

本文最初发布于 RISELab 博客,经原作者 Jason Dai、Zhichao Li 授权由 InfoQ 中文站翻译并分享。
近年来,人工智能有了很大的发展。为了获得洞察力并基于海量数据作出决策,我们需要拥抱先进的、新兴的人工智能技术,如深度学习、强化学习、自动机器学习(AutoML)等。
Ray 是由加州大学伯克利分校 RISELab 开源的新兴人工智能应用的分布式框架。它实现了一个统一的接口、分布式调度器、分布式容错存储,以满足高级人工智能技术对系统最新的、苛刻的要求。Ray 允许用户轻松高效地运行许多新兴的人工智能应用,例如,使用 RLlib 的深度强化学习、使用 Ray Tune 的可扩展超参数搜索、使用 AutoPandas 的自动程序合成等等。
在本文中,我们将介绍 RayOnSpark,这是新近添加到 Analytic Zoo 的功能之一。Analytic Zoo 是开源的端到端数据分析 + 人工智能平台。RayOnSpark 允许用户直接在 Apache Hadoop/YANE 上运行 Ray 程序,这样用户就可以在现有的大数据集群上以分布式的方式轻松尝试各种新兴的人工智能应用。此外,大数据应用和人工智能应用并没有运行在两个独立的系统上,因为这往往会带来昂贵的数据传输成本和较高的端到端学习延迟。RayOnSpark 允许 Ray 应用无缝集成到 Apache Spark 数据处理管道中,并直接在内存中的 Spark RDD 或 DataFrame 上运行。
接下来,我们将重点阐述如何在 Hadoop/YARN 之上使用 PySpark 运行 Ray 集群和程序(见下面的图 1)。注意,虽然本文只展示了如何在 YARN 集群上运行 Ray,但同样的逻辑也可以应用于 Kubernetes 和 Apache Mesos。

为了说明预期的 RayOnSpark 工作流,我们将使用一个简单的 Ray 示例,它使用 Actor 收集服务器的 IP 并在 YARN 集群上运行该实例。
请按照下面的链接来安装 Anaconda:
https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html
创建名为“zoo”(或任何其他名称)的虚拟环境,如下所示:
将 Spark、Analytics Zoo、Jupyter 和 Ray 安装到 Conda 环境中。
安装 Java 环境。
Spark 需要 Java 环境设置。如果环境变量 JAVA_HOME 已经用 JDK8 设置好,则可以跳过这一步。
搜索并记住 Hadoop 配置文件夹的路径,这是稍后在 YARN 上初始化 Spark 所需的。文件夹的层次结构如下所示:
启动 Jupyter Notebook。
在 Jupyter Notebook 中,只需调用 Analytics Zoo 提供的“init_spark_on_yarn” Python 方法,就可以在 YARN 上启动 SparkContext:
注:在 YARN 上使用 PySpark 时,用户面临的一个挑战是,在集群中的每个节点上准备 Python 环境,而不修改集群。你可能会考虑使用 rsync 手动将依赖项从驱动程序转移到集群,但这需要时间,且容易出错。此外,你可能在生产环境中没有 ssh 权限。在这里,我们通过利用 conda-pack 和 YARN 分布式缓存来解决这个问题,以便帮助用户在集群中自动捆绑和分发 Python 依赖项。
在 YARN 上使用 PySpark 启动 Ray 集群。
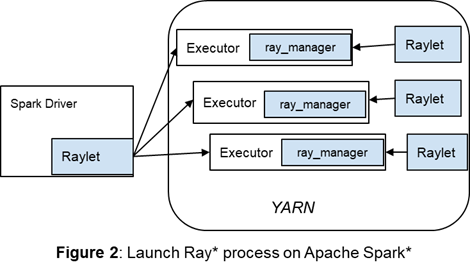
在 RayOnSpark 中,我们首先创建一个 SparkContext,它将负责通过 “ray start” 在底层集群(即 YARN 容器)中启动 Ray 进程。对于每个 Spark 执行器,都会创建一个 “Ray Manager” (见下面的图 2)来管理 Ray 进程;当故障发生或者程序退出时,它将自动关闭或重新启动进程。
“RayContext”是触发 Ray 集群部署的入口点。下面是调用“ray_ctx.init()”幕后的逻辑:
将在本地节点上启动一个 Ray“驱动程序”。
带有 Redis 进程的单个 Ray“master”将在一个 Spark 执行器上启动。
对于每个剩余的 Spark 执行器,将启动一个“Slave”Reylet。
Ray master 和 Raylet 进程将配置为使用由“executor_cores”参数指定的内核数。
之后,我们将编写一些简单的代码来测试 Ray 集群是否已经成功启动。例如,以下代码将创建 Actors 来从分配的 YARN 容器中收集 IP。
在阅读上面的简单示例代码之后,你可以参考更复杂的 RayOnSpark 的 Jupyter Notebook,这是基于实现 Sharded 参数服务器的官方 Ray 执行。
借助 Analytics Zoo 中的 RayOnSpark 支持,用户只需在 Ray 程序的顶部添加三行额外的 Python 代码(如下所示):
这样就可以在现有的 Hadoop/YARN 集群中直接运行构建在 Ray 之上的人工智能新的应用,这些应用可以无缝集成到 Spark 数据处理管道中。作为第一个用力,我们目前正在使用 RayOnSpark 来实现自动机器学习对时间序列预测的支持(包括自动特征生成、模型选择和超参数调优)。
作者介绍:
Jason Dai,英特尔高级首席工程师、大数据分析和人工智能创新院院长。
原文链接:
RayOnSpark: Running Emerging AI Applications on Big Data Clusters with Ray and Analytics Zoo

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论