

CI/CD & Pipeline
随着 DevOps 的理念在众多公司的采纳,CI/CD 也渐渐落地。
CI(Continuous Integration)持续集成,是把代码变更自动集成到主干的一种实践。CI 的出现解决了集成地狱的问题,让产品可以快速迭代,同时还能保持高质量。它的核心措施是,代码集成到主干之前,必须通过一系列自动化测试,比如编译、单元测试、lint、代码风格检查。
CD 包括持续交付和持续部署。持续交付(Continuous Delivery)指的是团队自动地、频繁地、可预测地交付高质量软件版本的过程,可以看做持续集成的下一个阶段,强调的是无论代码怎么更新,软件都是随时可以交付的;持续部署(continuous deployment)更强调的是使用自动化测试来保证变更的正确性和稳定性,以便在测试通过后立即部署,是持续交付的更进一步。二者的区别是,持续交付需要人为介入,需要确保可以部署到生产环境时,才去进行部署。
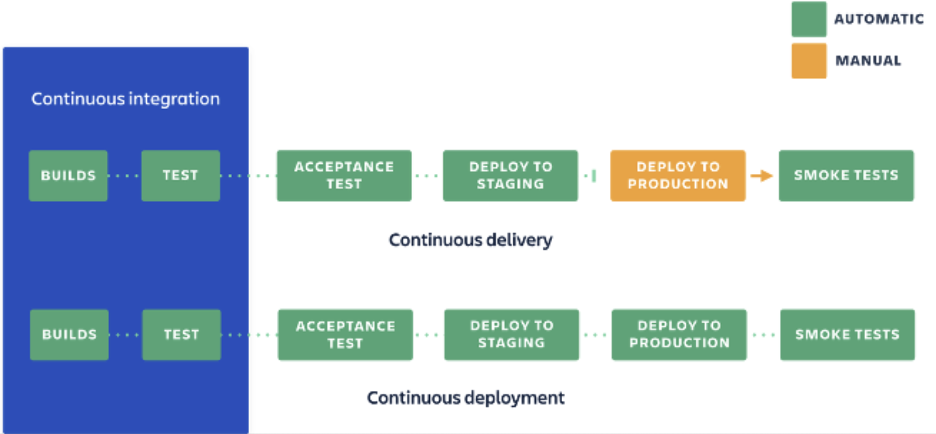
图 1 持续集成 & 持续交付 & 持续部署
CI/CD Pipeline 是软件开发过程中避免浪费的一种实践,展现了从代码提交、构建、部署、测试到发布的整个过程,为团队提供可视化和及时反馈。Pipeline 推荐的实施方式是,把软件部署的过程分为不同的阶段(Stage),其中任务(Step)在每个阶段中运行。在同一阶段,可以并行执行任务,帮助快速反馈,只有一个阶段中所有任务都通过时,下一阶段的任务才可以启动。比如图中,从 git push 到 deploy to production 的整个流程,就是一条 CD Pipeline。可以利用 Pipeline 工具,如 Jenkins、Buildkite、Bamboo,来帮助我们更方便的实施 C/ICD。
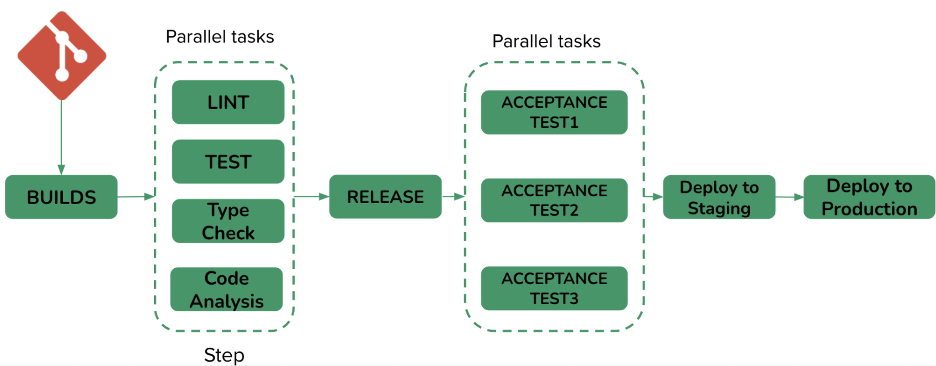
图 2 CI/CD Pipeline
CI/CD Pipeline 的反模式
虽然有 Pipeline 广泛的应用,但我们却会听见开发人员抱怨糟糕的 Pipeline 对他们的伤害,如阻塞开发流程,影响变更的部署效率,降低交付质量。我们收集了项目上经常出现的 Pipeline 的八大反模式,按照出现频率排序,分别阐述这些坏味道,分析可能产生的原因、影响及解决方式,希望能够减少抱怨,让 Pipeline 更大程度上提升工作效率。
1. 没有代码化
反模式:Pipeline 的定义没有完全代码化,进行版本控制,存储在代码仓库,而是在 Pipeline 工具上直接输入 shell 脚本定义 Pipeline 的运行过程。原因:由于早期的 CI 工具不支持代码化,一直能够保留到现在,没有做重构和升级。影响:Pipeline 的创建和管理都是通过 CI 工具的界面交互来的,难以维护,因此需要专门的管理员来维护,而有人工操作的部分就会出错,因此会降低 Pipeline 的可靠性。如果 Pipeline 因为一些原因丢失就没有办法很快恢复,就会影响交付速率。
解决方案:Pipeline as code 这个理念已经提了很多年了,在 ThoughtWorks 2016 年的技术雷达里就已经采纳了,需要强调的是,用于构建、测试和部署我们应用程序或基础设施的交付 Pipeline 的配置,都应以代码形式展现。随着组织逐渐演变为构建微服务或微前端的去中心化自治团队,人们越来越需要以代码形式管理 Pipeline 这种工程实践,来保证组织内部构建和部署软件的一致性。通常,针对某个项目的 Pipeline 配置,应和项目代码放在项目的源码管理仓库中。同业务代码一样要做 code review。这种需求使得业界出现了很多支持 Pipeline 工具,它们可以以标准的方式构建、部署服务和应用,如 Jenkins、Buildkite、Bamboo。这些工具用大多有一个 Pipeline 的蓝图,来执行一个交付生命周期中不同阶段的任务,如构建、测试和部署,而不用关心实现细节。以代码形式来完成构建、测试和部署流水线的能力,应该成为选择 CI/CD 工具的评估标准之一。
