

0. 对话系统简介
对话系统的一般架构如图:
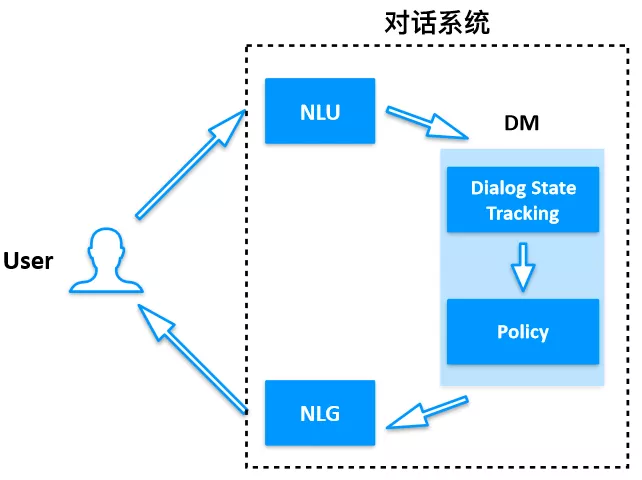
图 1:对话系统一般架构
这是我们所熟知的对话系统框架,这里面主要有:NLU 自然语言理解,DM 对话管理,NLG 自然语言生成 3 个主要模块,DM 里面有 dialog state tracking 用于对话状态追踪,policy 用于对话策略管理。
当我们在执行一个对话任务时,例如“开发票”,系统不仅要识别用户的需求,还需要与外部系统对接,进行订单号的合法性校验,调用开发票接口等,这时候 DM 不仅要完成与用户的交互、管理槽位信息,还需要访问外部接口,管理调用的结果。
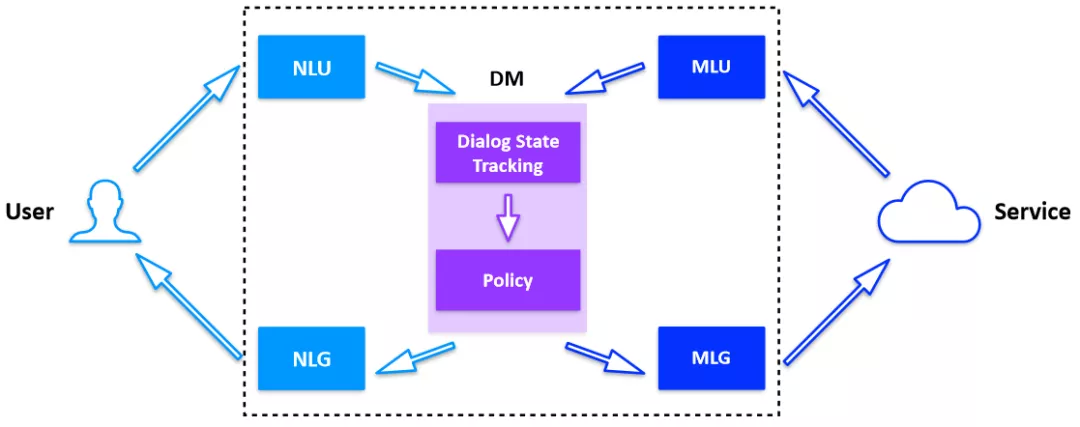
图 2:完整的对话系统架构
当构建好一个机器人后,还需要进行对话的诊断,效果评测,才能发布上线,如果这些工作全都让人来完成,整个过程会非常费力,于是我们引入了用户模拟器来提高整体交付效率。
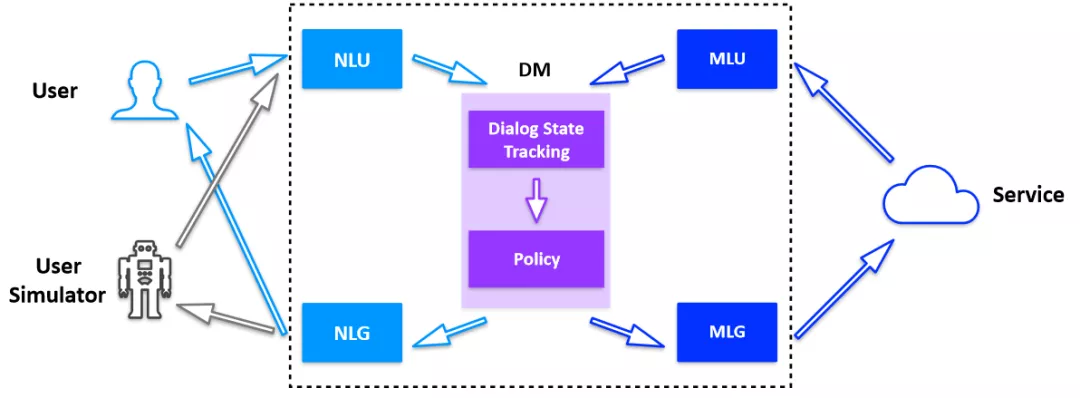
图 3:用户模拟器应用到对话系统
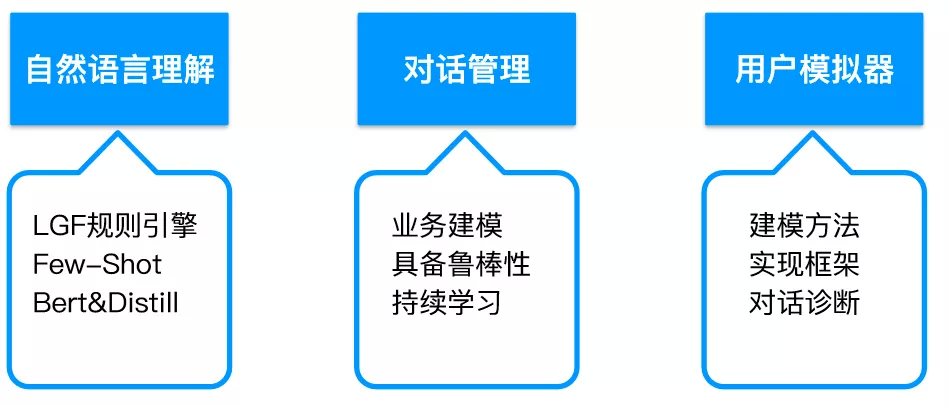
云小蜜对话机器人核心算法主要包括三部分:1. 自然语言理解;2. 对话管理;3. 用户模拟器。
1. 自然语言理解
由于云小蜜对话机器人需要满足各行各业各种场景下的对话服务需求,所以我们的自然语言理解是平台视角下的自然语言理解。根据训练样本的多少,我们把它分为 3 种不同的情况:无样本、小样本、多样本。在没有样本的情况下,我们提供了一套简单易懂的规则表示语法,帮助用户实现快速冷启动。以查天气为例,用户只需写 1 条规则,就能表示 100 多个句子。

图 4:无样本自然语言处理解决方案
