

在计算机视觉领域,预训练对下游分类和目标检测等任务效果都有很大的提升。近期,谷歌大脑团队(Google Brain)通过实验证实,自我训练对分类和目标检测等下游任务,效果有很大提升。本文是 AI 前线第 111 篇论文导读,我们将对这项研究工作进行详细解读。
概览
预训练是计算机视觉领域的一种主流范式。由于许多视觉任务都是相关的,因此需要在一个数据集上预先训练一个模型,以帮助另一个数据集。现在普遍的做法是在 ImageNet 分类上预先训练目标检测和分割模型的骨干。这种做法最近受到了何恺明等人的质疑(Rethinking ImageNet Pre-training)。他们给出了一个令人惊讶的结果,即这样的 ImageNet 预训练并没有提高 COCO 数据集的准确性。
与预训练形成鲜明对比的是自我训练。假设我们想使用 ImageNet 来帮助 COCO 目标检测,在自我训练下,我们将首先丢弃 ImageNet 上的标签,然后在 COCO 上训练一个目标检测模型,并用它在 ImageNet 上生成伪标签。再将伪标记的 ImageNet 和标记的 COCO 数据结合起来训练一个新的模型。最近自我训练的成功提出了一个问题:自我训练在多大程度上比预先训练更有效。在预训练失败的情况下,使用 ImageNet 改进 COCO,自我训练能否在准确的设置下有效?
我们的工作是研究自我训练(我们的方法基于噪音的学生训练),并回答上述问题。我们定义了一组控制实验,其中我们使用 ImageNet 作为附加数据,目的是改善 COCO。我们改变 COCO 中标记数据的数量和作为控制因素的数据增强的强度。我们的实验表明,当我们增加数据扩充的强度或增加标记数据的数量时,预训练的价值就会降低。事实上,随着我们最强大的数据增强,预训练显著地降低了-1.0AP 的准确度,这是一个令人惊讶的结果。
我们的实验表明,自我训练与数据扩充有很好的相互作用:更强的数据扩充不仅不会损害自我训练,而且有助于自我训练。在相同的数据扩充下,使用相同的 ImageNet 数据集,自训练可以获得正的+1.3AP 改进。这是另一个显著的结果,因为它表明自我训练在预先训练失败的情况下是有效的。这两个结果为上述问题提供了一个肯定的答案。
一种越来越流行的预训练方法是自监督学习。自监督学习方法在不使用标签的情况下对数据集进行预训练,以期构建更通用的表示形式,用于更广泛的任务和数据集。我们研究了使用最先进的自监督学习技术对 ImageNet 模型进行预训练,并与基于 COCO 的标准监督 ImageNet 预训练进行了比较。我们发现,使用 SimCLR 的自监督预训练模型具有与有监督 ImageNet 预训练相似的性能。当自我训练有帮助时,这两种方法都会在高数据/强增强环境下损害 COCO 的性能。我们的结果表明,监督和自我监督的预训练方法都不能随着标记数据集大小的增长而扩展,而自训练仍然是有用的。
然而,我们的工作并不排斥计算机视觉的预训练。在我们的实验中,微调预训练的模型比从头开始训练和自我训练要快。加速比从 1.3 倍到 8 倍不等,这取决于预先训练的模型质量、数据扩充的强度和数据集大小。在难以收集足够的标记数据的应用程序中,预训练也可以受益。在这种情况下,预训练效果很好;但自我训练也有利于有或无预训练的模型。例如,我们对 PASCAL 分割数据集的实验表明 ImageNet 预训练提高了准确性,但是自训练在预训练的基础上提供了额外的+1.3%的 mIOU 提升。事实上,即使使用相同的数据集,预训练的好处也不会抵消自我训练的收益,这表明了自我训练的普遍性。
