


一、测试整体方案
百分点面对的业务场景,主体是要解决超大规模数据集的 Ad-Hoc 查询问题,并且大多是单表查询场景。架构团队在此过程中选取了 HAWQ、Presto、ClickHouse 进行评测。评测中选取的数据集与 SQL 来自项目实际业务,我们需要评测维度主要如下:
A.数据在不同压缩格式下的压缩能力。
B.不同格式下的数据查询能力。
C.特定格式下的 HAWQ、Presto、ClickHouse 查询能力横向对比。
二、测试组件介绍
1.HAWQ
HAWQ 是 Hadoop 原生 SQL 查询引擎,结合了 MPP 数据库的关键技术优势和 Hadoop 的可扩展性、便捷性,以及 ANSI SQL 标准的支持;具有 MPP(大规模并行处理系统)的性能,比 Hadoop 生态圈里的其它 SQL 引擎快数倍;具有非常成熟的并行优化器等。
2.Presto
Presto 是一个分布式的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto 是一个 OLAP 的工具,擅长对海量数据进行复杂的分析。但是,对于 OLTP 场景,并不是 Presto 所擅长,所以不要把 Presto 当做数据库来使用。
Presto 需要从其他数据源获取数据来进行运算分析,它可以连接多种数据源,包括 Hive、RDBMS(Mysql、Oracle、Tidb 等)、Kafka、MongoDB、Redis 等。
