

上一篇文章《数据库恢复子系统的常见技术和方案对比(一)》中,我们基本介绍了数据库管理系统中的 Logging & Recovery 恢复子系统,详细讨论了基于 Physical Logging 的主流恢复算法 ARIES 的概念和技术实现。本文将华师大宫学庆教授关于介绍 Logical Undo Logging 的原理以及两种数据库系统 SQL Server(Azure)和 Silo 的恢复技术的介绍分享给大家。
Logical Undo Logging
在上篇文章中,我们简单介绍了 Early Lock Release 的优化思路:通过将索引上的 Lock 提前释放以提高并发程度,但同时会在事务之间产生依赖关系,导致级联回滚。比如第一个事务已经释放锁,但在刷日志时出现故障需要回滚,此时锁已被下一个事务获得,那下一个事务要和前面的事务一起回滚,极大地影响系统性能。
基于这样的情况,恢复系统中引入了 Logical Undo Logging,在一定程度上解决了上述问题。Logical Undo Logging 的基本思想是在事务回滚时撤销修改操作,而不是对数据的修改,如插入的撤销是删除,对数据项+1 的撤销是对数据项-1。
此外处理 Logical Undo 时引入了 Operation Logging 的概念,即记录日志时对事务一些操作采用特殊的日志记录方式,称为 Transaction Operation Logging。当 Operation 开始时,会记录一条特殊的 Operation Logging,形式为 log<Ti, Oj, operation-begin>,其中 Oj 为唯一的 Operation ID。在 Operation 执行过程中,系统正常进行 Physical Redo 和 Undo 日志记录;而 Operation 结束后,则会记录特殊的 Logging <Ti, Oj, operation-end, U>,其中 U 便是对于已经进行的一组操作的 Logical Undo 操作。
举例来说,如果索引插入新键值对(K5, RID 7)到叶子节点 Index I9,其中 K5 存储在 Index I9 页面的 X 位置,替换原值 Old1;RID7 存储在 X+8 位置上替换原值 Old2。对于该事务,记录日志时会在最前面添加操作开始记录<T1, O1, operation-begin>,中间 Physical Logging 正常记录数值的更新操作,结束时记录结束日志<T1, O1, operation-end, (delete I9, K5, RID7)>,其中(delete I9, K5, RID7)是对 T1 操作的 Logical Undo,即删除 I9 节点页面的 K5 和 RID7。
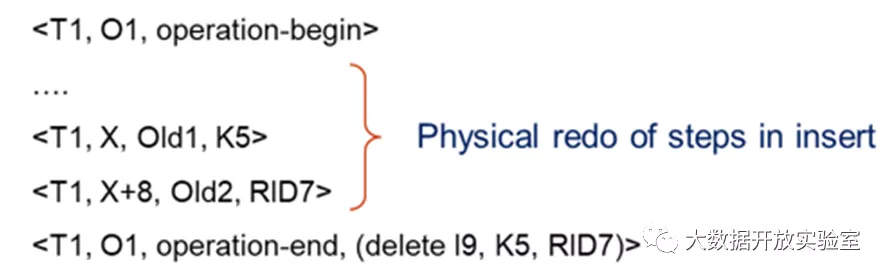
在 Operation 执行结束后,可以提前释放锁,允许其他事务能成功向该页面插入< Key,Record ID>,但导致所有 Key 值重新排序,使得 K5 和 RID7 离开 X 和 X+8 的位置。此时如果进行 Physical Undo,需要将 K5 和 RID7 从 X 和 X+8 撤回,但实际中二者的位置已发生改变,按原日志记录进行 Physical Undo 并不现实。但从逻辑上看,Undo 只需要把 K5 和 RID7 从索引节点 I9 删掉即可,因此在日志中加入操作日志(delete I9, K5, RID7),表示如果进行 Undo,只需要按照这个逻辑指令进行即可。
