

数据中台最早是阿里提出的,但真正火起来是 2018 年,我们能感受到行业文章谈论数据中台的越来越多。大量的互联网、非互联网公司都开始建设数据中台。为什么很多公司开始建设数据中台?尽管数据中台的文章很多,但是一千人眼里有一千个数据中台,到底什么是数据中台?数据中台包含什么?
2017 年开始,当网易严选有了一定量的数据,我们就开始规划建设我们的数据中台,目前我们已经完成了数据中台体系的搭建,我将根据我们建设数据中台的经验和方法论试图解答上面这些问题。
为什么大家开始建设数据中台?
2018 年开始,朋友圈里讲数据中台的文章开始逐渐变多,当然拿着手机看世界并不一定看到真实的世界。我也跟各个行业的一些大公司的 CIO 交流,发现很多行业的大公司都开始组建大数据团队,建设数据中台。结合文章和交流获取的信息,我切身感受到宏观经济对技术的影响。2018 年开始经济下行,生意不好做了,粗放的经营已经不行了,越来越多的企业想通过数据驱动来进行精细化的运营和数据化转型。
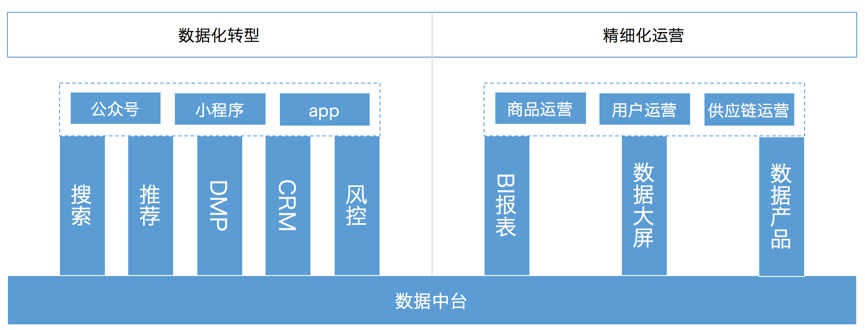
如上图所示,企业需要数字化转型,需要更多的触点去跟自己的用户/客户建立联系,很多企业就需要做自己的公众号、小程序(各家的小程序)甚至 app。我们希望用户更容易找到我们的商品/服务,我们就需要搜索。我们希望用户更多的浏览/使用我们的商品/服务就需要推荐。我们维护用户/客户的生命周期,根据生命周期采取不同的营销动作,就需要 CRM。我们需要拉来更多的新用户,就需要投放广告,为了更好的投放效果,我们需要建设我们的 DMP。当我们生意做大,我们需要对抗黑产(羊毛党),让我们的优惠能让真正的用户享受,我们需要风控。这一切都需要底层大数据的支持。
企业需要精细化运营,就需要不断的提升运营的频次(如下图所示)和粒度。我们需要把运营的节奏提升到周级、天级甚至实时。我们随时随地了解我们企业经营状况,需要不断的更精细(细粒度)的分析我们的业务,快速做出业务决策。我们就需要能够快速地构建大量的 BI 报表,在一些重要的节点(大促)时,甚至需要盯着数据大屏。如果我们有能力,还可以建设场景化的数据产品来支持业务的决策。这一切都需要底层大数据的支持。
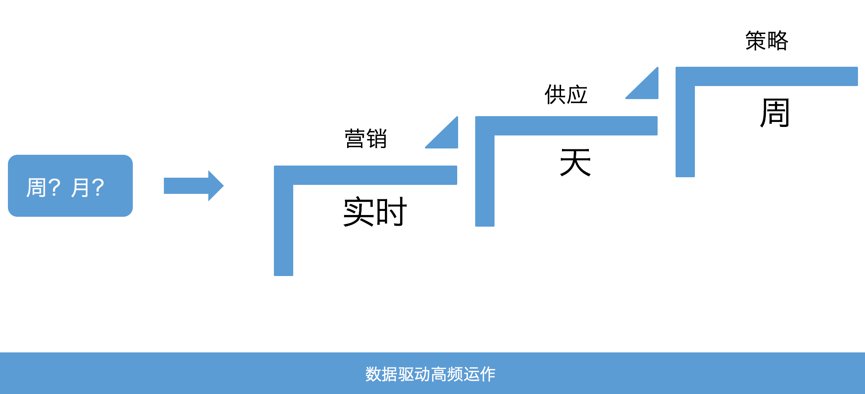
如何快速地利用底层大数据的支持,让我们的数据化转型、精细化运营能够高频的迭代,这就需要我们的数据中台提供强有力的支持。
这里也提醒一点,当我们需要大规模的数据应用时(搜索/推荐/BI 报表…),我们才需要构建数据中台。因为建设数据中台的投入大。打个比方,当我一家人要吃饭,我自己买菜,在自己的厨房用普通的厨具自己做就好了,如果是富士康,几万几十万人吃饭,就需要建食材的加工配送中心(类比数据中台)。本质上是“需求规模量级的变化,导致解决方案的质变”。所以我们看到的,基本是大公司在建设数据中台。尽管你们可能现在不适合建设数据中台,但数据中台的思想大家都可以借鉴。
小结一下,当企业需要数据化转型、精细化运营,进而产生大规模数据应用需求的时候,就需要建设数据中台。
什么是数据中台?
