

上一期我们分享了《大规模分布式系统资源管理(一) 》,介绍了云游戏中的资源管理;本期将继续介绍搜索引擎中的资源管理和 AI 在资源管理中的应用。
1 搜索引擎中的资源管理
实例分布调整
问题描述
1、IDC 中有多种 service,每个 service 有很多实例
2、对已有实例的分布进行调整,达到负载均衡
3、约束条件
Resource Constraints (CPU, Memory, SSD)
这个约束条件是关于资源的条件。调整过程中还有调整结束之前,都不能违反容量的限制。不能调整之后每台服务器加起来的容量超过了服务器的容量。
Conflict Constraints
为了容错或者备份等,有一些实例是不可以放在同一台服务器上的。比如来自同一个 service 的实例。
No Service Interruption (Online)
调整过程中是不能影响线上服务的。这是一个比较苛刻的条件。
挑战
大规模调整复杂度高、小规模调整效果差
如果用数学来描述的话其实这是一个带约束条件的整数规划问题。这个问题的变量非常多,如果用数学传统的解方程的方法解出来的话是不太可能的。
线上调整对安全性、可靠性有极高要求
不光不能影响正常的服务,也不能带来任何的风险。调整的过程中不能使服务器超过安全线等有非常多的限制。
调整过程约束条件多
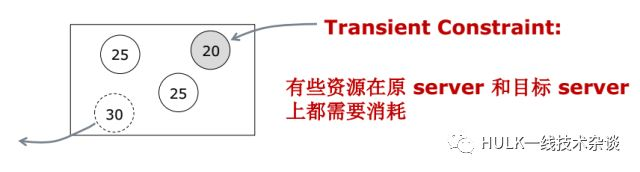
如果想把一个实例从一台服务器挪到另一台服务器上,在这个实例在新的服务器上能正常工作之前,旧的实例是不能删除的。所以这个实例在这段时间其实在新的服务器和旧的服务器上占了 2 份资源。而这段时间正好是调整的过程。所以说这个资源并没有被释放掉。
调整算法
局部搜索
局部搜索有几种搜索的策略。
1、Shift: 移动一个实例到另一台 server
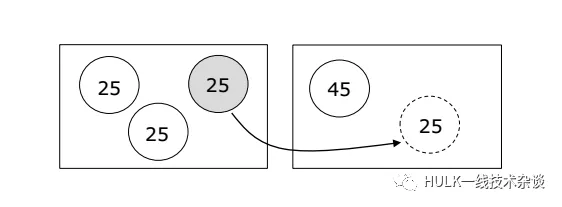
如果移动完之后,负载变得更均衡了,那么这个方法就是可行的。
2、Swap: 交换位于不同 server 上的两个实例
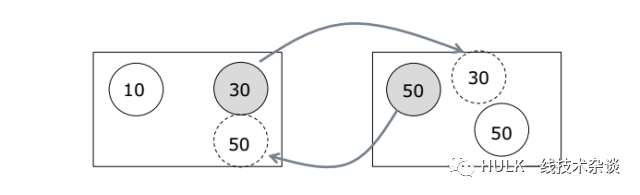
如果负载变均衡了,那么这个操作是可接受的。
3、BigMove:移动实例到一台 server, 同时移走 server 上若干实例
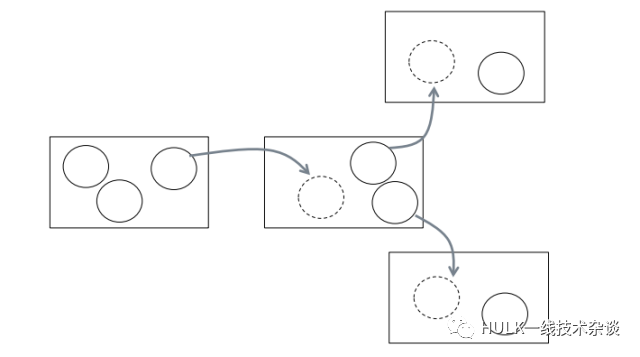
这个会比前 2 种操作更有效。尤其在移动比较大的实例,系统资源比较紧张的时候,这个策略非常有效。
例子:
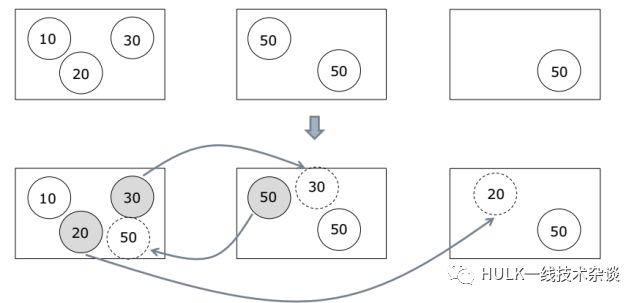
