

在 2019 年的 RedisConf 会议上,我演示了一个在 RedisGraph 节点上进行全文 RediSearch 的解决方案。当时讲的有点模糊,但现在,我意识到我们应该解释一下我们是如何做到这一点并发布源代码。
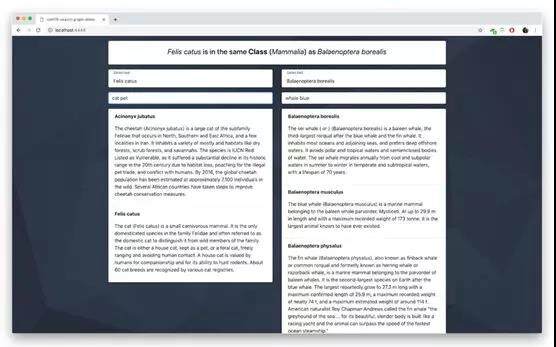
在这个演示中我展示了一个小界面,它支持搜索动物并通过生物分类系统(界、门、类、目等)查看它们之间的关系。全文部分基于维基百科的第一段英文。例如,搜索“宠物猫”和“蓝鲸”,会发现他们都是哺乳动物,而如果搜索“宠物猫”和“雪豹”,则会发现他们都属于同一个科:猫科。
这个演示项目出乎意料地简单,但我应该指出 RediSearch 和 RedisGraph 之间的集成仍处于早期阶段,在编写本文时还没有准备好应用于生产环境。所以,我建议您在了解 RediSearch 和 RedisGraph 的集成将在未来几个月逐渐成熟的前提下,确定此方法是否能够满足您的需求。
让我们再讨论一下如何从源码构建。要完成的第一件事是基于代码库中正确的分支构建 RediSearch 和 RedisGraph。RediSearch 使用的是当前的主分支,而 RedisGraph 是 redisconf 分支。如果您想根据自己的需要构建解决方案,可以从源代码构建这两个模块。RedisGraph 和 RediSearch 的网站上都有关于如何构建的详细说明,这并不困难,只是需要一点时间。
配置模块的位置在 redis.conf 文件中,为了确保在 RediSearch 之前加载 RedisGraph,需要在 redis.conf 文件的模块部分将 RediSearch 的 loadmodule 配置项放在 RedisGraph 的 loadmodule 配置项之前。在完成编辑 redis.conf 之后,需要重启 Redis 服务器让配置生效。
在之前演示的 demo 中,我使用 RedisGraph-bulk-loader 脚本将以下内容从 CSV 加载到 RedisGraph,从而包括了我们收集的数据集。这个数据集只包括哺乳动物,因为其他动物的数据质量较低(非哺乳动物物种很少有好的维基百科描述)。
下面是加载数据的例子:
(gist:https://gist.github.com/stockholmux/0727a4a784a46f8cb9e8329d393a513a)
在这里,key MAMMALS 包含了我们的整个图表。一些重要的注意事项:
•bulk_insert.py 上的-q 开关非常重要,因为它允许在读取 CSV 时进行智能引用。
•调用一次 redis-cli 对所有节点进行批量索引,从而为全文搜索摄取了 7000 多个文档。
现在让我们启动并运行一个 UI。和几乎所有 Node.js 应用程序一样,我们先安装 npm。安装大概需要几秒钟,因为我们不仅要管理 Node 的服务器端文件。还有前端的 Vue.js 组件。如果你最近没有花很多时间在前端 JavaScript 上,那你大概不能使用一个 FTP 和 HTML 文件来实现这些功能。所幸现代前端确实重视工具,所以我们可以安装 VueCLI(我建议遵循 Vue CLI 入门指南)。
在你的前端工具准备好过后,让我们继续来讲 npm 安装和启动运行前端上:
这将创建我们所有前端文件的 dist 目录。现在我们有数据在 Redis 里,我们的前端文件也准备好启动服务,所以我们可以连接 Redis 服务器:
让我们先讨论一下关于我们刚刚打开的这个服务器的一些问题。它构建在 Express.js 上,主要使用 WebSocket 进行通信。我还集成了可视化引擎调试工具,它允许您在单独的浏览器窗口中查看正在执行的命令。你可以把浏览器指向地址:http://localhost:4444。
总之,相对于它所实现的功能来说,它非常的简短——只有 75 行代码。我们的解决方案不需要那么长,因为我们实际上所做的就是接受 WebSocket 连接,根据传递的消息运行 Redis 命令,然后将这些消息与结果一起传递回来。Redis(Graph)做了所有复杂的工作。让我们看看正在执行的命令。
为了搜索关键字,我们运行这个命令:
这很简单。我们的键是哺乳动物,我们使用一个特殊的语法调用了一个特定的函数,它的第一个参数是我们要查找的节点的标签,另一个参数是实际要搜索的字符串。您可以传递有效的 RediSearch 参数进行查询,但请记住,目前这只是全文本搜索,因此不要使用地理空间、标记或数字子句。
一旦我们确定了我们要比较的两种动物,我们就可以使用一个简单的命令进行查询:
GRAPH.QUERY MAMMALS"MATCH (s:Species)-[]->(x)<-[]-(c:Species) WHERE c.fullname =‘Felis catus’ AND s.fullname = ‘Balaenoptera borealis’ RETURN x.name,labels(x) LIMIT 1"
在 server.js 文件中,这些查询被表示为 JavaScript 模板字符串,没有对用户隐藏,用户输入的字符串被直接插入到输入中进行查询。但如果在生产环境中部署类似这样的东西,就需要小心接收和校验用户输入。
如果打算修改前端代码,请确保编辑的是/src 目录,而不是/dist。编辑之后,您需要再次运行 npmrun build 或使用开发服务器(npmrun serve),该服务器自动编译对前端代码的更改,并将其提供给另一个端口。这是一个非常标准的 Vue.js 和 Bootstrap 应用。唯一真正相关的文件是:
/src/App.js, /src/components/panels.vue and /src/components/search.vue.
以上就是一个简单的功能强大的 demo,集成了两个不同的 Redismodule:RediSearch 和 RedisGraph。我鼓励你使用你自己数据集来体验这个 demo。
本文转载自 中间件小哥 公众号。
原文链接:https://mp.weixin.qq.com/s/dbqatouGwg0P_L9_SR5v_Q

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论