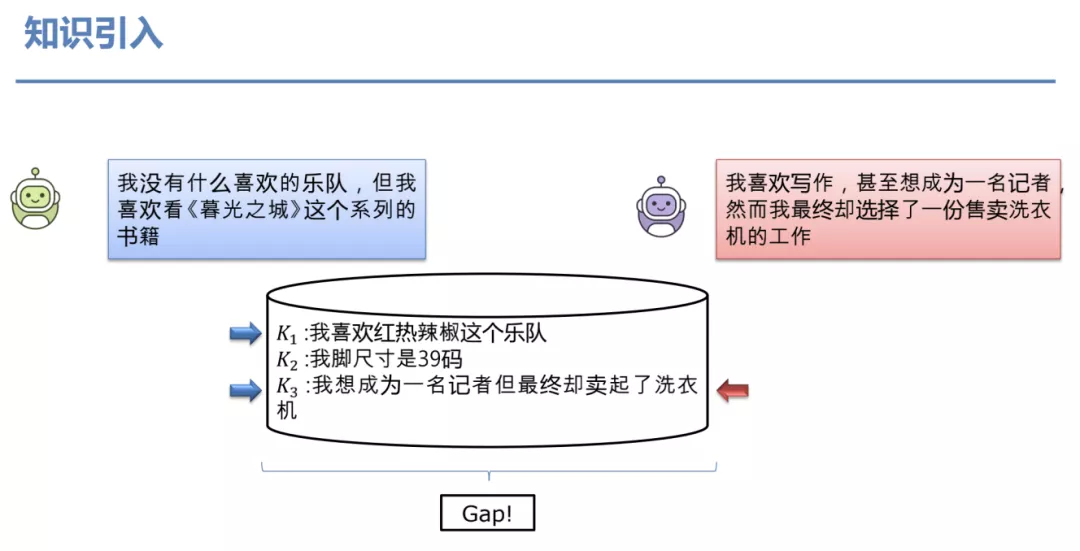
但是这类方法存在一些问题,如图所示,给了 3 个知识 K1、K2和 K3。针对机器人的问题进行回复时,我们发现 K1和 K3是相关的,K2是不相关的,因此,选择 K1和 K3都是没有问题的。但是如果针对当前这条特定的回复可以看到它明确地只用了 K3这条知识。所以这里再一次的,inference 和 training 存在一个 gap,而之前的工作是没有考虑这个差异的。
② 模型方案
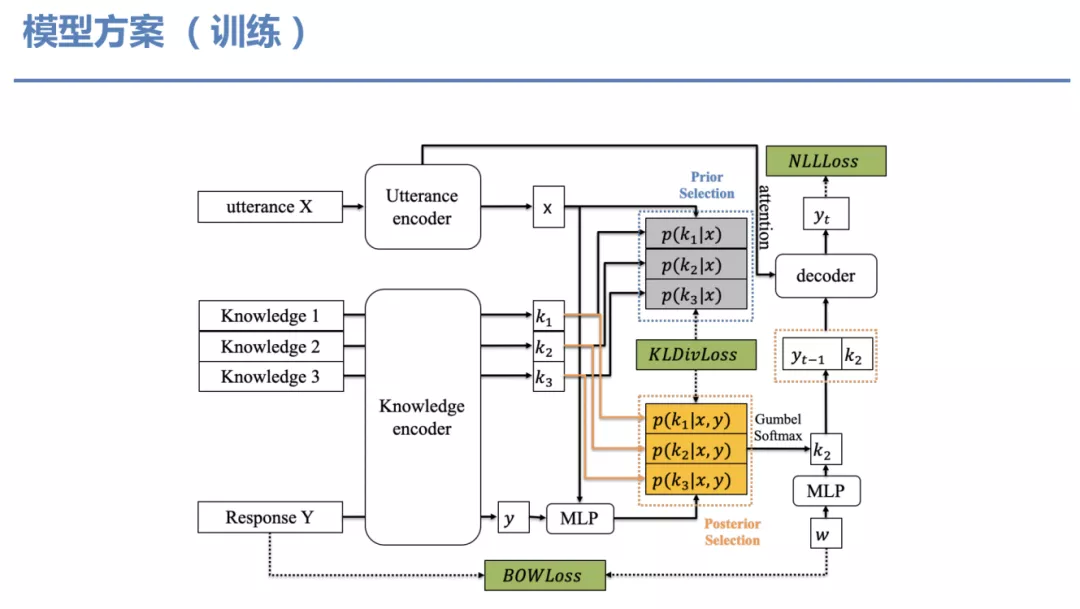
训练: 为了解决这个问题,这是我们的模型方案。输入对话上文 X 和回复 Y 分别被编码为 x 和 y,Knowledge 也编码成对应的表示 ( k1 ,…, kn )。灰色和黄色都是对知识的选择权重,也就是 attention,灰色框叫做 Prior Selection,它只基于输入的 x 来做选择。橙色框的叫 Posterior Selection,它同时基于回复和上文做选择。我们引入了几个 loss,除了 NLLloss 之外,我们还引入了 KLDivloss,是因为我们想把 Prior Selection 和 Posterior Selection 之间的距离拉近,除此之外,我们还引入了一个 BOWLoss,这是为了加速整个模型的收敛。