开始时有三台服务器,数字表示它的 CPU 所占用的比例。每台服务器的容量如果是 100 的话,左边的是 60,中间的是 100,右边的是 50。那么我们通过 BigMove 移动之后,先把右边 的 50 移动到左边这台机器上,再把 20 挪到右边的机器上,30 挪到中间的机器上,整个的 balance 就会好很多。
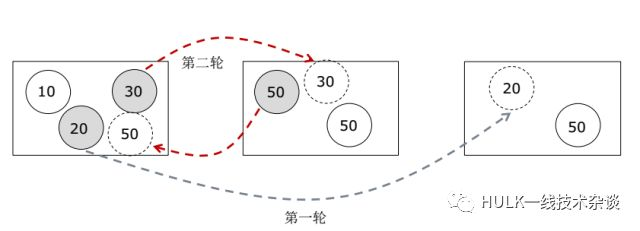
刚刚讲的 Transient Constraint 在移动过程中有可能会超过容量的限制,那怎么办呢?有可能移动是有顺序的。比如想移动 50 过来,如果 20 不挪出去的话它是进不来的,那么这会分为两轮算法。
整个算法的描述是这样的。
以 server 为单位多轮迭代,直到所有 server 变为不可调状态
(1) 每次迭代选取当前 cpu 使用率最高的 server 进行调整
(2) 依次对 server 上的每一个实例进行如下操作:
(a) 依次尝试 shift, swap 和 BigMove 调整
(b) 如果上述任意一个尝试成功,本次迭代结束,跳至步骤(1)
© 如果全部尝试失败,标记此实例为失败
(3) 如果 server 上所有的实例都失败,标记此 server 为不可调(以后不参与调
整),结束本次迭代,跳至步骤(1)
调整效果
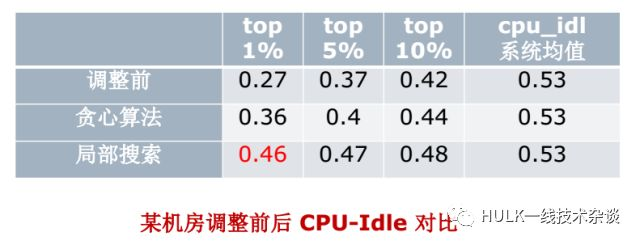
CPU-Idle=1-CPU 的利用率
即调整前,前 1%的服务器的 CPU 利用率是 1-27%=73%,整个系统 CPU 的平均值是 53%,可见前 1%的服务器还是比较高的。经过局部搜索算法调整之后可以降到 46%,非常接近 50%,所以这个算法是很有效的。
副本策略
实例副本
每个 service 通常有多个实例副本,以满足大量并发请求
一个 service 有多个实例,共同分发流量,目前每个实例的流量,据了解目前比较简单的流量的调度算法,通常是平均分配在这些实例上的。如果一个 service 有很多实例,实例是一样的,都是完成同一个服务的,那么通常流量是均匀分布的。这有利于做负载均衡。
副本个数影响单实例资源消耗
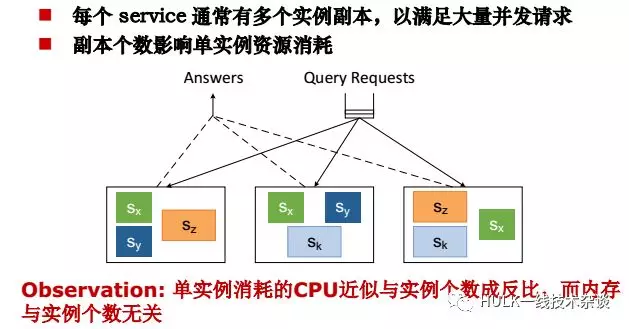
现在有一个问题是如何定副本的个数。这个问题也可以叫做配流管理。假如每个如果实例都是装在一个容器里的,那么需要定容器的容量。容器的容量定下来之后,副本的个数就定下来了。反之如果副本个数定下来了那么容器的容量也定下来了。
我们的工作主要是从资源利用率的角度来考虑副本的策略。比如优化响应时间优化负载均衡等,这一部分的目标是尽量用少的机器。假如有很多的 service,现在要做的就是要用每一个 service 来决定用多少个副本,使得安全地装下所有的 service 所用的机器最少。