在小样本的情况下,比如共 10 个类别的意图,每个意图下有十多个样本,这种情况下还不足以训练一个有监督模型,但我们可以借助平台数据积累的优势,当只有少量样本的情况下,也可以做出比较好的结果。
实现思路:我们先整理出一个大数量级的数据(十万级别),每一个类目几十条数据,为它建立 meta-learning 任务。对于一个具体任务来说:构建支撑集和预测集,通过 few-shot learning 的方法训练出 model,同时与预测集的 query 进行比较,计算 loss 并更新参数,然后不断迭代让其收敛。这只是一个 meta-learning 任务,我们可以反复抽样获得一系列这样的任务,不断优化同一个模型。在线预测阶段,用户标注的少量样本就是支撑集,将 query 输入模型获得分类结果。实验表明,few-shot learning 的效果优于无监督相似度匹配的方法。
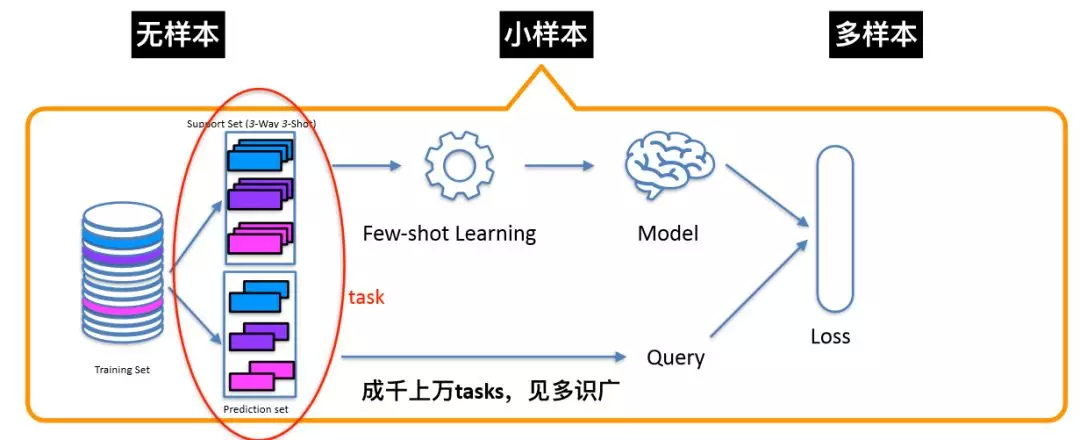
图 5:小样本自然语言处理方案
具体是怎么实现的呢?我们借鉴了图像领域的工作,图像领域大多数工作都只考虑了样本的信息,但是在 NLP 领域样本的信息可能会存在噪声或冗余,比如说“开发票”场景,用户在表述开发票这个事情,除了常见的“我要开发票“、”帮忙开一张发票“以外,他还可能会说:“你好,我前两天在你们店里买了一条裙子,请问现在能帮我开下发票吗?”而这样的句子是普遍存在的,我们需要对这些句子进行归纳,得到类别的信息,然后再与要预测的 query 比较语义相似度。它的神经网络结构分为 3 部分,首先是 Encoder 将句子变成句子向量,然后再通过 Induction Network 变成类向量,最后通过 Relation Network 计算向量距离,输出最终的结果。
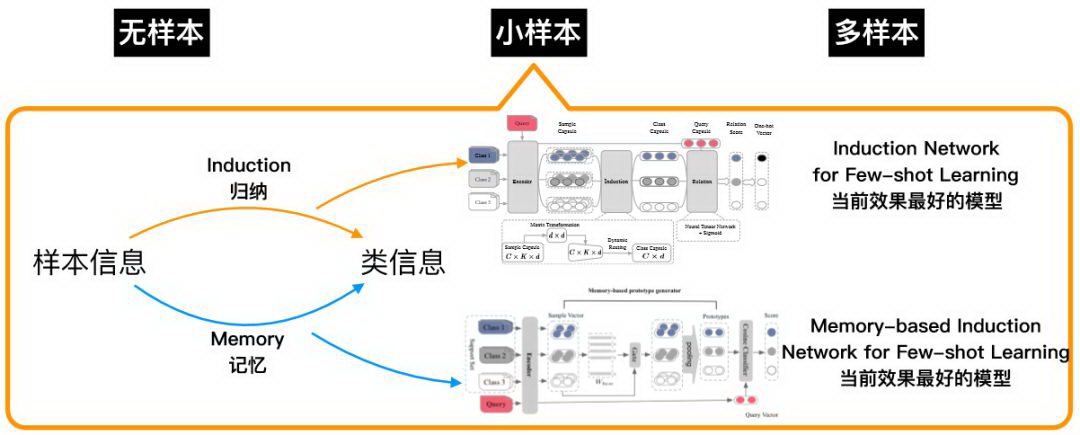
图 6:小样本训练算法
