

为了降低成本和提高效率,越来越多的企业把基础设施迁移到云端,不管是以公有云还是私有云的形式。
云计算可以提供一定的灵活性,然而随之也带来了一些资源上的浪费。这是因为用户倾向于高估(overestimate)对资源的需求,并且在申请资源之后会低效的使用资源(underutilize)。各种分析表明业界的云计算 CPU 使用率只有 6%到 12%[1]。
eBay 有着巨大规模的云计算基础设施,任何一点微小的改善都将显著地为数据中心节省成本。从 2018 年起,我们专注提高 eBay 私有云的使用效率。截止 2018 年底,eBay 云计算 CPU 的超售比例达到 295%,内存达到 118%,最终为标准型物理服务器贡献出额外的超过 300TB 的内存容量。这相当于 1000 多台最新型的标准服务器。
本文将分享我们如何通过如下步骤为 eBay 数据中心节省资源,旨在为同行带来思考和借鉴:
一、监控和分析物理服务器的性能指标
二、改进 openstack 的资源调度器
三、建立动态再平衡系统
四、灰度策略发布
一、监控和分析物理服务器的性能指标
eBay 私有云现在正在使用的 openstack 的计算模块 Nova,本身并没有记录实际的计算资源使用情况。
所以我们的第一步是改进分布在宿主机上的 Nova-Compute,从而保证可以收集并汇报实际的计算资源使用情况,特别是 CPU 和内存。
Nova 收集并汇报的计算资源使用情况,只能服务于 Nova 相关的子模块,比如资源调度器。但是我们还需要有计算资源使用情况的全局视角,所以我们采用了基于 Elastic 的 metricbeat 解决方案,保证我们能够收集到大量物理服务器的性能数据,同时也可以按需去做各种各样的聚合方便我们去发现计算资源的使用特性。
二、改进 openstack 的资源调度器
安全的内存超售
集群资源管理系统的资源调度器一般是基于装箱的。
比如,如果一个物理服务器有 300G 的内存,而一个虚拟机实例需要 10G 的内存,资源调度器将最多只会调度 30 个实例到这台物理机上。当然,为了简化说明问题,我们这里忽略了给物理机预留的内存,并且实际调度中会有更多维度的资源限制。
当我们有了足够多的性能指标和装箱数据后,我们发现物理服务器有着大量的可用内存资源,即使从装箱角度来看他们已经接近饱和,因此我们针对内存引入了实际使用率(AllocationRatio)的概念。