3.ClickHouse
ClickHouse 是“战斗民族”俄罗斯搜索巨头 Yandex 公司开源的一个极具"战斗力"的实时数据分析数据库,是面向 OLAP 的分布式列式 DBMS,圈内人戏称为“喀秋莎数据库”。ClickHouse 有一个简称"CK",与 Hadoop、Spark 这些巨无霸组件相比,ClickHouse 很轻量级,其特点包括:分布式、列式存储、异步复制、线性扩展、支持数据压缩和最终数据一致性,其数据量级在 PB 级别。
三 、测试环境
1.服务器硬件配置
大数据服务器:大数据网络增强型 d1ne

2.OLAP 引擎环境
HAWQ 环境

Presto 环境
ClickHouse 环境

3.测试数据
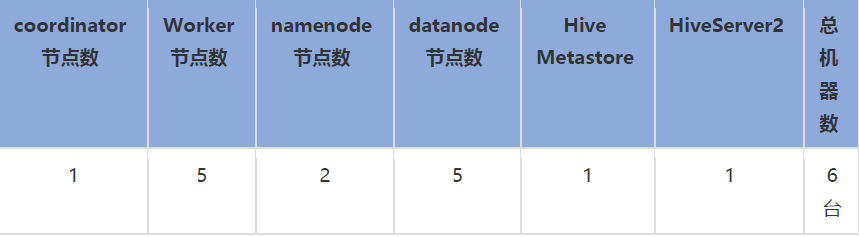
数据存放路径:/data1~12/iplog,一个盘 20G,6 台服务器每台都是 240G,一共 1440GB;每台服务器 12 个盘装载 4 个分区(小时)数据,每个盘装载 4 个分区的 1/12 的数据,4 个文件,每个文件大小 5G,2500w 条记录,一条记录 200Byte。
4.测试 SQL
测试挑选 4 个实际典型 SQL,大致如下:

四、测试过程