Memory-based Induction Network 是我们在 Induction Network 的基础上引入了 memory 机制,目的是模仿人类的记忆和类比能力,在效果上又有进一步提升。
Induction Network 很关键的一部分就是怎么把样本向量抽象到类向量,我们采用的是 matrix transformation 的方法,下图显示的是 1 个 5-way 10-shot 的数据,转换前,几个类很难区分,类中心不够内聚,转换后,类边界更清晰,更利于下游 relation 的计算。
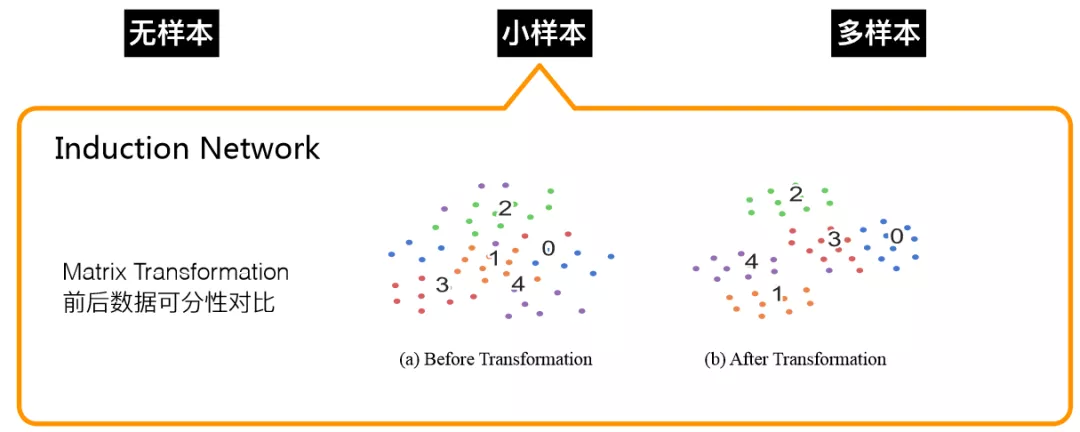
图 7:样本空间转换
当业务方有一定标注数据的情况下,我们就考虑上监督模型了。在云小蜜实际业务场景中,企业相关的标注数据的获取成本是比较高的,因此有监督模型的目标是希望让业务方能够在标注数据量不是很大的情况下达到很好的效果,因此我们构建了一个三层的模型,最底层是具有较强迁移能力的通用模型 BERT,在此基础上构建不同行业的模型,最后用相对较少的企业数据来训练模型。这样构建出来的企业的 NLU 分类模型,F1 基本都在 90%+。
这种模型也有缺点,就是它的结构比较复杂,在线预测的时候延时会比较长,在真实生成环境中应用落地有困难,所以我们通过知识蒸馏的方法来进行模型压缩,在效果相当的同时预测效率更快了。
在实际业务场景的多数情况下,任务型对话和 FAQ 型问答一般都是同时存在的,我们也引入了多任务学习(multi-task learning),能让任务共享底层的信息并互相增强,使得模型具有更强的泛化能力。在政务场景里,我们通过多任务学习, acc 提升两个点以上。
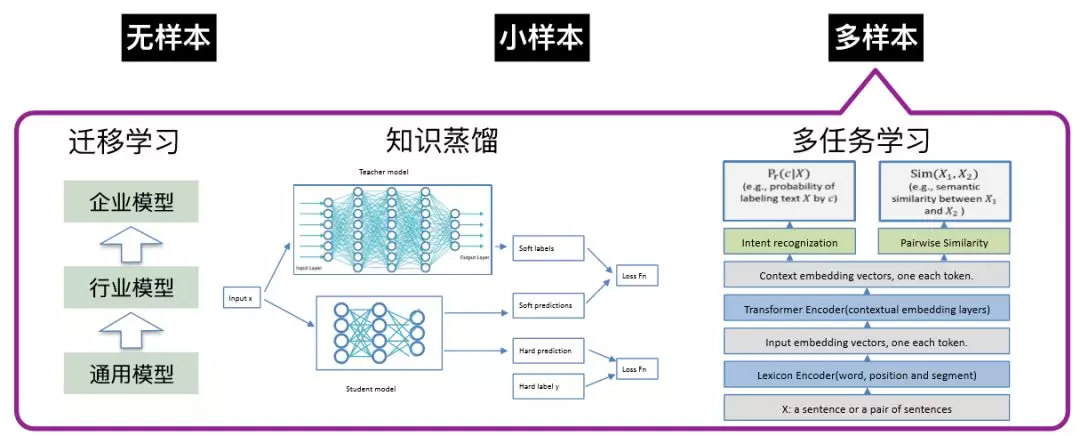
图 8:大规模标注集上的多任务学习
简单小结一下,这是 NLU 的整体能力输出的能力版图:
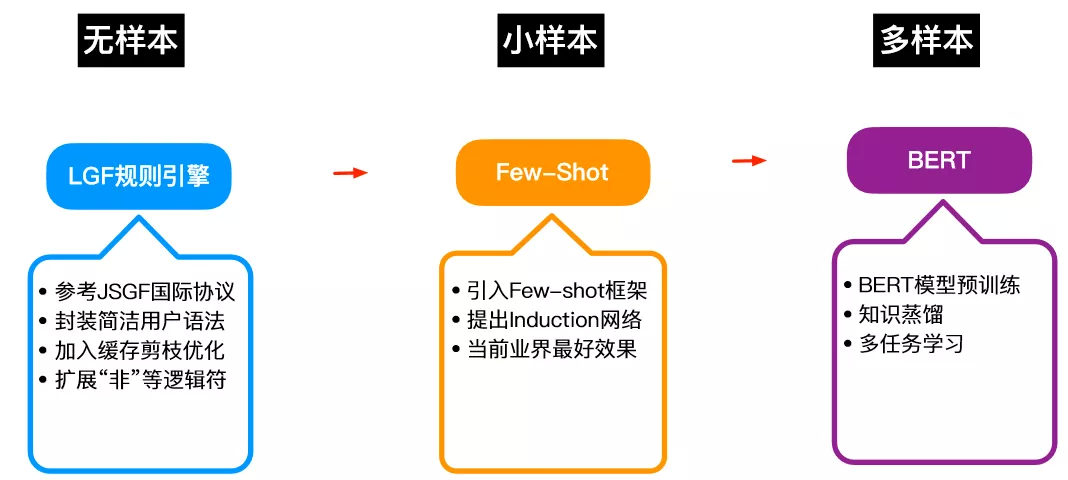
