

很多 AWS 客户采用多账户策略。集中式的 AWS Glue 数据目录对于在最大程度上减少与不同账户之间元数据共享相关的管理工作来说非常重要。本文介绍了基于 Amazon Athena 在不同 AWS 账户之间查询集中式数据目录的功能。
解决方案概述
在 2019 年年底,AWS 推出了将 Amazon Athena 连接到您的 Apache Hive Metastore 的功能。借助于此功能,您也可以配置 Athena 指向不同账户内的数据目录。Hive Metastore 功能采用 AWS Lambda 函数对您的数据目录进行联合查询。您可以使用此功能实现对不同账户数据目录进行查询的 Proxy。
下图显示了使用 Athena 访问跨账户 Glue 数据目录的必要组件以及数据流动:
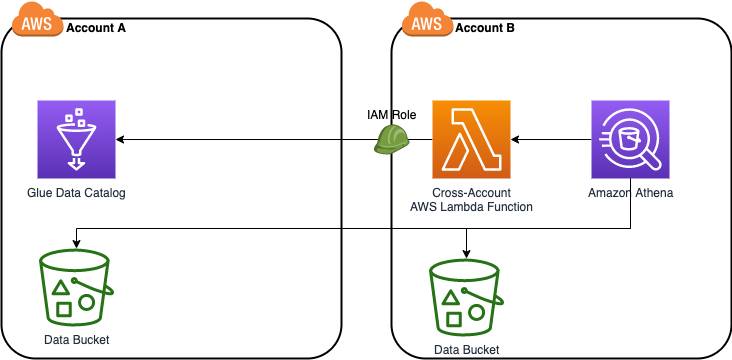
在此演练中,您将在运行 Athena 查询的相同账户(账户 B)中创建 Lambda 函数。您将在使用资源策略为 Lambda 函数赋予跨账户访问权限,允许账户 B 中的函数查询账户 A 中的数据目录。账户 B 中的用户必须拥有相关表指向的 Amazon S3 资源的访问权限,并具有执行 Lambda 函数的权限。如需关于实现该 Lambda 函数的更多信息,见 Github repo。
本文还会提供 AWS CloudFormation 堆栈,以创建 Lambda 函数和用于该函数的只读 IAM 角色。本文使用来自 AWS 的开放数据网站注册的数据。您无需担心如何确保对 S3 上的数据进行跨账户访问。
先决条件
在此演练中,您需要符合以下先决条件:
一个具有创建 IAM 角色、Lambda 资源和运行 Athena 查询功能的 AWS 账户(图表中的账户 B)。
另一个您可以在其中创建数据目录的 AWS 账户(账户 A)
对账户 A 中的 AWS Glue 进行访问的 AWS CLI 管理员权限
作为本文的一部分,您将在账户 B 中为账户 B 中的 Lambda 函数创建一个只读 IAM 角色(由 CloudFormation 堆栈启动),以访问账户 A 中的数据目录。
此角色有两项附加的策略。第一项策略为 Lambda 函数提供跨账户数据目录中的特定资源的只读访问权限。见以下代码:
第二项策略为 Lambda 函数提供写入 CloudWatch Logs 的权限。见以下代码:
您还将创建以下更多资源:
账户 B 中作为数据目录请求 Proxy 的 Lambda 函数(由 CloudFormation 堆栈启动)
通过为账户 A 中的数据目录添加策略,赋予 Lambda 函数跨账户执行访问权限
账户 A 中的示例表
本文中的 CloudFormation 堆栈在账户 B 中创建 Lambda 函数,并通过附加上述两项策略赋予必要的访问权限。单击此按钮,从 CloudFormation 控制台将 CloudFormation 模板部署到 us-east-1 区域。

请按照如下所述,为参数输入值以启动堆栈:
GlueDataCatalogAccountID:作为您的集中式数据目录账户(账户 A)的账户 ID
区域:
us-east-1DatabaseName:您要在跨账户 Glue 目录中为 Lambda 函数提供此数据库的访问权限。出于本文的目的,输入
opendataTableName:您要在跨账户 Glue 目录中为 Lambda 函数提供位于上述特定数据库中的此表的访问权限。出于本文的目的,输入 * 。这样做将提供位于上述特定数据库中的所有表的访问权限
现在,点击“下一步”按钮,直到您看到创建堆栈的按钮。在堆栈结束预置以后,您就可以开始演练。
注意:若要允许 Lambda 函数访问更多数据库和表,您可以编辑附加到由 CloudFormation 堆栈创建的 IAM 角色的内联 IAM 策略 AWSGlueReadOnlyAccess,以便添加更多资源。
赋予跨账户访问权限
在您要在运行 Athena 查询以访问跨账户数据目录的账户(账户 B)上创建好 Lambda 函数之后,您需要将该 Lambda 函数注册为 Athena 内的数据源。
注册集中式数据目录
首先,创建工作组以访问预览功能。然后按照 将 Athena 连接到 Apache Hive Metastore 中的步骤进行操作。在连接详细信息页面上,为 Lambda 函数选择创建 CloudFormation 堆栈所在的 Lambda 函数。 它看起来应该类似于 -AthenaCrossAccountLambdaFunc-。将您的数据目录命名为 centraldata。
赋予跨账户执行访问权限
附加策略,而该策略赋予访问账户 B 中 IAM 角色的权限,以便读取账户 A 的数据目录中的数据库和表。在账户 A 中运行以下命令,但进行以下更改:
将 Principal 值替换为(来自账户 B 的)CloudFormation 堆栈 输出选项卡中的
CrossAccountPrincipal的值。将 <ACCOUNT_ID> 替换为账户 A 的 AWS 账户 ID。
在资源部分,将 替换成您想要查询的跨账户目录的数据库名称。本文使用 opendata。
上述代码为数据目录附加一项策略(若尚未为其附加策略)。如果有,而且您希望对其进行覆盖,从代码中移除 --policy-exists-condition NOT_EXIST。它会使用 –policy-in-json 的值替换现有的策略。您还可以在 AWS Glue 控制台中直接编辑策略,以合并您的现有策略与 --policy-in-json 的值。
在账户之间执行查询
在创建您的 Lambda 函数并将其注册到 Athena 以后,您可以跨账户运行查询。
从位于 AWS 的开放数据注册表创建 Amazon 客户评论示例表,您可以使用它在账户 B 中进行查询。完成以下步骤:
登录账户 A 并打开 Athena 控制台。
运行以下三条查询,每次一条:
要为此示例创建数据库,运行以下查询:
CREATE DATABASE opendata要创建示例表,运行以下查询:
要为表添加分区,运行以下查询:MSCK REPAIR TABLE amazon_reviews_parquet
登录到 Athena 账户(账户 B)。
在 Athena 控制台中输入以下查询:
SELECT * FROM centraldata.opendata.amazon_reviews_parquet LIMIT 10;
