

现有的深度学习框架通常使用模型并行或数据并行来解决深度神经网络(DNN)的并行计算问题,但这两种策略往往会导致模型无法达到最优结果。今年 ACM 的 SysML 大会上,斯坦福大学 Matei 团队在论文《Beyond Data and Model Parallelism for Deep Neural Networks》中提出了一种新的 DNN 并行化策略搜索空间——SOAP。SOAP 从样本(Sample)、运算符(Operator)、属性(Attribute)以及参数(Parameter)四个维度度寻找更好的 DNN 并行化策略。为了加速这个搜索过程,该论文同时提出了一个新的深度学习引擎——FlexFlow。**与目前最先进的方法相比,FlexFlow 能够将训练吞吐量提高 3.3 倍并且可以达到更高的精度。**作者还比较了 FlexFlow 和 TensorFlow 在 Inception-V3 上进行端到端训练时的性能,FlexFlow 比 TensorFlow 减少了 38%的训练时间。我们对该方法做了梳理与总结,本文是 AI 前线第 82 篇论文导读。
1 背景介绍
随着深度学方法的发展,DNN 模型变得越来越大,这导致了 DNN 的计算成本也变得越来越高。因此,对于 DNN 的实际应用,分布式异构 DNN 训练集群成为了标准化的做法。尽管深度学习模型以及硬件集群变得越来越复杂,但是用于并行化训练的框架(例如,TensorFlow、Caffe2 以及 MXNet)却仅用了一些简单的并行化方法,并且其优化结果往往并不是最理想的。
最常用的神经网络并行化可分为数据并行和模型并行。数据并行的基本思想是使用多个设备上的模型副本同时对数据子集进行训练,并在迭代结束时同步跨副本的模型参数。数据并行对于计算密集型且参数量少的运算具有高效性,例如卷积操作。但对于参数量大的运算操作则不能得到最优的结果,例如嵌入操作。而模型并行则是让分布式系统种不同的设备负责网络模型的不同部分,例如将卷积操作分给一部分 GPU 而嵌入操作分给另一部分 GPU 或 CPU 设备。
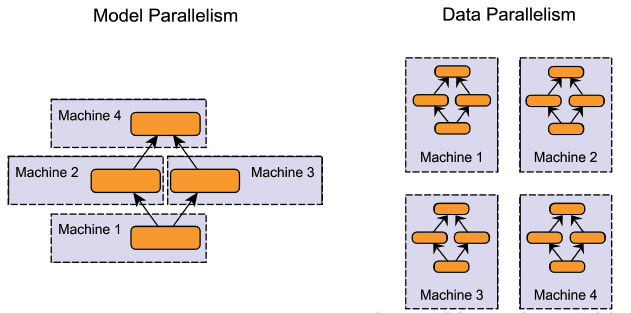
图 1:左半部分为模型并行,不同的机器负责模型中的不同运算模块;右图为数据并行,在不同的设备上创建了完整的模型副本对数据子集进行处理。