1.HAWQ 存储格式与性能评测
经过对比测试后,考虑数据的压缩比、数据的插入速度,以及查询时间这三个维度综合评估,我们的场景推荐 HAWQ 采用列式存储+Gzip5 的压缩方式;如果大家对压缩没有非常高的要求,可以按照测试的详细数据采用其它的组合方式。
HAWQ 压缩测试注意事项:只有当 orientation=parquet 的时候才能使用 gzip 进行压缩,orientation=row 的时候才能使用 zlib 进行压缩,snappy 不支持设置压缩级别。
详细的评测数据及图片展现如下文所示。
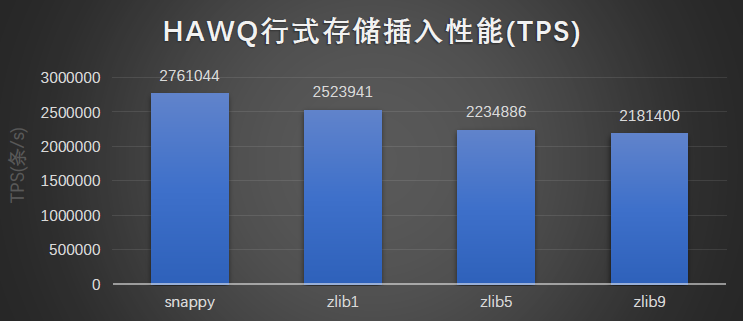
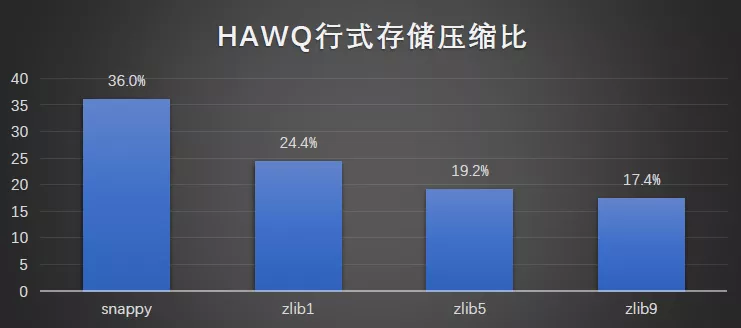
行式存储与压缩:
HAWQ 的插入方式是将数据写入 CSV 文件后,Load 到 HAWQ 表中。本次评测的是数据 Load 的过程和最终压缩比。可以发现,zlib 压缩级别到 5 以后,压缩比的降低就不那么明显了。
测试明细:
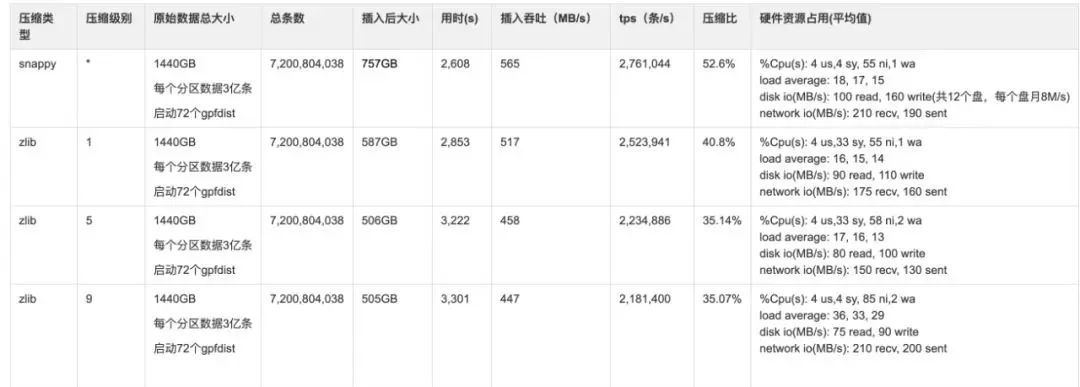
结果图形展示:
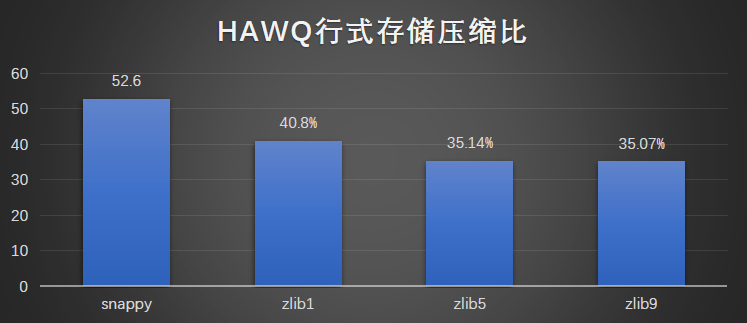
行式存储查询性能:
测试明细:
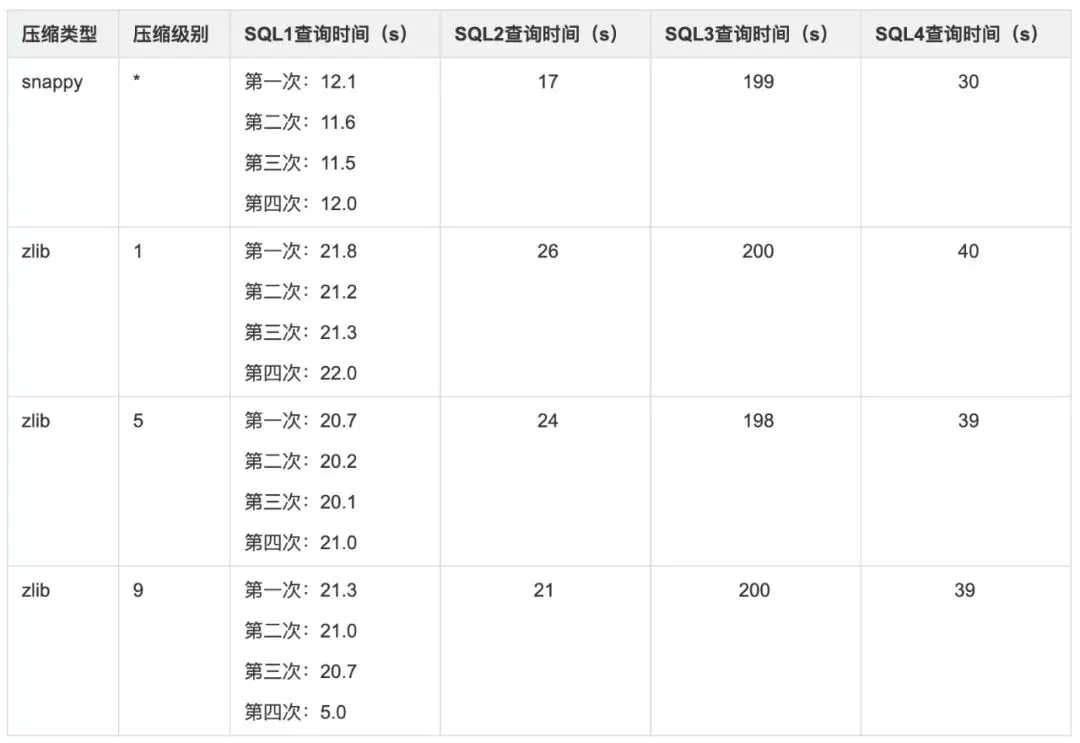
