

近日,爱奇艺技术产品团队举办了“i 技术会”第 16 期技术沙龙,本次技术会的主题是“NLP 与搜索”。我们邀请到了来自字节跳动、去哪儿和腾讯的技术专家,与爱奇艺技术产品团队共同分享与探讨 NLP 与搜索结合的魔力。
其中,来自爱奇艺的技术专家张轩玮为大家带来了爱奇艺多语言台词机器翻译技术实践的分享。以下为“爱奇艺多语言台词机器翻译技术实践”分享精华内容,根据【i 技术会】现场演讲整理而成。
本次分享的第一部分是爱奇艺多语言台词机器翻译实践开展的相关背景,第二部分是爱奇艺针对多语言台词机器翻译模型的一些探索和优化,最后是该模型在爱奇艺的落地与应用情况。
爱奇艺多语言台词机器翻译实践的相关背景
2019 年 6 月,爱奇艺正式推出服务全球用户的产品 iQIYI App,并通过中台系统为 iQIYI App 提供全球化运营支持,由此开启了海外市场布局之路。作为影视内容服务商,其中必然涉及大量长视频,而长视频的出海,重要的一环就是台词翻译。
目前,爱奇艺已在多个国家布局,涉及多种语言的台词翻译,主要有泰语、越南语、印尼语、马来语、西班牙语、阿拉伯语等等语言,这就使得多语言翻译成为了迫在眉睫的现实需求。
此外,与通用翻译相比,台词翻译有一些独有的特点如:
(1)台词一般句子较短,上下文信息不足,歧义性大;
(2)很多台词来源于 OCR 或 ASR 识别的结果,会有错误,可能影响翻译质量;
(3)在台词对话中往往会涉及很多人物的指代,故而角色名和代词的翻译对于台词翻译来说尤为重要;
(4)部分台词需要结合视频场景信息才能进行语义消歧。
正是爱奇艺海外多国布局的现实需要以及台词翻译的独有特点这两大因素使得台词场景下多语言机器翻译实践成为现实。
多语言台词机器翻译模型的探索和优化
1.one-to-many 翻译模型优化
首先介绍一下什么是 one-to-many 模型。
One-to-many 顾名思义,即通过不同语言翻译之间的参数共享,通过一种模型来达到翻译多种目标语言的目的。
这个模型设计的初衷是节约维护和训练成本。前面已经讲到,目前,爱奇艺已经布局到海外多个国家,这就涉及到多种语言的翻译,如果采用一种语言一个模型的方法,随着目标语言的增多,我们需要训练、部署和维护的模型也会越来越多,导致运营成本的增加。