在回滚时,系统对日志进行扫描:如果没有 operation-end 的日志记录,则进行 Physical Undo,这是因为只有在 Operation 结束时才会释放锁,否则就说明锁还没有被释放,其他事务不可能修改其锁定的数据项。如果发现存在 operation-end 日志,说明锁已经被释放掉,此时只能进行 Logical Undo,把 begin operation 和 end operation 之间的所有日志跳过,因为这些日志的 Undo 已被 Logical Undo 替代。如果在 Undo 时发现了<T,O, operation-abort>日志,则说明这个 Operation 已经 Abort 成功,可以直接跳过中间日志,回到该事务的<T, O,operation-begin>继续往上 Undo;当 Undo 到<T,start>的日志时,表明该事务的全部日志均已经撤销完成,记录<T, abort>日志表示 Undo 结束。
其中需要注意的是,所有 Redo 操作都是 Physical Redo,这是因为 Logical Redo 的实现非常复杂,例如需要决定 Redo 顺序等,因此大多数系统里所有的 Redo 信息都是 Physical 的。此外,Physical Redo 和锁提前释放并不冲突,因为 Redo 只有在出现故障时才会进行,此时系统挂掉导致所有的锁已经都没有了,重做的时候要重新申请锁。
SQL Server:Constant Time Recovery
对于大多数商业的数据库系统如 SQL Server 等,大多采用 ARIES 恢复系统,因此 Undo 所有未 Commit 事务的工作量与每个事务所做的工作内容成正比。事务做的操作越多,Undo 所花费的时间就越长。因为事务操作可能是一条语句但更新很多记录,Undo 就需要对记录逐条撤销,导致撤销时间可能过长。虽然正确性得到保证,但对于云服务或者对可用性要求高的系统将难以接受。为了应对这种情况,出现了 CTR 优化技术(Constant Time Recovery),将 ARIES 系统和多版本并发控制相结合,实现固定时间恢复。固定时间恢复是指不管遇到什么情况,都利用数据库系统中的多版本信息,保证恢复操作在确定的时间内完成。其基本思想是利用多版本数据库系统中的不同数据版本,确保数据 Undo 到一个正确的状态,而不是用原来 WAL 日志里的信息进行恢复。
MS-SQL 的并发控制
SQL Server 在 05 年开始引入了多版本并发控制,但早期多版本仅用来实现 Snapshot 隔离级别而非恢复,支持系统根据 Snapshot 的时间戳去读数据库中的数据。在更新数据时,多版本并发控制可以在数据 Page 上对记录进行就地更新,但旧版本没有丢掉,而是被单独放在 Version Store 中。Version Store 是一个特殊的表,只允许不断的添加数据(Append-Only),通过指针链接指出该记录的老版本,老版本又会指向上一个更老的版本,进而构成一个数据版本链。在访问数据时,可以根据事务的时间戳来决定读取哪个版本数据。因此,早期多版本 Version Store 的更新并不需要记录日志,因为一旦出现故障,重启以后所有时间戳都是最新的,只要保持最后一个版本即可,不会有比这个版本更早的 Snapshot 访问需求。对于当前 Active 的事务,可以根据当下时间戳,通过 Garbage Collection 机制将老版本丢弃。
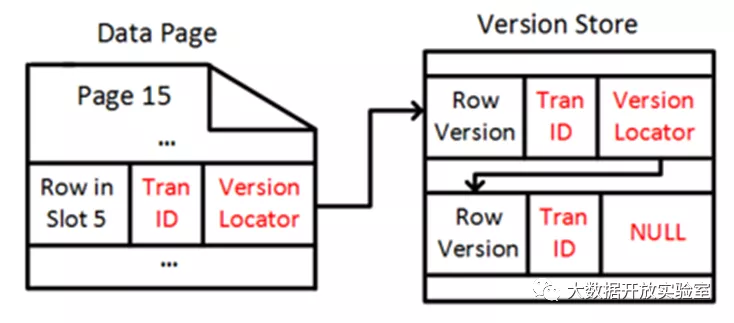
CTR 基于原 Version Store 进行优化,实现了 Persistent Version Store,使得旧版本能够持久化存储。在 CTR 技术下,系统更新 Version Store 时会记录日志为恢复进行的准备,使得 Version Store 的体量和开销变大,于是出现两种实现老版本存储的策略 In-Row Versioning 和 Off-RowVersioning。
In-Row Versioning 是指对于更新一条记录的操作,如果只是改动很小的数据量,就不需要放进 Version Store 存储,而是在记录后加一个 delta 值,说明属性的数值变化。其目的是为了降低 Versioning 时的开销,因为同一个位置改动的磁盘 I/O 相对较小。
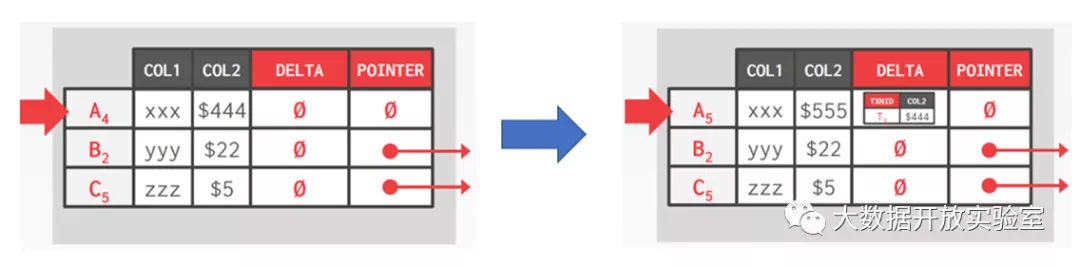