实际使用率= 实际使用的内存/装箱内存
eBay 私有云的物理服务器分为三种类型:标准(Standard)、高内存性能(High memory)和大数据类型(Big Data)。
标准机型主要运行着 Web 相关应用。以生产环境中运行的第五代物理服务器为例,实际使用率(AllocationRatio)的分布如下图所示,样本总数约为 4000 台,可以发现大多数服务器的实际使用率(AllocationRatio) 主要分布在 60%到 90%区间。
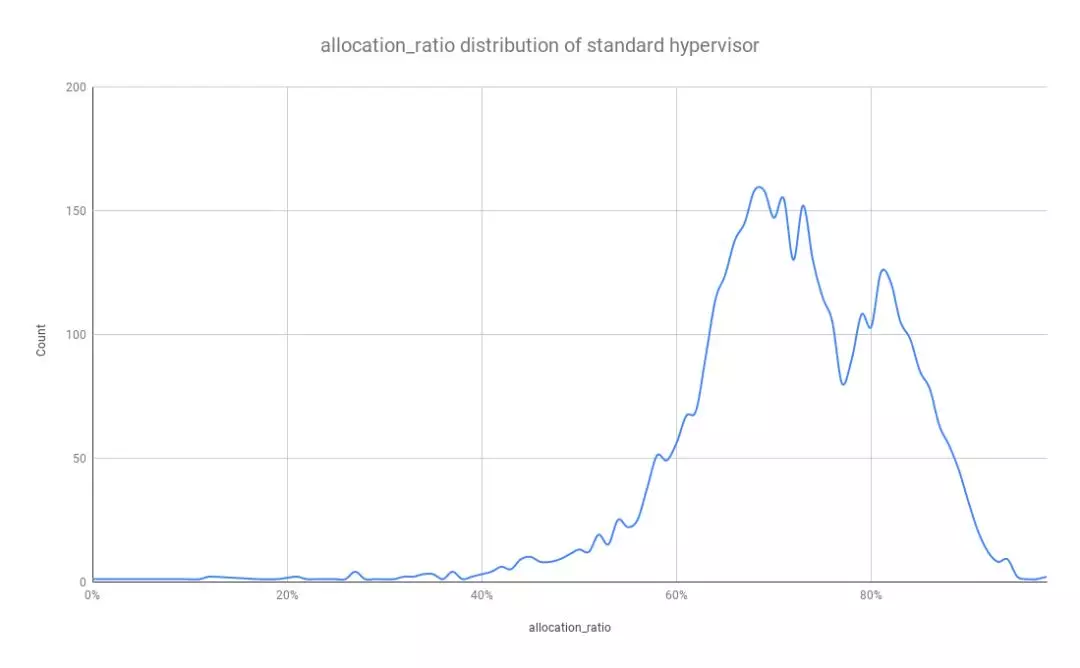
基于如上数据,如果我们希望提高物理服务器的资源使用率,尤其是内存资源,就需要进行安全的内存超售(Safe Memory Oversubscription)。我们发现,安全的内存超售的理论最大值基本上约等于实际使用率(AllocationRatio)的倒数。之所以用“约等于” ,是因为我们需要考虑到物理服务器作为虚拟机宿主机的内存消耗以及安全的内存缓冲(safety memory buffer)。
比如,如果一个虚拟机在创建的时候申请了 10G 内存,但是在整个生命周期中只使用了 7G 内存,我们就可以说这台虚拟机的实际内存使用率为 7/10=0.7。同时,我们也可以计算物理服务器的实际使用率(AllocationRation)。
为简单起见,我们假设所有的虚拟机都符合前面提到的情况,并且物理服务器本身的内存使用为 10G,那么物理服务器的内存使用率为(7*30+10)/300= 73.3%,此时安全超售的理论最大支持为 1/0.73=1.36,也就是说我们还可以在这台物理服务器上再编排接近 10 个同样大小的虚拟机。考虑到真实生产环境中的风险以及内存缓冲(safety memory buffer), 我们不能做到如此激进。
云原生亲和性
我们将 eBay 私有云上运行的虚拟机实例按照是否可以自由迁移以及迁移的时间成本分为三类:
云原生(CloudNative) :可迁移,迁移成本小于 1 小时
准云原生(Quasi-CloudNative) :可迁移,迁移成本大于一小时
非云原生(NonCloudNative):不可迁移
