

对于 hacker 来说,最有趣的事情莫过于破坏软件设计者的原有规则,重新建立属于自己的规则了。姑且不论这个行为是否合法或违规,单就技术本身而言,矛与盾、攻与防、破坏与重建的过程中,为了达到最终目的而衍生出来的奇妙技术,再配上天马行空的想像和创造足以 让人着迷不已。
开篇
尽管 Linux 内核开源,升级或替换内核十分方便,但仍有一些特殊场景,需要在不替换内核的前提下给内核“动手术”。考虑如下两种场景:
24 小时不能停机的服务器,因为某些扩展性原因需要升级到新版本 Linux 内核;
不能二次烧录的嵌入式设备,需要修复其内核安全漏洞。
对于前一种场景,Linux 有已一套 livepatch 的解决方案。然而 livepatch 当前并不支持嵌入式常用的 arm 架构,因此针对后一种场景,我们只能采用一些非常规的手段达到目的。
我们要完成两个任务:在不重编内核的前提下给嵌入式设备的 Linux 内核做安全修复和安全加固。修复即是规避掉有缺陷的函数;加固即是保留原有函数不变,只不过我们需要在执行函数功能之前,先检查函数的传参是否合法,是则放过,否则阻断。以图为证:
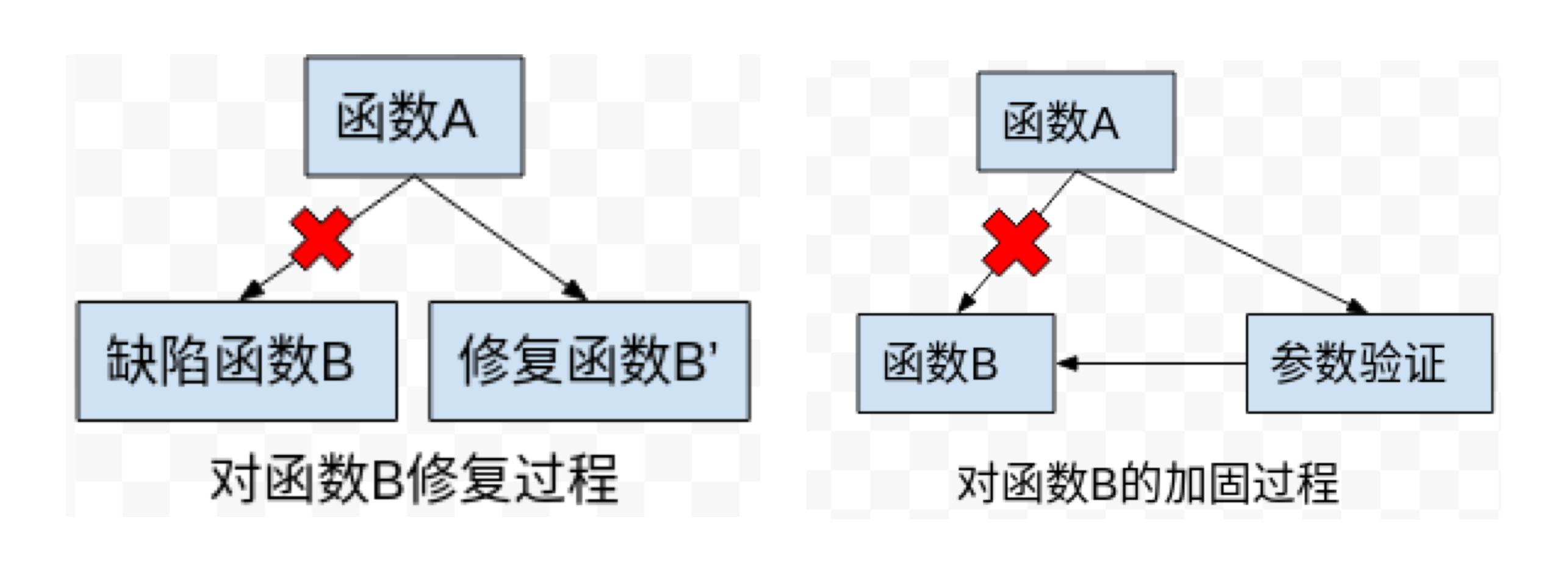
祭出 inline hook 的大杀器
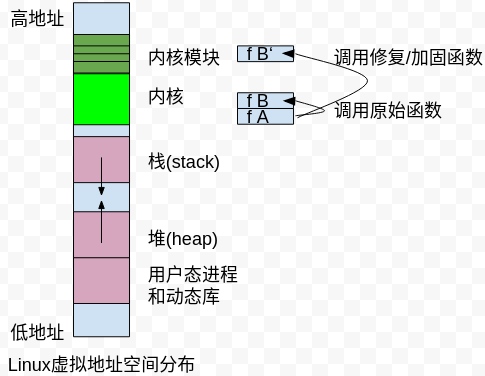
无论我们出发点的好坏,内核并不期待这种函数执行流的改变,那么只能去 hack 它。好在内核提供了可插拔的模块功能,我们可以将 hack 的逻辑放入内核模块,然后插入到内核中。内核模块由于是内核功能的扩展,两者工作在同样的权限和地址空间中(与之对比的是用户态程序,只能通过系统调用获得内核支持),插入内核后便可修改内核自身的数据。请见下图:
既然需要修改函数的调用关系,那么有两种修改办法:1)修改父函数;2)改造子函数。从这里开始,所有的函数都是以二进制汇编指令的形态呈现。
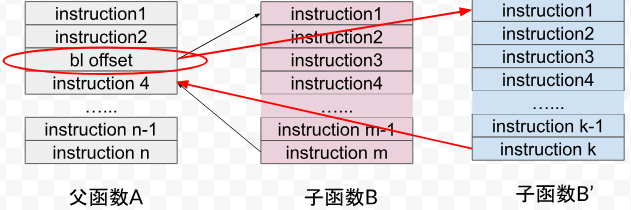
修改父函数的函数调用指令,将 offset 替换成修复函数地址。这样做的优点是侵入简单,缺点是但凡调用 B 函数的父函数都需要修改,查找父函数的工作量难以承受。