Off-Row Versioning 则有一个特殊的系统表,用来存储所有表的老版本,通过 WAL 记录 Insert 操作的 Redo 记录。当修改量较大导致 In-Row Versioning 无法完全保存数据更新时,便采用 Off-Row Versioning 方式。如下图中,A4 行的 Col 2 为 444,在更新为 555 后会写入一个 delta,用于记录版本变化。但这种修改受限于数据量的大小,以及记录本身所在的页面上是否有空闲空间。如果有空闲空间就可以写入,若没有就需要把更新的记录放入 Off-Row Versioning 表中。
恢复过程中,CTR 分为三个阶段实现(Analytics、Redo 和 Undo)。分析阶段和 ARIES 类似,用来确定每一个事务的当下状态如 Active、Commit 和需要 Undo 的事务。在 Redo 时,系统会把主表和 Version Store 的表重放一遍,都恢复到出现 crash 的状态。Redo 完成后,数据库就可以上线对外服务。CTR 的第三步是 Undo,在分析阶段结束后,已经知道哪些事务未提交,Undo 阶段可以直接将这些事务标记为 Abort。由于每条 Record 的不同版本都会记录与该版本相关的事务号,因此后续事务在读到该版本时,首先判断相关事务的状态,如果是 Abort 就忽略掉该版本而读上一个旧版本。这样的恢复方式使得在读到不可用版本时,需要根据链接去找前一个版本,虽然会带来额外性能开销,但减少了数据库的下线时间。在继续提供服务后,系统可以在剩下时间进行 Garbage Collection,将失效老版本慢慢清除,这样的机制叫做 Logical Revert。
Logical Revert
Logical Revert 有两种方式。第一种是用后台进程 Background Cleanup 把所有数据块扫描一遍,判断哪些是 Garbage 可以回收。判断条件为:如果主表中最后一个版本来自于已经 Abort 的事务,那就从 Version Store 里拿上一个已经 Commit 的旧版本放到主表。即使此时不做这件事情,后面使用数据时也是会到 Version Store 中读数据。因此,可以通过后台的 Garage Collection 进程,慢慢进行版本搬迁。第二种是如果事务在更新数据时,发现主表里的版本是 Abort 的事务的版本,就会覆盖该版本,而此时这个事务的正确版本应该在 Version Store 中。
可以看到,CTR 的恢复是一个固定时间,只要前两个阶段结束即可,而前两个阶段所需时间实际上只与事务的 Checkpoint 有关。如果做 Checkpoint 的间隔是按照固定的日志大小决定,当 Redo 阶段结束,数据库便可以恢复工作,且恢复时间不会超过一个固定值。
Silo:Force Recovery
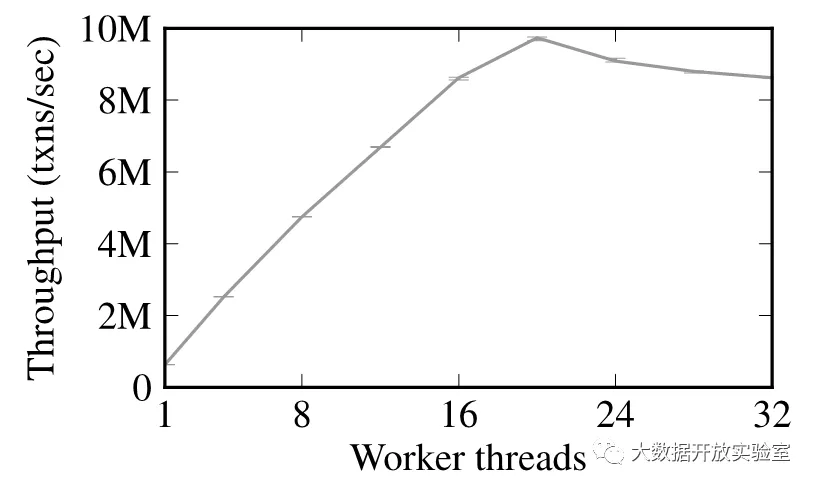
Silo 是哈佛大学和 MIT 合作研究的一个高性能内存数据库系统原型,解决了并发程度过高导致的吞吐率下降问题。如果一个 CPU 内核对应一个线程来执行事务,在不存在竞争的情况下,吞吐率随着核数增加而增加,但高到一定程度后会出现下降,可能的情况是因为出现了某些资源竞争所导致的瓶颈。尽管在事务执行过程中每个线程单独执行,但最终所有事务在提交前都需要拿到事务 ID,事务 ID 是全局范围的,事务通过原子性操作 atomic_fetch_and_add(&global_tid)获得 commit 时的 ID。而事务 ID 的分配通过全局的 Manager 角色实现,在事务申请 ID 时,Manager 会通过计数+1 来更新事务计数器,保证事务 ID 的全局唯一且递增,因此 Manager 写操作的速度会是系统性能的上限。当并发越来越高且事务都去申请 ID 时,就会出现竞争关系使得等待时间变长,导致吞吐率下降。
乐观的并发控制