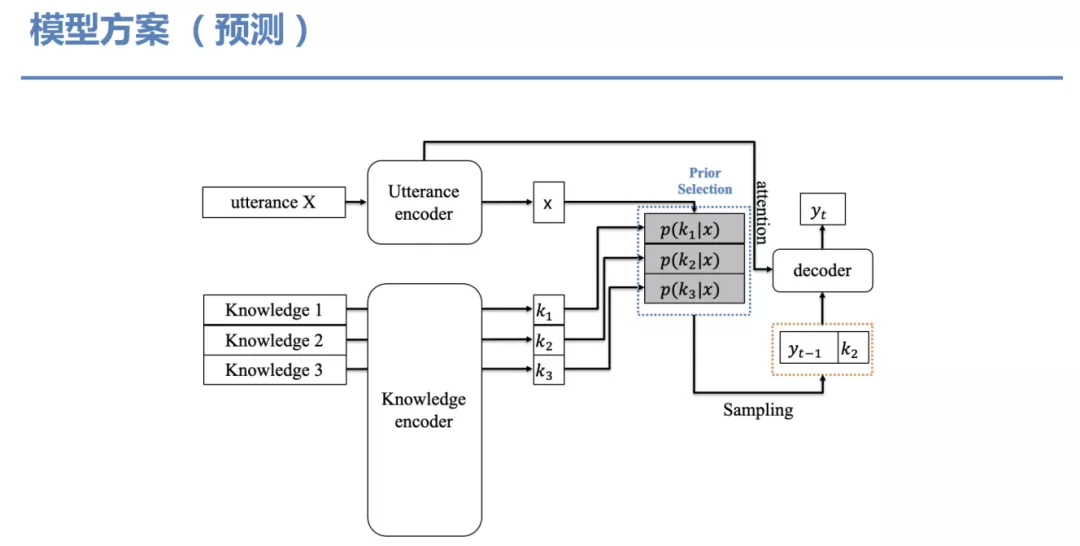
预测: 在推导过程就没有回复的输入和 Posterior 选择了,这时仅基于 Prior 选择权重进行采样。
③ 案例展示

改进之后模型效果更好,句子也更加通畅。
3. 自动化评价和对话流控制
① 自进化对话系统 ( SEEDS )
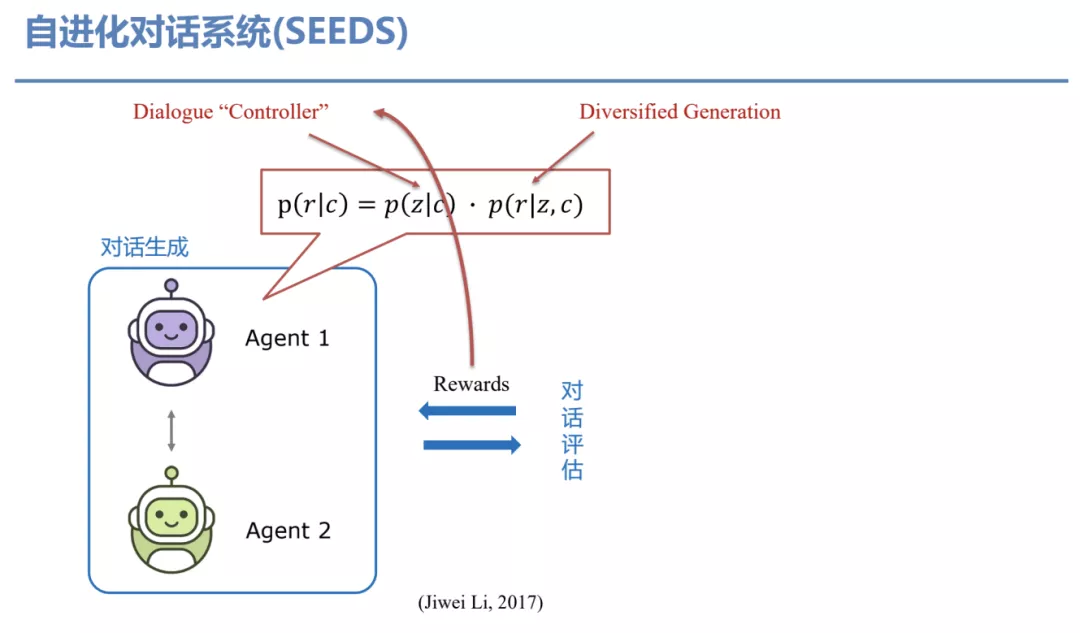
前面都是监督学习范畴,但监督学习只能考虑当前一轮的回复,所以当不同 Agent 在进行交流时我们会发现很多问题,这些问题的原因是因为在数据中没有见过这些信息。因此,我们能否考虑利用长远的反馈信息来提升对话的控制?我们基于刚刚讲到的多样化生成理论,它包含两部分。一部分是 Diversified Generation,它是根据特定知识或隐空间生成回复的过程;另一部分是 Dialogue “Controller”,也就是怎么去选择知识或者隐空间而不是仅仅依赖于 Prior?在这个工作里,我们通过强化学习来提升选择知识或者隐变量的能力。但是,一个比较难的问题是 Rewards 是从哪来?