图 9:NLU 的整体能力输出。
2. 平台视角下的对话管理
对话管理成功的三要素:
业务建模:能够对不同行业不同场景的业务进行抽象,能够用一套统一的表示体系建模,保证业务逻辑的正常运行;
具备鲁棒性:能够很好的处理业务未定义的通用对话需求和各种异常情况;
持续学习的能力:能够在与用户交互的过程中,不断的学习,不断适应新场景,根据用户的反馈调整系统的对话策略。

图 10:平台级对话管理的应用需求
2.1 基于 TaskFlow 的业务建模
我们以“火车票”场景为例,一个有经验的卖火车票的售票员在指导一个新售票员的时候,他会把常见的对话样例描述出来,让新售票员知道用户怎么问,我该怎么答,同时他还会告诉新售票员需要查询哪些系统才能获得票务信息,以及有票和无票的情况下分别怎么回复用户。
基于对上述真实场景的观察,我们对整个交互过程进行抽象,我们认为对话的基本单元是一个 turn ( 一轮 ),它可以拆解为 3 部分:用户说、机器人思考和机器人回复,分别对应三个基础节点:触发节点、函数节点和回复节点。上面说的是单轮的情形,如果把所有的后一轮的触发节点接到前一轮的回复节点后面,就构成了一个多轮交互 ( multi-turn ) 的对话。
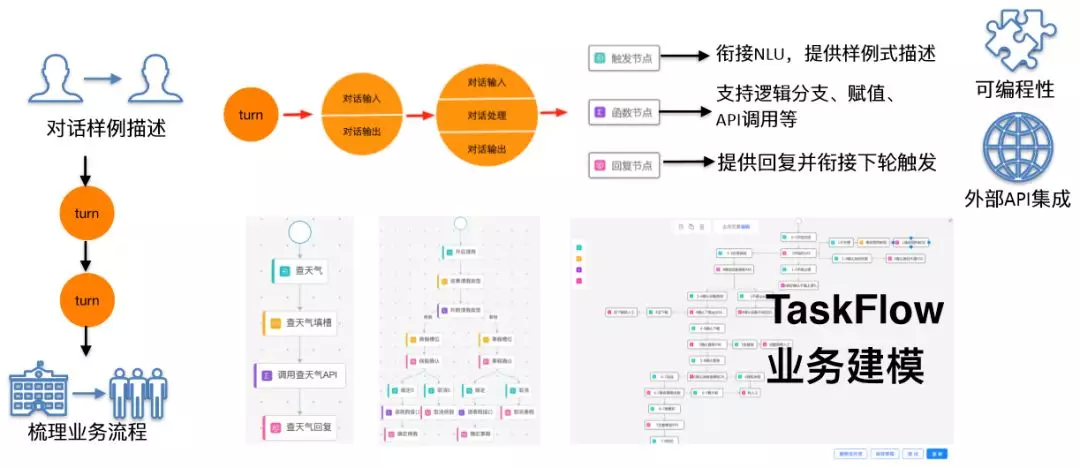
图 11:基于 TaskFlow 的建模框架
为了让 TaskFlow 在平台上执行,我们设计了一种双层状态机的方案,上层是对话逻辑,底层是一套通用的对话引擎,通过这种解耦的设计,不论上层的业务逻辑如何变化,下层都用一套统一的引擎在支撑,如果想赋能上层业务,只需要不断升级底层的能力,上层的所有业务都会受益。
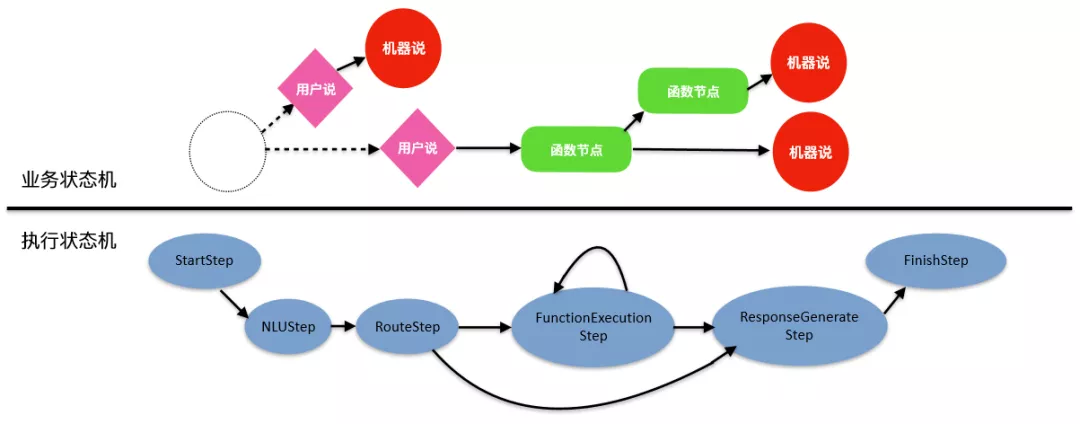
图 12:基于双层状态机的方案
2.2 具备鲁棒性