经调研,我们发现了 one-to-many 模型,它极大地减轻了模型的训练和部署维护的成本,可以充分利用不同语言之间迁移学习的特点,起到相互促进的作用,从而提高模型效果。
图 1 是 transformer 架构,是目前大多数机器翻译模型优化的主流框架,我们也是以此为基础,在上面进行优化。
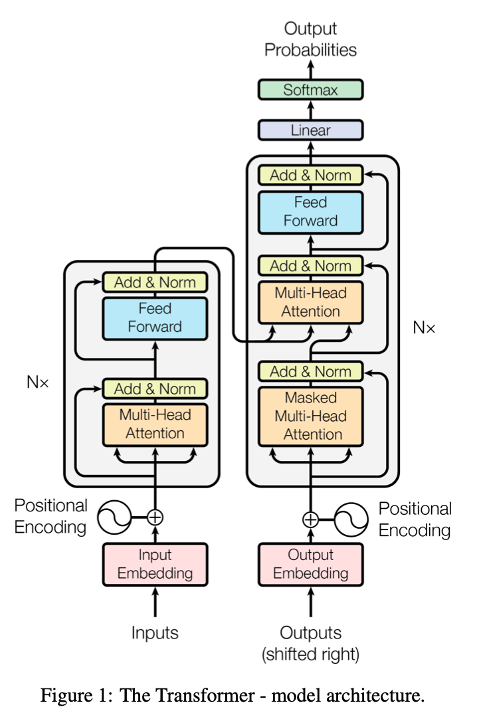
图 1:transformer 模型
而针对 one-to-many 模型,我们借鉴近期大家较为熟悉的预训练模型 BERT,设计了一个特定的输入形式。
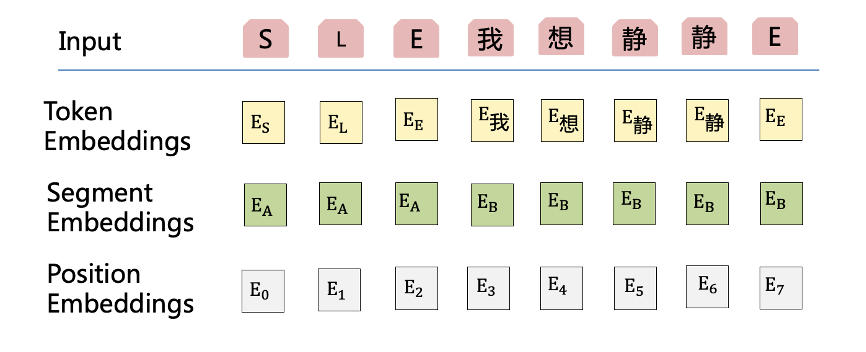
图 2
每个输入的 token 的表达都是由三种 embedding 组成,分别是:token embeddings、segment embeddings、 position embeddings。我们把语言类型 token 作为单独的一个域,那它具有不同于内容的 segment embeddings。
segment embeddings 由两部分组成,一个叫 EA,一个叫 EB。EA 相当于前面语言的 token 的 segment,后面的 EB 就是内容的 embeddings,不同语言的 L 是不同的。
另外语言 token 表达也会作为 decoder 的第一个输入作为指导模型的解码。
2.融合台词上下文信息
刚才提到,台词翻译第一个显著特点就是文本较短,上下文信息不足,容易产生歧义。
这里举个例子,比如“我想静静”就可能有两种意思,一是 let me alone,二是 I miss Jingjing。
仅凭文本,我们很难区分究竟是哪一个意思。
但我们如果能够结合台词的上句和下句,就可以减少这种歧义性。比如,上下句分别是“你走吧”、“再见”,我们就可以知道他想说的是 let me alone。
因此,我们设计了用 BERT style 的方式融合台词上下文的模型,输入时将上文和下文分别与中心句进行拼接,以特定的分隔符做分隔,而在 encoder 输出,我们还会对上句和下句进行 mask,因为在解码这个时候,由于上下句在编码时已经被中心句吸收了相关信息,上句和下句已经不起太多作用。并且,如果不进行 mask,有可能还会引来一些翻译错位的问题。
那么我们是如何融合上下文的呢?