② 自动化的对话评价体系
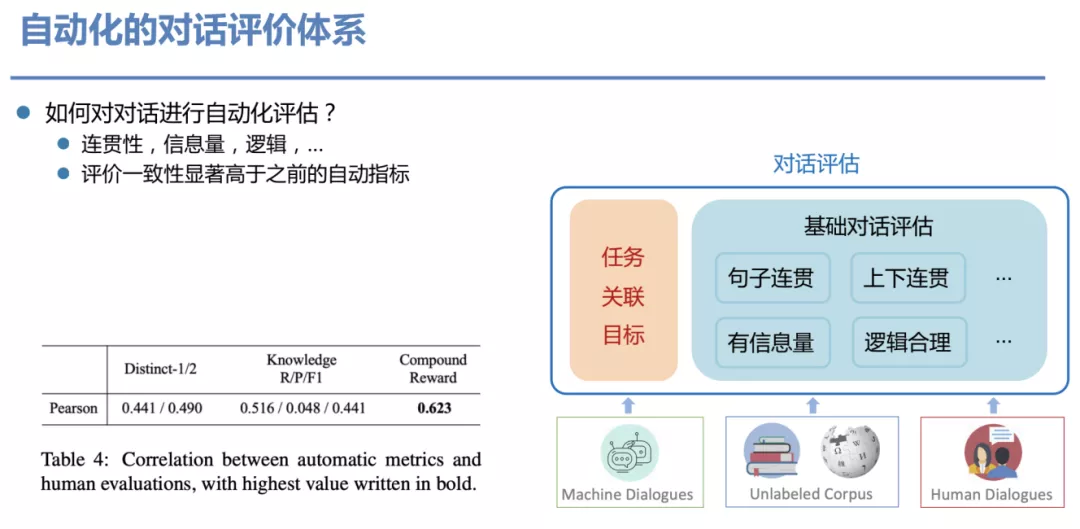
上面这个问题,可以归结为:如何对一段对话进行自动化评估?我们从连贯性、信息量、逻辑等角度用一系列模型去评价这些对话,我们为此建立了一系列模型。这些模型是根据 dialog 和无监督语料训练出来的,从图中的表格可看出,模型的指标即表里的 Compound Reward 高于之前一些自动化的指标。
③ SEEDS 效果
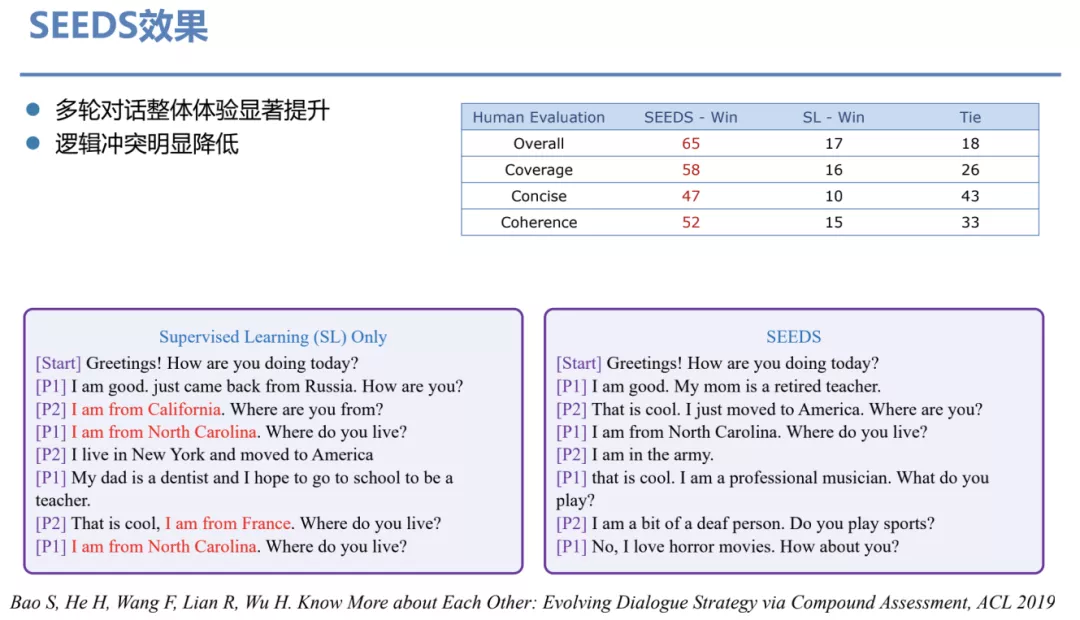
这样的一套评价流程我们又反过来用做 reward 来优化对话策略的控制,带来的效果是多轮对话整体体验显著提升、逻辑冲突明显降低。
4. 大规模和超大规模隐空间对话生成模型
① 自然语言处理模型的近期趋势

近些年来我们看到 NLP 出现了一种趋势,像 BERT 这类的预训练模型参数不断的增大,但这不是单纯炫耀算力的过程,参数增大给理解和生成带来了明显的效果,尤其为生成类任务带来了质变。
② 使用隐空间的对话模型 PLATO

我们去年底发布的隐空间 PLATO,该模型的特点是基于前面提到的隐空间的机制,来使得 Transformer 模型生成的对话丰富度要更丰富。
③ PLATO 模型结构和训练流程