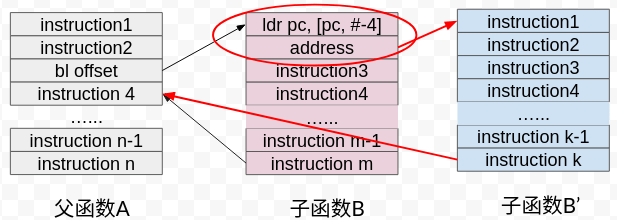
改造子函数意味着需要替换子函数的二进制指令,在子函数中侵入一个无条件跳转,跳转的目标是新子函数。这样做的优点是不用满天下寻找父函数,缺点是对子函数的侵入需要仔细设计。
这里有几个比较 tricky 的地方:
既然是指令侵入,那么设计的原则是侵入的指令越少越好。以 ARM32 CPU 为例,尽管单指令可以做无条件跳转,但是单指令跳转的距离有限±32MB,而内核的长度一般都超过了这个值,单指令很有可能跳转不到内核模块中(见 Linux 虚拟地址空间图)。因此最短的安全跳转指令条数为 2 条,以完整 32 位地址(4GB 空间)作为跳转区间。
只能抹去子函数最开始的 2 条指令,而不可以做指令的整体后移。假如在子函数开头做指令插入,后面所有指令整体向后平移的话,所有存在于子函数后面的函数地址都需要发生变化,函数调用的 offset 也都会变化,这样修改起来几乎是不可能的。
子函数指令被抹,意味着子函数功能被破坏。在修复缺陷的情况下,这是可以接受的,反正 B 函数再也不会被使用了,因为有修复函数 B’帮我实现同样的功能。但是在加固的情况下,B‘函数负责检查 B 函数的传参是否合法,合法的话还需要跳回到 B 函数中。那么怎样回到原先那个正常的 B 函数呢?这里又有两种设计方法:i)在 B’中回填 B 开头被抹掉的指令;ii)再设计一个跳板函数,由跳板函数统一保管被抹掉的指令。
第一种方式实现起来比较简单,但是存在一个致命的缺陷,它会引入竞争。内核是一个高并发的环境,假如线程 1 回填指令使得 B 函数恢复正常后,线程 2 执行到 B 函数则不会再跳转进入 B‘,成为参数检查的漏网之鱼。同时回填指令是典型的原子操作,反复侵入和回填会增加进程的阻塞程度,假如 B 函数是内存分配等频繁使用的函数,会严重降低系统的性能。
第二种方式需要再额外设计一个跳板函数,如图:
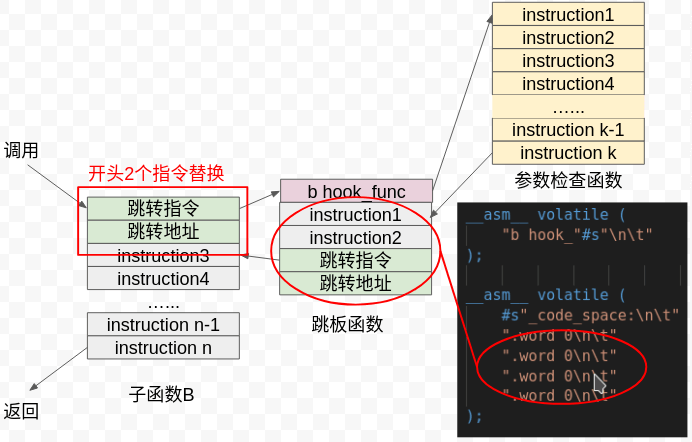