2. 运行速度慢
反模式:一条 Pipeline 的执行时间超过半小时,就属于运行速度慢的 Pipeline。(这里的运行速度与交付的产品有关,在不同的项目中,运行时长的限定也有所不同)很多原因都会导致运行一次 Pipeline 时间很长,比如:
该并行的任务没有并行执行,等待的任务拉长了执行时间;
执行 Pipeline 的 agent 节点太少,或者性能不足,导致排队时间太长,效率太低;
执行的任务太重,相同测试场景被不同的测试覆盖了很多次。比如同样的逻辑在不同测试中都测了一遍;
没有合理利用缓存,比如每个任务里都要下载全部依赖,在构建 Dockerfile 时没有合理利用 layer,每次都会构建一个全新的 image。
影响:这是开发人员抱怨最多的一个反模式。敏捷开发模式需要 Pipeline 快速反馈结果,受这一反模式制约,在特性开发过程中,经常出现开发人员改一行代码,等半天 CI 的效果。如果出现一个线上事故需要修改一行代码来修复,最终需要很长的周期才能让这一更改应用在生产环境。解决:不同的原因导致的 Pipeline 速度慢,有不同的解决方法。比如针对上面的问题,我们可以去:
检查 Pipeline 的设计是否合理,尽可能让任务并行;
对代码的各种测试深入了解,让测试尽量正交,避免过多的重复;
检查代码中的依赖,合理利用好缓存。包括 Docker Image、Gradle、Yarn、Rubygem 的缓存,以及 Dockerfile 是否合理的设计,最大化的将不可变的 layer 集中的开始阶段;
检查执行构建的节点资源是否充足,能否在任务量大时做弹性伸缩,减少等待和执行时间。
3. 执行结果不稳定

图 3 执行多次结果不稳定反模式:构建相同代码的 Pipeline 运行多次,得到结果不同。比如,基于同一代码基线,一条 Pipeline 构建了 5 次,只有最后一次通过了。原因:出现执行结果不稳定的原因也多种多样,比如测试用例的实现不合理,导致测试结果时过时不过;代码中使用了不可靠的依赖源,比如来自国外的依赖源,下载依赖经常超时;由或是在 Pipeline 运行过程中没有合理设计各个阶段,导致有些任务同时运行冲突了。影响:Pipeline 作为代码发布的最后一道防火墙,最基本的特性是幂等性,即在一个相同的代码基线,执行 Pipeline 的任意任务,不管是 10 次、100 次,得到的结果都相同。Pipeline 不稳定会直接导致代码的部署速率降低。更重要的是,影响开发人员对 Pipeline 的信任。如果不稳定 Pipeline 不及时解决,慢慢这条 Pipeline 会失去维护,开发最后会转向手工部署。解决:要构建幂等的、可靠的 Pipeline,就要分析这些不稳定因素出现的原因。
提升测试的稳定性,比如用 mock 替代不稳定的源。
采用 Pipeline 的重试功能,或者采用稳定的镜像源,或者提前构建好基础镜像。
引入 Pipeline 的插件保证任务不会并行执行。
4. 滥用 job 处理生产环境数据
反模式:使用 Pipeline 的定时任务的特性,运行生产环境的负载。比如经常会定期做数据备份、数据迁移,数据抓取。原因:由于对 Pipeline 的认识不够清晰,将重要的任务交由 Pipeline 做。Pipeline 一旦有了某个生产环境的访问权限,做这些数据处理相关的任务就很方便,减少了很多人为的操作。
影响:Pipeline 是用来做构建、部署的工具,不能用于业务逻辑的执行。由于 Pipeline 是一个内部服务,他的 SLO/SLI 必定和生产环境不同,如果强依赖势必影响生产环境的 SLO。假如某天 Pipeline 挂掉了,生产环境就无法得到想要的数据。另外,任务和 Pipeline 紧密耦合,是我们后面会讨论的另一个反模式。解决方法:用生产环境自身的工具解决这种数据问题,比如 采用 AWS 的 lambda,定时触发数据处理任务。