集群资源管理系统的调度器在编排资源时的策略一般可以分为两种:平铺(Spread) 和堆叠(Stack)。**平铺(Spread)可以满足上层应用程序对于容错域(Fault Domain)的需求从而可以保证应用程序的可用性。容错域代表出错的一个物理单元,在 eBay 内部特指共享物理交换机、电源等设备的一组物理服务器,通常是半个或者整个机架。堆叠(Stack)**可以提高服务器的利用率,因为对于新的资源编排请求,堆叠总是优先把资源聚集到高负载的服务器,而不是那些空闲服务器。
OpenStack 默认采用的是平铺(Spread)策略,本质上不利于提高物理服务器的利用率。我们采取的方法是在不影响上层应用程序对于容错域需求的情况下,将物理服务器划分为云原生和非云原生两类。由于一些特定的原因,我们只能找到很少全是云原生虚拟机的物理服务器,所以我们将云原生物理服务器的标准放宽为其上运行的云原生虚拟机实例个数大于 N, N 值是动态调整的。在完成物理服务器的分类和标定之后,我们进一步改进了 Nova-Scheduler 的编排策略,实现了:
尽量把云原生(CloudNative)属性的虚拟机编排到云原生物理服务器上,从而实现云原生虚拟机的聚集效应,提高云原生物理服务器的计算资源利用率;
禁止准云原生(Quasi-CloudNative)和非云原生(NonCloudNative)属性的虚拟机请求编排到云原生物理服务器上,从而保证下文提到的动态再平衡系统可以在系统有过载倾向时可以介入并能正常工作。
三、动态再平衡系统
随着我们通过上述的超售方式把越来越多的虚拟机实例放到物理机上,不可避免地会出现资源过载情况,可能出现在处理器或者内存,也可能两者兼而有之。
我们需要一个再平衡系统去监测和发现高负荷运载的物理机,在系统资源饱和影响上层应用程序性能和业务之前迁走上面的工作负载,从而让有过热倾向的物理机回到正常状态。
再平衡系统定义了两种形式的任务:被动式(Reactive)和主动式(Proactive)
被动再平衡(Reactive)
针对这种任务,再平衡系统定义了三种形式的报警策略:
i CPU 过载 — 阈值设定为范化的 15 分钟 CPU 负载(normalized cpu load15) >= 0.7, 0.7 是基于 eBay 线上大规模应用性能的统计经验值;
ii 内存过载— 和 CPU 提供给实例的是使用时间不同, 内存提供的是使用空间,所以内存是计算资源中最不具有弹性的资源,这意味着内存的使用大小基本上是不可压缩的, 因为它是有状态的,申请资源慢,并且基本上不可能被回收。 基于安全原因的考虑, 我们需要保留一定的安全内存缓冲(safety memory buffer), 从而保证任何时候虚拟机实例向物理机申请内存都能够成功,所以我们用到的最小可用内存阈值是物理机总内存的 10%;