去年的 PMLR 上,这篇论文的作者 Zhihao Jia 就提出了一种基于线性计算图的 CNN 逐层并行化方法——OptCNN(相关文献:(https://arxiv.org/pdf/1802.04924.pdf)。OptCNN 使用动态编程的方法联合优化每种运算,但是没有考虑不同运算之间的并行性。此外,OptCNN 不适用于大部分的语言模型,包括针对机器翻译、推荐系统等趋向于 RNN 或其他非线性的深度神经网络。
针对上述问题,SOAP 从扩展搜索空间和模拟运行两方面出发,与现有的 Metropolitan-Hastings 马尔可夫蒙特卡洛方法(MCMC)相结合寻找模型在并行系统下的最优解。其中,作者通过扩展可行解集合的方法将模型的最优化搜索空间扩展为 SOAP 搜索空间,以期在更多可能的潜在并行策略中寻找最优的一种情况。此外,使用 FlexFlow 构建的执行模拟器(execution simulator)可以在 SOAP 搜索空间中更精确的评估并行化策略的性能。
2 方法介绍
2.1 方法总览
FlexFlow 是一种使用运算符图 G 来描述 DNN 中所有运算以及状态的深度学习框架。图 G 中的每个节点 o_i 表示一个运算,例如矩阵乘法、卷积等;而图 G 中的每个边(o_i,o_j )则表示一个张量,这个张量是 o_i 的输出,同时也是 o_j 的输入。此外,FlexFlow 还使用了设备拓扑图 D=(D_N,D_E)来描述所有的可用硬件设备以及他们之间的连接关系。
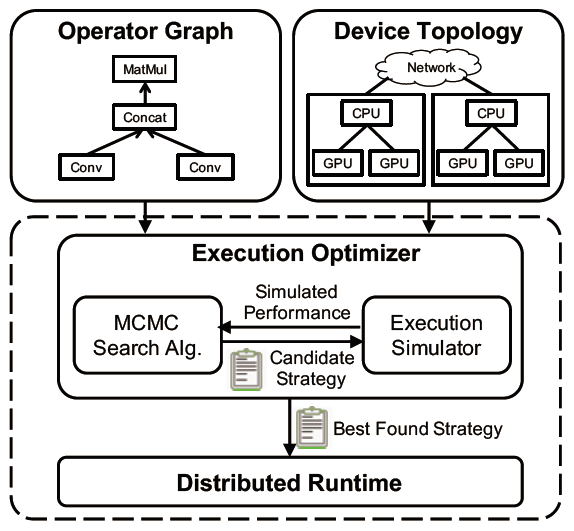
图 2:FlexFlow 总览图,左上角为运算符图,右上角为设备拓扑图,下半部分为执行模拟器与搜索算法迭代求解过程的示意图。
如上图所示,设备拓扑图中 D_E 中的一个节点 d_i 表示一个设备,可能是一个 GPU 或一个 CPU;图 D_E 中的每个边(d_i,d_j)表示两个设备之间的一个硬件连接,例如 NVLink 或 PCI-e。图中的每个边会使用连接的带宽和延迟对它们进行标记。FlexFlow 会将运算符图和设备拓扑图作为输入,在 SOAP 搜索空间中自动搜索有效的策略。搜索空间中的所有策略都会使用 DNN 中定义好的计算方式进行实现,因此可以保持与模型设计时相同的准确率。在图 2 中,优化器使用 MCMC 搜索算法在 SOAP 搜索空间中进行搜索,模拟器则用增量模拟算法(delta simulation algorithm)来产生候选的子策略,这两个步骤迭代进行从而找到最优解。