结果图形展示:
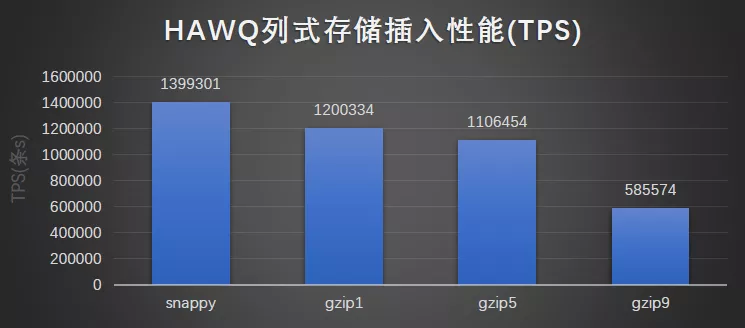
列式存储与压缩:
测试明细:
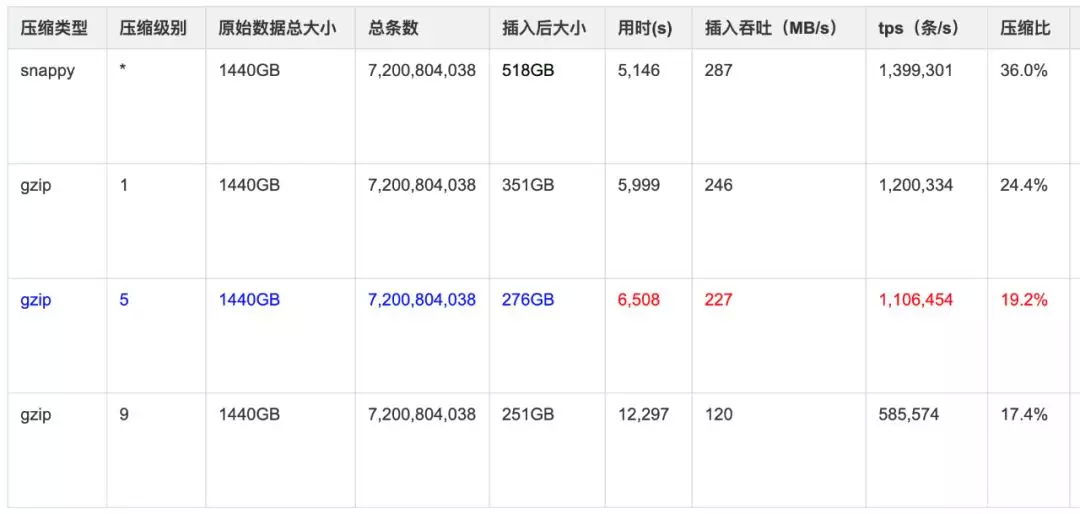
结果图形展示:
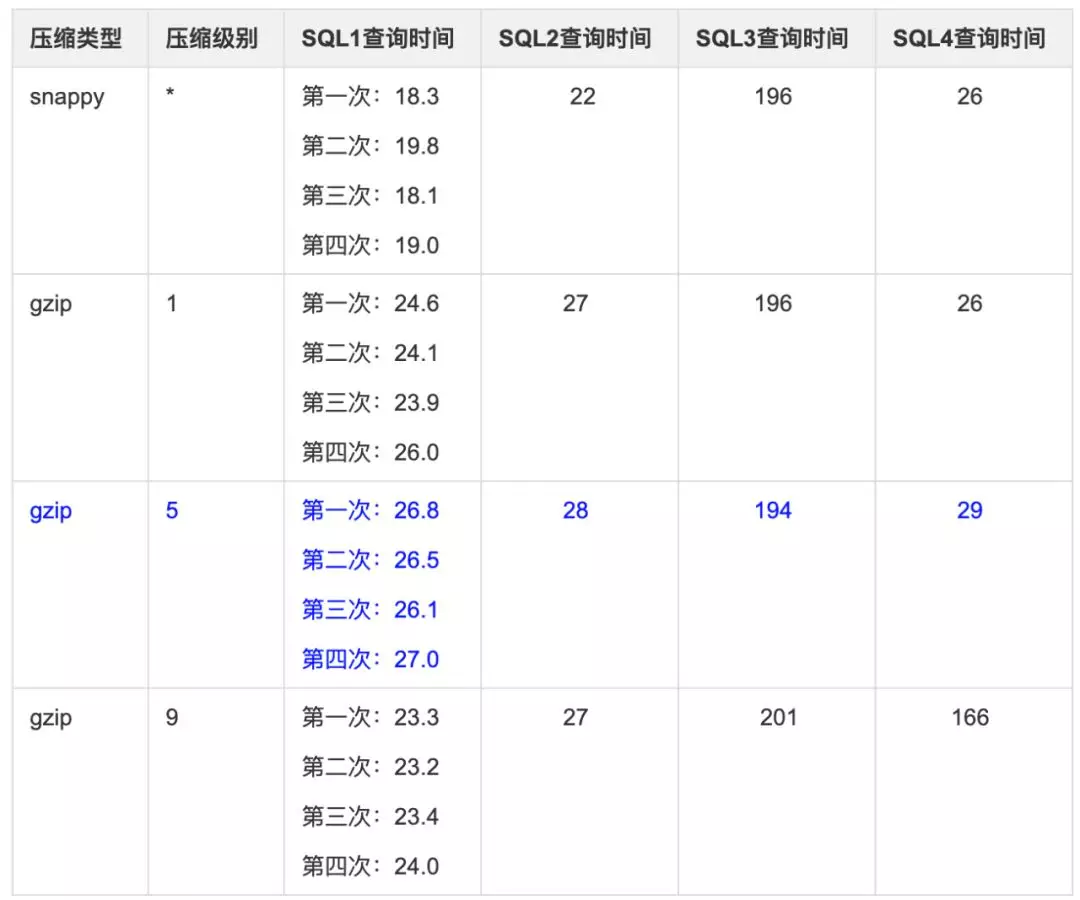
列式存储查询性能:
测试明细:
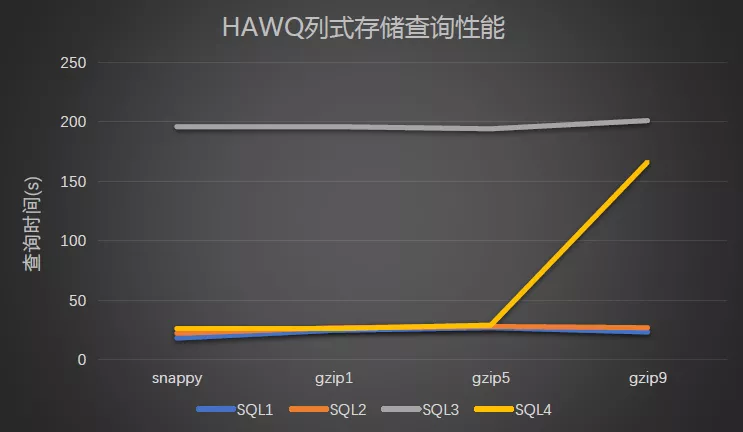
结果图形展示:
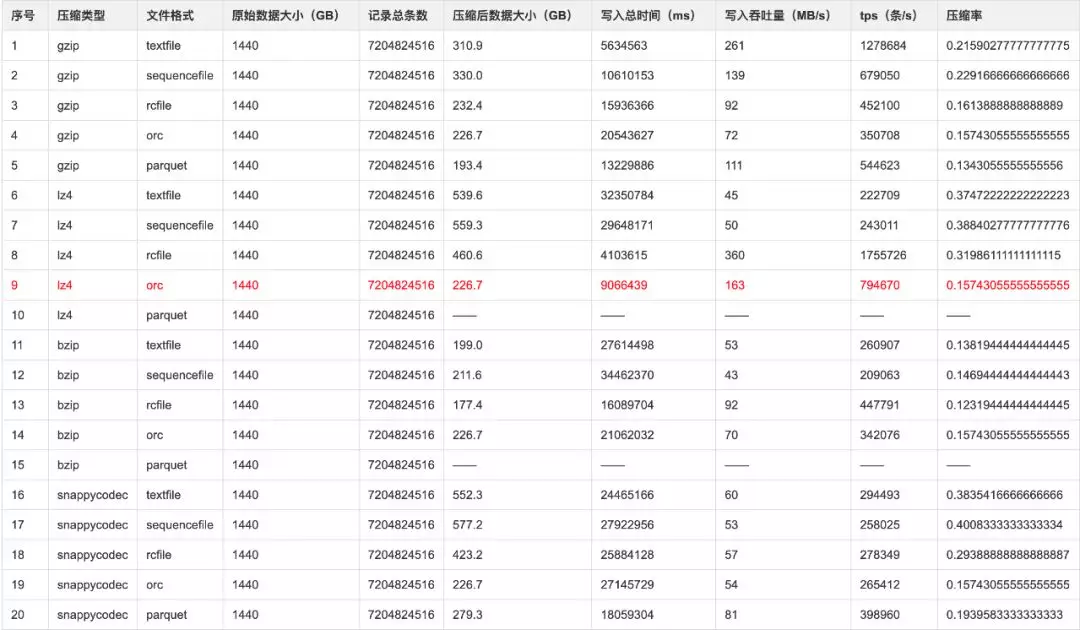
2.Presto 存储格式与性能评测
经过对比测试后,考虑数据的压缩比、数据的插入速度,以及查询时间这三个维度综合评估,我们的场景推荐 Presto 采用 LZ4+ORC 方式。这个结果也与各公司采用的格式一致。
存储与压缩:
测试方式,通过 CSV 文件 Load 到 Hive 表,原始数据总量为 1440GB。
查询性能:
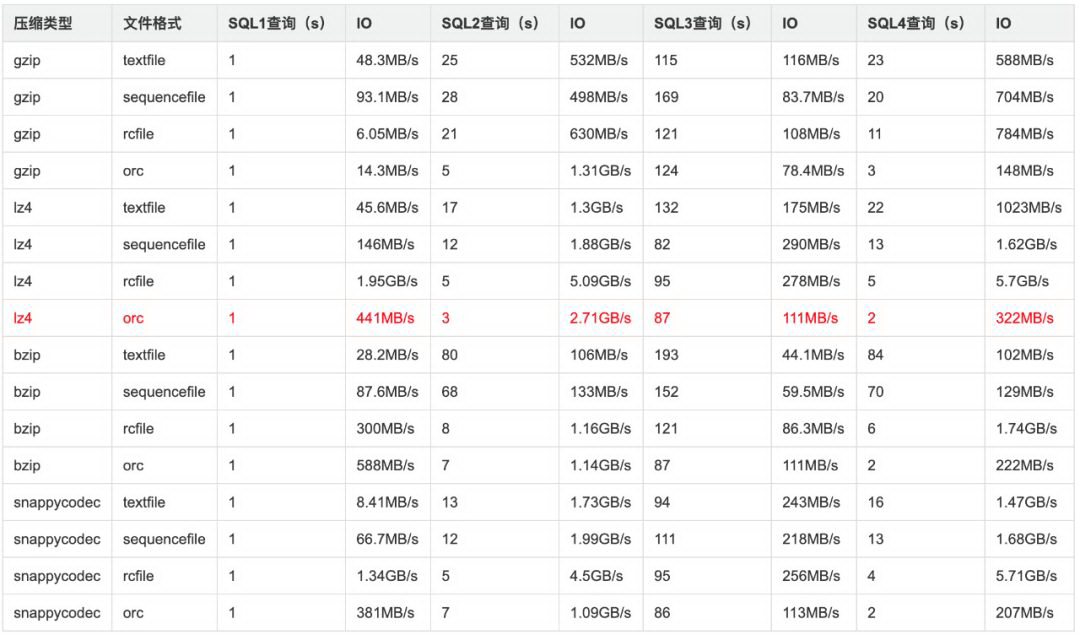
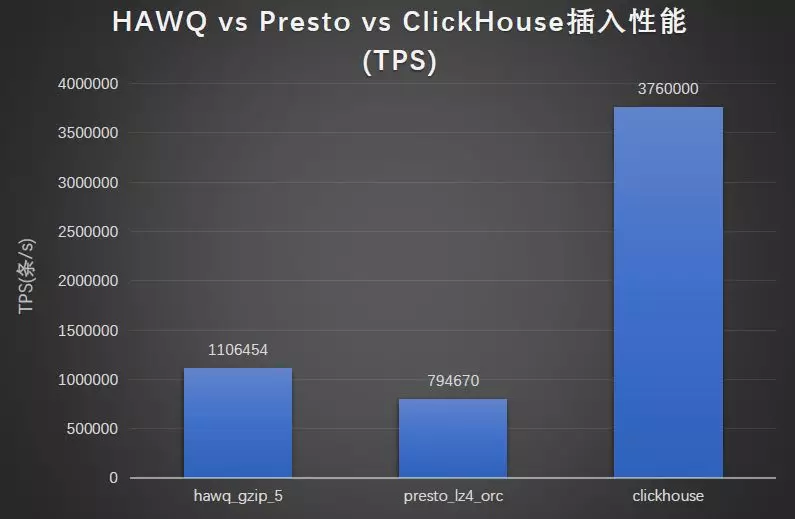
3.查询对比测试:HAWQ vs Presto vs ClickHouse
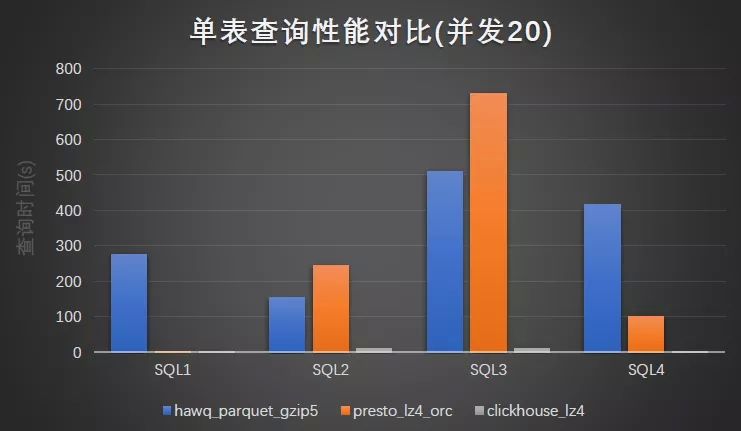