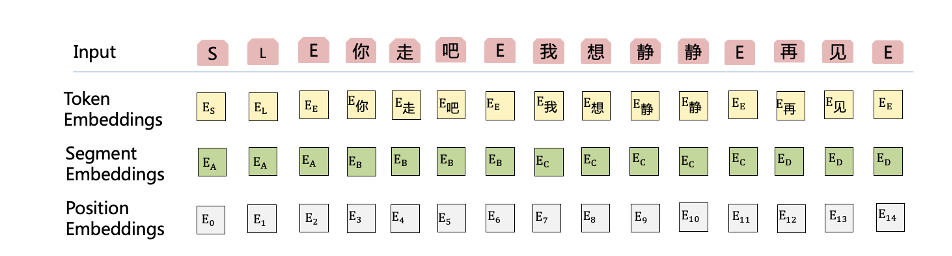
图 3
也是在输入端,我们可以看到图 3 和图 2 的不同就在于我们除了把语言 token 和中心句用三种 embedding 向量融合之外,还会将上句“你走吧”和下句“再见”放在中心句的前后,然后以同样的方式,每个 token 也是三种 embedding 的相加融合,把上下文作为辅助信息,帮助中心句进行消歧。
我们把语言、上句、中心句、下句分别标记为 EA、EB、EC、ED 四种,对这四种信息进行区分,每一种标记都对应一种 segment embedding。
这个输入经过 encoder 之后,我们会对“你走吧”和“再见”进行 mask,也就是在解码的时候隐藏上句和下句,减少它对解码的影响。
3.增强编码能力
除此之外我们还对编码端做了一些提高。
Transformer 里面一个比较主要的组件就是 attention,其中 base 版本包含 8 个 head。我们为了强化 attention,鼓励不同的 head 学习不同的特征,从而丰富模型的表征能力。
下图是这 4 种 attention 的示意图。我们通过不同的 mask 策略实现不同的 attention,图中黑色的方块代表 mask 掉的部分。
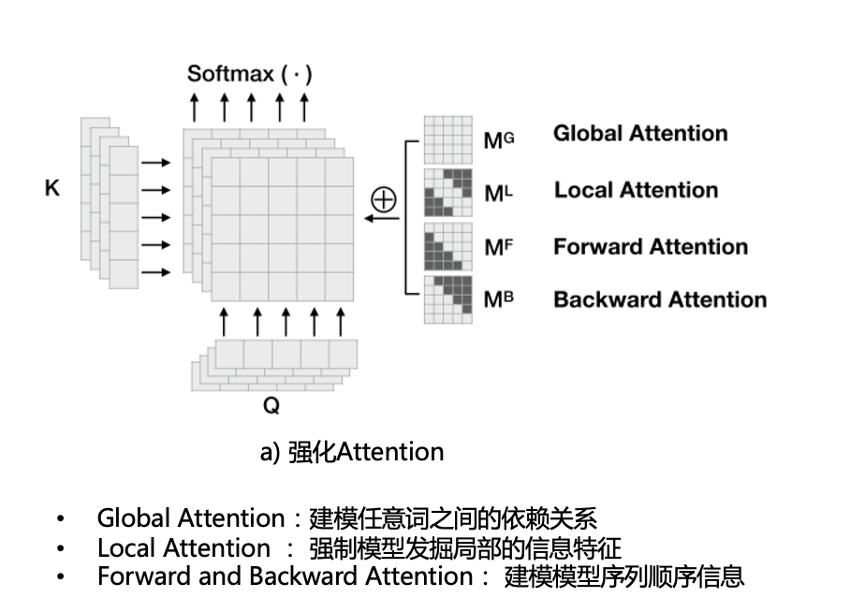
图 4
global attention:建模任意词之间的依赖关系;
local attention:强制模型发掘局部的信息特征;
forward and backward attention:代表建模模型序列顺序信息。forward 只能看到前面,backward 只能看到后面。
通过人为设定特点的 attention,我们强制不同的 head 学习不同的特征,避免产生冗余的情况。
除此之外我们还借鉴 bert,使用 Masked LM 任务增强模型对文本的理解能力。