2.2 SOAP 搜索空间
对于一个运算符 o_i,作者通过研究其输出的分割情况来对它的并行化操作进行建模。作者将 o_i 的可并行化维度(即哪些方面可以进行并行化)定义为 P_i,P_i 是 o_i 的输出的所有可分维度的集合,因此 o_i 一定包含一个样本(Sample)维度。表 1 中列出了一些运算符的可并行化维度。

表 1:几种不同运算符的并行化维度
对于 P_i 中的所有其他维度,如果在该维度上进行分割操作需要拆分模型的参数则将其称为参数维度(Parameters), 其他的维度则称为属性维度(Attribute)。此外,作者还考虑了运算符维度(Operator)中不同运算符的并行性。图 3 展示了一些 1D 卷积运算符在单维度以及混合维度上的并行化配置的例子。
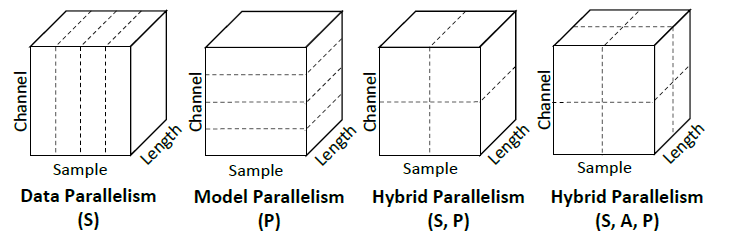
图 3:1D 卷积的并行化配置示例。虚线表示对张量的分割。
对于一个运算符 o_i,它的一个并行化配置(parallelization configuration)c_i 表示在跨设备时该运算符会被如何并行化处理。对于每个 P_i,c_i 包含一个正整数,这个正整数表示在该维度中并行化的等级。|c_i|是 c_i 的所有并行化维度的并行化等级的乘积。作者在每个维度中使用相同大小的分区来保证均衡的工作负载。并行化配置 c_i 将运算符 o_i 分为|c_i|个独立的任务 t_{i:1},…,t_{i:|c_i|},同时 c_i 也包含了分配给每个任务 t_{i:k}的设备。经过上述建模,给定一个任务的输出张量以及它的运算符类型,我们可以推理出执行每个任务所必须的输入张量。图 4 是对于一个矩阵乘法运算符(U=VW)的并行化示例。该运算被划分为四个独立的任务并被分配到不同的 GPU 设备上。该运算的输入输出如图中所示。
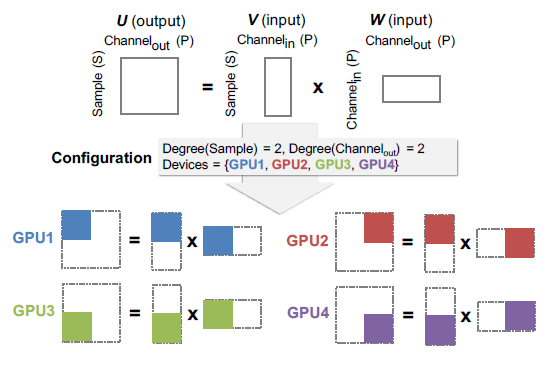
图 4:矩阵乘法并行化示例。
最终,作者使用一个并行化策略 S 表示应用中的一个可能的并行化结果。S 包含了每个运算 o_i 的所有并行化配置 c_i,并且 o_i 的配置可以从所有可能的配置中被独立地选择。