如果对话管理只能保证用户已定义的业务逻辑正确运行,它的鲁棒性还不够,还需要考虑更多情形,包括:通用对话能力和异常处理能力,如图:

图 13:对话系统的鲁棒性
总体的实现思路是,通过系统内置 TaskFlow 实现对话鲁棒性。以“流量包业务”的对话中模糊澄清为例,我们采用插件化的方式实现,在用户定义的 TaskFlow 基础上,增加澄清 TaskFlow,它的功能包括:
判定是否需要触发澄清;
选择澄清的策略:是隐式澄清还是显示澄清,是单意图澄清还是多意图澄清;
澄清话术的生成。
在上线之前,系统会把这两部分的 Taskflow 进行编译和链接,变成一个可执行的 Taskflow,然后放进执行引擎提供在线服务。其他的功能,比如重听,个性化拒识等都是采用同样的方法实现。
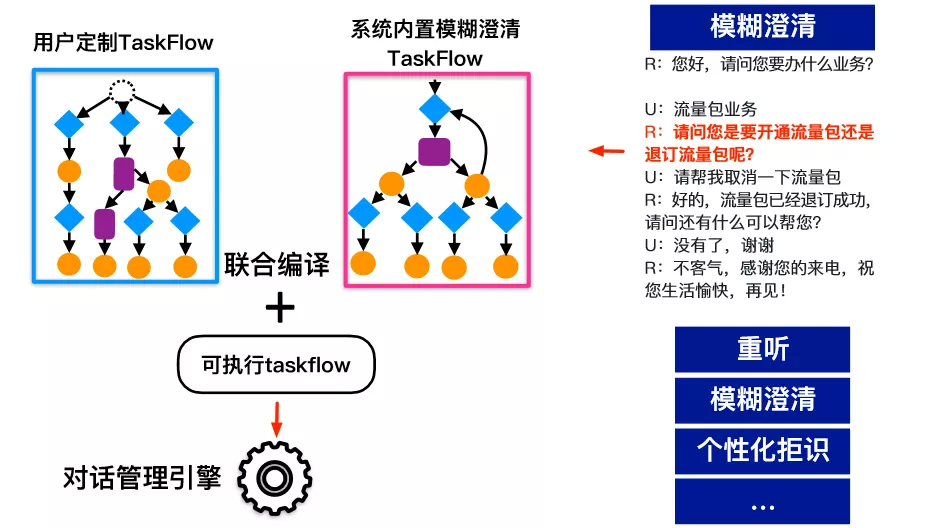
图 14:通过系统内置 TaskFlow 引擎增强系统鲁棒性
2.3 可持续学习
以上的两部分能力都是解决对话中高频、确定的部分问题。如果希望用户在实际对话中越聊越好,仅有以上部分是不够的,需要利用好对话数据,建立对话模型,去 cover 中长尾对话行为,并且基于反馈快速调整对话策略,从而获得更好高价值的智能。
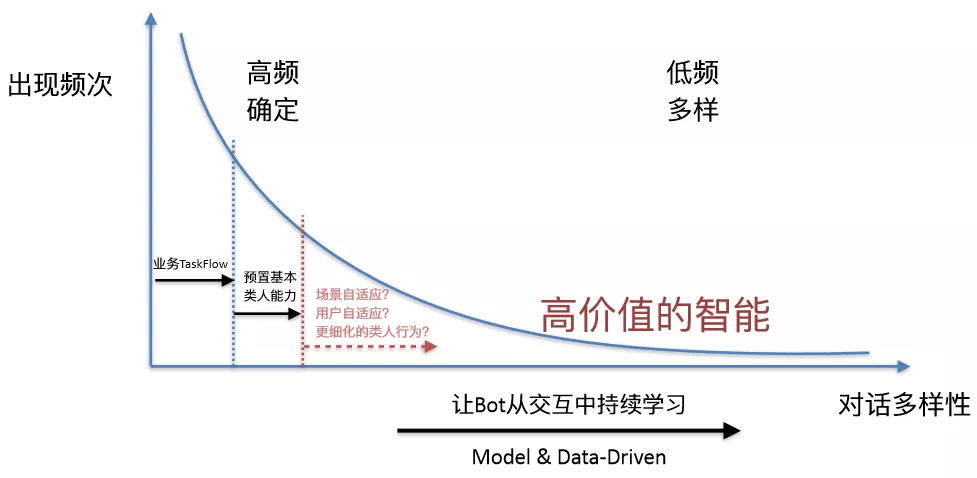
图 15:可持续学习的对话系统
持续学习:

图 16:对话系统增强学习技术架构
总体分为 3 步:
构建 DM 模型,保证它是可学习的;
让模型可交互学习;
支持在线学习。
训练模型得先有数据,我们构建了一个用户模拟器,让它与机器人对话,从而获得大量的带标注的数据,然后分别训练 DST 模型和 Policy 模型,这一步完成了机器人知识的蒸馏,可以获得一个与规则系统效果上等价的 DM 模型。接下来,对 User Goals 进行采样,通过用户模拟器对 DM 模型进行交互,利用 Reward Evaluator 模型进行 Reward 打分,从而获得大量的 Transition 四元组:
<state(t),act(t),state(t+1),reward(t)>
利用增强学习 A2C 算法训练,直至收敛。然后发布到线上,进行在线学习。
2.4 Dialog State Tracking(DST)

图 17:阿里与学术界在 DST 的差异
真实场景下,我们的 DST 与学术界相比,有以下几点主要差异:
多智能体建模:DM 不仅跟用户交互,还跟多个外部服务交互,这些服务都可以看做是一个个智能体;
追踪变量:外部返回的结果会存储在变量中,我们的 DST 扩展了数据形式;
slot-value 假设:学术界假设 slot value 都是离散可枚举的,哪怕是“时间”类型的值,会通过静态化处理进行简化,这显然和实际情况不符,我们不做这样的假设;
追踪次数:我们对每轮对话中 tracking 的次数不做约束。
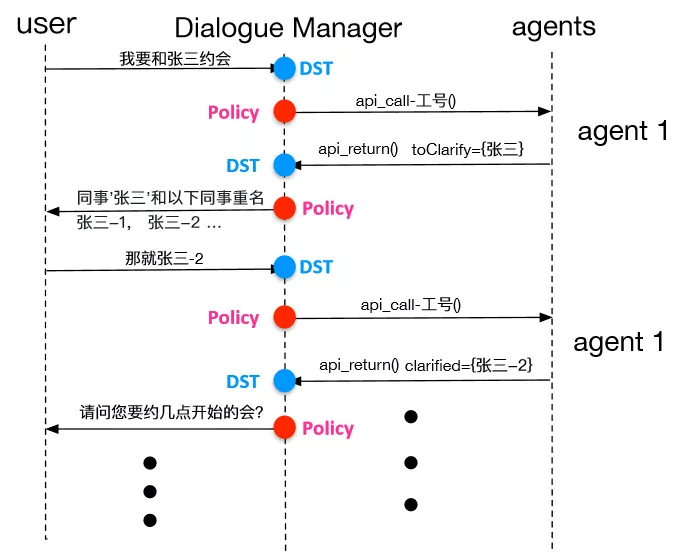
图 18:约会议的追踪过程
如上图所示,一共有两轮对话,每一轮有两次对话追踪。
DST 模型的输入是上一轮对话的状态、上一轮系统行为、当前轮用户 utterance、API 返回,输出是当前轮的对话状态。
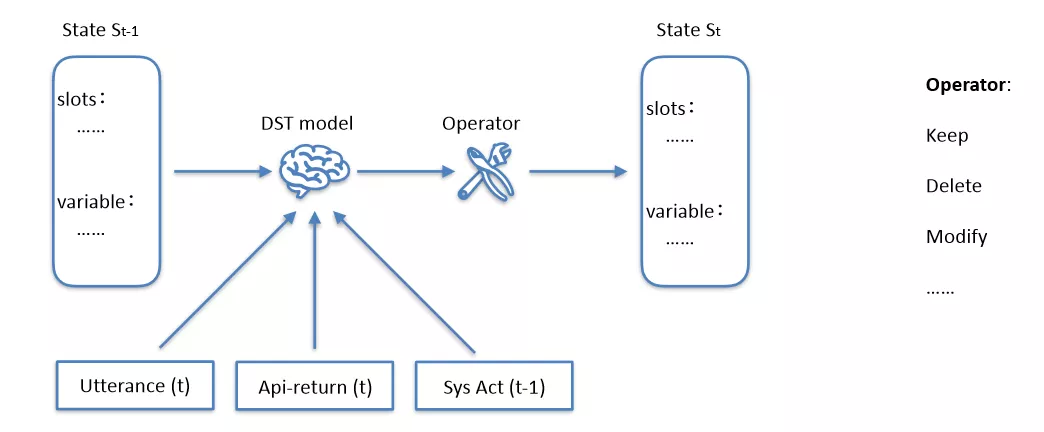
图 19:DST 的状态跟踪流程
这个模型的核心是 operator。在“约会议”场景中,工号的 slot value 一直在变化,开会时间也是不可枚举,如果把 slot value 加入到模型中训练,在预测的时候就会遇到未知的 slot value,此时模型效果就变差。operator 的操作对象是 slot 本身,它只关心信息的流转,而不关心具体 value 是什么,它摆脱了对 value 具体值的依赖,因此具备更强的适应能力。