进一步,我们探讨了在 COCO 和 PASCAL 数据集上自我训练的局限性,从而证明了该方法的灵活性。我们对 COCO 数据集进行自训练,以开放图像数据集作为未标记数据源,RetinaNet 和 Spinnet 作为目标检测器。这种组合在 COCO 测试集上达到 54.3AP,比最强的 Spinnet 模型好+1.5AP。在分割方面,我们使用 PASCAL-aug 集作为未标记数据的来源,使用 NAS-FPN 和 EfficientNet-L2 作为分割模型。这种组合在 PASCAL VOC 2012 测试集上达到 90.5AP,超过了 89.0AP 的最新精度,后者还使用了额外的 300M 标记图像。这些结果证实了自我训练的另一个好处:它对未标记的数据源、模型体系结构和计算机视觉任务非常灵活。
相关工作
在整个深度学习的历史中,预训练一直备受关注。21 世纪初,深度学习的复苏也始于无监督的预训练。NLP 中无监督预训练的成功重新激起了人们对计算机视觉无监督预训练的兴趣,尤其是对比训练。在实践中,有监督的预训练在计算机视觉领域是非常成功的。例如,许多研究表明,在 ImageNet、Instagram 和 JFT 上预先训练的 ConvNets 可以为许多下游任务提供强大的改进。
有监督的 ImageNet 预训练是用于目标检测和分割的最广泛的初始化方法。然而,如果我们考虑一个非常不同的任务,比如 COCO 目标检测,ImageNet 的预训练效果并不好。
与何恺明等人相比,我们的工作更进一步,更详细地研究了预训练在计算机视觉中的作用,包括更强的数据扩充,不同的预训练方法(监督和自监督),以及不同的预训练检查点质量。
本文没有深入研究有针对性的预训练,例如使用一个目标检测数据集来改进另一个目标检测数据集,原因有二。首先,有针对性的预训练费用高昂,而且不可扩展。第二,有证据表明,在与目标任务相同的数据集上进行预训练仍然无法产生改进。例如,Shao 等人发现开放图像对象检测数据集上的预训练实际上会损害 COCO 的性能。更多有针对性的预训练分析见[42]。
我们的工作证明了自我训练的可扩展性和普遍性。最近,自我训练在深度学习(如图像分类[9,10]、机器翻译[11]和语音识别[12,43])方面取得了显著进展。与我们的工作关系最密切的是 Xie 等人的工作。他们在自我训练中也使用了强大的数据扩充,但用于图像分类。更接近应用的是用于检测和分割的半监督学习,他们只研究孤立的自我训练,或者没有与 ImageNet 预训练进行比较。他们也不考虑这些训练方法和数据扩充之间的相互作用。
方法论
3.1 方法和控制因素
数据增强:我们使用了四种不同的增强策略来增强检测和分割。这允许在我们的分析中改变数据增强的强度。我们根据文献、AutoAugment 和 RanAugment 中的标准翻转和 scale jittering 来设计我们的增强策略。标准翻转和裁剪策略包括水平翻转和缩放抖动。随机抖动操作将图像大小调整为目标图像大小的(0.8,1.2),然后对其进行裁剪。AutoAugment 和 RandAugment 最初是用标准的抖动设计的。我们在 AutoAugment 和 RandAugment 中增加了尺度抖动(0.5,2.0),发现性能得到了显著改善。我们得出了四个数据我们用于实验的增强策略:FlipCrop、AutoAugment、具有更高比例抖动的 AutoAugment、使用更高比例抖动的 RandAugment。在全文中,我们将它们分别称为:Augment-S1、Augment-S2、Augment-S3 和 Augment-S4。最后三种增强策略比何恺明等人提出的策略更为强大。他使用基于 FlipCrop 的策略。