2.3 执行模拟器
执行模拟器将运算符图 G、设备拓扑图 D 以及一个并行化策略 S 作为输入,通过在设备拓扑图 D 上使用策略 S 运行运算符图 G 来预测执行时间。执行模拟器的设计依赖于以下这些假设:
A1:每个任务的执行时间是可预测的,具有低方差的性质,并且与输入张量的内容无关。
A2:对于 d_i 和 d_j 间的具有带宽 b 的每个连接,将一个大小为 s 的张量从 d_i 传递到 d_j 的时间是 s/b,即通信带宽可以被完全利用。
A3:每个设备使用 FIFO(先进先出)调度策略处理分配的任务。这是 GPU 等现代设备使用的策略。
A4:运行时的等待时间可以忽略不计。一旦设备的输入张量可用且设备已完成先前的任务,设备就开始进行处理任务。
为了模拟执行过程,作者借用了 OptCNN 中的想法,为每个配置测量每个不同运算符的执行时间,并将这些测量值包含在任务图(task graph)中,任务图包含了所有从运算符中派生出的任务以及任务之间的依赖关系。通过在任务图上运行模拟算法,模拟器可以生成一个执行时间线。
任务图模拟了从运算符派生的各个任务之间的依赖关系。为了方便抽象化,作者将设备之间的硬件连接模式转化为只能执行通信任务的通信设备。注意,设备和硬件连接被分别建模为单独的设备,如果可能的话,计算(即,常规任务)和通信(即,通信任务)是可以重叠的。对于一个操作符图 G、一个设备拓扑图 D 以及一个并行化策略 S,作者对其构建一个任务图 T=(T_N,T_E)。其中任务图中的每个节点表示一个任务(即常规任务或通信任务),任务图中的每个边(t_i,t_j)表示一种任务依赖关系,即直到任务 t_i 结束之前,任务 t_j 不能开始。
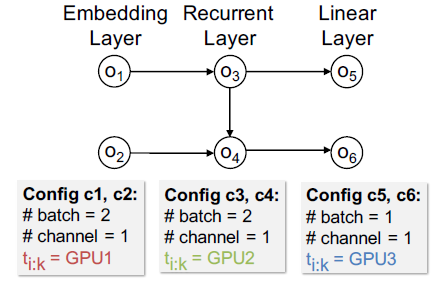
图 5:一个并行化策略示例
图 5 展示了一个标准 3 层 RNN 网络的一个并行化策略示例,该网络包含了一个嵌入层、一个循环层和一个线性层。它表示了一种常用的模型并行化操作,即将每层中的不同操作符分配给一个专用的 GPU。图 6 则是相应的任务图,每个正方形和六边形分别表示常规任务和通信任务,并且每个有向边表示任务之间的依赖关系。
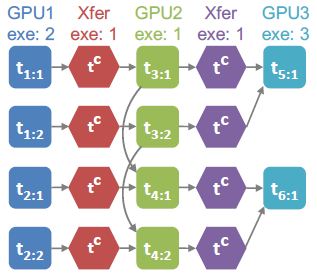