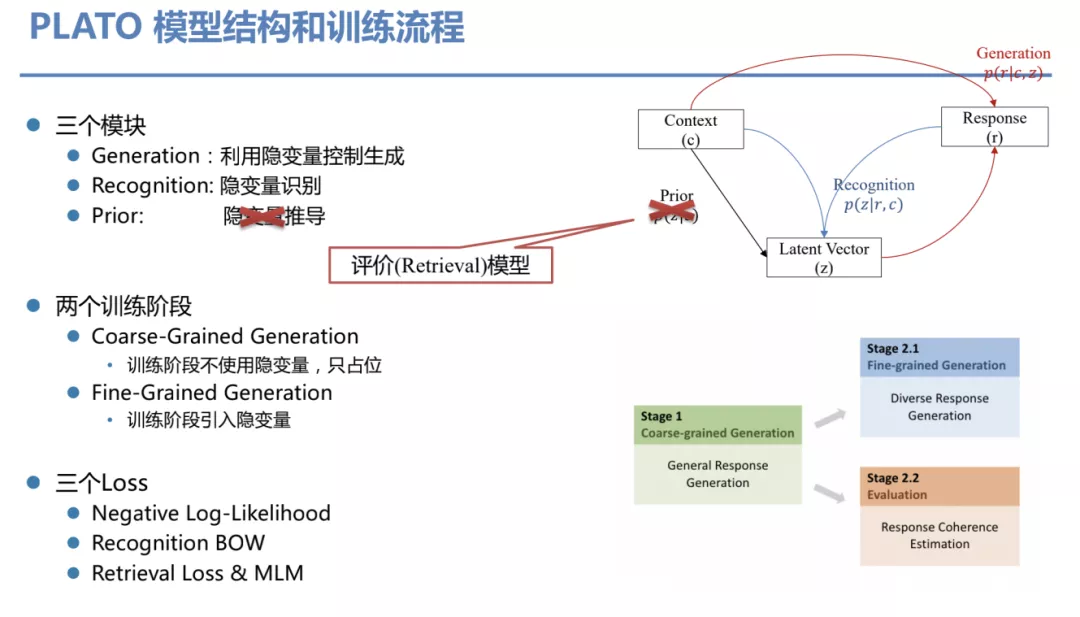
它是怎么实现的?PLATO 模型总共由三个模块组成,Generation ( 利用隐变量控制生成 )、Recognition ( 隐变量识别 ) 和 Prior ( 隐变量推导 )。而我们 6 月份提出的 PLATO2 的一个相对 PLATO 的改进则是没有使用 Prior 模块,因为实验发现用一个 Retrieval 模块来代替 Prior 模块效果会更好。PLATO2 有两个训练阶段:一个叫 Coarse-Grained Generation,即先训练一个基础版网络,没有用隐变量。之后基于这个网络我们再进一步训练,叫做 Fine-Grained Generation,引入隐变量等信息。训练时用到了三个 Loss,前面讲过,此处不再赘述。
④ PLATO 全貌
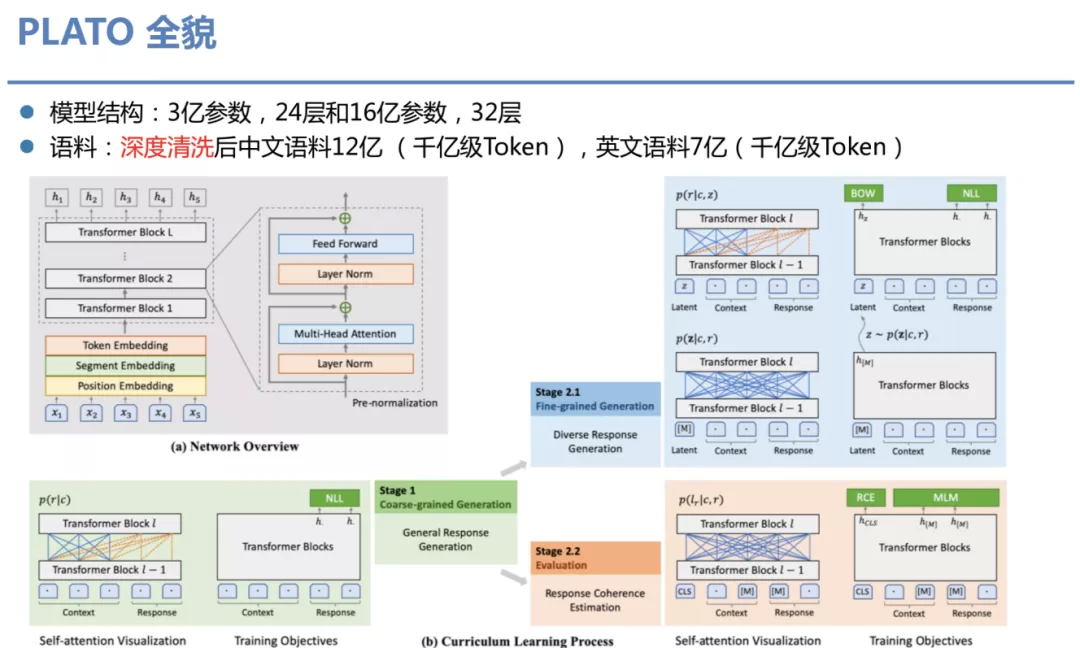
该图为 PLATO 模型全貌,我们发布了两个版本,分别为 3 亿参数 24 层的模型和 16 亿参数 32 层的模型。语料用的是深度清洗后的中文语料 12 亿,英文语料 7 亿,token 数据基本在千亿级。