首先将输入的某一个词进行 mask,然后在输出端进行恢复。比如“你走吧”,“我想静静”,“再见”,其中,“走”,“见”,都会被 mask,输出的时候再被恢复。这就使得 encoder 在这种任务中充分地学习到文本的表达,增进它对文本的理解。同时将 mlm loss 乘以一定的权重加到总体的 loss 上,进行联合训练。
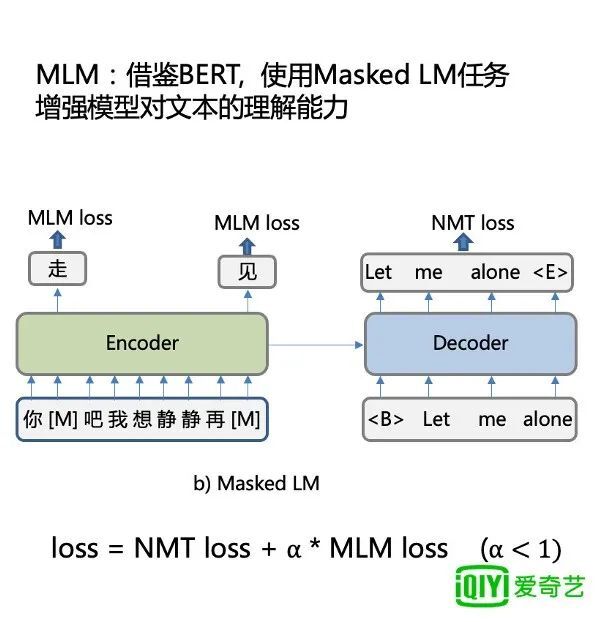
图 5:MLM 模型
4.增强解码能力
为了增强模型解码端的能力,在训练阶段,我们要求解码端在预测每个 token 的同时,增加对全局信息的预测,同时增强模型解码端的全局前瞻能力。
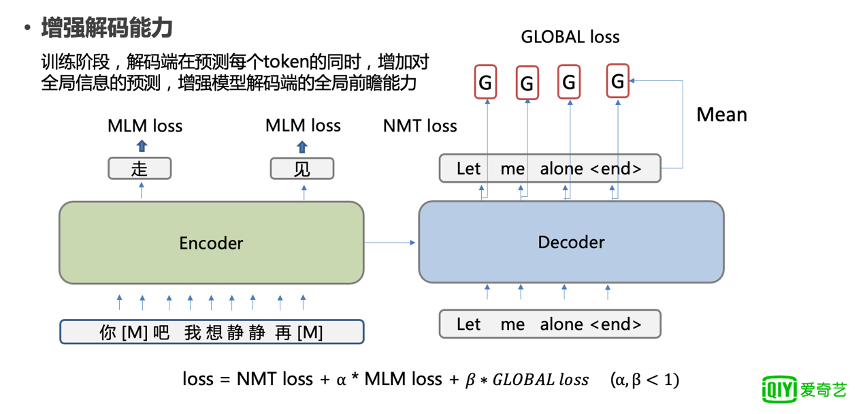
图 6
比如这里的 G 代表 let me alone 的 embedding 的平均向量,每个 token 都会预测这个向量,从而产生 GLOBAL loss。
这个好处就是你在解码每个 token 的时候,我们可以让模型也预计我们将要解码的信息,而不会过分依赖于我们前面已经解码的信息,这样就使得模型具有一定的未来规划的能力。同样这也会产生一个 loss,这个 loss 会和总体 loss 进行加权求和,用了一个β,也是小于 1 的权重,和整体的模型进行联合训练。
5.欠翻译和过翻译问题的解决
欠翻译和过翻译是模型在做翻译时可能会经常遇到的一些问题。
欠翻译是指翻译的目标语言词语缺失,过翻译指的是目标语言词语冗余。
比如上文提到的“你走吧、我想静静、再见”这个案例,就有可能在模型训练不到位的时候产生 let alone,缺少了 me,这就是所谓的欠翻译。
另外,也有可能翻译成 Let me me alone, 重复翻译 me, 这就是所谓的过翻译。
这些都是我们不希望在翻译结果中出现的,而产生这两大问题的一个本质原因就在于解码生成的信息和编码的信息不够对等。
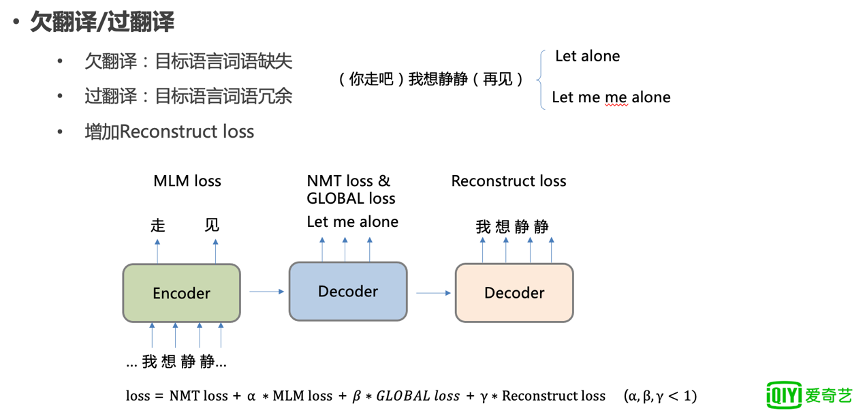
图 7
所以我们增加了一个重建的模块,对其进行约束。