预训练:为了评估预训练的有效性,我们研究了不同质量的 ImageNet 预训练检查点。为了控制模型容量,所有检查点使用相同的模型体系结构,但在 ImageNet 上具有不同的精确度(因为它们的训练方式不同)。我们使用 EfficientNet-B7 架构[51]作为预培训的强大基线。对于 EfficientNet-B7 架构,有两个可用的检查点:1)使用 AutoAugment 训练的 EfficientNet-B7 检查点,在 ImageNet 上达到 84.5%的 top-1 准确率;2)使用噪声学生方法训练的 EfficientNet-B7 检查点,利用额外的 300M 未标记图像,达到 86.9%的 top-1 精度。我们将这两个检查点分别表示为 ImageNet 和 ImageNet++。随机初始化的训练用 Rand Init 表示。因此,我们所有的基线都比何恺明等人都强。他只将 ResNet 用于他们的实验(EfficientNetB7 检查点比 ResNet-50 检查点具有大约 8%的准确性)。表 1 总结了数据增强和预先训练的检查点的符号。

自我训练:我们的自我训练实现基于噪音的学生训练,有三个步骤。首先,教师模型是根据标记的数据(例如 COCO 数据集)进行训练的。然后教师模型在未标记的数据(例如 ImageNet 数据集)上生成伪标签。最后,学生模型训练是联合优化人类打的标签与伪标签上的损失。学生的主要噪声源是通过数据增强和先前在相关模型中使用的其他噪声方法。我们对各种超参数和数据增强的实验表明,用这种标准损失函数进行自我训练是不稳定的。为了解决这个问题,我们实现了一种标准化损失的技术。
3.2 附加实验设置
目标检测:我们使用 COCO 数据集(118k 个 images)进行监督学习。在自我训练中,我们将 ImageNet(1.2M images)和 OpenImages(1.7M images)作为未标记的数据集进行实验。在实验中,我们在 EfficientNet-B7 骨干网络上采用 RetinaNet 检测器和特征金字塔网络。我们使用图像大小为 640×640,从 P3 到 P7 的金字塔级别,每像素 9 个锚,如[14]所述。训练批大小为 256,带权重衰减为 1e-4。该模型的学习率为 0.32 和余弦学习率衰减策略。对于所有使用不同增强强度和数据集大小的实验,我们允许每个模型进行训练,直到它收敛为止(当训练时间较长时,停止有助于甚至损害在一个有效数据集上的性能)。例如,当两个模型随机初始化时,使用 Augment-S1 进行 45k 次迭代,使用 Augment-S4 进行 120k 次迭代。对于使用 SpineNet 的结果,我们使用文[15]中报告的模型结构和超参数。当我们使用 SpineNet 时,由于内存限制,我们将批处理大小从 256 个减少到 128 个,并将学习率提高一半。除批处理大小和学习速率外,超参数遵循 SpineNet 开源存储库中的默认实现。所有 SpineNet 模型也使用 sigma 为 0.3 的 Soft-NMS。在自我训练中,我们使用硬分数阈值 0.5 来生成伪框标签。我们使用总共 512 个批处理大小,COCO 的 256 个,伪数据集的 256 个。其他训练超参数与监督训练相同。