网络整体骨架参考了 GPT-2 并行了改进优化,使用了 Pre-normalizaion, Context 用了双向 attention,Response 用了单向 attention,既不同于 GPT-2 的纯单向,也不同于 Alexa 的 encoder-decoder 结构,更像 UniLM 结构,蓝色是 Generation,橙色是 Evaluation。
⑤ PLATO 评估结论
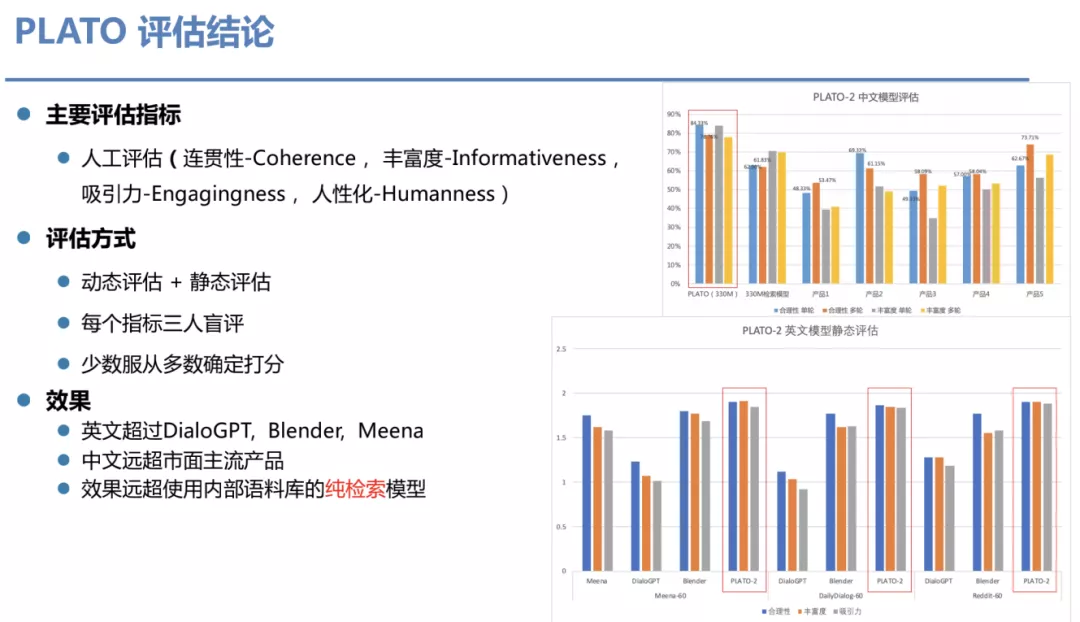
评估方法使用了静态和动态两种评估方式。静态评估指的是把多轮对话的语料从某个位置截断,然后让模型来生成一轮回复,并人工比较生成回复和原来回复。动态评估则是人或机器跟机器去对话很多轮。每个指标都采用三人盲评,从 4 个指标去评估,少数服从多数打分。上图中的静态结果,PLATO 稳步超越其他方法,并且参数量小于其他模型。与百度内部的纯检索技术相比,生成效果也已显著更高。
⑥ PLATO 文章和代码

⑦ PLATO-2 Case 展示

PLATO-2 有非常好的常识理解和话题引导能力

PLATO-2 的古诗歌词能力,在没有干预的前提下

PLATO-2 的数学题能力
04 开放域对话系统的未来