重建模块对解码端的输出通过一个反向翻译的 decoder 翻译成 source,也就是恢复输入,从而使得解码端的信息和编码端的信息保持一致,约束解码端,从而减轻欠翻译和过翻译问题,同样它也会产生一个 loss,和之前一样也是加到总体 loss,进行联合训练。
6.增强容错能力
除了以上的探索优化之外我们刚才也提到了一点,就是我们的台词字幕有很大一部分是来源于 OCR 或者 ASR 识别的结果, 难免会出现一些词识别错误的问题,如果我们不进行特定处理有可能影响最后的翻译质量。
所以我们针对这个台词识别错误的问题,设计了一个容错模块。这个容错模块可以认为是纠错模块。我们借鉴了去年发表的一篇论文所提出的一个模型——T-TA 模型。
这个模块类似大家应该很熟悉的 transformer 结构,但是我们在里面做了一些特定的处理:
首先是它使用了一种叫做 language autoencoding 的方式,输出的每个 token 只能看到其他的 token,但看不到它自己。
也就是说,它输出的表达是由它周边的 token 的意思来产生的。比如 X1 是错的,但 X2,X3,X4 是对的,在你经过大量的数据训练之后,可以通过 X2、X3、X4 去生成正确的 X1,从而达到一种纠错的能力。
那要怎么才能让每个 token 看不到它自己而只能看到周边呢?
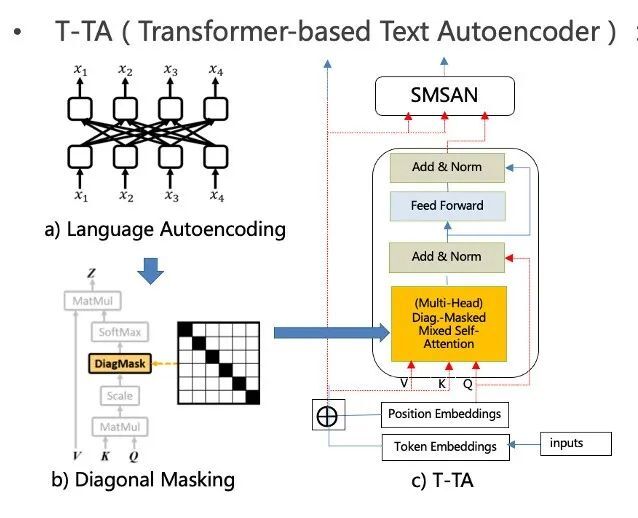
图 8
其实也很简单,就是使用了一个对角线 mask 的方式。这样,每次它就只能看到他其他的 token,中间的黑色对角是看不见的,也就看不到它自己。通过这个方式,对深黄色那部分进行这样的特定处理,从而实现一种纠错能力。
我们可以注意到它的 Q 也只是用到 position embedding,因为如果 QKV 和 Self attention 是一样的,再残差连接的话就会把 token embedding 给加到输出,相当于把你刚刚挖掉的部分又填补上了,会产生信息泄露的问题,这样就训练不出一种纠错的模块。所以 Q 只是 position embedding。
这个模块大致就是这样,但是它们是怎么融合到机器翻译模型中呢?