副本策略的影响
假如有 A 和 B 两个 service,(单个实例内存的需求与实例个数没有关系),每个 A 和 B 的实例每个各需要 0.5 的内存,每个 sever 都有 1 单位的内存,
A: 总 CPU 需求 6.0(即需要 6 个机器), 单实例内存需求 0.5
B: 总 CPU 需求 4.0(即需要 4 个机器), 单实例内存需求 0.5
现在需要决定给 A 和 B 各自几个副本。
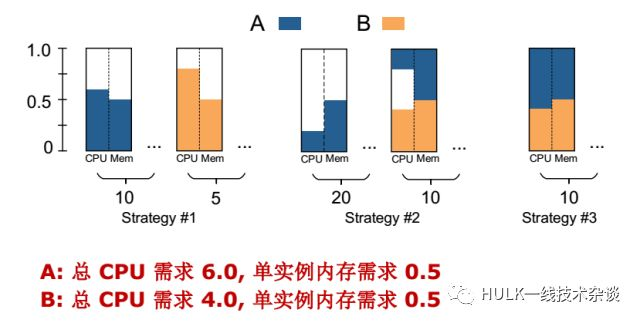
上图有 3 个策略。
左边的 S1:给 A 10 个副本,B 5 个副本,则 A 的每个单个实例 CPU 的需求是 0.6,每个内存是 0.5,所以一台机器只能放一个实例。所以 A 需要 10 个服务器,B 需要 5 个服务器,一共需要 15 个服务器。
中间 S2:给 A 30 个实例,单实例的 CPU 下降为 0.2,则有 10 个 A 的实例可以和 B 的放在一起。这个策略一共占了 30 个服务器。
右边 S3:给 A 和 B 各 10 个实例。那么 A 和 B 正好可以放在一台服务器上,需要 10 台服务器就可以了。
所以副本个数对最后所用机器容量有很大的影响。
目标
寻找合理的副本策略,使得所用资源最少
算法
1、全局搜索
时间复杂度高、结果较优—不太适合在动态过程中应用,只适合机房初始建时
2、最少副本策略
副本最少、单实例较大,不利于调整
3、固定资源占比策略
异构场景不友好
4、Online 调整策略
效果
每台 server 同时只能运行几个游戏
如果用户比较多的话,那么运营商就要提供很多的服务器。服务器的成本很高,包括它的运营成本维护成本等。云游戏收用户的钱可能还抵不过服务器的钱或者网络的钱。所以成本一直是云游戏里一个很大的挑战。
2 AI 在资源管理中的应用
磁盘故障预测
目标
利用硬盘 S.M.A.R.T.信息,预测硬盘故障,实现主动容错。
数据集
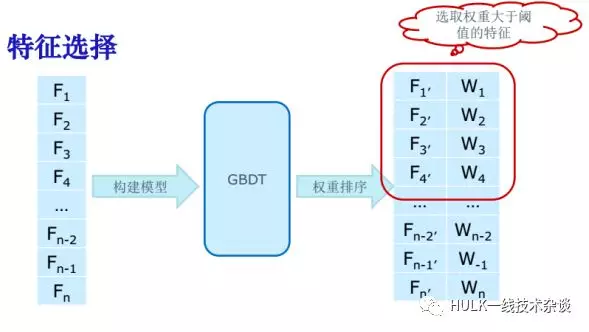
特征选择
方法
十分位分布 (quantile distributions)
秩和检验 (rank-sum test)
标准分 (z-score)
反向安排检验 (reverse arrangement test)
属性
“W”数据集:选取 10 个基本属性+3 个差值属性
“S”,“M”数据集:选取 7 个基本属性+3 个差值属性
已有成果
一、评价标准转变
二分类 → 剩余寿命 → 迁移率/误迁移率
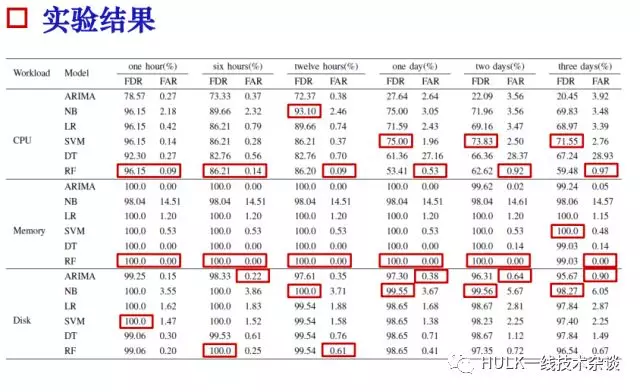