2.5 Policy: A2C-ER with TaskFlow bootstrapping
下图表示的是增强学习的数据收集和训练的过程。首先,用户输入 user act(t),进入一个对话状态 state(t),经过 feature generator 模块,得到 b(t),接着把它输入到 policy 网络获得 act(t),这个 act 会和对话状态一起输入到一个 Reward Evaluator 模型进行打分,得到 reward(t),然后进入下一个对话状态 state(t+1),这时候会得到一个 experience,它包括:
<state(t),act(t),state(t+1),reward(t)>
四元组,然后通过 off-policy 的方式进行训练,而这里收集到的样本分布和 policy 真正输出的样本分布存在偏差,可以利用重要性采样 ( Importance Sampling ) 的方法进行修正,这样能训出一个比较好的 policy 模型。
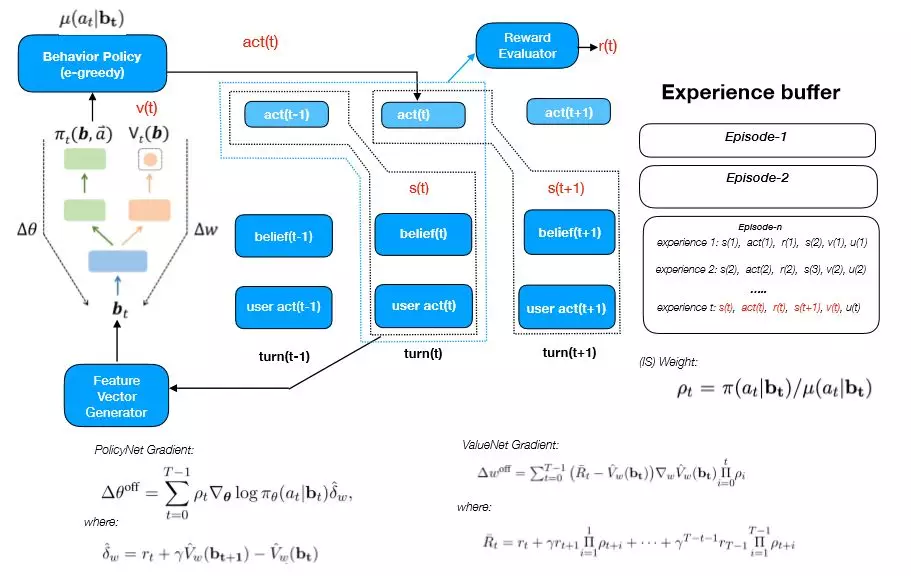
图 20:Policy 的学习过程
3. 用户模拟器
3.1 Simulation System
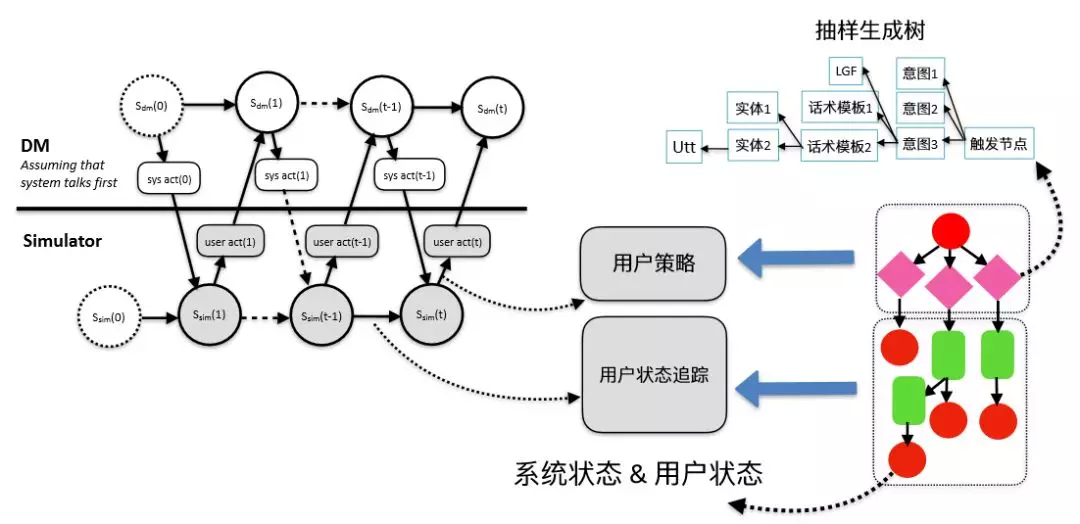
图 21:Simulation System 的实现原理
从上面所说的 DM 模型的训练过程,我们可以看到用户模拟器起到非常重要的作用,这里我们介绍一下用户模拟器的实现原理。
我们的用户模拟器是以 Taskflow 为根基构建的,触发节点展开后形成的抽样树对应用户策略,函数节点+回复节点的串联对应用户状态管理,这是实现用户模拟器的基础。
它由 3 部分组成:User State Tracker、User Policy 和 User Model。其中 User Model 可以针对不同的任务设定不同的参数,比如:生成对话数据,对话评测,它们的 Goal 和 Profile 都可以不一样,这样既保证是一套统一的建模框架,同时又保证了系统的灵活性。
