

知识图谱是以实体为顶点、关系为边构成的有向图,实体具有实体类型。知识图谱在搜索引擎、个人助理等领域用途很大。Amazon 的知识图谱的使命是回答关于产品和相关知识的一切问题。知识图谱在 Amazon 有着非常重要的应用。日前,Amazon 为了将他们不同的知识图谱进行组合,最后使用了新颖的跨图注意力(cross-graph-attention)机制和自注意力(self-attention)机制,发现这两种机制能够实现最先进的性能。InfoQ 中文站翻译并分享此文,以飨对知识图谱感兴趣的读者。
本文已获得原作者授权,由 InfoQ 中文站翻译并发布。
知识图谱(Knowledge Graph)是表示信息的一种方式,相比传统数据库,知识图谱更容易捕获复杂的关系。在 Amazon,我们使用知识图谱来表示 Amazon.com 上产品类型之间的层次关系、Amazon Music 和 Prime Video 上创作者和内容之间的关系,以及 Alexa 的问答服务的一般信息等等。
将知识图谱进行扩展,通常需要将其余另一个知识图谱集成。但是,不同的知识图谱可能对同一个实体(Entity)使用了不同的术语,这可能会导致集成过程中出现错误和不一致现象。因此,我们就需要某种自动化技术,能够进行实体对齐(Entity Alignment),或者确定不同知识图谱的哪些元素引用的是相同的实体。
译注:实体(Entity)是指客观存在并可相互区别的事物,包括具体的人、事、物、抽象的概念或联系,知识图谱中包含多种类别的实体。实体对齐(Entity Alignment)也被称作实体匹配(Entity Matching),是指对于异构数据源知识图谱中的各个实体,找出属于现实世界中的同一实体。是指多个异构数据源和实体,多源数据源的融合。