以下截图显示的是上述查询所得的 100 个随机行:
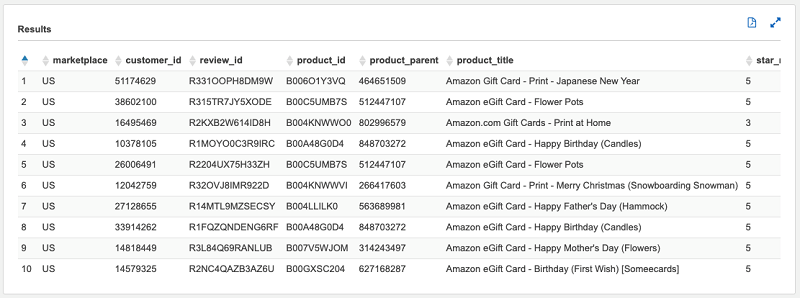
此查询在 Athena 账户(账户 B)中运行,但会访问您的主账户(账户 A)中的集中式数据目录。然后,Athena 会从 S3 检索数据,并在 Athena 账户中处理查询。您甚至可以跨账户合并数据,或者使用其他账户的数据在一个账户中创建派生表。
在账户 B 中使用账户 A 的数据创建派生表
在本文中,假设您想要从 Amazon 评论表创建派生数据集,以确定在某产品类别中留下有用评论的客户是否也在其他类别中写下评论。
在您运行 Athena 查询的账户中,通过 Athena 的 从查询结果创建表功能并使用来自集中式数据目录的数据创建新表。您可以在默认数据库中创建一个表,而这个数据库会查找在“玩具”产品类别中撰写超过 1000 条评论的客户。见以下代码:
在运行查询以后,您应该会看到 Query successful 消息。您现在可以检查结果数据。运行以下查询:
SELECT * FROM default.helpful_reviewers LIMIT 100;
以下截图显示的是 default.helpful_reviewers 的上述查询所得的 10 个随机行:
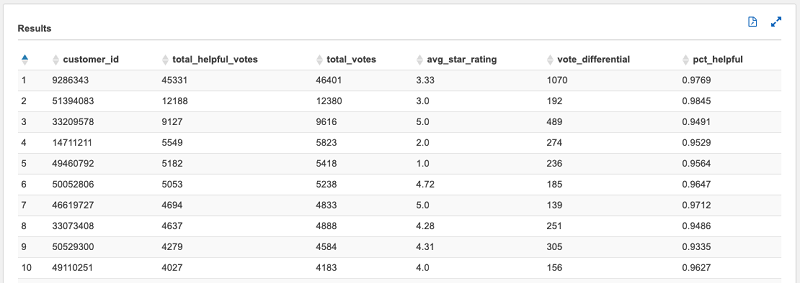
结果显示,有些人会留下大量数据。您现在可以在您的账户中对此派生数据集运行查询,因为您已经对与您的调查相关的数据进行过一些汇总,因此这样做可能更有效率。
跨账户合并表
您还可以查看相同的人员还在其他哪些产品类别中留下评论。以下查询会选择账户 B 中表的数据,然后将其与账户 A 中的原始数据合并:
以下截图显示上述查询的结果,客户在玩具产品类别撰写的超过 1000 条评论以及除“玩具”以外其他产品类别留下的评论数:
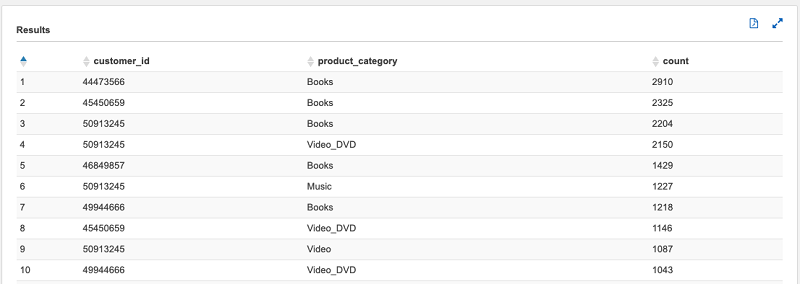
您可以看到在玩具类别中留下评论的客户也会在图书和视频类别中撰写评论。
清理
为了避免在未来产生费用,从您的 Athena 账户取消注册数据目录条目,然后删除 CloudFormation 堆栈。
限制
虽然这是在一个或多个账户之间分享数据目录的有效方式,但它也存在以下限制:
授权—在 CloudFormation 模板中 Lambda 函数的权限以角色赋予,所以任何用户或者角色包含同样的策略可以访问这个角色定义同样的数据目录。
只读—当前实施仅对必要的 Lambda 函数授予只读访问权限,因为我们假定中心团队也会对集中式数据目录进行管理。
结论
本文介绍了如何使用 Athena External Hive Metastore 功能来进行跨 AWS 账户数据目录查询。您也可以在您的账户里创建派生数据集,并在这两个账户之间合并数据。Lambda 函数采用开放源代码;您可以随时查看并为 GitHub repo 做出贡献。
作者介绍:Pathik Shah 是 AWS 的 Amazon EMR 的大数据架构师。
本文转载自 AWS 技术博客。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论