通过对比测试结果可以发现,在相同的数据量查询 SQL 情况下,ClickHouse 对比 HAWQ、Presto 有数量级的性能优势。由于我们的业务更多是单表的 Ad-Hoc 查询和分析,因此本次评测最终采用 ClickHouse 作为我们的 OLAP 引擎。
同时,测试过程中我们也发现一些有意思的现象,如:
(1) HAWQ 对查询都是全表扫描,如类似 Select * from where c1=xxx limit 10 查询,而 Presto 则对扫描的结果直接返回。
(2) HAWQ 查询会使用到系统缓存,而 Presto 对这方面并没有特别的优化。表现出的现象就是,在一定的并发度下,HAWQ 反而会体现出缓存的优势,而 Presto 性能则呈现线性下降趋势。
详细见测试过程的详细记录及图形化的直观展现。
并发 1 查询性能:
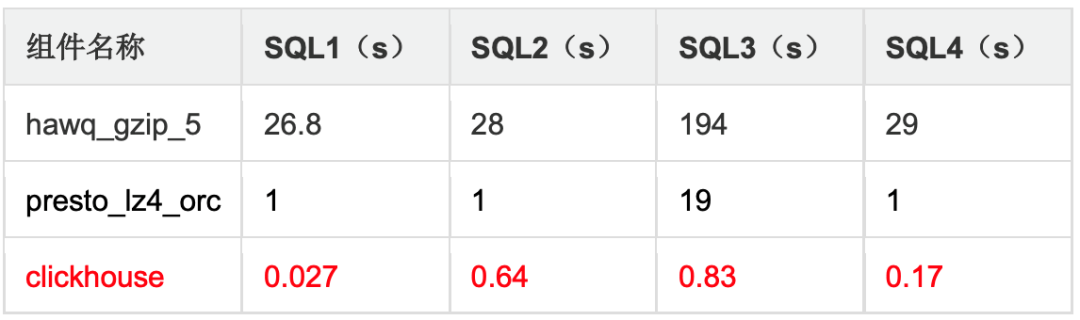
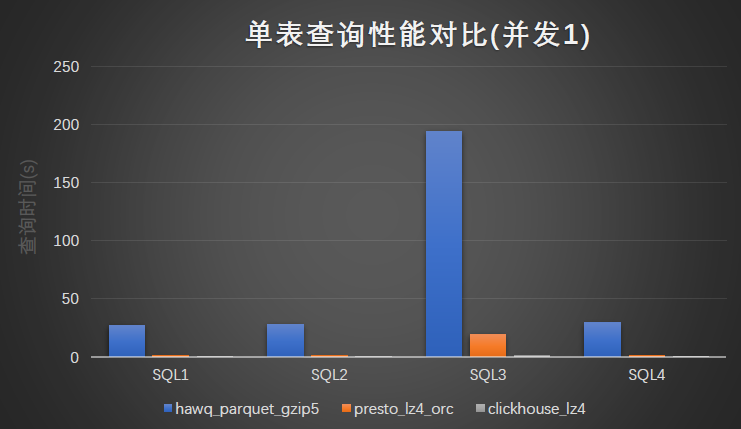
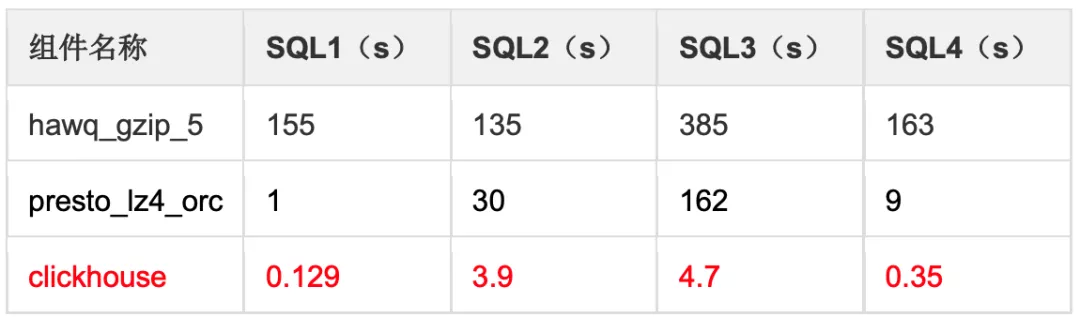
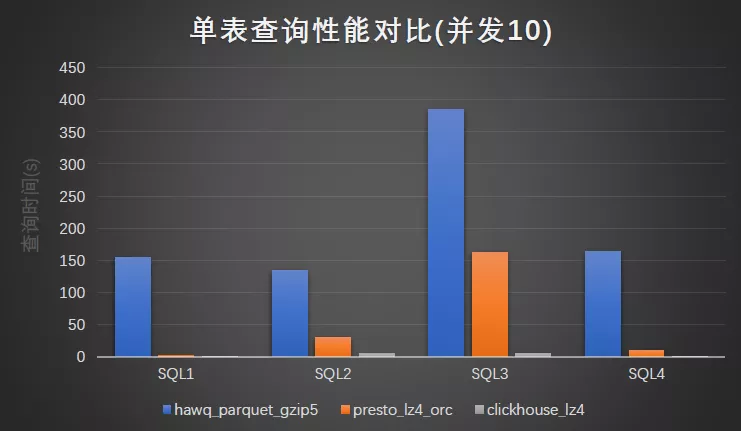
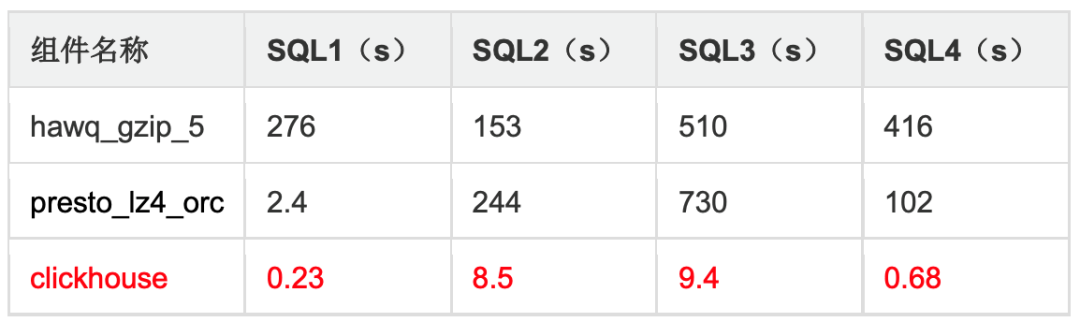
并发 10 查询性能:
并发 20 查询性能:
4.其它扩展测试
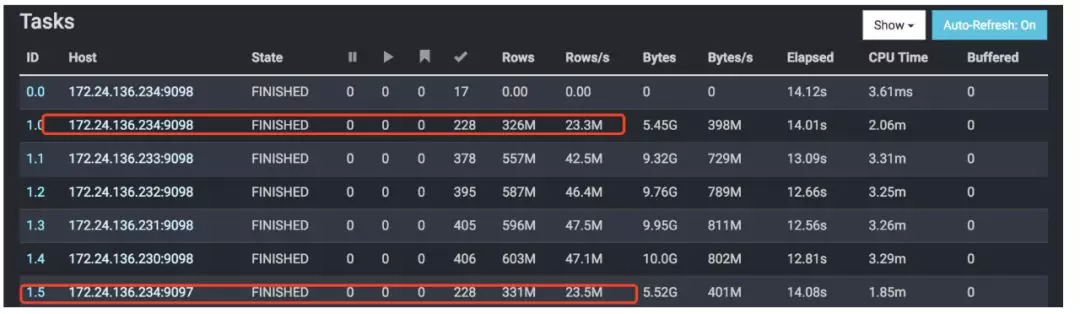
Presto 单机多 Worker:
我们通过添加单机的 Worker 数量验证是否提高查询效率,提高单机的查询利用率。
单机增加 Presto Worker,部署多 Worker。测试结果:表现为 CPU 瓶颈,没有效果。如下图,可以发现每个 Worker 的吞吐也少了一半。
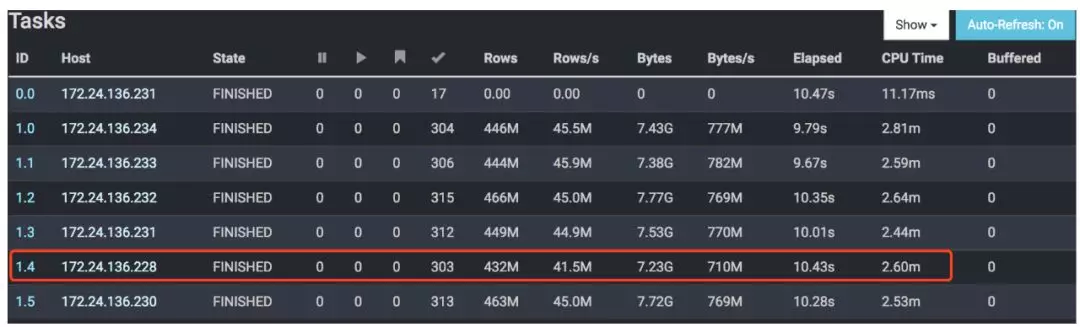
Presto 扩容:
我们通过添加扩容机器并部署 Worker,验证查询性能影响。
加入新的机器,部署 Worker。测试结果:表现为性能基本线性增长,受限于数据节点的磁盘 IO 和网络。
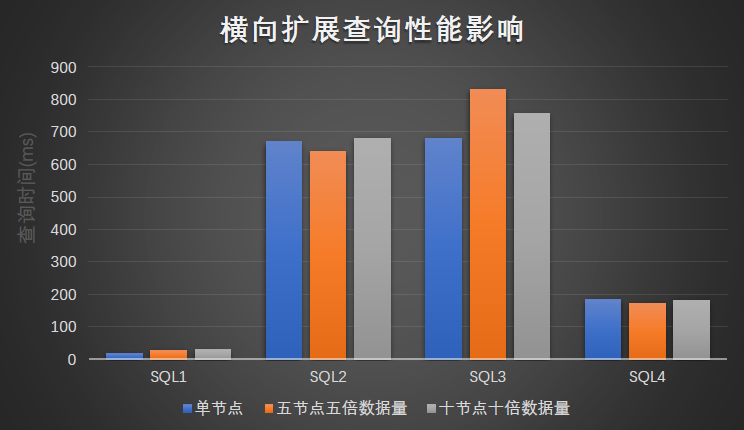
ClickHouse 横向扩展查询测试:
测试横向扩展对查询性能的影响,每个节点的数据量是相同的,使用相同的 SQL 分别测试单节点、五节点、十节点的查询性能。
根据测试结果可以看出,横向扩展后,节点数和数据量等比增加,查询时间几乎保持不变。所以对于 ClickHouse 我们可以基于单节点的数据量和性能,推断一定场景下整个集群的情况。
测试明细:
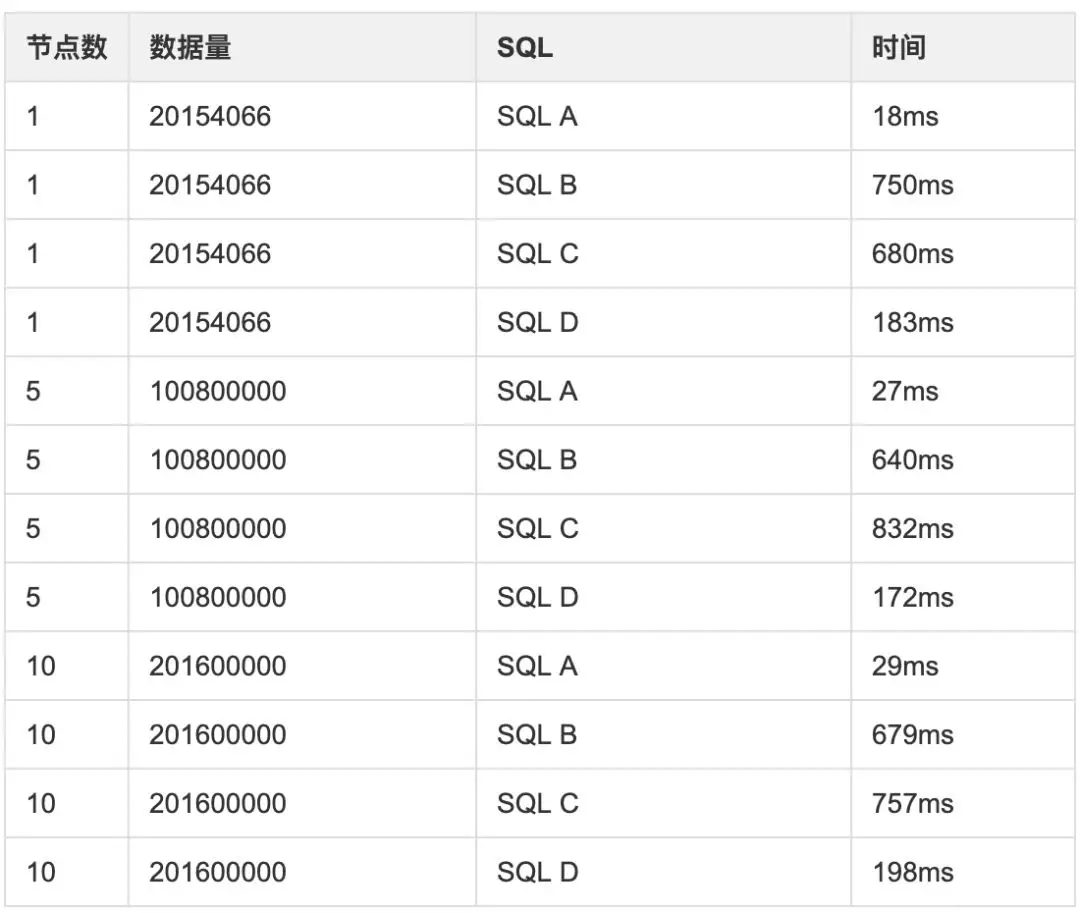