这是一个千人千面的问题。我们的定义是“数据中台是高质量、高效赋能数据前台的一系列数据系统和数据服务的组合”。因为规范最终是在系统和服务中落地的,所以定义中就没有包含规范部分。
数据中台的核心职责是高效地赋能数据前台为业务提供价值。要想理解数据中台先要理解数据前台,上文说到的搜索、推荐、BI 报表、数据大屏等都属于数据前台。我们来看下面网易严选数据体系的图就更清楚数据中台的定位了。
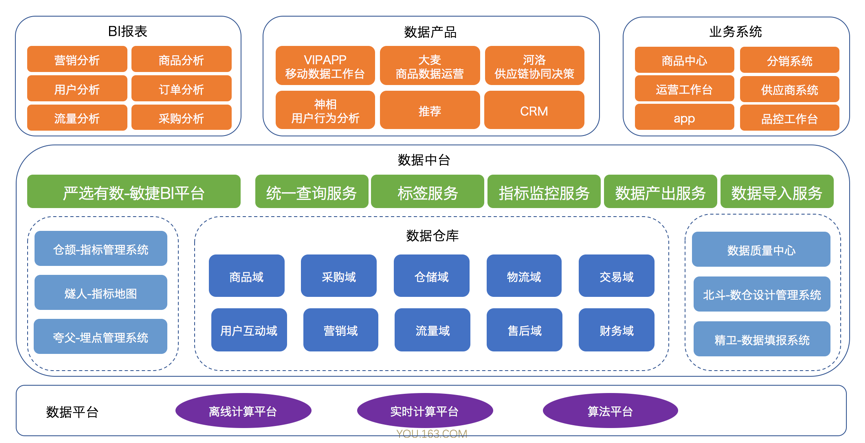
数据中台的下层是数据平台,数据平台主要解决跟业务无关的问题,主要是大数据的存储和计算问题。
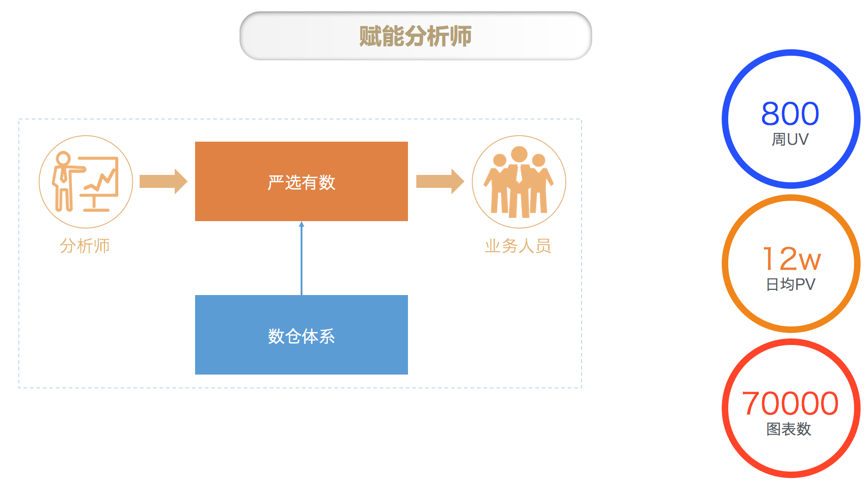
数据中台的上层就是数据前台,主要包括 BI 报表、数据产品和业务系统。数据中台首先赋能分析师通过 BI 报表的形式来驱动业务精细化运营。如下图所示,基于数仓里已经半加工好的数据,分析师使用严选有数敏捷 BI 平台可以快速的根据业务需求进行数据可视化和数据分析。严选有数现在每周的 UV 超过 800,每天报表浏览次数超过 12w,目前的图表数超过 7W。对于一个事业部级的 BI 平台,应该算是一个非常好的成绩。这里特别感谢下我们的分析师团队,她们的辛勤工作才会有这样的成绩。