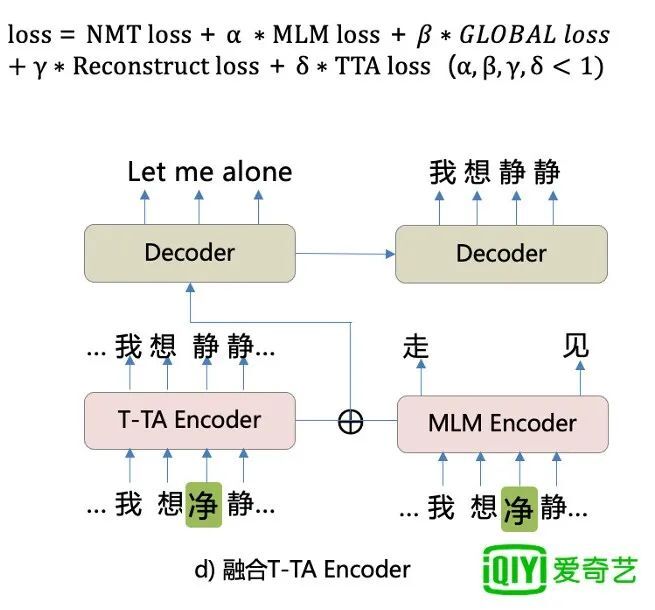
图 9
其实,只要直接和我们之前介绍的那些 encoder 进行相加融合,两个 encoder 输入都是一样的,输出进行相加融合,融合之后再进入后面的两个 decoder 的处理,这样就可以对原始 encoder 的错误进行纠正。比如这里的“静”错输成了“净”,但 T-TA 的 encoder 却能输出正确结果,起到了纠错的作用。
7.代词翻译
刚才我们也提到,在台词翻译领域另一个重要问题就是代词的翻译。
因为在对话中我们会涉及到很多人物之间的指代,比如提到你、我、他等等,在不同的场景下,对应的翻译是不同的,这就大大提高了台词翻译的难度。
遇到这种情况我们该怎么办呢?
针对这个问题,我们首先可以看一下它的表达数量以及表达场景。因为代词在中文里面可能很简单,就是你、我、他,可能也就最多 3、4 种或者 4、5 种,但在其他语言中未必是这样。
比如泰语的代词第一人称就有 12 种表达,第二人称代词有 15 种表达,第三人称有 5 种表达。对于第一人称,这 12 个表达还会随着性别和使用场合的不同而发生变化。
此外,对话人身份之间的差异,也会使得这种代词表达有所区别。这对于台词机器翻译来说,是一个巨大的挑战。所有这些不同场合都需要我们将其区分出来,而这项工作很难仅仅只通过文本来完成。

图 10:中文-泰语人称代词对应表
因此,我们做了一个融合视频场景信息的代词的语义增强。
首先我们通过人脸识别和声纹识别对齐台词和角色,通过这种对齐可以使得每一句台词定位到它所处的场景。再将角色人物属性比如性别,年龄,人物关系,身份等标注好,使角色的信息更丰富、更加立体。