在一篇被网络会议接受的论文中,我和同仁描述了实体对齐的一种新技术,该技术将实体名称附近的图谱信息纳入考虑范围。在涉及两个电影数据库集成的测试中,我们的系统在 10 个基准系统中性能最好的基础上提高了 10%,这一指标被称为“精确回收曲线下面的面积”(area under the precision-recall curve,PRAUC),它评估了真正类(true-positive)率和真负类(true-negative)率之间的权衡。
尽管我们的系统性能有所提高,但它仍然具有很高的计算效率。我们用于比较的基准系统之一,是一个基于神经网络的系统,名为 DeepMatcher,它是专门为可伸缩性而设计的。在涉及电影数据库和音乐数据库的两项任务中,我们的系统与 DeepMatcher 相比,训练时间减少了 95%,同时在 PRAUC 方面带来了重大的改进。
图是一种数学对象,它由节点(通常描述为圆)和边(通常描述为连接圆的线段)组成。网络图、组织图表、和流程图都是图的常见示例。
我们的工作专门解决了多类型知识图谱的合并问题,或者节点表示不止一种类型实体的知识图谱的合并问题。例如,在我们处理的电影数据集中,节点可能表示演员、导演、电影、电影类型等等。而边表示实体之间的关系,如扮演、导演、编剧等等。
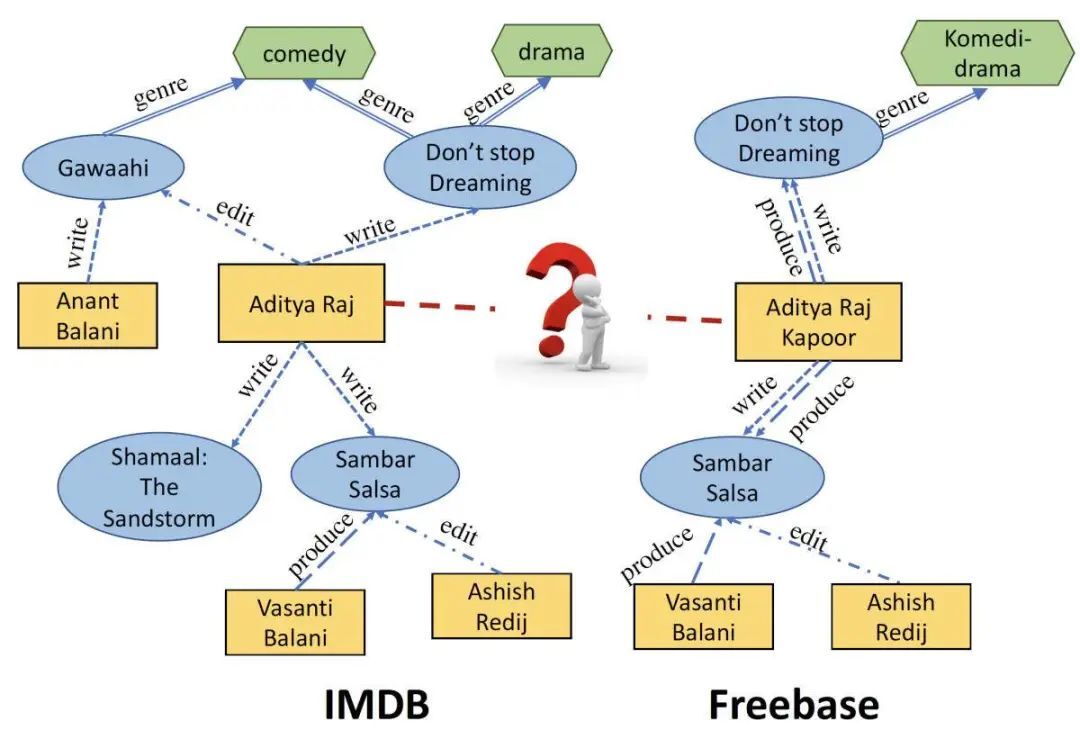
此实例阐明了实体对齐的挑战。IMDB 将电影《梦无止境》(Don’t Stop Dreaming)的作者列为 Aditya Raj,但 Freebase 的数据库却将作者列为 Adiya Raj Kapoor。他们是同一个人吗?