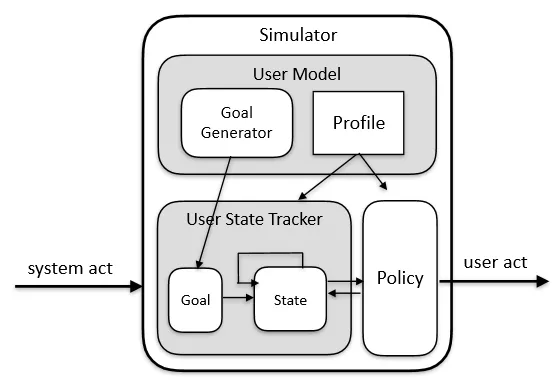
图 22:User Simulator - 实现框架
具体的应用场景如下:
图 23:User Simulator - 应用
3.2 User Simulator - 对话诊断
这是一个公积金查询的对话流,它一共有 175 条路径,如果要去覆盖需要输入 1000 次以上,这个过程耗时耗力。
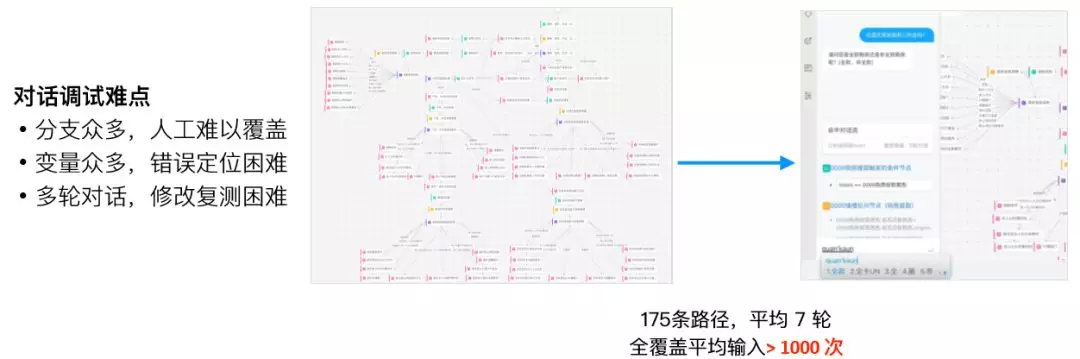
图 24:对话系统的对话诊断难度
为了解决这个问题,我们提出了利用一个机器人诊断另外一个机器人的想法,具体的实现架构如下图所示:
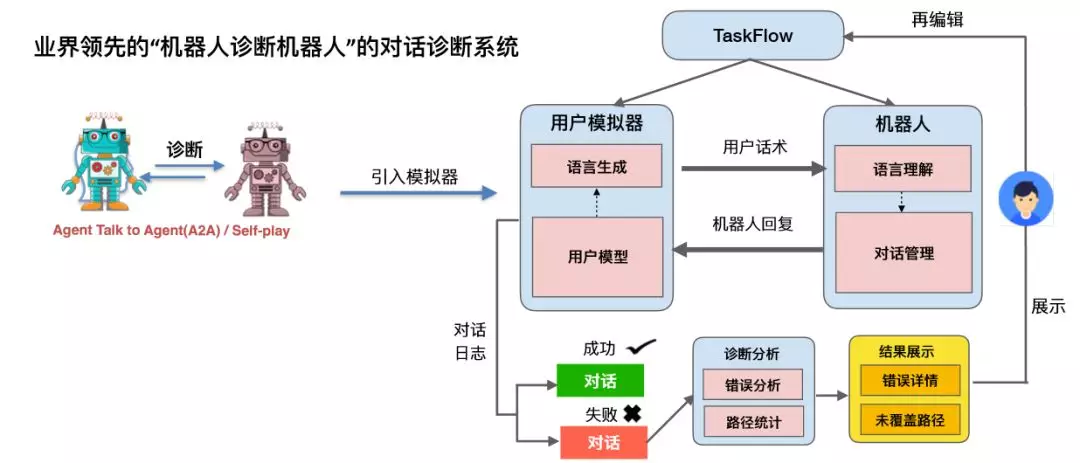
图 25:对话诊断机器人架构
它的基本逻辑是,首先有一个对话系统,它加载的是 Taskflow,对话系统与用户模拟器交互,产生对话日志,这里面有成功的 session 也有失败的 session,如果是失败的,会把它送到一个诊断分析的模块,进行错误分析和路径统计,得到错误详情及问题产生原因,反馈给业务人员,业务人员根据提示修正 Taskflow,然后重新诊断,以此往复直到所有的问题都解决。
4. 总结
总结如上,这是本次分享的主要内容,谢谢大家!
作者介绍:
唐呈光 ( 蒽竹 ),阿里巴巴算法专家。2017 年初加入阿里,对话工厂对话引擎负责人,主导人机对话相关技术在真实商业场景的应用,主要研究方向为用户模拟器和对话系统。此前曾在百度从事搜索推荐系统的算法研发工作,发表国家发明专利 8 项,国际发明专利 2 项。
本文来自 DataFun 社区
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论