语义分割:我们使用 PASCAL VOC 2012 分割数据集的训练集(1.5k images)进行监督学习。在自我训练中,我们使用增强 PASCAL 数据集(9k images)、COCO(240k images,结合标记和未标记的数据集)和 ImageNet(1.2M 图像)进行实验。在 EfficientNet-B7 和 EfficientNet-L2 主干模型,我们采用 NAS-FPN 模型架构。我们的 NAS-FPN 模型,使用重复 7 次的深度卷积网络。我们使用 P3 到 P7 的金字塔级别,并将所有的特征级别上采样到 P2,然后通过求和运算将它们合并。我们在合并后的特征后应用 3 层 3×3 卷积,然后附加 1×1 卷积进行 21 类预测。对于批量大小为 256、权重衰减为 1e-5 的 EfficientNet-B7 和 EfficientNet-L2,学习率设置为 0.08。该模型采用余弦学习率衰减策略进行训练。EfficientNet-B7 经过 40k 次迭代训练,EfficientNet-L2 经过 20k 次迭代训练。对于自我训练,我们对 EfficientNet-B7 使用 512 的批处理大小,对于 EfficientNet-L2 使用 256 的批处理大小。批处理的一半由监督数据和另一半伪数据组成。其他超参数遵循监督训练中的参数。此外,我们使用硬评分阈值 0.5 来生成分割掩码,分数较小的像素被设置为忽略标签。最后,我们应用多尺度推理增强算法(0.5,0.75,1,1.25,1.5,1.75)来计算伪标记的分割掩码。
实验
4.1 增强和标记数据集大小对预训练的影响
这一节扩展了何恺明等人的发现。他研究了 COCO 数据集的预训练的弱点,因为他们改变了标记数据集的大小。与他们的研究类似,我们使用 ImageNet 进行监督前训练,并改变 COCO 标记的数据集大小。与他们的研究不同,我们还改变了其他因素:数据增强能力和预先训练的模型质量(更多细节见第 3.1 节)。如前所述,我们使用以 EfficientNet-B7 架构为主干的 RetinaNet 对象检测器。以下是我们的主要发现:
当使用更强的数据增强时,预训练会影响性能
我们分析了当我们改变增强力量时,训练前的影响。在图 1-Left 中,当我们使用标准数据扩充(Augment-S1)时,预训练会有所帮助。但是,随着数据增强强度的增加,预训练的价值就降低了。
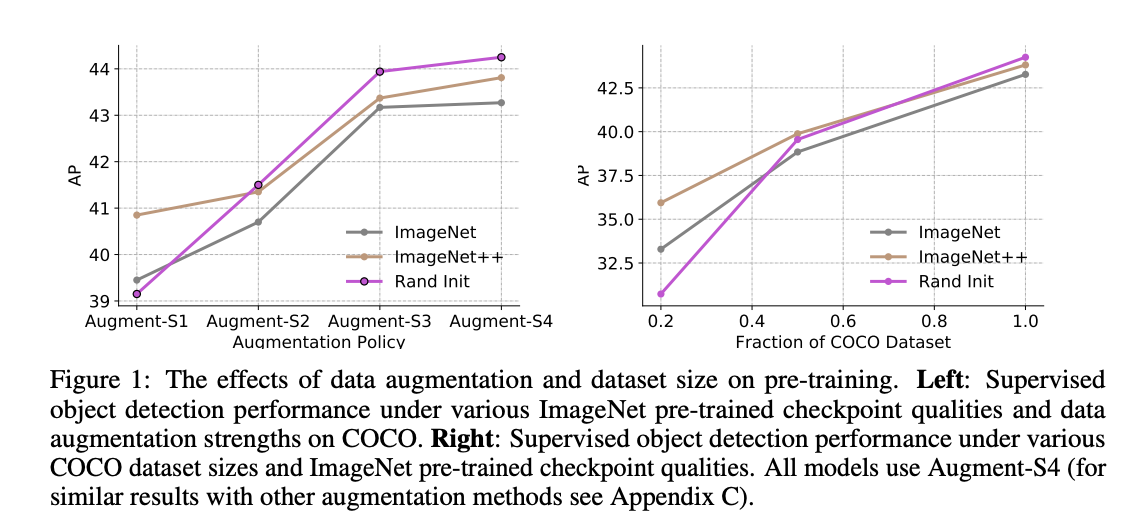
此外,在强扩充机制下,我们观察到,预训练实际上会对成绩造成很大的伤害(-1.0AP)。何恺明等人没有观察到这一结果。因为预训练只会轻微地影响他们的表现(-0.4AP)或者在实验中是中性的。
更多的标记数据会降低预训练的价值
接下来,我们分析了改变标记数据集大小时预训练的影响。图 1-右图显示,预训练在低数据区(20%)是有帮助的,在高数据区是中性或有害的。这一结果与何恺明等人的观察结果基本一致。这里的一个新发现是,检查点质量确实与低数据状态下的最终性能相关(ImageNet++ 在 20%COCO 上的性能最好)。
4.2 扩增和标记数据集大小对自我训练的影响