数据中台还会赋能业务系统开发通过统一查询服务(主要是统一查询服务和标签服务)来辅助业务过程中的决策。基于数仓里面加工好的数据模型,业务系统开发人员使用统一查询服务获取到的模型数据在业务系统中增加辅助决策功能。比如供应商系统需要对供应商进行评级,供应商评级需要供应商的商品销售数据、评论数据、退货数据、质量数据,供应商采购的交期数据等等。数仓会根据这些数据加工模型,供应商系统可以通过统一查询获取模型在供应商系统中使用。在严选,统一查询服务已经接入了 67 个应用、670 个模型、每天有 300w 的调用。
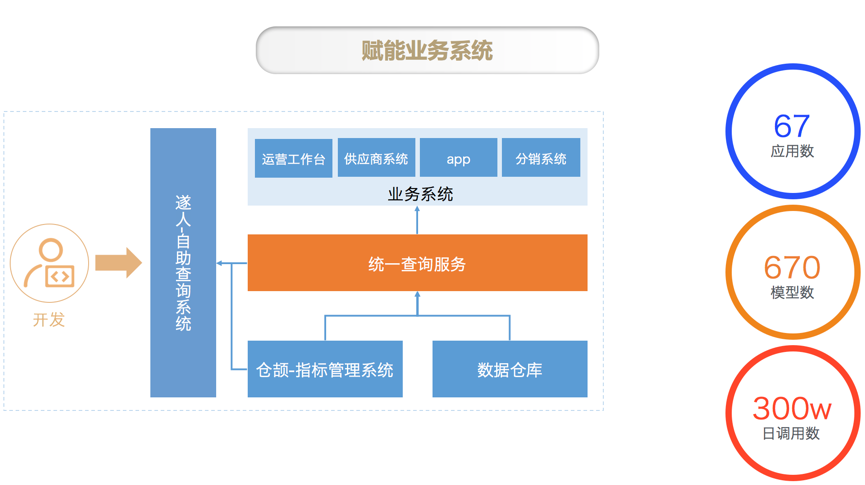
我们自己做的数据产品(如下图所示),基本会用到我们数据中台所有的能力支持,包括统一查询服务、标签服务、指标监控服务、数据产出服务等数据服务,也会使用严选有数创建 BI 报表挂载到数据产品中。
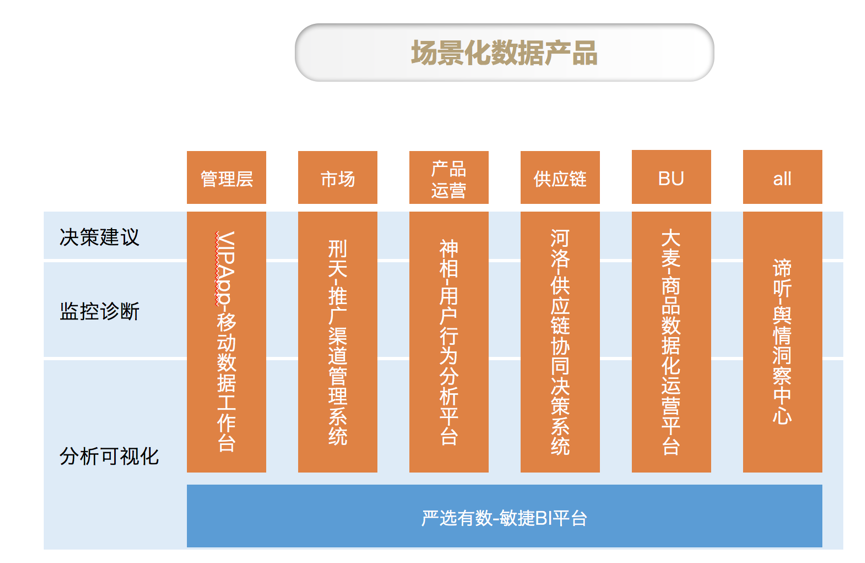
数据中台包含什么?
