

在软件架构中,有一种模式虽鲜为人知的,但值得引起更多的关注。面向数据的架构(Data-Oriented Architecture)由 Rajive Joshi在RTI的2007年白皮书中首次提出,而维也纳大学(University of Vienna)的 Christian Vorhemus 和 Erich Schikuta 在 2017 年的iiWAS论文中又再次对其进行了描述。 DOA 是对传统二分法的颠覆,它介于单体架构和微服务(Microservices)、面向服务的架构(Service-Oriented Architecture)之间。单体架构由一个单体二进制文件(binary)和数据存储组成;微服务、面向服务的架构由许多小型的、分布式的、独立的二进制文件组成,并且每个二进制文件都有自己的数据存储。在面向数据的架构中,单体数据存储是系统中状态的唯一来源,并由松耦合无状态的微服务对其进行操作。
我很幸运,我的前雇主也采用了这种非同寻常的架构选择。它提醒我们,事情可以用不同的方式来做。无论如何,面向数据的架构都不是银弹。它有自己独特的成本和收益。不过,我确实发现,许多大型公司和生态系统都陷入了某种种类型的瓶颈,而这种类型的瓶颈正是面向数据的架构能解决的。
单体架构简介
由于许多架构通常都是在与单体架构(Monolithic Architecture)进行对比的情况下定义的,因此,花一些时间来介绍单体架构是值得的。毕竟,它是服务端软件开发传说中的自然状态。
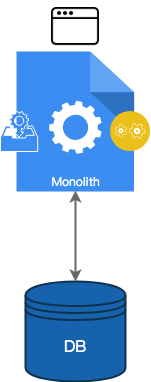
在单体(monolithic)服务中,大部分服务端代码都在一个程序中,该程序与一个或多个数据库通信,并处理功能计算的各个方面。假设有一个交易系统,它接收客户购买或出售某种证券的请求,为它们定价,并完成订单。
在单体服务中,仍然可以将代码组件化并分离到各个模块中,但是程序中不同组件之间的 API 边界不是强制的。程序中唯一经过严格定义的 API 通常是:**(a)UI 和服务端之间的 API(可以使用任何它们约定好的 REST/HTTP 协议);(b)服务端和数据存储之间的 API(可以使用任何它们约定好的查询语言);或(c)**服务端与其外部依赖之间的 API。
面向服务的架构和微服务