结果图形展示:
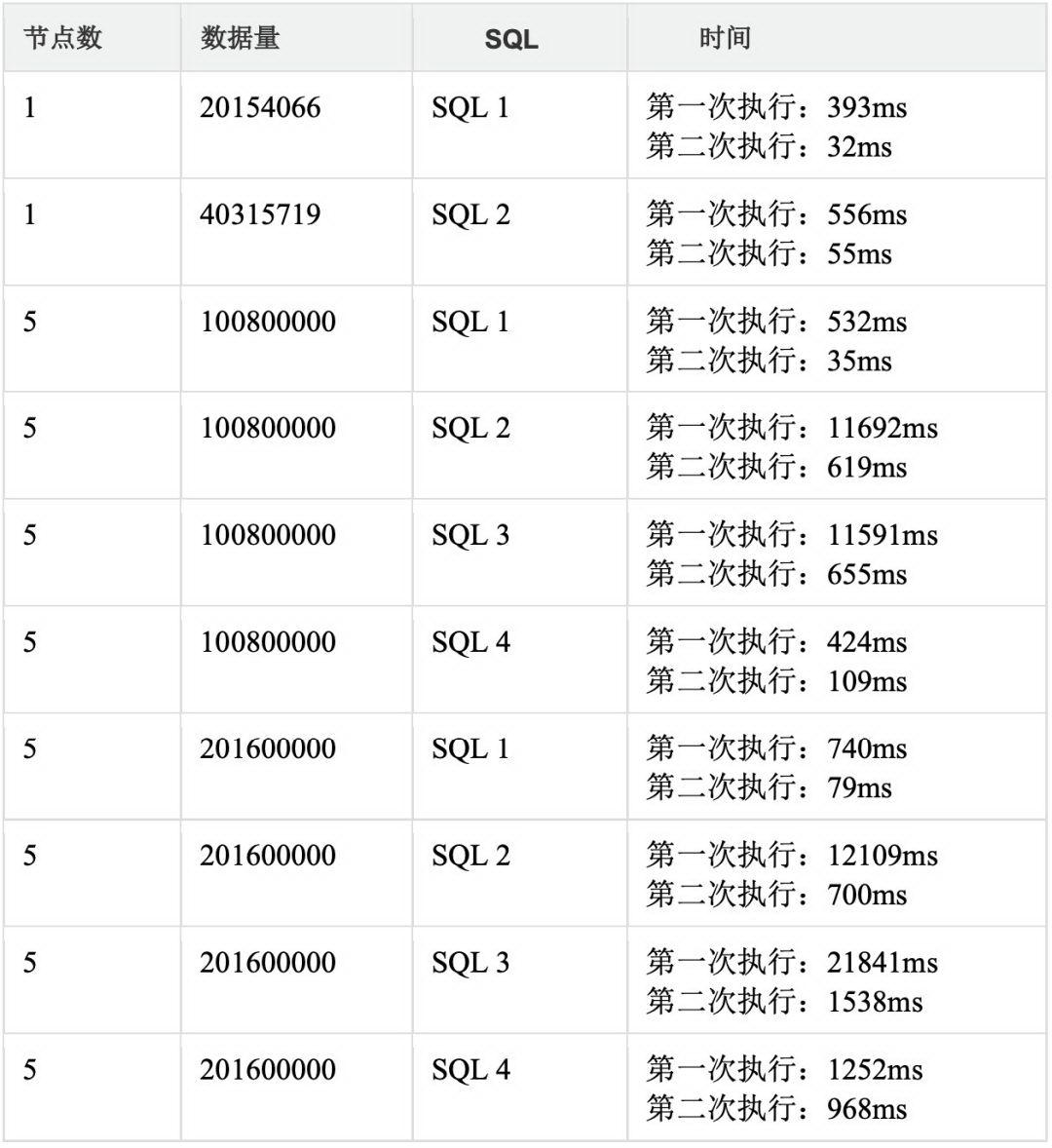
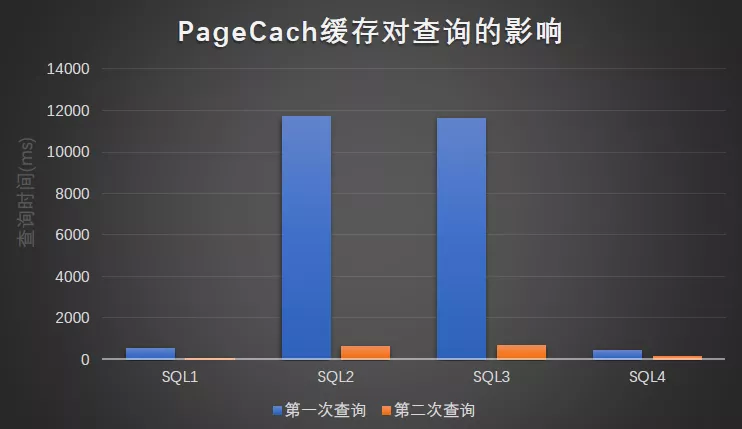
ClickHouse PageCache 缓存查询测试:
测试 PageCache 对查询性能的影响,首先清除所有缓存分别查询四个 SQL,然后再重复执行一次,可以发现,PageCache 对第二次查询的性能提高是影响巨大的。
ClickHouse 充分利用了系统缓存(PageCache),对查询有数量级的性能提升作用。
测试明细:
结果图形展示:
五、各组件综合分析
通过上述测试结果和分析图表,结合我们查询各组件的开源介绍进行综合分析,如下:
HAWQ 采用基于成本的 SQL 查询优化器,生成执行计划;同时在标准化 SQL 兼容性这方面表现突出(基于 TPC-DS 进行 SQL 兼容性测试)。数据存储直接使用 HDFS,与其它 SQL on Hadoop 引擎不一样,HAWQ 采用自己的数据模型及存储方式。在本次对单表的查询测试中,性能并不理想,并且我们发现对于表查询类似 limit 1 语句。HAWQ 也会全表扫描,这个过程让我们感觉有点诧异。