从上文的图中,我们已经初步了解了数据中台包含了哪些系统和服务。概括来说,数据中台包含数仓体系、数据服务集和 BI 平台。
数仓体系
数仓体系是数据中台的核心,数据是新能源,是生产资料。数仓体系包含数仓和一系列的管理系统,用来管理数据,保证数据的完整、一致和准确。数仓体系的构成和关系,如下图所示。数仓是数仓体系的核心,也是整个中台的核心。数仓的开发和存储,主要依赖网易猛犸数据平台(希望详细了解的,可以搜索网易猛犸)。
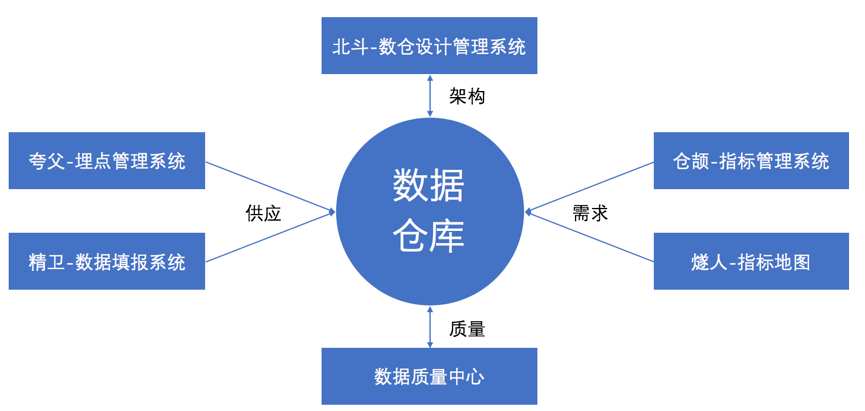
夸父-埋点管理系统和精卫-数据填报系统从供应侧保障数据的完整性和质量。埋点数据由于来源广(web 端、ios、android、小程序等)、链路长、格式(日志的 scheme 约束)等问题,一直是数据质量的重灾区。夸父-埋点管理系统提供了埋点的管理、埋点流程协同和埋点测试,提供了埋点日志的 scheme,保障了埋点数据质量。精卫-数据填报系统提供数据导入数仓及导入时的验证功能,提升数据的完整性。整个电商的业务过程非常多,所有业务过程都线上化的过程非常漫长。当我们下游的数据应用需要某个业务过程的数据,而这个业务过程还没有线上化时,就可以通过精卫-数据填报系统导入数据到数仓,下游就可以使用这份数据。
仓颉-指标管理系统和燧人-指标地图是从需求侧提升数据(指标)的一致性。仓颉-指标管理系统顾名思义是管理指标定义,在提供指标统一管理的同时,提供了指标定义规范的约束。数据开发可以根据指标定义里的指标口径来进行指标开发。燧人-指标地图是提供给业务方查看当前的指标分类与指标定义。
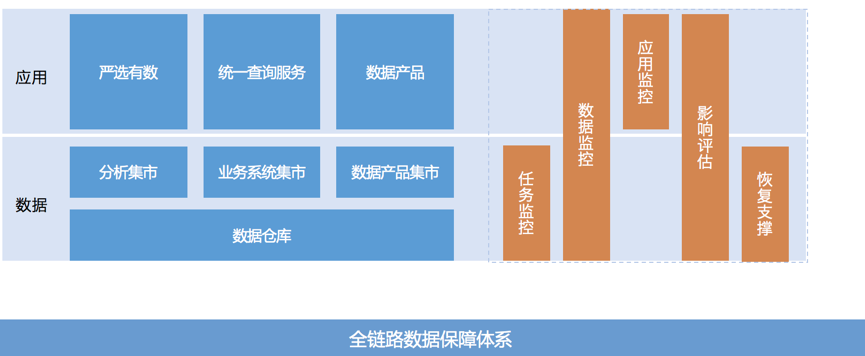
数仓开发本身要解决的核心问题是质量和效率(所有开发也都需要解决),无论是质量和效率都需要好的架构设计。北斗-数仓设计管理系统就是来完成数仓设计。数仓的开发原本总是非常的经验化,很多知识都是存在数据开发的脑子里。我们通过北斗-数仓设计管理系统来推行数仓先设计再开发,通过北斗-数仓设计管理系统将数仓开发的经验知识化、标准化、工具化。数据质量中心(如下图所示)提供全链路的数据保障体系,提供任务监控、数据监控、应用监控、影响范围评估和恢复的支撑。