另一方面,面向服务的架构(Service-oriented architectures,SOA)将单体程序分解成各个相互独立的、组件化的功能服务。在我们的交易应用程序中,我们可能需要一个单独的服务来作为外部 API 接收请求并处理客户响应;第二个单独的系统来接收报价和其他市场相关的信息;第三个系统来跟踪订单和风险等。这些服务之间的接口都是一个个形式化定义的 API 层。服务之间通常通过 RPC 进行点对点的通信,此外,通过其他通信技术(如,消息传递和发布订阅模式)进行通信也是很常见的。
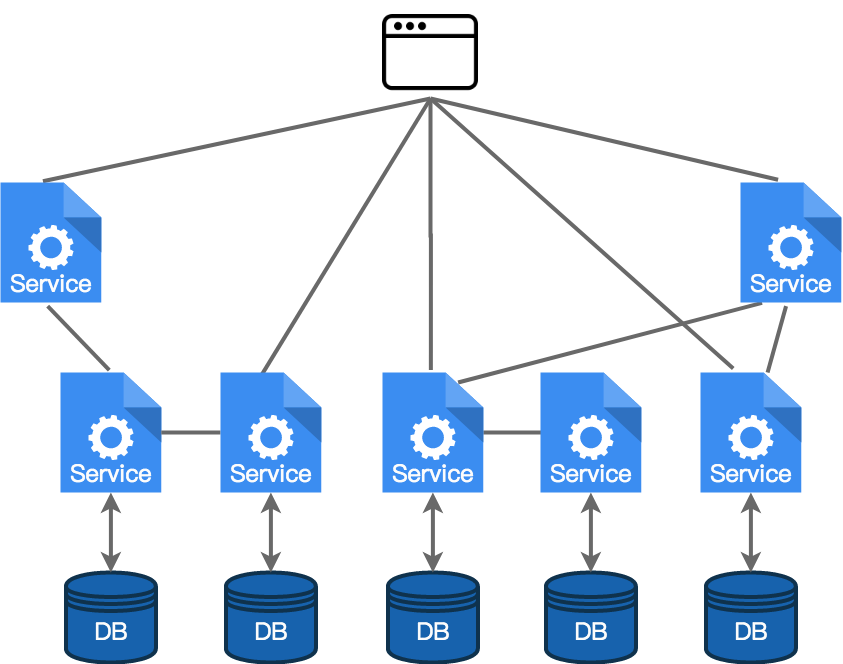
面向服务的架构允许根据需要对不同的服务进行独立(并行)开发和推理。这些服务是松耦合的,这就意味着一个全新的服务现在可以重用其他服务了。
由于 SOA 中的每个服务都定义了自己的 API,因此可以独立访问每个服务并与之交互。开发人员如果要调试或模拟各个功能部分,可以分别调用各个组件,并且新流程可以重新组合这些单独的服务以启用新的行为。
微服务是面向服务的架构的一种形式。根据服务对象的不同,它们可能与 SOA 不同,因为这些服务本应特别小巧轻量,或者它们只是 SOA 的同义词。
规模问题
在 SOA 中,各个组件通过每个组件各自定义的特定 API 直接相互通信。为了通信,每个组件都可以单独寻址(即,使用 IP 地址、服务地址或其他内部标识符来相互发送请求/消息)。这意味着架构中的每个组件都需要了解它们的依赖关系,并且需要专门与它们的依赖进行集成。
依赖于架构的拓扑结构,这可能意味着需要一个额外的组件来跟踪了解所有之前的组件。此外,这可能还意味着要替换一个已经与其他 N 个组件通信的单个服务也是一种挑战:我们需要注意保留我们定义的任何点对点的 API,并确保有一个迁移计划,用于将每个组件从老的寻址服务移动到新的寻址服务上。由于服务到服务的 API 是点对点的(ad-hoc)(1),这通常意味着组件之间的 RPC 可以是任意复杂的,这可能会增加将来 API 变更的影响面。因为如果要对服务中被其他服务依赖的每个 API 进行变更都将是一项艰巨的任务。
我要说的是,随着微服务生态系统的发展,在规模上,它变得很容易受到如下问题的影响:
随着组件数量的增长(2),集成的复杂度也以 N^2 的级别增加。
网络的形状变得很难用先验来推理;即,创建或维护测试环境或沙箱将需要进行大量的推理才能确保图中的任何组件都不具有外部依赖性
我的一些朋友也提出了一些他们在使用大规模面向服务的架构时遇到的问题:
随着 SOA 规模的增长,我发现的另一个问题是服务之间的循环依赖。由于我们是单独发布各个服务的,很少从头开始构建整个系统,因此很容易引入循环并破坏 DAG。
大规模 SOA 另一个值得注意的问题是:它们要求我们提前了解所有未来的客户工作流。假设我们需要跨多个垂直领域来隔离单个工作流的数据,如果没有做到提前了解,那么我们要么会遇到性能问题,因为它将试图保证跨多个持久化存储的事务性;要么需要重新定义要用哪些垂直主服务器来复制(缓存,但实际上是持久化到数据库中的)数据。
面向数据的架构
在面向数据的架构( Data-Oriented Architecture,DOA)中,系统仍然围绕小型的、松耦合的标准来组织组件,就像在 SOA、微服务中一样。但是 DOA 与微服务的区别主要体现在两个方面:
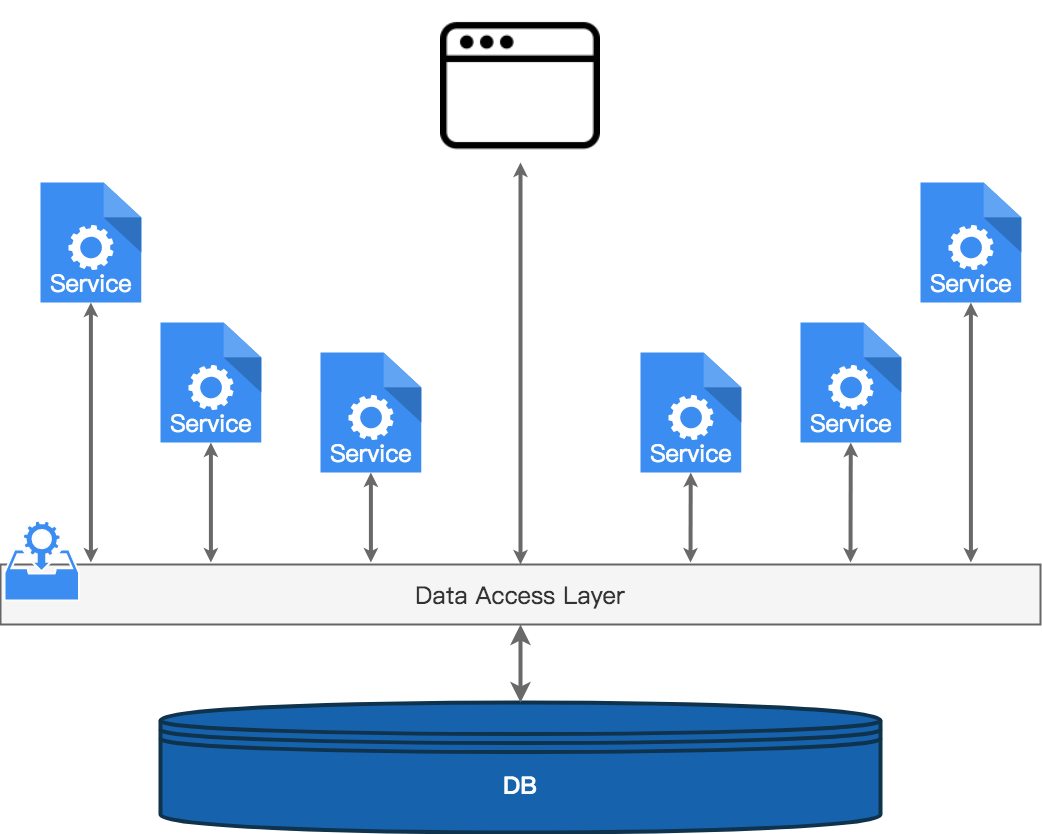
组件通常是无状态的
DOA 没有对每个相关组件的数据存储进行组件化和联合,而是要求按照集中管理的全局模式来描述数据或状态层。
最小化了组件之间的交互,并通过数据层的交互来替代
在我们的交易系统中,接收不同证券报价的组件在我们的数据存储中只是以一种规范的形式来发布价格。系统可以通过查询数据层的价格来使用这些报价,而无需通过特定的 API 向某个特定的服务(或一组服务)请求价格。
这里,集成的代价是线性的。变更 DOA 模式意味着最多只需要更新 N 个组件,而不是它们之间互联的最大值 N^2。
真正令人瞩目的地方在于不同的提供者可以填充独立的高级数据类型。如果我们用一张表来替换一个服务,这并不会带来太大的简化。但是当同一个通用数据类型有多个源时,这样做就会有很大的帮忙。假设交易系统需要连接到多个市场,每个市场都会将客户的请求发布到询价(RFQ)表中,那么下游系统就可以查询这个表,而无需关心客户请求到底来自何处。
组件通信类型
由于在 DOA 中最小化了组件之间的交互,那么如何通过数据层的交互来代替当今 SOA 中组件之间的通信呢?