对于性能瓶颈问题,Silo 的解决思路是多核并发工作+共享内存的数据库里采用乐观并发控制。乐观并发控制在《内存数据库解析与主流产品对比(三)》中介绍过,指事务在执行时认为相互之间没有任何影响,仅在提交时检查是否存在冲突,如果没有冲突再去申请全局的事务 ID 完成 Commit。而 Silo 通过设计 Force Recovery 取消了所需的全局事务 ID,使用 Group Commit 的概念,将时间分成多个 Epoch,每个 Epoch 为 40 毫秒。Epoch 包含了当前时间段涉及的多个事务,因此可以通过提交 Epoch 的方式将这一组事务一起提交,不需要为每个事务逐一申请全局事务 ID。但这种设计的缺陷在于如果事务执行时间超过 40 毫秒,带来的跨级会对提交和恢复带来影响。
在 Silo 中,每个事务由 Sequence Number + Epoch Number 来区分,Sequence Number 用来决定执行过程中事务的顺序,通过 Sequence Number 和 Epoch Number 共同决定恢复策略。每个事务会有事务 ID(TID),事务按照 Epoch 来进行 Group Commit,整体的提交按照 Epoch Number 的先后实现序列化。事务 ID 为 64 位,由状态位、Sequence Number 和 Epoch Number 共同组成,其中高位是 Epoch Number,中间是 Sequence Number,前三位是状态位。每条记录都会保存对应的事务 ID,其中状态位用来存放访问记录时的 Latch 锁等信息,内存数据库和传统基于磁盘的 DBMS 数据库相比,其中一个重要区别就是锁的管理是和记录放在一起,并不会另外管理 Data Buffer 和 Locking Table。

事务提交的三个阶段
由于 Silo 采用标准的乐观并发控制,因此只有在提交时才会检查是否存在冲突。在 pre-commit 阶段,读数据项时会把数据项中的事务 ID 存入 Local Read-Set,随后再读取数值;而在修改数据记录时,也需要把修改的数据记录放入 Local Write-Set 里。
Silo 事务提交时分三个阶段,第一步为 Local Wite-Set 里所有要写的记录拿到锁,锁信息保存在事务 ID 中的状态位,通过原子操作 Compare and Set 获取;随后从当前的 Epoch 读出全部事务。系统里有专门线程负责更新 Epoch(每 40ms+1),所有事务不会去竞争写 Epoch Number 而只要读该值即可。事务提交的第二步是检查 Read-Set,Silo 中每个数据项都包含最后一个对其进行更新的事务的 ID,如果记录的 TID 发生变化或记录被其他事务锁住,说明从读到提交的过程中记录已经更改,需要进行 Rollback。最后是生成事务 TID,在新事务 Commit 时,TID 中的 Sequence Number 应该是一个大于所有读到的 Record 的事务 ID 的最小值,以保证事务递增。提交后只有全部事务落盘后,才会返回结果。
Recovery——SiloR
SiloR 是 Silo 的恢复子系统,使用 Physical Logging 和 Checkpoints 来保证事务的持久性,并在这两个方面采用并行恢复策略。前面提到,内存数据库中的写日志操作速度最慢,因为日志涉及写盘,磁盘 I/O 是整个系统架构的性能瓶颈。因此 SiloR 采用并发方式写日志,并存在以下假设:系统里每个磁盘有一个日志线程,用来服务一组工作线程,日志线程和一组工作线程共享一个 CPU Socket。
基于此假设,日志线程需要维护日志缓冲区池(池中有多个日志缓冲区)。一个工作线程如果要执行,首先需要向日志线程索要一个日志缓冲区写日志,写满后交还日志线程落盘,同时再获得新的日志缓冲区;如果没有可用的日志缓冲区,工作线程便会阻塞。日志线程会定时将缓冲区刷到磁盘,缓冲区空出来后,可以继续交给工作线程处理。对于日志文件,每 100 个 Epoch 生成 1 个新日志文件,旧日志文件按照固定规则生成文件名,文件名最后部分用来标识日志中最大的 Epoch Number;日志内容则记录了事务的 TID 和 Record 更新的集合(Table, Key, Old Value -> New Value)。