我们的系统是图神经网络的一个例子,这是一种神经网络类型,最近开始流行于与图相关的任务。为了理解它的工作原理,请考虑上面所述的 Freebase 示例,其中包含我们所称的表示 Aditya Raj Kapoor 的节点的“邻域”。这是一个两跳(two-hop)局部图,表示包含连接到 Kapoor 的节点(一跳)和连接到它们的节点(两跳),但它在知识图谱中并没有进一步展开。因此,该邻域由六个节点组成。
对于标准图神经网络(Graph Neural Network,GNN),第一步称为第 0 级步骤,是嵌入每个节点,或者将其转换为固定长度的向量表示。这种表示是为了获取有关对网络任务有用的节点属性信息(在本例中为实体对齐),这种信息是在网络训练过程中学到的。
接下来,在第 1 级步骤中,网络考虑的是中心节点(此处是 Aditya Raj Kapoor)以及与它相距一跳的节点(《梦无止境》和《Sambar Salsa》)。对于这些节点中的每一个,它都会生成一个新的嵌入,该嵌入由节点的 0 级嵌入与其相邻节点的 0 级嵌入之和串联组成。
在第 2 级步骤(两跳网络的最后一步),网络为中心节点生成新的嵌入,它由该节点的第 1 级嵌入和它的相邻节点的第 1 级嵌入之和串联组成。
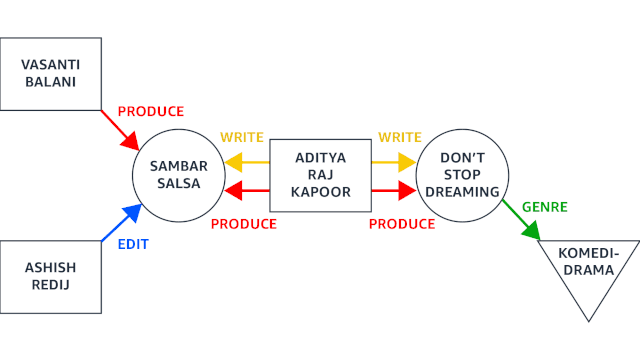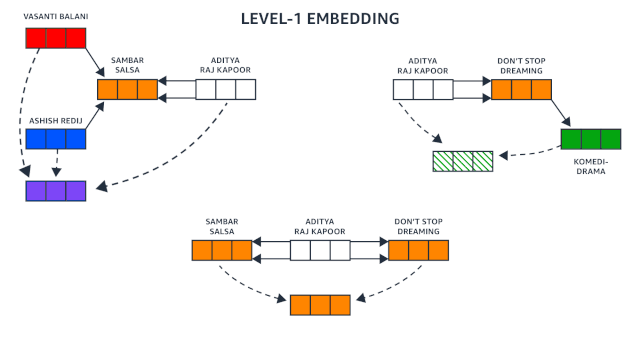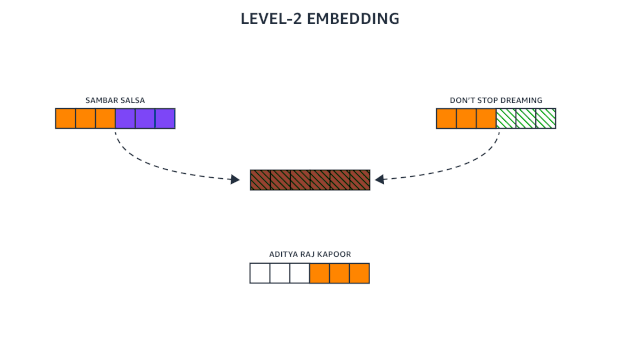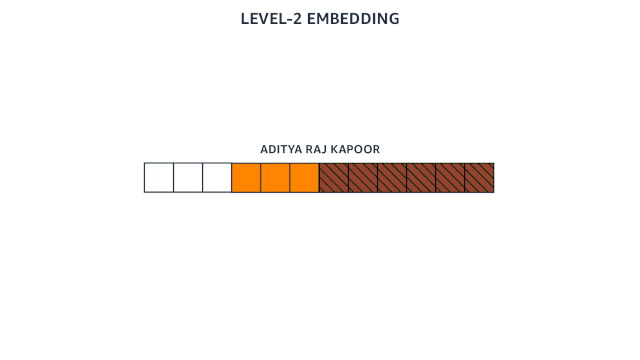
上面动图演示了图神经网络如何使用递归嵌入将两跳图中的所有信息压缩成单个向量。实体之间的关系——例如电影数据库中的制片人和编剧(分别以红色箭头和黄色箭头标注),被编码在实体本身的第 0 级嵌入中(分别为红色块和橙色块)。