二、实验结果
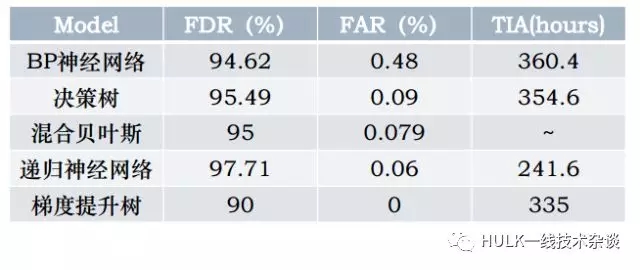
1.二分类——预测硬盘是否将要发生故障
2.剩余寿命预测——抓住问题的时序特征
CBN 模型:剩余寿命区间预测准确率达到 60%
RNN 模型:剩余寿命区间预测准确率达到 40%~60%
3.迁移率和误迁移率——针对分布式存储系统的评价指标
直接反映预测模型对危险数据的保护效果

三、引入到分布式存储系统中+预警处理机制
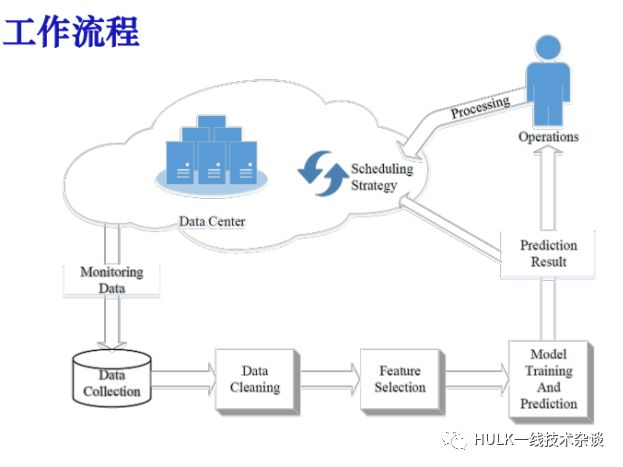
负载预测
问题描述
对大型数据中心负载预测最终目的:提供高效资源管理系统。
在硬件故障预测的基础上发展到分布式系统软件应用的层面对负载进行一些预测。主要以大型数据中心的 sever 上的 CPU,硬盘的占用率体现出对业务的请求引起的变化来进行一些预测。相应的我们构造一些机器学习的模型来预测一段时间内 sever 上是否发生异常事件。
方法:
利用机器学习来预测工作负载
基于预测结果考虑改善资源管理的策略
开展工作
数据集:来自百度的面向数据库服务的数据中心。
5466 台 host, 67 天,每隔 10min 的负载记录
(CPU,MEM,DISK)。
模型: ARIMA, LR, SVM, NB, DT, RF。
DDoS 攻击检测
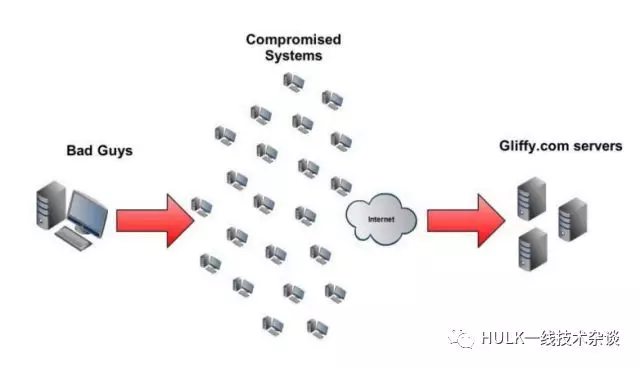
问题定义
目标
寻找合理的高检测率、 低误报率的识别策略
挑战
1.攻击流与正常流相似度高
2.伪造攻击源
3.攻击种类繁多
4.实时检测开销大
研究工作
算法
1.K-Nearest Neighbor
2.Support Vector Machine
3.Decision Tree
4.Random Forest
特征选择
1.Chi-Squared Test
2.Pearson Correlation Coefficient
研究成果
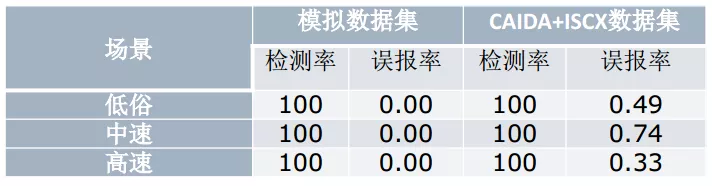
随机源攻击
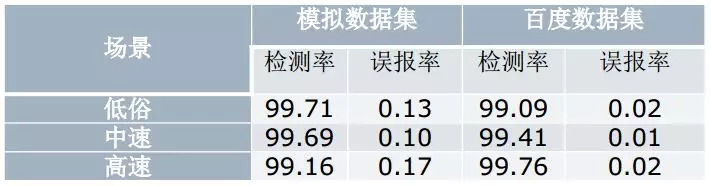
固定源攻击
总结
这两期文章我们从云游戏中的资源管理、搜索引擎中的资源管理、AI 在资源管理中的应用三个方面介绍了大规模分布式系统资源管理。
希望对大家有所帮助~
本文转载自公众号 360 云计算(ID:hulktalk)。
原文链接:
https://mp.weixin.qq.com/s/cIRop16XppLMl95zH5kbHA

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论