Presto 的综合能力对比其他 SQLon Hadoop 引擎还是比较突出的。我们在测试过程中发现,单节点的扫描速度达 5000WRow/S。Presto 是完全基于内存的并行计算,对内存有一定的要求。只装载数据到内存一次,其他都是通过内存、网络 IO 来处理,所以在慢速网络下是不适合的,所以它对网络要求也是很高。Presto 只是查询引擎,不负责数据的底层持久化、装载策略。Presto 支持丰富的多数据源,可跨多个数据源查询。另外,在我们测试的版本上没有本地数据读取优化策略,开源社区里在新版本上是支持的。
ClickHouse 作为战斗民族的开源神器,是目前所有开源 MPP 计算框架中速度最快的。对比测试的结果表明,ClickHouse 在单表的查询中性能十分优异。对多表的关联分析场景,查询其他报告并不十分理想,本次测试并不涉及,不做评论。ClickHouse 性能很大程度上依赖于系统缓存。对完全非缓存,进行磁盘扫描的场景,性能也不是十分突出,二者也有数量级的性能差距。这也是我们在使用过程中的优化点。
最后,以上采用 MPP 架构的 OLAP 引擎,随着并发的提高,查询性能都出现了线性下降,Presto 在这个问题上的尤为明显。CK 由于单次查询速度快,所以一定程度上掩盖了这个问题。因此,大家在未来的业务中进行 OLAP 评估时,也需要将并发作为一个重要的考虑因素。

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论