数据服务集
数据服务主要是数据场景下的解决方案的沉淀。数据服务集极大的加速了数据应用开发效率。核心的数据服务是统一查询服务和标签服务,提供指标模型和标签模型对数据应用系统(业务系统和数据产品)的统一配送。统一查询服务核心提供表转接口和数据网关的功能。数仓管理的是数据模型表,通过统一查询,数据应用系统就可以通过接口的形式来访问数据模型表。统一查询服务是数据体系和数据应用系统之间的总网关,需要提供模型级限流、熔断等网关功能。
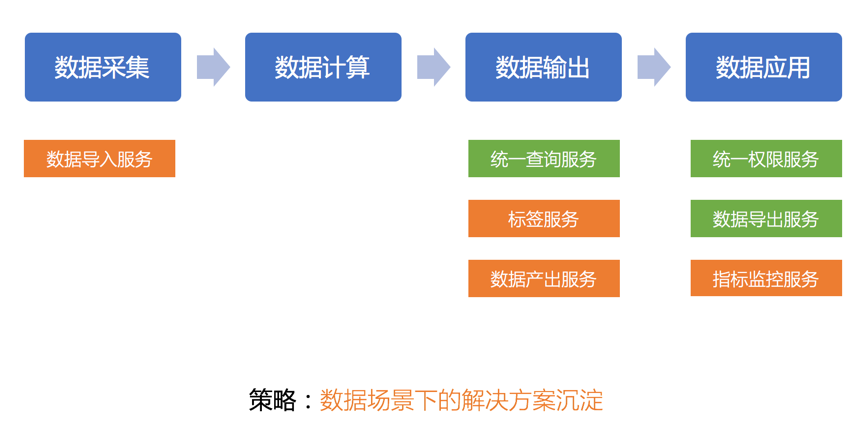
BI 平台
BI 平台我们用的是严选有数,也就是在网易有数在严选的版本。网易有数是一款敏捷 BI 平台,在设计上通过以终为始的设计理念和类 PPT 操作模式,在保障灵活性的基础上,提供了极大的操作便利。想进一步了解的,可以搜索网易有数。
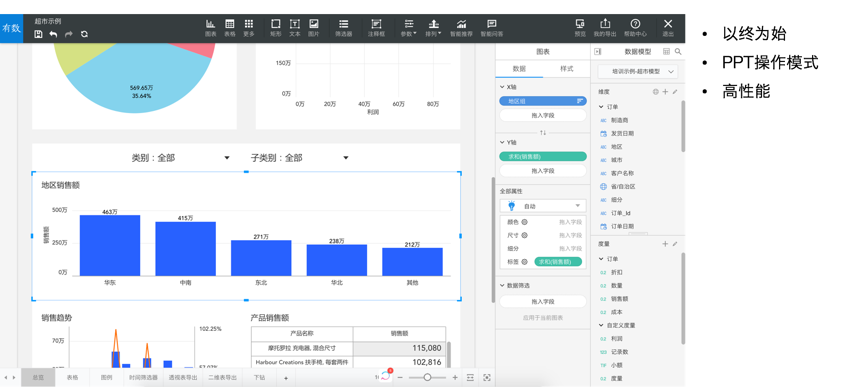
在性能方面,我们结合数据产出服务做的基于数据产出的缓存策略极大地提升了报表的性能。图表首访缓存命中率基本稳定在 100%,整体缓存命中率超过 80%。
数据中台的内容非常长,本文非常概括的从严选实践介绍了数据中台。总结一下:当企业需要数据化转型、精细化运营,进而产生大规模数据应用需求的时候,就需要建设数据中台。数据中台是高质量、高效赋能数据前台的一系列数据系统和数据服务的组合。数据中台包含数仓体系、数据服务集和 BI 平台。
作者简介:
魏文庆,现任网易严选数据技术及产品部总监。2007 年浙江大学计算机硕士毕业后入职网易杭州研究院,从事前端开发,后历任技术主管、技术经理、技术总监。曾负责网易摄影、网易企业邮箱、易信公众号等产品开发,以及网易前端微专业。2015 年开始内部创业,孵化敏捷 BI 平台-网易有数,任网易有数总经理,负责产品研发和商业化。2017 年开始负责网易严选数据技术及产品部,从 0 到 1 搭建网易严选数据中台和数据产品体系。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论