
在最近的一篇 Reddit 文章中,Unsloth 发布了他们支持的所有开放模型的全面教程。该教程可以用来比较这些模型的优势和劣势,以及它们的性能基准。
这些教程涵盖了许多广泛使用的开放模型家族,比如 Qwen、Kimi、DeepSeek、Mistral、Phi、Gemma 和 Llama。这些教程对于寻找模型选择指导的架构师、机器学习科学家和开发人员非常有用,其次是关于微调、量化和强化学习的指导。
对于每个模型,教程都包含了模型的描述以及它能良好支持的用例。例如:
Qwen3-Coder-480B-A35B 在代理编码和代码任务方面提供了 SOTA(state of the art)的优势,匹配或超越了 Claude Sonnet-4、GPT-4.1 和Kimi K2。480B 模型在 Aider Polygot 上达到了 61.8%,并支持 256K 的 token 上下文,可扩展到 100 万个 token。
另外,教程提供了如何在 llama.cpp、Ollama 和 OpenWebUI 上运行模型的指导,包括推荐的参数和系统提示。教程提供了如何为 Unsloth 用户微调模型的指导和资源。
对于 Gemma 3n 和 Ollama,指导如下:
如果你还没有安装 ollama,请使用如下命令安装!

运行模型!注意,如果失败,你可以在另一个终端调用 ollama 服务器!我们在 Hugging Face 上传的参数中包含了我们所有的修复和建议参数(温度等)!
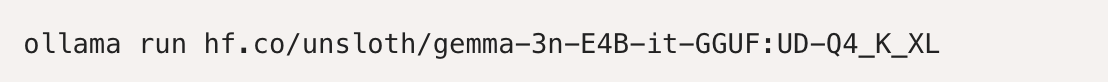
微调指导专门针对 Unsloth 平台,它提供了解决模型实现潜在问题的实际提示。例如,Gemma 3n 微调指南包括以下评论:
Gemma 3n 和 Gemma 3一样,在 Colab 中的 Flotat16 GPU(如 Tesla T4)上运行时遇到了问题。如果你不为推理或微调修复 Gemma 3n,你会遇到 NaN 和无穷大的问题。更多信息如下。
[...]
我们还发现,由于 Gemma 3n 的独特架构在视觉编码器中重用了隐藏状态,它在梯度检查点(Gradient Checkpointing)方面会带来了另一个有趣的现象,如下所述。
像 Unsloth 和 Axolotl 这样的开源微调框架创建者,希望减少团队为特定用例创建模型所需的时间。
对于使用其他微调框架和模型生态系统(如 AWS)的用户来说,他们应该也能发现这些教程对于运行模型的指导和它们能力的总结会很有用。
Unsloth 是一家成立于 2023 年的旧金山初创公司,它在 Hugging Face Hub 上提供了一系列开放的微调和量化模型。这些模型是为特定目的训练的,如代码生成或代理工具支持。量化意味着它们在推理模式下运行会更便宜。Unsloth 文档解释了系统的目的是简化“在本地和[云]平台上的模型训练。我们简化的工作流程处理了从模型加载和量化到训练、评估、保存、导出和与推理引擎集成的所有事情。”
你可以在公司网站上找到Unsloth初学者指南。
原文链接:
Unsloth Tutorials Aim to Make it Easier to Compare and Fine-tune LLMs