1. 数据生产和消费
设计 DOA 系统的主要方法是将组件组织成数据的生产者和消费者。
如果我们能够在较高层次上将业务逻辑编写为一系列的 map、filter、reduce、flatMap 和其他一元(monadic)操作,那么我们就可以将 DOA 系统编写成一系列的组件,每个组件都查询或订阅其输入并产生其输出。 DOA 面临的挑战在于这些中间步骤是可见的、可查询的数据,这意味着需要对其进行良好的封装和表示,并且需要将其与特定的业务逻辑概念对应。不过,它的优势在于系统的行为是可从外部观察、跟踪和审核的。
在 SOA 交易系统中,从市场上接收订单的组件可能会使用 RPC 调用来确定如何对订单进行定价、报价或交易。在 DOA 中,微服务接收来自市场的请求(通常是通过 SOA 的方式)并生成询价(RFQ),而其他生产者则生产定价数据,等等。另一个微服务通过请求来查询 RFQ,该 RFQ 会结合它们的所有定价以输出报价、订单或任何其他需要响应的自定义数据。
2. 触发动作和行为
有时,RPC 是组件之间通信的最简单方式。虽然在设计良好的 DOA 系统中(3),其大部分组件间的通信采用的是生产者/消费者模式,但是我们可能仍需要采用直接的方式来让组件 X 告诉 Y 去做 Z。
首先,必须考虑是否可以将 RPC 重组为事件(event)及其影响(effect)。即,不是让组件 X 向发生事件 E 的组件 Y 发送 RPC 请求,而是询问 X 是否可以生成事件 E,并让组件 Y 通过消费这些事件来驱动响应?
这种方法,我称之为基于数据的事件(data-based events),它可以很好地逆转我们通常使用的组件通信方式。它之所以如此强大是因为它使我们可以将“松耦合”这个术语提升到一个全新的层次。系统不需要知道谁在消费它的事件(即,系统不是一个绝对需要知道他们在调用谁的 RPC 调用方),生产者也无需担心事件的来源,只需知道这些事件的业务逻辑语义即可。
当然,存在一种简单的方法可以实现基于数据的事件,在这种方法中,每个事件都是以与 RPC 请求序列化版本 1:1 的对应关系持久化到自身表的数据库中。在这种情况下,基于数据的事件根本不会使系统解耦合。为了使基于数据的事件能正常运行,则要求将请求/响应转换成的持久化事件必须是有意义的业务逻辑结构。
基于数据的事件有时可能不太合适。例如,我们实际上要触发某个特定组件中的行为。在这些情况下,可能仍然需要保留少量的实际组件到组件的 RPC。
面向数据的架构的成功案例研究
高集成问题空间
我之所以一直以交易/财务软件为例,部分原因在于财务通常需要较大的集成表面积。一个典型的允许较小客户进行交易的卖方公司,通常会与许多市场进行整合,以与客户进行互动,而许多流动资金提供者则会通过其获取价格并下订单。在请求进入市场到对客户做出响应之间需要处理的业务逻辑是一个复杂的、多阶段的流程。
在高集成问题空间中,单个服务可能需要了解许多其他服务。为了避免 O(N^2)的集成成本及具有高扇出比率的复杂独立服务的出现,围绕数据生产者和消费者的重新配置系统可以使集成更加简单。假设要进行一个新的集成,不能编写 N 个新系统,也不能编写一个具有向 N 个其他系统进行复杂扇出的系统,那么集成过程可能需要编写一个适配器,该适配器以通用的 DOA 模式生产数据、消费最终的输出并以正确的线性格式来呈现。
隐含地是,集成中出现了一种新的复杂性:需要考虑模式。任何新的集成对我们的系统而言都应该是原生的,并且我们的模式应该能在不添加补充、修改和特殊用例的情况下扩展。这本身就是一项艰巨的任务。但是,当集成的数量足够多时,难度就会降低,而且往往是值得的。
沙箱数据以及数据隔离的推理

如果我们要手动建模或测试,则希望最好能在生产之外进行。但是,某些 SOA 生态系统的架构方式通常意味着,想要知道某个服务所处的环境或特定环境是否完全独立并不那么容易。