在这一部分,我们分析了自我训练,并与上述结果进行了对比。为了保持一致性,我们将继续使用 COCO 对象检测作为感兴趣的任务,ImageNet 作为自训练数据源。与预训练不同,自我训练只将 ImageNet 视为未标记的数据。再次,我们使用 RetinaNet 目标检测器作为 EfficientNet-B7 网络的主干,以与先前的实验兼容。
以下是我们的主要发现:
自我训练在高数据/强增强系统中有帮助,即使在训练前受伤的情况下也是如此。
与上一节类似,我们首先分析了当我们改变数据增强强度时目标检测器的性能。表 2 显示了四种数据扩充方法的自训练性能,并将它们与监督学习(Rand Init)和预训练(ImageNet Init)进行了比较。在这里,我们还展示了自我训练和预训练到基线的收益/损失。结果证实,在预训练受损的情况下(强数据扩充:Augment-S2,Augment-S3,Augment-S4),自我训练有显著的帮助。当预训练的损害为-1.0AP 时,它在基线之上提供了超过+1.3AP 的提升。在 ResNet-101 上也得到了类似的结果。

自我训练适用于不同的数据集大小,是对预训练的补充
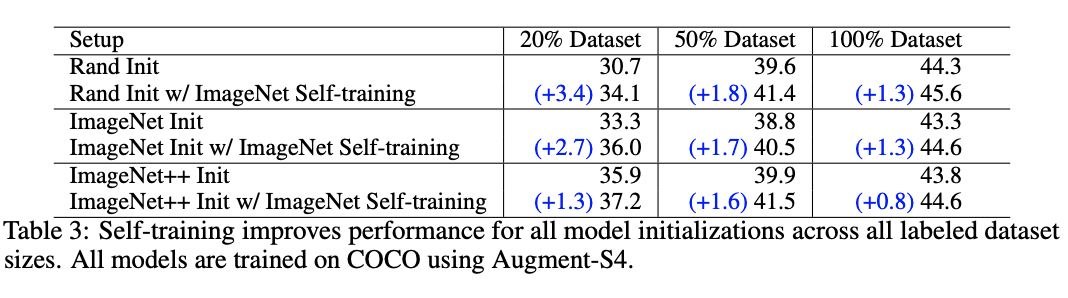
接下来,我们分析自我训练在改变 COCO 标记的数据集大小时的性能。从表 3 中可以看出,不管预训练方法如何,自训练对数据集大小(从小到大)的对象检测器都有好处。最重要的是,在 100%标记集大小的高数据状态下,自我训练显著改善了所有模型,而预训练却很受损。
在 20%的低数据范围内,自训练在 Rand Init 的基础上获得了最大的+3.4AP 增益。这个增益大于 ImageNet Init(+2.6AP)获得的增益。虽然自训练增益小于 ImageNet++Init 的增益,但 ImageNet++Init 使用了额外的 300M 未标记图像。
即使在使用相同的数据源时,自我训练与预训练相比也是相当重要的。例如,在数据量为 20%的情况下,使用 ImageNet 预训练过的检查点可以提高+2.6AP。使用 ImageNet 进行预训练和自我训练可获得额外的+2.7AP 增益。在所有的数据集大小中,可以观察到结合预训练和自训练的额外的收益。
4.3 当自我训练在高数据/强增强系统中有帮助时,自我监督的预训练也会造成伤害
先前的实验表明,ImageNet 预训练会损害准确性,尤其是在高数据、增强能力最强的情况下。在这种情况下,我们研究了另一种流行的预训练方法:自我监督学习。
自我监督学习的主要目标是建立可转移到更广泛的任务和数据集的通用表示。由于有监督的 ImageNet 预训练会损害 COCO 的性能,所以不使用标签信息的潜在的自我监督学习技术可能会有所帮助。在本节中,我们重点讨论高数据(100%COCO 数据集)和最强增强(Augment-S4)设置中的 COCO。我们的目标是将随机初始化与使用最先进的自监督算法预先训练的模型进行比较。为此,我们选择一个在 ImageNet 上使用 SimCLR 框架预训练的检查点。我们在对 ImageNet 标签进行微调之前使用检查点。所有主干模型都使用 ResNet-50,在工作中,SimCLR 只使用 ResNet。
表 4 中的结果表明,自我监督的预训练检查点对性能的影响与在 COCO 数据集上的监督预训练一样大。两个预训练的模型比使用随机初始化的模型性能降低了-0.7AP。我们再次看到自我训练提高了 0.8AP 性能,当两个预训练的模型都损害了性能。尽管自我监督学习和自我训练都忽略了这些标签,但是自我训练似乎在使用未标记的 ImageNet 数据来帮助 COCO 时更为有效。