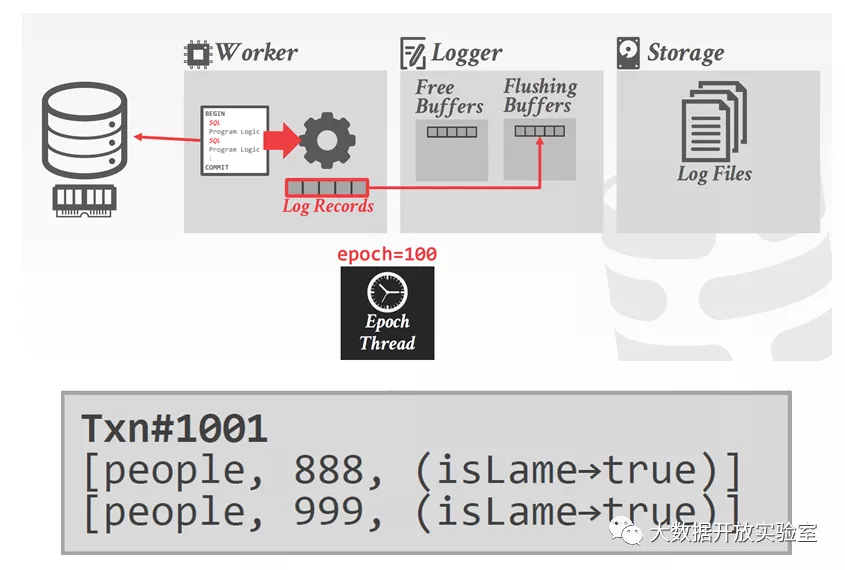
上面介绍了多核 CPU 中一个核所处理的事情,实际上 CPU 中每个核都以同样的方式工作,会有一个专用线程来追踪目前哪些日志已经全部刷到磁盘上,并把最新已经落盘的 Epoch 写到磁盘上的固定位置。所有事务通过比较自己当前的 Epoch 和已经落盘的 Persistent Epoch(以下简称 Pepoch),如果小于等于 Pepoch,表明日志已经落盘,可以向客户端返回。
恢复过程
和 ARIES 恢复系统一样,SlioR 也要做 Checkpoints。SlioR 的第一步是把最后一个检查点的数据读出再进行恢复;由于内存数据库不对索引做日志,因此索引需要在内存中重构。第二步是日志回放,内存数据库只做 Redo 不做 Undo,Redo 操作并不是和 ARIES 一样按正常日志顺序进行,而是从后向前执行直接更新到最新版本。在日志回放时,先检查 Pepoch 的日志文件,找出最新的 Pepoch 号,凡是超过该 Pepoch 号的日志记录,则认为对应的事务没有返回给客户端,因此可以忽略。日志文件的恢复采用 Value Logging,对于每条日志,检查数据的 Record 是否已经存在,如果不存在就根据日志记录生成数据 Record;如果存在则比较 Record 和日志中的 TID。如果日志中的 TID 大于 Record 中的 TID,就证明需要 Redo,用日志中的新数据值来替换旧值。可以看到,SiloR 的 Redo 不是像 ARIES 一样一步步恢复到故障现场,因为 ARIES 的目的是要将磁盘上的数据恢复到最终正确状态,而 SiloR 是要把内存当中的数据恢复到最新正确状态。
In-Memory Checkpoint
对于内存数据库,恢复系统相比磁盘 DBMS 系统较为简单些,只要对数据做日志即可,索引则不需要,且只需 Redo 日志而不需 Undo 日志。所有数据都是直接覆盖修改,不需要管理 Dirty Page,不会存在 Buffer Pool 和缓冲区落盘问题。但内存数据库仍受限于日志同步时间开销,因为日志依旧要刷到非易失性存储(磁盘)。早期 80 年代时,内存数据库的研究都是假设内存数据不会丢失,如带电池的内存(断电后还可以用电池支撑一段时间工作);还有非易失性内存 NVM(Non-Volatile Memory)等技术,但目前这些技术还远达不到普遍使用,依旧要考虑持久化存储。
持久化系统要求对性能影响最小,不能影响到吞吐量和延迟。为减少对事务执行的影响,内存数据库追求的第一目标是恢复速度,即在故障后可以最快时间内完成恢复。因此串行恢复无法满足速度要求,目前有很多研究工作都集中在对内存数据库的并行日志研究,而并行使得对于锁和 Checkpoints 的实现都变得复杂。
对于 In-Memory 的 Checkpoints,实现机制通常和并发控制紧密融合,并发控制设计决定了检查点如何实现。理想的 In-Memory 中 Checkpoints 第一个要求是不能影响正常的事务执行,并且不能引入额外延迟以及占用太多内存。
Checkpoints 种类:Checkpoints 分为一致性 Checkpoints 和 Fuzzy Checkpoints 两类。一致性 Checkpoints 指产生的检查点中的数据不包含任何未提交的事务,如果包含则在 Checkpoints 时去掉未提交的事务;Fuzzy Checkpoints 包含已经提交和未提交的事务,在恢复时才把未提交的事务去掉。
Checkpoints 机制:Checkpoints 机制分为两种,第一种可以通过开发数据库系统自身功能来实现 Checkpoint,比如使用多版本存储来做 Snapshot;第二种可以通过操作系统级别的 Folk 功能,拷贝出进程的子进程;随后把内存中所有数据拷贝一遍,但需要额外操作去回滚正在执行且还未提交的修改。