环境是指内部一致、连接一致的服务集合,通常或理想情况下,它应与生产的拓扑结构相同。由于 SOA 服务通常是可独立寻址的,因此,环境一致性断言要求环境中的每个服务必须与环境中的其他服务就调用哪个地址能达成共识。RPC、订阅模式(pubsub)和数据流不能从一个环境泄漏到另一个环境中。
很明显,在 SOA 中有很多方法可以解决这个问题,比如转换到能为服务生成正确配置的服务注册中心 (4),或者,如果是通过 URI 访问服务,则隐藏直接的服务地址,以支持某个环境前缀下的不同路径(5)。
然而,在 DOA 中,环境的概念要简单得多。知道组件连接到哪个数据存储层就足以描述它所处的环境了。由于所有组件都不在内部存储任何状态,因此数据是根据定义来隔离的。组件仅通过数据存储进行通信,因此不存在将数据从一种环境泄漏到另一种环境的危险。
面向数据架构比你想象的更接近现实
如今,有很多类似于面向数据的架构的通用案例。将所有(或大部分)数据保存在一个大型数据存储中的数据单体,在系统架构上就非常接近于 DOA。
例如,知识图谱(Knowledge Graphs)就是一个广义的数据单体。也就是说,它们通常不是很通用;许多与业务逻辑相关的状态可能会丢失。
GraphQL通常被用作标准化的数据存储层,就像数据单体一样。 GraphQL 是否能成功地成为 DOA 系统的后端,在很大程度上取决于系统对模式设计的选择:选择与业务逻辑概念相关的通用模式和表,而不是选择特定于该数据特定源的模式和表。
权衡取舍
这种架构也不是万能的。当面向数据的架构消除了某些类型的问题时,就会出现新的问题:它要求设计人员需要认真考虑数据的所有权。当多个写程序修改同一记录时,可能会很麻烦,它通常会鼓励系统仔细划分记录的写入所有权。而且,由于组件间的 API 是在数据中编码的,因此必须采用需要谨慎考虑的共享全局模式。
我记得 Google 的 Protocol Buffers 文档,在讨论如何根据需要将模式中的字段标记为 required 时,它会警告说:“Required Is Forever”。在 Broadway Technology,首席技术官(CTO)Joshua Walsky 曾对 DOA 模式说过类似的话:数据是永远存在(Data Is Forever)。事实证明,出于与 Protobuf 警告类似的原因,在松耦合的分布式系统中,从表中删除列确实非常困难。
我的建议是:如果您担心自己的架构存在水平扩展问题,那么就可以考虑以数据单体为中心来进行设计了。
备注
(1)服务到服务的 API 不一定是点对点的,但是组件到组件的直接通信通常意味着,为了达到某个给定的目的,需在两者之间传递参数。
(2)一个架构的集成复杂度增长是否真能达到 N^2,实际上取决于架构的拓扑结构。如果在我们使用的系统中集成是主要的瓶颈之一,则可能会遇到这个问题。
例如,集成了各种流动资金提供者和场外交易(OTC)市场的交易系统,在理想情况下不应处于这样的场景中:每个管理市场订单的组件都需要了解每个提供流动资金的组件。
(3)非常适合的 DOA 就是精心设计的。
(4)假设服务调用对方是基于直接地址的(例如,IP 或正在运行的进程的某些内部地址模式),并且服务基于命令行参数能知道在何处访问特定的服务,那么就可能需要使用更适合的逻辑来包装这些服务了,对应的逻辑需要根据环境来构造正确的标志。
(5) 例如,与其通过 IP 地址或特定于某个服务的内部 URI 来访问该特定服务,不如将每个服务构造在一个服务端路由的“路径”下。例如,使用 ://env.namespace.company.com/Employees/* 而不是 ://process1.namespace.company.com/*
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论