4.4 探索自我训练和预训练的局限性
在本节中,我们将结合我们关于数据扩充、自我训练和预训练的相互作用的知识,以改进最先进的技术。以下是我们的主要成果:
COCO 目标检测
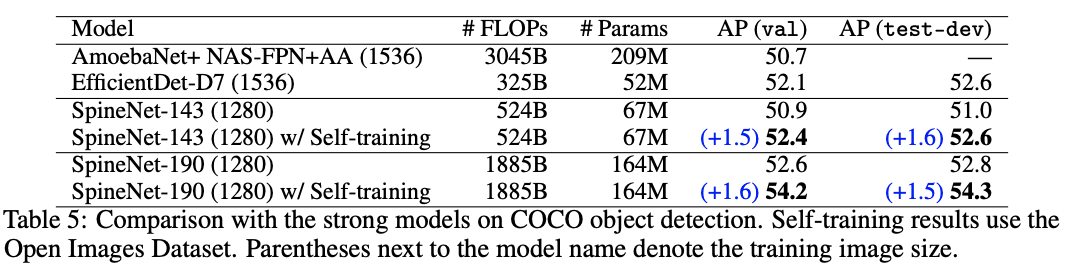
在本实验中,我们使用自训练和 Augment-S3 作为增强方法。之前对完整 COCO 的实验表明 ImageNet 预训练会损害性能,所以我们不使用它。虽然对照实验使用了 EfficientNet 和 ResNet 主干,但是我们在这个实验中使用了 SpineNet,因为它更接近最先进的技术。对于自我训练,我们使用开放图像数据集(OID)作为自我训练的未标记数据,我们发现它比 ImageNet 更好(有关数据源对自我训练的影响的更多信息,请参阅附录 E)。请注意,通过[41]中的预训练发现 OID 对 COCO 没有帮助。
表 5 显示了我们在两个最大的 SpineNet 模型上的结果,并将它们与之前在此数据集上的最佳单一模型、single-crop 性能进行了比较。对于最大的 SpineNet 模型,我们将最好的 52.8AP SpineNet 模型改进+1.5AP,以达到 54.3AP。在所有模型变体中,我们至少获得+1.5AP 增益。
PASCAL-VOC 语义分割
在这个实验中,我们使用 NAS-FPN 架构,EfficientNet-B7 和 EfficientNet-L2 作为主干架构。由于 PASCAL 的数据集很小,所以在这里,预训练仍然很重要。因此,本实验采用预训练、自我训练和强数据扩充相结合的方法。对于预训练,我们使用 ImageNet++来训练 EfficientNet 主干。对于增强,我们使用 Augment-S4。我们使用 PASCAL 的 aug 集作为自训练的附加数据源,我们发现它比 ImageNet 更有效。
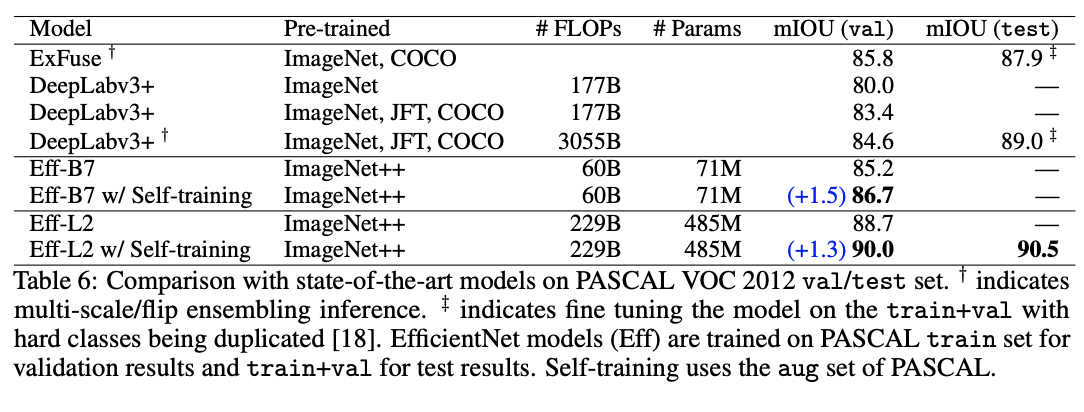
表 6 显示,我们的方法在很大程度上改进了现有的技术。我们在 PASCAL VOC 2012 测试集上使用单尺度推理实现了 90.5%的 mIOU,超过了旧的最先进水平 89%mIOU 利用多尺度推理。对于 PASCAL,我们发现有一个良好的检查点的预训练是至关重要的,没有它,我们可以达到 41.5%的 mIOU。有趣的是,我们的模型比以前的技术进步了 1.5% mIOU 甚至在训练中使用更少的人类标签。我们的方法使用 ImageNet(1.2M images)和 PASCAL 序列分割(1.5k images)中的标记数据。相比之下,以前最先进的模型使用了额外的标记数据:JFT(300M images)、COCO(120k images)和 PASCAL-aug(9k images)。关于伪标记图像的可视化。
讨论
重新思考预训练和通用特征表征
计算机视觉最宏伟的目标之一是开发能够解决许多任务的通用特征表示。我们的实验显示了在分类任务和自监督任务中学习普遍表征的局限性,这表现在自训练和预训练的表现差异上。我们对预训练表现不佳的直觉是,预训练没有意识到感兴趣的任务,可能无法适应。在切换任务时通常需要这样的适应,因为,例如 ImageNet 的良好特征可能会丢弃 COCO 所需的位置信息。我们认为,与监督学习相结合的自我训练目标更能适应感兴趣的任务。我们怀疑这会导致自我训练更普遍地有益。
联合训练的好处