在我们的示例中,这个过程将 Freebase 数据库中的整个六节点邻域图压缩为单个向量。对于 IMDB 的十节点邻域图也是如此,比较向量是网络判断图中心的实体(即 Aditya Raj 和 Aditya Raj Kapoor)是否相同的基础。
这是针对实体对齐问题的图神经网络的标准实现。然而不幸的是,在我们的实验中,它的表现非常糟糕。所以,我们进行了两项重大的修改。
第一个修改是跨图注意力机制,在第 1 级和第 2 级聚合阶段,当网络度每个节点的邻居的嵌入进行求和时,它会根据与另一个图的比较对这些求和进行加权。
在我们的这个示例中,这意味着在第 1 级和第 2 级的聚合过程中,出现在 IMDB 和 Freebase 图中的《梦无止境》和《Sambar Salsa》,将比只出现在 IMDB 中的 Gawaahi 和 Shamaa 获得更大的权重。
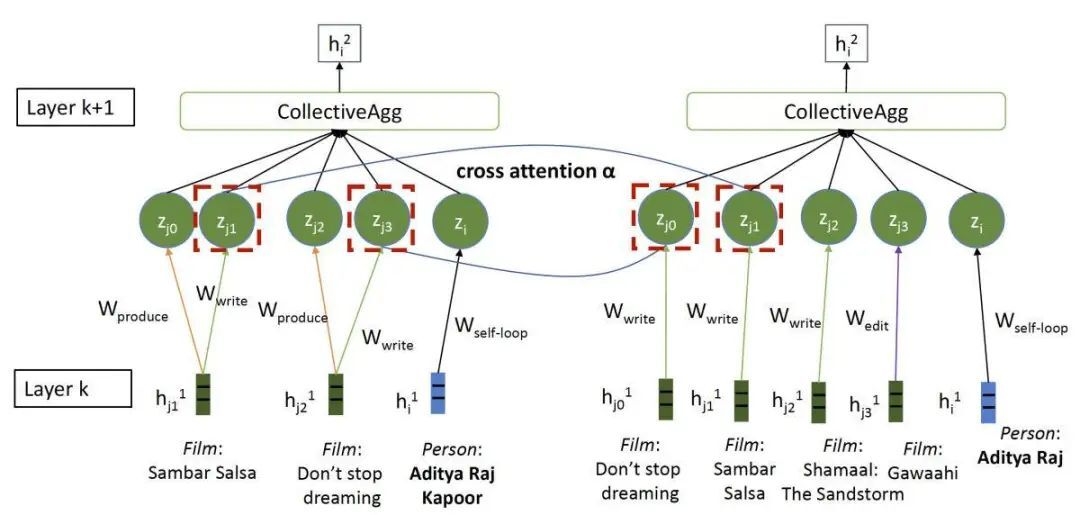
在此实例中,我们的跨图注意力机制(蓝线)为邻域图之间共享的实体的嵌入增加了权重(红线虚线)。
因此,跨图注意力机制强调了图之间的对应关系,而不再强调差异。毕竟,图之间的差异就是将它们的信息组合在一起非常有用的原因。
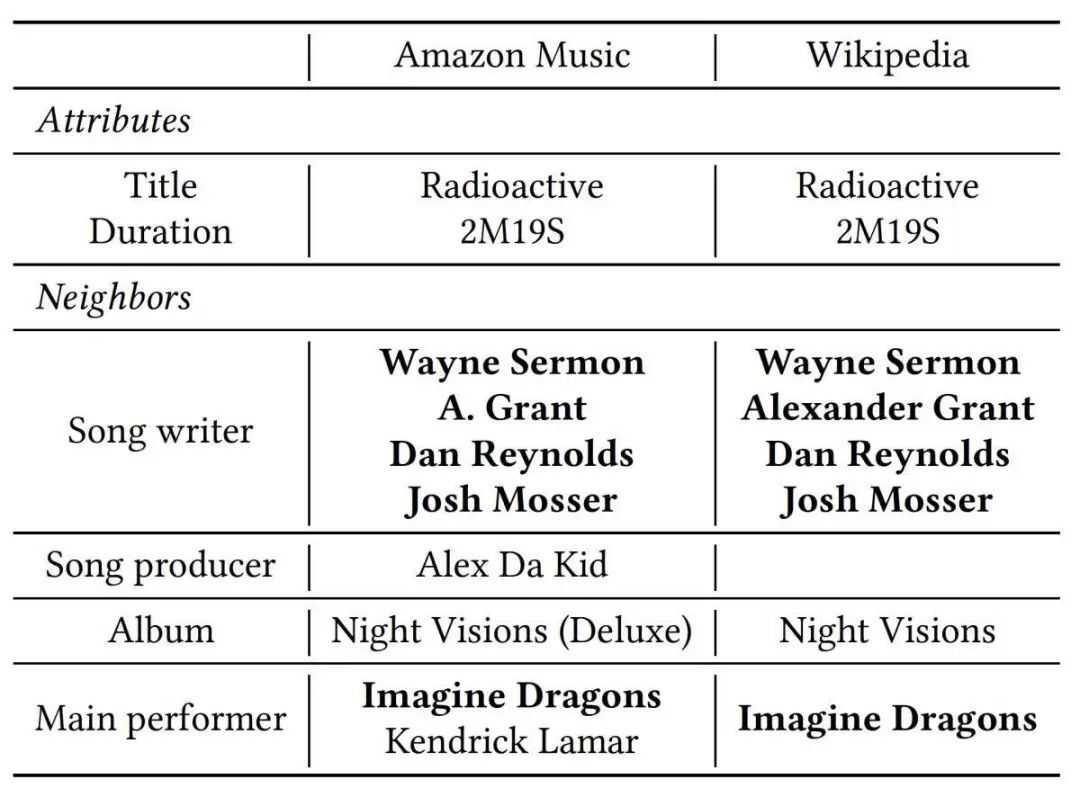
《Radioactive》的原版和混音版是截然不同的曲目,但它们有如此多的共同属性,以至于简单的实体对齐系统可能会将它们错误地分类为相同的曲目。
然而,这种方法存在一个主要问题:有时,图之间的差异比它们的对应关系更重要。想想上面的示例,它比较了梦想之龙乐队(Imagine Dragons)的热门歌曲《Radiative》的两个不同版本,原始专辑剪辑版和 Kendrick Lamar 的混音版。