跳板函数专门预留 4 个指令长度的空间,用作子函数 B 的第 1、2 条指令存放,同时有两条指令长距离跳转到 B 函数的第 3 条指令地址处。当参数检查函数想要恢复 B 函数功能时,它先执行跳板函数中保存的两条指令,再回跳到原函数第 3 条指令处继续执行。那么通过跳板函数的“接力”,子函数 B 的指令被完整执行,这样也就保留了 B 函数的功能不受影响。
既然是做参数检查,那怎样保证参数检查函数能拿到子函数 B 的所有传参?我们都知道,C 语言参数的传递通常有两种方式,寄存器传参和栈传参。也就是说,父函数在调用子函数前,要么把参数压栈,要么把参数放到指定的寄存器里面。在子函数中,要么通过特定的栈偏移量取值,要么通过特定的寄存器取值。在设计阶段我们不能假定内核最终使用了哪种方式,因此对于跳板函数的设计原则为:
I. 不能改变栈;
II. 不能修改通用寄存器。
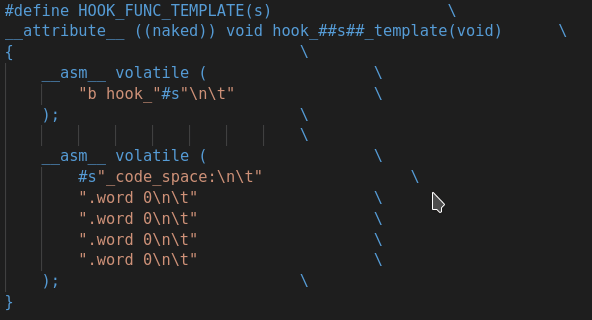
通常情况下,编译器会替我们打理好所有的栈操作和寄存器分配任务(事实上我们也不需要操心这些细节)。而如今我们不能信任编译器能帮我们做好这些事。实现跳板函数时,首先我们会使用 naked 强制编译器不生成栈的序言和结尾(prologue and epilogue)。其次我们使用 asm 自己编写汇编指令操纵所需寄存器,并且使用 volatile 拒绝编译器帮我们做任何优化。
结尾
至此看上去问题已经解决了,可事实上并非如此。在考虑了这么多情况后,我们的设计达到了最优吗?我认为不是的。功能上的达标跟设计上的 beautifully 还有很长的路(比如把这种静态的宏定义设计成为动态可注册的方式),设计上的美学追求将永无止境。
作者介绍:
刘涛:5 年 linux 内核开发经历,熟悉操作系统原理,擅长 C 语言、汇编,热爱底层技术,曾在业余时间独立开发过操作系统。目前是 ThoughtWorks 中国安全团队核心成员。我的个人 github 地址是 https://github.com/liutgnu
本文转载自 ThoughtWorks 洞见。
原文链接:
https://insights.thoughtworks.cn/hacking-linux-kernel-with-inline-hook-technique/

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论