iii Swap— swap 的触发意味着可能存在内存的慢速访问,极有可能会影响上层应用程序的性能进而影响业务。
再平衡系统会周期性地查询物理服务器性能指标,以检查是否有过载倾向。如果服务器有过载的倾向,系统会产生一个报警消息并发送到消息队列里;
多个工作进程会监听消息队列,拿到消息队列后会从其他的配置系统里获取其他数据,包括服务器具体的性能指标,从 KVM 角度观察到的虚拟机性能指标,虚拟机、资源池以及应用服务的配置信息;
基于上述收集到的数据,再平衡系统会做出综合决策,挑选出一个或者多个虚拟机并且通过调用 PaaS 层的 API 来完成虚拟机的迁移,从而减轻物理服务器的工作负载保证其在安全范围之内。
由于内存是最不具弹性的计算资源,并且我们持续的优化内存去提高利用率,在这种情况下,物理服务器的可用内存就成为了一个关键指标,所以我们定义了两级内存报警:警告(warning)和危险(Critical)。一旦可用内存低于警告(warning) 阈值, 再平衡系统会挑选出一个或者多个虚拟机并调用 PaaS API 来迁移。但是这个迁移过程需要一定的时间,如果在此期间可用内存持续快速减少并达到危险(Critical)阈值,再平衡系统会基于一定的安全策略从中挑选一个云原生(CloudNative)属性的虚拟机强制关机,从而保证该物理服务器上的其他虚拟机性能不受影响。
主动再平衡(Proactive)
基于实际观测到的数据,当物理服务器规模足够大时,它们实际的计算资源使用率基本上服从正态分布,尤其是 CPU 使用率,如下图所示:
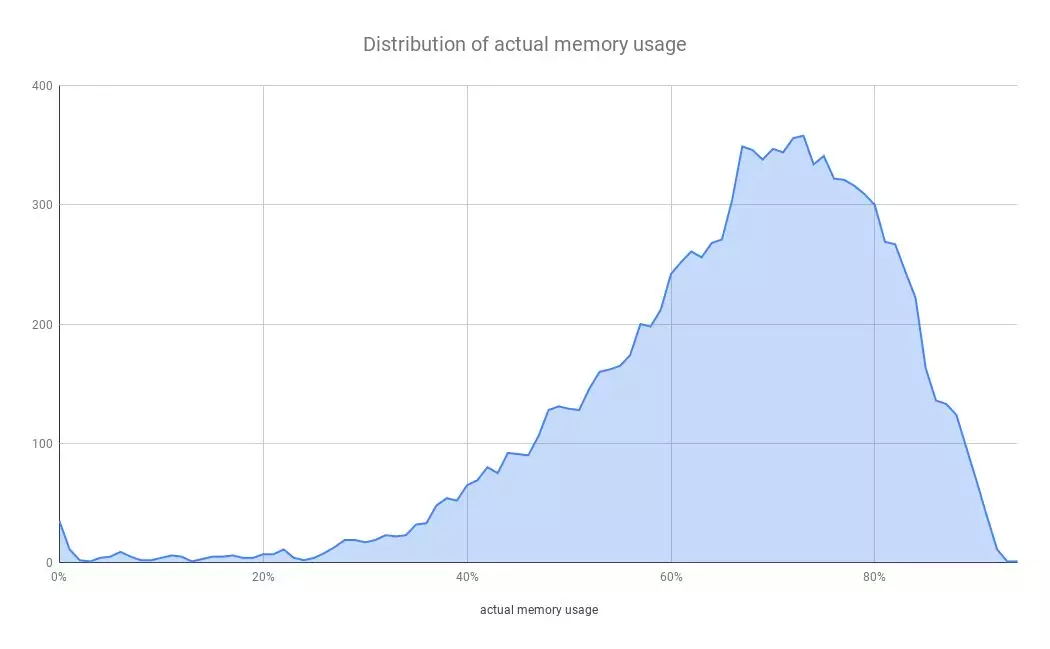
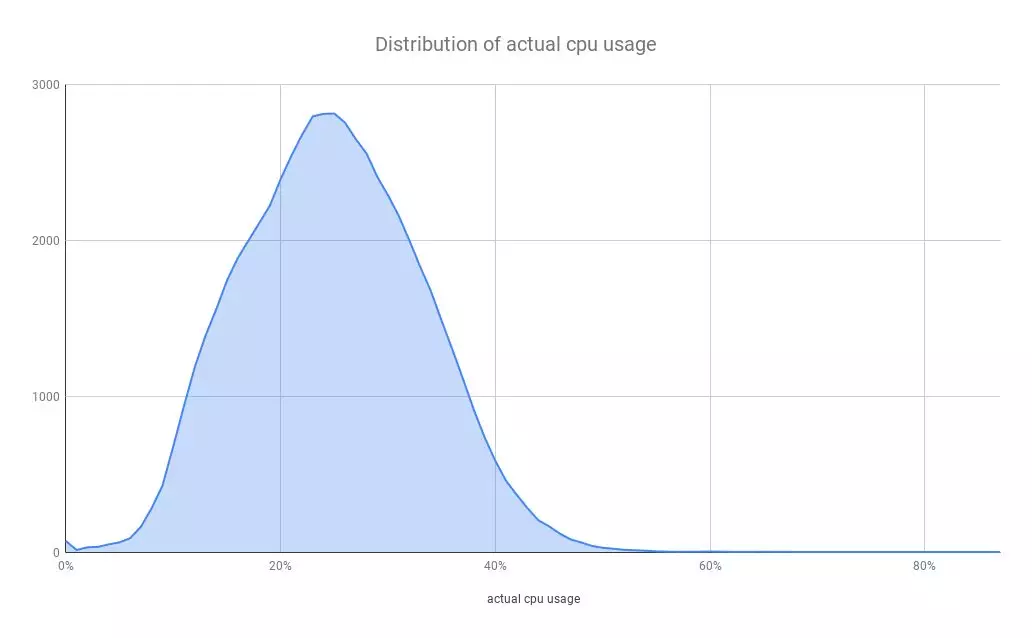
除了上文中提到的被动再平衡任务,再平衡系统也会周期性地扫描所有的云原生物理服务器实际的 CPU 和内存使用率,并从中挑选出前 2.5%的物理服务器迁移上面的云原生虚拟机,从而做到平衡云原生物理服务器的负载。其中,2.5%约等于正态分布右侧二级标准差[2]之外的数值。
四、灰度策略发布
有云原生属性的虚拟机实例主要分布在标准(Standard)物理服务器上,我们标定了其中约 5000 台服务器来实施安全内存优化。通过应用上文提到的改进的资源调度器将更多的虚拟机实例编排到这些物理服务器上并且不断的将云原生虚拟机编排到云原生物理服务器上,同时用再平衡系统来保证应用程序的性能不会因为计算资源的超售受到影响。