我们说,尽管近期对话生成取得了非常多进展,但对话系统通过图灵测试还为时尚早,这里指的图灵测试,不是机器对话然后人去判断是否是专家还是机器产出的对话,而是专家直接去有目的地对话机器然后挑毛病。所有的系统目前还经不起这样的测试。
这里我想说的一个观点,当我们谈论对话,我们可能在谈论 AGI,正因为对话底下潜藏的各种背景知识,信息和逻辑,仍然远超目前所有模型的能力。
我认为,未来解决对话问题的要素可以从以下方面入手:
语料 & 知识, 这是训练任何模型的基础
记忆 & Few-shot Learning, 人类是能够在对话中不断学习的,一个好的对话系统需要具有这种能力
虚拟环境 & Self-Play, 当前很多语料不能提供足够背景知识的前提下,虚拟环境能很好地提供这一点
今天的分享就到这里,谢谢大家。
作者介绍:
王凡,百度主任架构师
王凡,2012 年加入百度,现任百度自然语言处理部主任架构师,负责在线学习、前瞻对话等技术方向工作,将强化学习技术广泛落地到百度搜索、信息流、地图等核心业务。带队两次获得 NuerIPS 强化学习赛事国际冠军,在 ACL、IJCAI、KDD 等国际会议发表多篇论文。曾获百度最高奖,百度骄傲最佳个人。
本文来自 DataFunTalk
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论