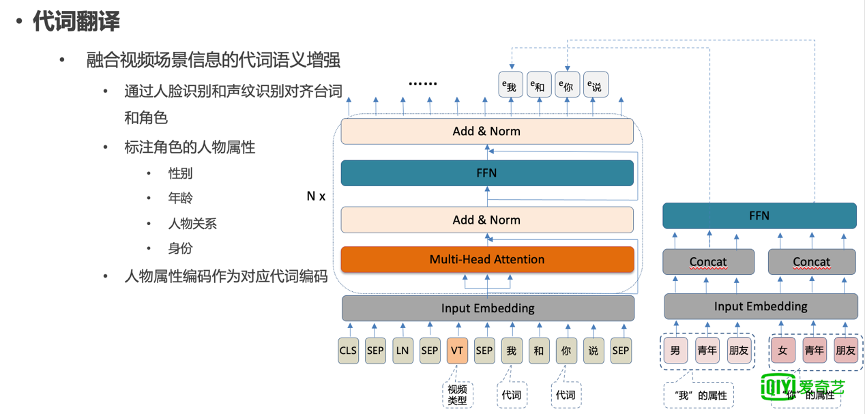
图 11
左边的模型里面有两个代词,就是“你”和“我”,右边的模块是对“我”和“你”的一些信息的编码。比如“我”就属于男性,年龄是青年,“我”和对话人之间的关系是朋友等等。这样分别对“我”和“你”进行编码,编码后用这些信息做一个变换和降维,分别加到对应的代词上,使得解码的时候,知道这个代词所处的场景及人物关系,从而使它能够解码出正确的代词翻译。
8.成语翻译
除代词外,成语的翻译在台词机器翻译中也是比较困难的一个部分。这是因为:
(1)随着多年演变,很多成语都不再只是它字面的意思,而是包含了很多引申义。
这时候如果我们不做特定处理的话,极有可能仅将字面意思翻译出来,影响翻译准确度。所以,我们需要其他的辅助信息,比如释义等。
(2)有些成语具有语义独立的特点,也就是说某个成语的含义和上下文没有那么大的关联。
针对这两个特点,我们设计了针对成语翻译的模块,使用预训练的 BERT,对中文以及中文释义进行编码,直接替换 encoder 的成语输入和添加到 encoder 的输出,来确保成语真正含义的表达能够在模型中学习得到。
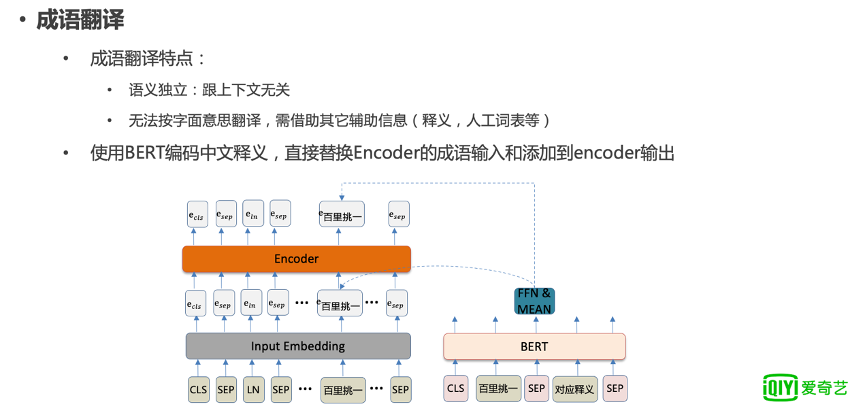
图 12
9.角色名翻译
针对这一部分,我们是通过增加特殊标识以及数据增强的方式,使得模型学习到特定的拷贝能力。大部分的台词从中文翻译到对应的语言的时候,角色名都是以拼音作为翻译的。当然在一些不适宜拼音的语言中,也会有一些其他的对应关系,在这里我们暂且以拼音为例。
我们首先将人名替换成拼音,因为这时候它的真正的文本已经不重要了,最重要的是它将要翻译的目标语言。