自我训练范式的一个优点是它联合训练监督目标和自我训练目标,从而解决两者之间的不匹配问题。但也许我们可以联合训练 ImageNet 和 COCO 来解决这个不匹配的问题?表 7 显示了联合训练的结果,其中 ImageNet 分类与 COCO 目标检测联合训练(我们在本实验中使用精确的设置作为自训练)。我们的结果表明,ImageNet 预训练可以提高+2.6AP,但是使用随机初始化和联合训练可以获得更大的+2.9AP 增益。这种改进是通过在 ImageNet 数据集上训练 19 个 epoch 来实现的。大多数用于微调的 ImageNet 模型需要更长时间的训练。例如,ImageNet Init(监督预训练模型)需要在 ImageNet 数据集中训练 350 个 epochs。
此外,使用相同的 ImageNet 数据源(表的最后一列),预训练、联合训练和自我训练都是相加的。ImageNet 预训练获得+2.6AP 改善,预训练+联合训练获得+0.7AP 改善,进行预训练+联合训练+自我训练获得+3.3AP 改善。

任务协调的重要性
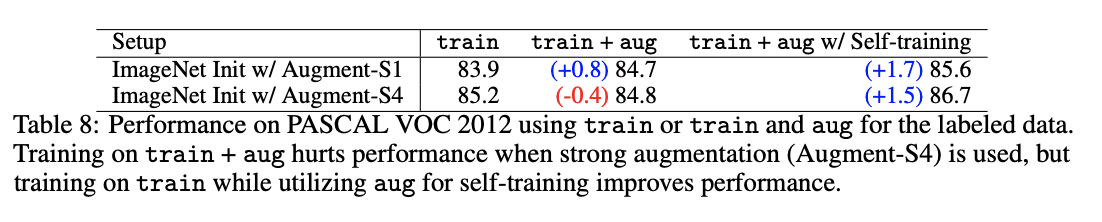
在我们的实验中,一个有趣的结果是 ImageNet 的预训练,即使有附加的人类标签,其表现也比自我训练差。同样,我们在 PASCAL 数据集上验证了同样的现象。在 PASCAL 数据集上,aug 集通常用作附加数据集,其标签比训练集噪声大得多。我们的实验表明,在强数据增强(Augment-S4)的情况下,使用 train+aug 进行训练实际上会损害准确性。同时,在同一个 aug 数据集上通过自训练生成的伪标签显著提高了准确性。这两个结果都表明噪声(PASCAL)或非靶向(ImageNet)标记比靶向伪标记更差。
值得一提的是,Shao 等人。[41]报告开放图像的预训练损害了 COCO 的性能,尽管它们都用边界框进行了注释。这意味着我们不仅希望任务是相同的,而且注释也是相同的,这对于预训练是非常有益的。另一方面,自我训练是非常普遍的,可以成功地使用开放图像来提高 COCO 的表现,这一结果表明自我训练可以很好地与感兴趣的任务保持一致。
局限性
目前的自我训练技术仍然存在局限性。特别是,自我训练需要更多的计算,而不是对预训练的模型进行微调。由于预训练,加速从 1.3 倍到 8 倍不等,这取决于预训练的模型质量、数据扩充的强度和数据集的大小。对于低数据应用,如 PASCAL 分割,也需要良好的预训练模型。
自我训练的可扩展性、通用性和灵活性
我们的实验结果突出了自我训练的重要优势。首先,就灵活性而言,自我训练在我们尝试过的每种设置中都很有效:低数据区、高数据区、弱数据区和强数据区。对于不同的体系结构(ResNet、EfficientNet、SpineNet、FPN、NAS-FPN)、数据源(ImageNet、OID、PASCAL、COCO)和任务(对象检测、分割)来说,自我训练也是有效的。第二,就一般性而言,自我训练即使在训练失败时也能很好地发挥作用,但当训练成功时也是如此。在可伸缩性方面,自我训练被证明表现良好,因为我们有更多的标记数据和更好的模型。机器学习的一个惨痛教训是,当我们有更多的标记数据、更多的计算或更好的监督训练配方时,大多数方法都会失败,但这似乎并不适用于自我训练。
论文原文链接:
https://arxiv.org/pdf/2006.06882.pdf

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论