

背景与介绍
推荐本质上需要完成从全量商品库高效检索 Topk 相关商品,由于候选商品数量过于庞大,现在的推荐系统一般分为两个阶段:召回和排序。对于召回阶段,面临着从全量商品库里面,高效召回商品的问题,由于存在系统的性能问题,需要重点去解决两个关键问题:
怎么高效检索,即算的快。高效检索意味着需要设计合理的检索结构和检索策略,能够在一个系统可容纳的时间内来保证可以召回足够量的商品。
整个召回的过程虽然算得快,但是不能算得太偏了,还是要把用户真正感兴趣的这些商品能够召回回来,就是所谓的算的准。
那么关于召回技术,大概经历了两代技术发展:第一代以启发式规则为代表(比如基于 item 的协同过滤),缺点是不能面向全量商品库来做检索,系统只能在用户历史行为过的商品里面找到侯选的相似商品来做召回,使得整个推荐结果的多样性和发现性比较差,你会发现系统老是给你推荐看过的或者买过的商品;第二代基于内积模型的向量检索方案,比如 YouTube-DNN 召回模型。通过离线学习 item 的 embedding 向量,然后通过积量化的方式构建索引,在线上应用的时候,实时计算 user embedding,在索引中查找最近邻(比较 user emb 和 item emb 的乘积)的 K 个 item 作为推荐候选。这类方法的核心思想是将用户和商品用向量表示,用向量内积大小度量兴趣,借助向量索引实现大规模全量检索。但是这个方法不太方便去做用户和商品之间的特征组合关系,使整个模型能力受限。
因此本文设计了一套全新的推荐算法框架:深度树匹配,允许容纳任意先进的模型而非限定内积形式,并且能够对全量候选集进行更好的推荐。
TDM 详解
TDM 是为大规模推荐系统设计的、能够承载任意先进模型(也就是可以通过任何深度学习推荐模型来训练树)来高效检索用户兴趣的推荐算法解决方案。TDM 基于树结构,提出了一套对用户兴趣度量进行层次化建模与检索的方法论,使得系统能直接利高级深度学习模型在全库范围内检索用户兴趣。其基本原理是使用树结构对全库 item 进行索引,然后训练深度模型以支持树上的逐层检索,从而将大规模推荐中全库检索的复杂度由 O(n)(n 为所有 item 的量级)下降至 O(log n)。
1.树结构
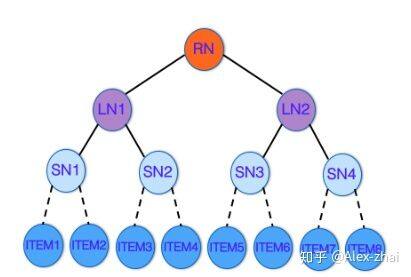
如上图所示,树中的每一个叶节点对应一个 item;非叶节点表示 item 的集合。这样的一种层次化结构,体现了粒度从粗到细的 item 架构。此时,推荐任务转换成了如何从树中检索一系列叶节点,作为用户最感兴趣的 item 返回。
怎么基于树来实现高效的检索?
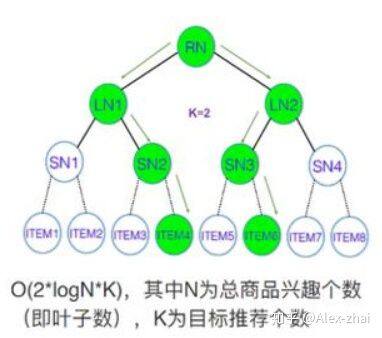
采用 beam-search 的方法,根据用户对每层节点的兴趣挑选 topK,将每层 topK 节点的子节点作为下一层挑选的候选集合逐层展开,直到最终的叶子层。比如上图中,第一层挑选的 Top2 是 LN1 和 LN2,展开的子节点是 SN1 到 SN4,在这个侯选集里挑选 SN2 和 SN3 是它的 Top2,沿着 SN2 和 SN3 它的整个子节点集合是 ITEM3 到 ITEM6,在这样一个子结合里去挑 Top2,最后把 ITEM4 和 ITEM6 挑出来。