5. 复杂难懂

图 4 Pipeline 的定义逻辑复杂
反模式:Pipeline 的定义包含了太多的逻辑,复杂难懂。只有在一条 Pipeline 运行起来才能知道这里会运行哪些步骤,会将这个版本部署到哪些环境。原因:Pipeline 的代码不够整洁。有人认为 Pipeline 只是给 CI 工具提供的,就随意编写,认为能完成指定的工作就够了。影响:Pipeline 的复杂性,会直接提升学习成本。如果想重复执行上一次构建,会花费较长时间。解决:Pipeline 的代码要简洁,把复杂性放在部署脚本或代码侧。通过每个阶段的的标题可以直接了解所要执行的任务。如果存在很多相同的逻辑,可以通过开发 Pipeline 的 Plugin 来简化配置。
6. 耦合太高
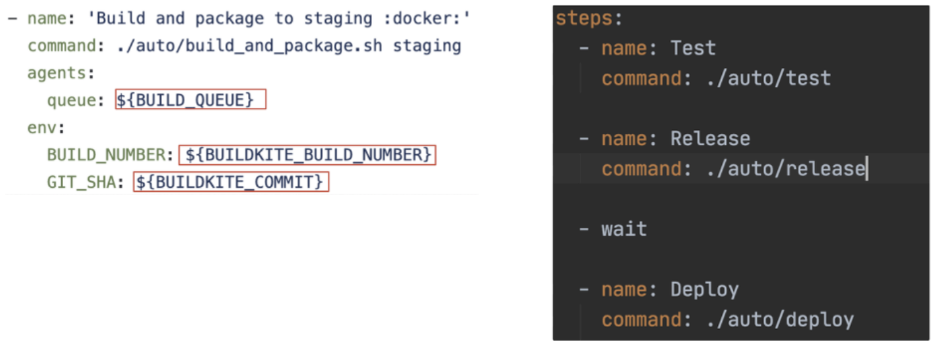
图 5 (左)耦合太高的 Pipeline 定义 (右)
期待的 Pipeline 定义反模式:Pipeline 跟运行它的 CI 工具紧密耦合,以至于无法在本地重复相同的步骤。表现可能多种多样:
Pipeline 的定义跟构建工具紧密耦合,包含了 Pipeline 工具特有的参数以及 CLI 命令。比如在配置中使用 BUILDKITE_BUILD_NUMBER,BUILDKITE_QUEUE 等等。结果就是本地运行的方式或结果和 Pipeline 上运行的方式以及结果不一致。
在 Pipeline 的任务中写了一大段脚本,或者直接使用命令加上一堆参数,以至于在本地想跑测试需要在 Pipeline 的配置中找命令并且在本地粘贴。
不做环境隔离, 测试,编译,部署等都依赖于运行时环境。可能出现 Pipeline 因依赖的软件/库等版本不一致而导致的不一致的情况,通常还很难排查。
影响:因为本地不方便调试,所变更的失败概率会大大增加。如果变更用来修复一个 Bug,由于不做环境隔离,会导致故障修复周期拉长。解决:Pipeline 的每个 step 都用脚本封装起来,脚本里不使用 Pipeline 工具特有的参数,并且保证本地运行时和 Pipeline 上保持一致。
7. 僵尸 Pipeline
反模式:一条 Pipeline 年久失修,很久没有执行过,而且最后一次的构建是失败的。原因:这种反模式通常出现于不再活跃开发的项目上,因此很久没有执行过 Pipeline。影响:Pipeline 的结果反应的是一个项目的状态。由于软件产品迭代速度快,这个软件的依赖可能已经发生了巨大的变化,一旦运行,大概率会出错。假如这个项目目前出现了一个事故,需要提交代码,就得先修复项目的 Pipeline,才能确保提交修复代码。解决:针对常年没有提交的 Pipeline,我们建议让 Pipeline 周期的执行,出现问题立即修复。如 Github 的 Dependabot,能保证项目的依赖始终是是最新的,而且能让 Pipeline 执行,提早发现问题。
8. 需要人工介入
反模式:通常项目上会有一个专职 Ops,在项目可以发布的时候手动触发部署流程,或者需要传递很多参数,让 Pipeline 运行起来。原因:包括项目的流程繁琐,需要反复确认;DevOps 成熟度不够,没有实现持续部署;或者 CI 的测试覆盖不够,CI 通过后还要进行更多的测试才能部署。影响:这些 Pipeline 需要专人盯着,去点某些按钮。会直接影响产品的交付速率和代码部署频率。解决:让项目的运行更加敏捷,减少 Pipeline 定义中的阻塞按钮,将手工测试自动化后集成到 Pipeline 中。
最后
希望通过本篇文章,意识到项目中 CI/CD Pipeline 的问题,使其发挥更大的价值。
本文转载自:ThoughtWorks 洞见(ID:TW-Insights)
原文链接:持续集成和交付流水线的反模式

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论