Checkpoints 内容:内容上 Checkpoint 分两种类型,一种是每次 Checkpoint 都全量拷贝数据;还有一种是增量 Checkpoint,每次只做本次与上一次之间产生的增量内容。二者差异在于 Checkpoint 时数据量以及恢复时所需要的数据量的区别。
Checkpoints 频率:有三种 Checkpoint 频率。一是基于时间的定周期 Checkpoint;二是基于固定日志的大小的 Checkpoint;最后一种是强制性 Checkpoint,如数据库下线后强制进行 Checkpoint。
本文小结
在本次两篇文章专栏中,我们对数据库系统的恢复子系统进行了介绍,分别介绍了 Physical Logging 的主流恢复系统 ARIES 和 Logical Undo Logging 的相关概念和技术实现。此外,我们介绍了两个数据库系统的恢复策略——SQL Server 的 CTR 固定时间恢复以及内存数据库系统 Silo 的 Force Recovery 恢复原理。下一讲将讨论数据库系统的并发控制技术。
参考文献
\1. C. Mohan, Don Haderle, Bruce Lindsay, Hamid Pirahesh, and Peter Schwarz. 1992. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking And Partial Rollbacks Using Write-Ahead Logging. ACM Trans. Database Syst. 17, 1 (March 1992), 94–162.
\2. Antonopoulos, P., Byrne, P., Chen, W., Diaconu, C., Kodandaramaih, R. T., Kodavalla, H., ... & Venkataramanappa, G. M. (2019). Constant time recovery in Azure SQL database. Proceedings of the VLDB Endowment, 12(12), 2143-2154.
\3. Zheng, W., Tu, S., Kohler, E., & Liskov, B. (2014). Fast databases with fast durability and recovery through multicore parallelism. In 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14) (pp. 465-477).
\4. Ren, K., Diamond, T., Abadi, D. J., & Thomson, A. (2016, June). Low-overhead asynchronous checkpointing in main-memory database systems. In Proceedings of the 2016 International Conference on Management of Data (pp. 1539-1551).
\5. Kemper, A., & Neumann, T. (2011, April). HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. In 2011 IEEE 27th International Conference on Data Engineering (pp. 195-206). IEEE.
本文转载自: 星环科技(ID:transwarp-sh)

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论