图 6:图 5 中并行化策略相应的任务图
对于任务图中每个任务的属性,作者给出了下表作为参考:
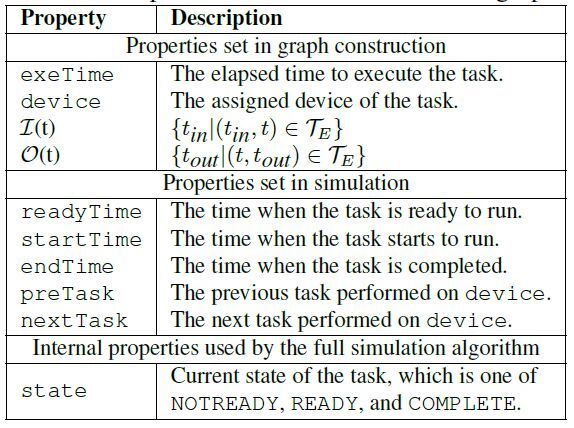
表 2:任务图中每个任务的相关属性
作者实现了一个全模拟算法作为基线,从而与他们提出的增量模拟算法进行比较。作者使用了 Dijkstra’s 最短距离算法的变体对任务图中的每个任务的属性进行配置。对于 Flex Flow,作者使用了 MCMC 搜索算法来产生新的并行策略。在通常情况下,从一个策略转变为另一个策略时,大部分任务的执行时间并不会产生变化。基于这个观察,作者提出了一种增量模拟算法,直接从前一个任务图推断当前更新的任务图的时间线。增量模拟算法极大的提高了执行模拟器的运行速度,尤其是对于大的分布式机器。图 7 是全模拟算法与增量模拟算法的任务图比较。
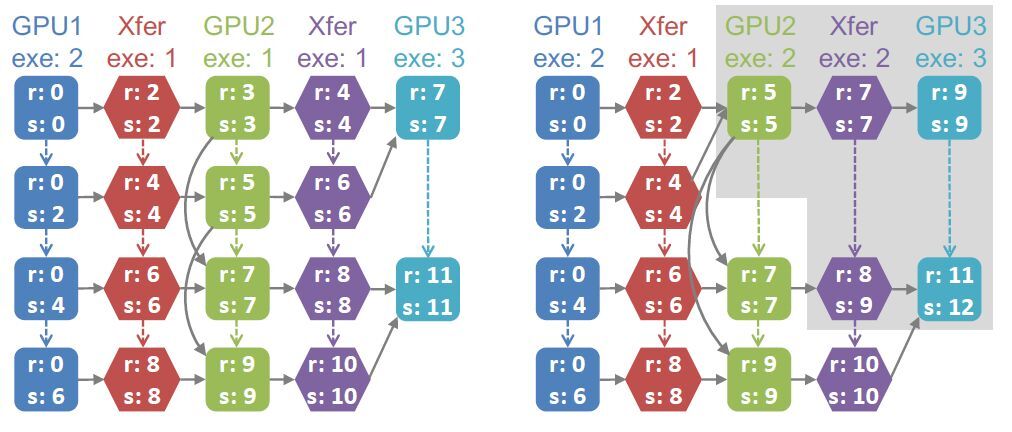
图 7:左半部分为全模拟算法的任务图,右半部分为增量模拟算法的任务图。
2.4 优化器
为了降低搜索策略地成本,FlexFlow 使用成本最小化搜索来启发式地探索搜索空间并返回最优策略:根据给定的初始策略 S,通过随机选择一个运算符并用随机选择的新运算符替换其并行化配置来创建新的候选策略 S^*,然后使用模拟器估计新候选策略的成本。新的候选策略被接受并变为新的当前策略地概率服从以下分布(Metropolis-Hastings MCMC):
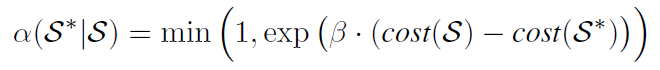
换句话说,只要新策略具有相同或更低的成本,就可以保证被接受。但同时系统也可以接受具有较高成本的策略,其可能性由参数β控制。
3 实验
作者使用 FlexFlow 在两个不同的 GPU 集群上对六个真实 DNN 基准进行评估。两个集群结构如下图所示:
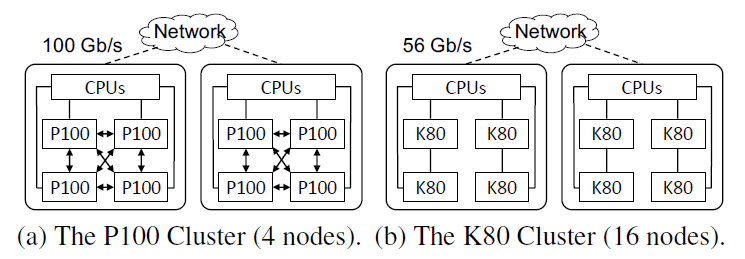
图 8:NVIDIA Tesla P100 集群和 K80 集群。
图 9 展示了所有 6 个 DNN 基准测试地每次迭代训练效果,对于 ResNet-101,FlexFlow 搜索到了类似数据并行地策略,除了在最后一个全连接层的单个节点上使用了模型并行外。相比于其他的 DNN 基准测试,FlexFlow 比基线算法找到了更多有效的策略,并且速度提高了 1.3-3.3 倍。