那么为什么可以这样操作去 top 呢?因为这棵树已经被兴趣建模啦(直白意思就是每个节点的值都通过 CTR 预估模型进行训练过了,比如节点的值就是被预测会点击的概率值),那么问题来了,怎么去做兴趣建模呢(基于用户和 item 的特征进行 CTR 预估训练)。
兴趣建模
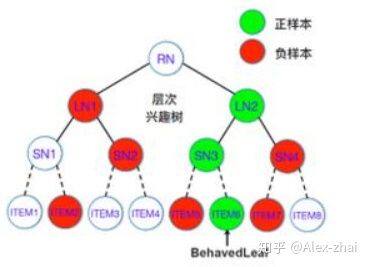
如上图,假设用户对叶子层 ITEM6 节点是感兴趣的,那么可认为它的兴趣是 1,同层其他的节点兴趣为 0,从而也就可以认为 ITEM6 的这个节点上述的路径的父节点兴趣都为 1,那么这一层就是 SN3 的兴趣为 1,其他的为 0,这层就是 LN2 的兴趣为 1,其他为 0。也就是需要从叶子层确定正样本节点,然后沿着正样本上溯确定每一层的正样本,其他的同层采样一些负样本,构建用于每一层偏序学习模型的样本。
构造完训练样本后,可以利用 DIN(这里可以是任何先进的模型)承担用户兴趣判别器的角色,输入就是每层构造的正负样本,输出的是(用户,节点)对的兴趣度,将被用于检索过程作为寻找每层 Top K 的评判指标。如下图:在用户特征方面仅使用用户历史行为,并对历史行为根据其发生时间,进行了时间窗口划分。在节点特征方面,使用的是节点经过 embedding 后的向量作为输入。此外,模型借助 attention 结构,将用户行为中和本次判别相关的那部分筛选出来,以实现更精准的判别。
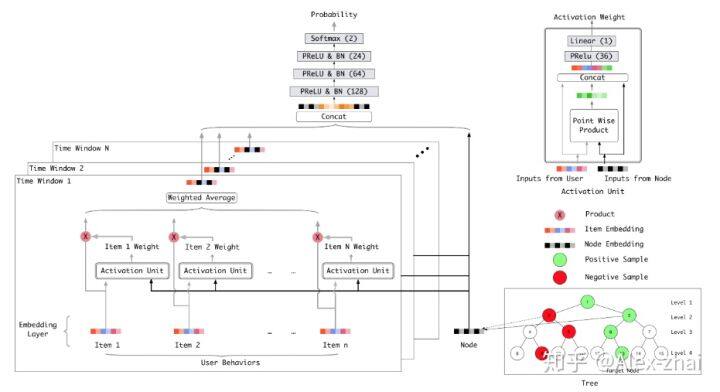
4. 兴趣树是怎么构建的?网络与树结构的联合训练
优化模型和优化样本标签交替进行。具体过程:最开始先生成一个初始的树,根据这个初始的树去训练模型,有了模型之后,再对数据进行判别,找出哪些样本标签打错了,进行标签的调整,相当于做树结构的调整。完成一轮新的树的结构的调整之后,我们再来做新的模型学习,实现整个交替的优化。
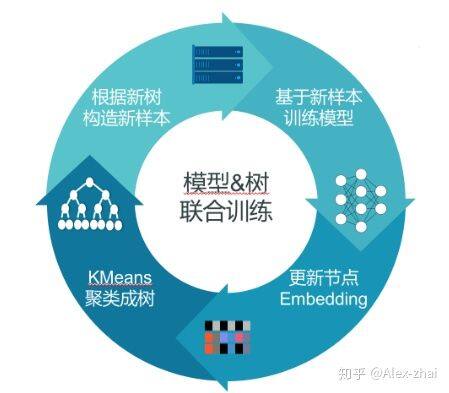
模型训练、优化样本标签过程迭代进行,最终得到稳定的结构与模型。
总结
目前 TDM 模型更多承担的还是召回的工作
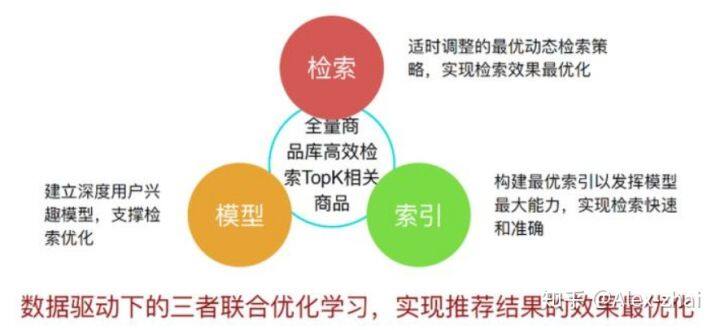
TDM 初步实现了在数据驱动下的模型、检索和索引三者的联合学习。其中索引决定了整个数据的组织结构,它承载的是模型能力和检索策略,以实现检索的快速和准确。检索实际上是面向目标,它需要和索引结构相适配。模型支撑的则是整个检索效果的优化。
TDM github 开源:https://github.com/alibaba/x-deeplearning/wiki/深度树匹配模型(TDM)
参考文献:
http://www.6aiq.com/article/1554659383706
https://arxiv.org/pdf/1801.0229
本文转载自 Alex-zhai 知乎账号。
原文链接:
https://zhuanlan.zhihu.com/p/78941783

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论