比如在图 13 这个例子中,“你认识李飞吗?”,我们首先将李飞中文替换成拼音 li fei,对其增加一个特殊的标识,这也就是想告诉模型:这部分是要拷贝过去的。
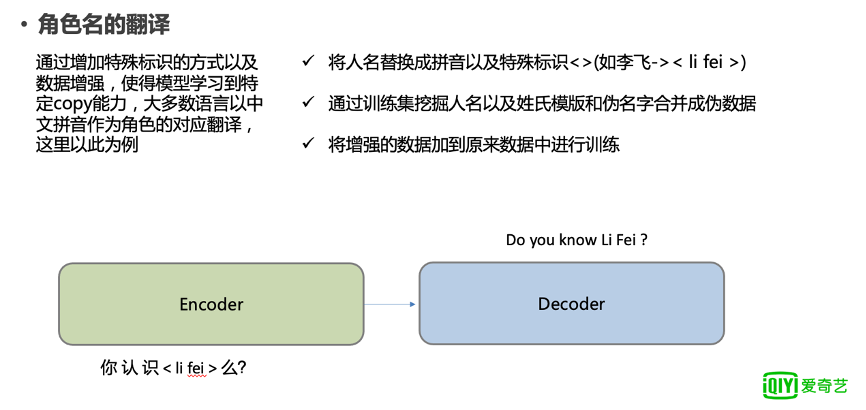
图 13
另外,为了增加模型见过的拼音输入表达的数量,我们通过训练集挖掘了人名和姓氏的模板将其与伪名字合并成增强的数据,将增强数据和原来的数据串在一起进行训练,使得模型能学到足够的拷贝能力。
这种方式通过训练模型,使得机器能够识别这种标识以及里面的拼音,将其复制到对应的位置。
多语言台词机器翻译在爱奇艺的落地应用
我们在多语言台词机器翻译模型上做了一些优化探索后,也对优化后模型的质检差错率做了一些评测,这里列举一部分。
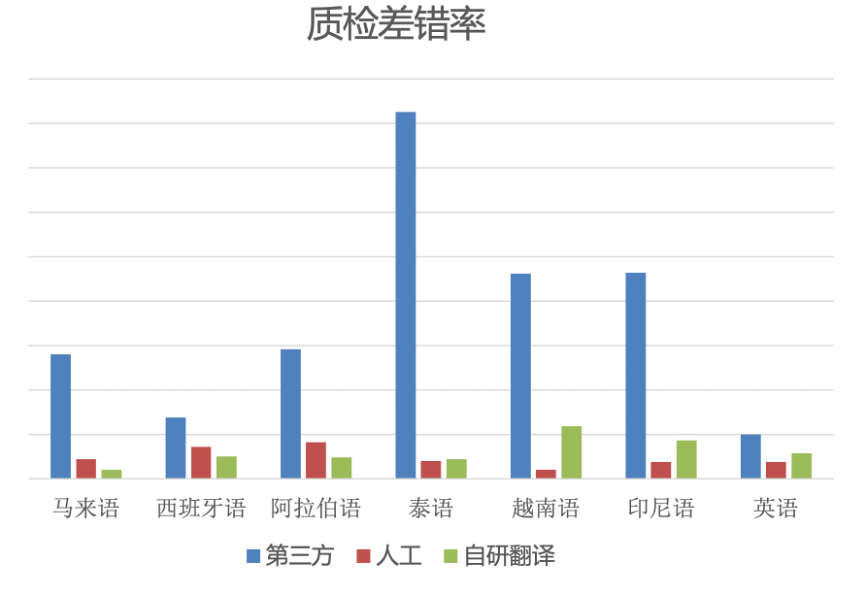
图 14:各语言质检差错率
图中的每种语言都有第三方机器、人工、自研机器三种翻译,其中,自研的机器翻译就是我们自己经过模型探索、优化后的效果。
从图 14 可以看出,我们自研的翻译差错率已经明显低于第三方,这个第三方指的目前市场上最好的第三方。在泰语、印尼语、英语等语言中,我们自研的机器翻译已经接近于人工,而在马来语、西班牙语、阿拉伯语的翻译中,自研翻译甚至已经超过人工。
此外,我们做的翻译主要应用在国际站长视频出海的项目中,目前已经支持从简体中文到印尼语,马来语,泰语,越南语,阿拉伯语,繁体中文等多种语言的翻译。
本文转载自:爱奇艺技术产品团队(ID:iQIYI-TP)
原文链接:爱奇艺多语言台词机器翻译技术实践

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论