在这里,跨图注意力机制可能会夸大两条轨迹之间的许多相似之处,而忽略了关键差异:主要表演者。所以,我们的网络也应包括一个自注意力机制。
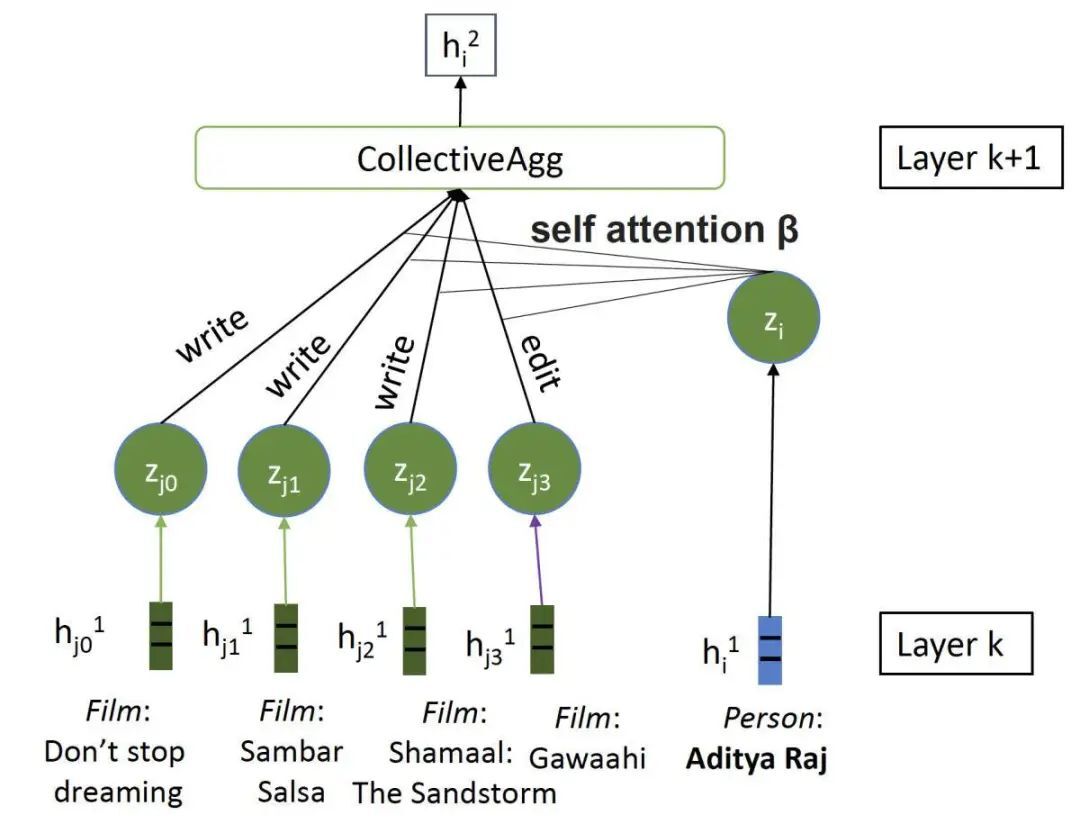
自注意力机制在 Aditya Raj 的运行示例中的应用
在训练过程中,自注意力机制学习一个实体的哪些属性最重要,以将其与看起来相似的实体区分开来。在这种情况下,它会了解到许多不同的唱片可能会共享相同的词曲作者;它们之间的差异在于歌手。
这两个修改主要是为了修改我们的模型,使其相对于我们与之比较的 10 个基准系统的性能有所提高。
最后,简单介绍一下我们用来提高模型计算效率的几种技术之一。尽管出于实体对齐的目的,我们比较了两跳邻域,但我们不一定包括给定实体的整个两跳邻域。我们对邻域中包含的节点数量设置了上限,并且为了选择要包含的节点,我们使用了加权抽样。
样本权重和与相关节点共享相同关系的相邻节点的数量成反比关系。例如,一部电影可能有几十个演员,但只有一个导演。在这种情况下,与包含任何给定演员节点相比,我们的方法在采样邻域中包含导演节点的几率要高得多。以这种方式限制邻域大小,可以防止我们方法的计算复杂性出现失控现象。
作者介绍:
Hao Wei,Amazon 产品图组织的应用科学家。
原文链接:
https://www.amazon.science/blog/combining-knowledge-graphs-quickly-and-accurately

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论