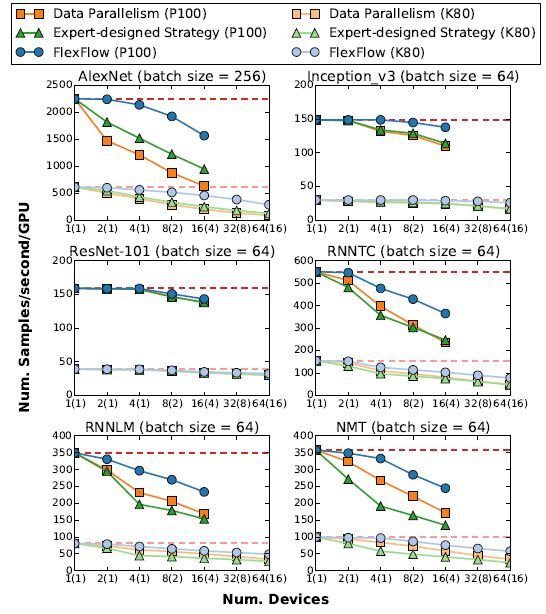
图 9:六个不同的 DNN 模型训练效果。括号中的数字是实验中使用的计算节点的数量,虚线表示理想的训练过程吞吐量。
与其他并行化策略相比,FlexFlow 发现的策略将每次迭代过程中的数据传输减少了 2-5.5 倍,并且还减少了任务的计算时间。此外,对于一个 DNN 模型,FlexFlow 与其他深度学习系统中的计算方法相同,因此可以得到相同的准确率。表 3 验证了 FlexFlow 在实验中可以使 DNN 基准模型达到了最好的精度。

表 4:实验中 DNN 模型的实现细节、所用数据库以及准确率。
这部分实验中,作者还比较了 FlexFlow 和 TensorFlow 在 Inception-V3 上进行端到端的训练时的性能。作者在 ImageNet 数据库上使用两种不同的框架训练 Inception-V3 模型,当模型在验证集上 single-crop 的条件下 top-1 精确率达到 72%时停止训练。对于 FlexFlow 和 TensorFlow 这两种框架,作者均使用了随机梯度下降(SGD)进行优化,其中学习率为 0.045,权重衰减为 0.0001。图 10 展示了两种系统的训练曲线,可以看出 FlexFlow 比 TensorFlow 少了 38%的训练时间。
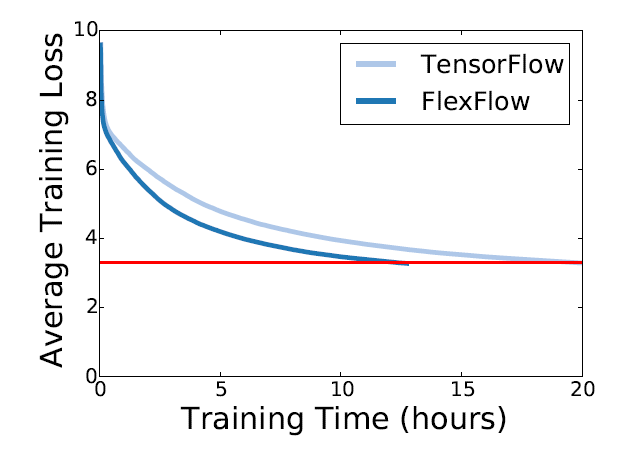
图 10:不同框架下 Inception-V3 的训练曲线,硬件系统为 16 个 P100 GPU(4 节点)。
同时,作者也对模拟器的性能进行了评估。在图 11 中,作者比较了不同模拟算法进行策略搜索性能。全模拟算法和增量模拟算法分别需要 16 分钟和 6 分钟以完成搜索。如果将搜索时间限制在 8 分钟内,全模拟算法只能得到很差的搜索结果。
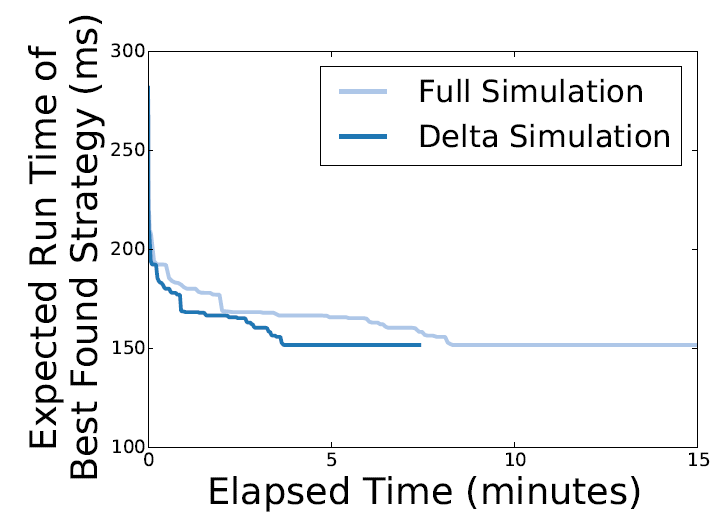
图 11:全模拟算法和增量模拟算法在 16 个 P100GPU(4 节点)对 NMT 模型进行搜索的性能比较。