在调整 CPU 和内存超售比例的过程中,我们采用灰度发布和对数增长策略来保证每一步调整足够的安全可靠,这意味着超售比例的每一次跃迁不会影响应用程序的性能,同时也不会引起再平衡系统的迁移风暴。
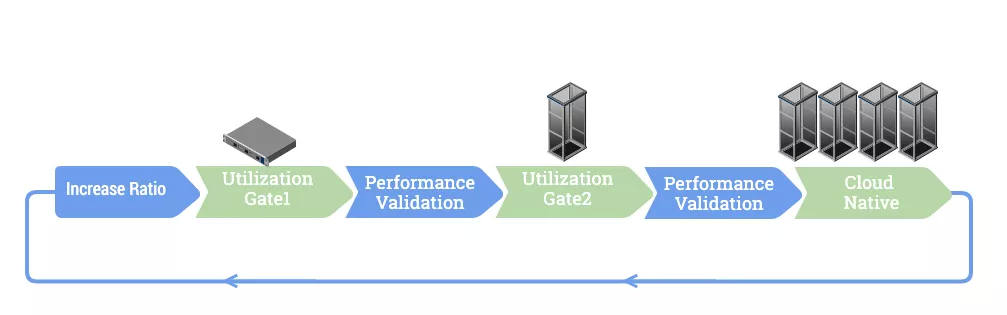
灰度发布策略:
标定三台云原生物理服务器为一级目标机,调整其计算资源超售比例;
当一级目标机上的装箱接近饱和并稳定运行一段时间后,对物理服务器以及其上运行的虚拟机和相关的应用程序做性能验证;
如果上一步提到的性能验证通过,会标定一个机架的物理服务器为二级目标机,调整其超售比例和一级目标机一致;
当二级目标机上的装箱接近饱和并稳定运行一段时间后,对物理服务器以及其上运行的虚拟机和相关的应用程序做性能验证;
如果二级目标机上的性能验证通过,会把同样的超售比例应用收到所有的 5000 台云原生物理服务器上;
进入下一轮超售比例调整。
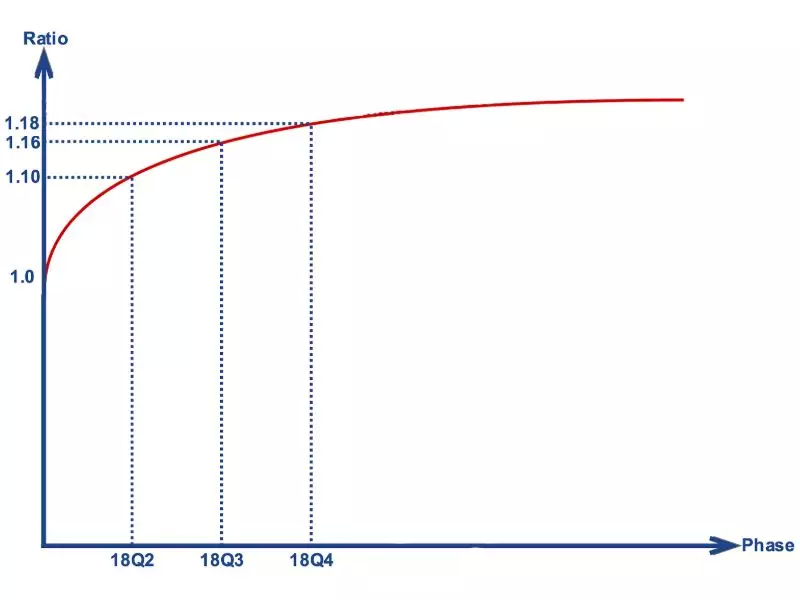
总结
通过一系列的优化和调整,在不影响上层应用程序性能这一绝对安全的前提下,我们持续的提高 CPU 和内存的超售比例。
截止 2018 年底,CPU 的超售比例达到了 295%,内存达到了 118%,最终为标准型物理服务器贡献出额外的超过 300TB 的内存容量。这相当于 1000 多台最新型的标准服务器。
基于此, 我们下调了 eBay 私有云的 2019 年的容量预算。
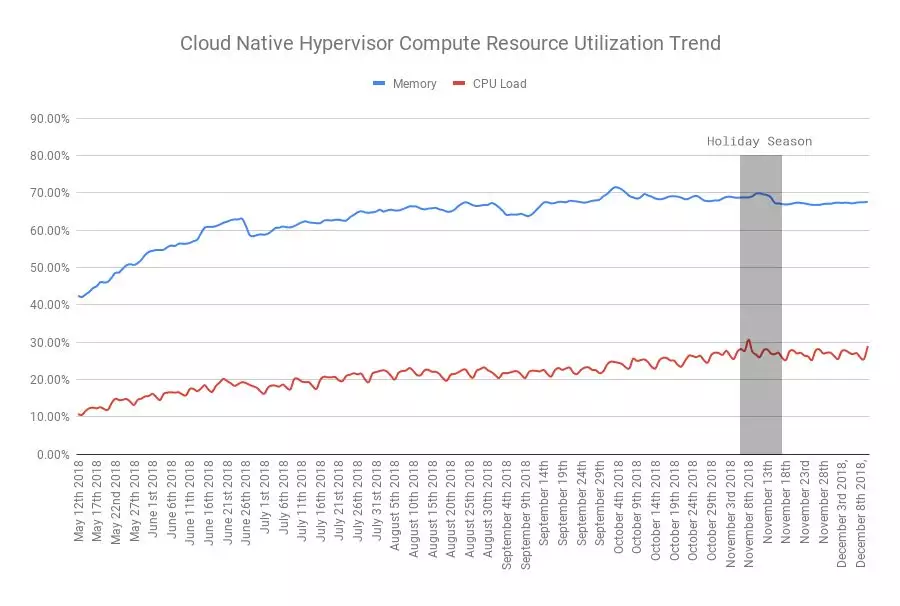
与此同时,我们也大幅提高了计算资源的实际使用率,尤其是 CPU 和内存,如图所示,从 2018 年 5 月到 2018 年 12 月,实际的内存使用率从 48%提高到了 68%,增幅约为 42%;实际的 CPU 使用率从 12%提到了 29%,增幅约为 142%,其中的峰值数据来自于十一月初的黑五大促前后。
本文转载自公众号 eBay 技术荟(ID:eBayTechRecruiting)。
原文链接:
https://mp.weixin.qq.com/s/7ThOAFS8j8mzvdJUSjJNSg

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论