此外,作者对本文使用的搜索算法与针对小规模计算的全局最优化搜索方法的性能进行了比较。为了获得合理的搜索空间大小,作者将设备数限制为 4,并使用了两种 DNN 模型。其中一个时 6 层的卷积神经网络 LeNet,另一个是 RNNLM 的变体。经过实验,作者发现对于全局最优化搜索方法,LeNet 和 RNNLM 分别需要经过 0.8 和 18 个小时的搜索才能得到最优策略。而 FlexFlow 在 1 秒内就能找到全局最优策略。
4 实例探究
图 12 给出了在四个 P100GPU 上 Inception-v3 的最优并行化策略,该策略在关键路径上使用运算符内并行化,在不同的分支上组合使用运算符内的运算符间并行化。这种并行化策略可以实现工作负载地均衡化,同时可以减少参数同步时的数据传递。与数据并行方法相比,该策略将参数同步时的成本降低了 75%,并将每次迭代的执行时间减少了 12%。
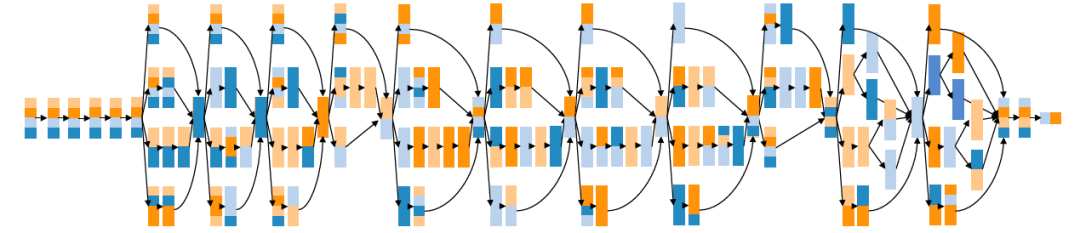
图 12:在四个 P100GPU 上 Inception-v3 的最优并行化策略。对于每个运算符,竖直和水平维度分别表示样本并行化和参数并行化。每个 GPU 由不同的颜色表示。
图 13 是 NMT 模型在四个 P100GPU 上搜索到的最优化并行策略。首先,对于网络中参数量较大的且运算较少的层(例如 embedding 层),该策略使用单 GPU 进行运算以减少参数同步的成本。其次,对于参数量大且运算量大的层(例如 softmax 层),FlexFlow 使用参数维度的并行化策略,并为每个任务的参数子集分配计算资源。这一方式在保持工作负载平衡的同时,减少了参数同步的成本。最终,对于多层循环层(例如 LSTM 和 Attention 层),FlexFlow 使用不同层之间的并发以及每个运算符内的并行性来降低参数同步成本,同时平衡负载。
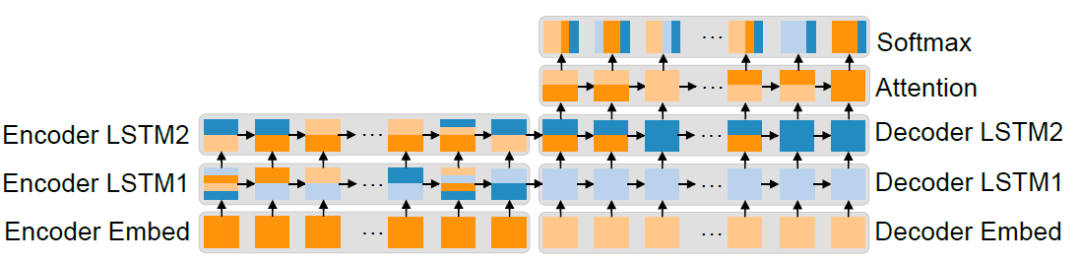
图 13:在 4 个 P100 GPU 上并行化 NMT 的最佳策略。对于每个运算符,竖直和水平维度分别表示样本并行化和参数并行化。每个灰色框表示一个层,其运算符共享相同的网络参数。每个 GPU 由不同的颜色表示。
论文原文:https://www.sysml.cc/doc/2019/16.pdf
Matei 团队其他研究成果

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论