导读:深度学习不仅在于其强大的学习能力,更在于它的创新能力。我们通过构建判别模型来提升模型的学习能力,通过构建生成模型来发挥其创新能力。判别模型通常利用训练样本训练模型,然后利用该模型,对新样本 x,进行判别或预测。而生成模型正好反过来,根据一些规则 y,来生成新样本 x。
生成式模型很多,本章主要介绍常用的两种:变分自动编码器 ( VAE ) 和生成式对抗网络 ( GAN ) 及其变种。虽然两者都是生成模型,并且通过各自的生成能力展现其强大的创新能力,但他们在具体实现上有所不同。GAN 是基于博弈论,目的是找到达到纳什均衡的判别器网络和生成器网络。而 VAE 基本根植贝叶斯推理,其目标是潜在地建模,从模型中采样新的数据。
本章主要介绍多种生成式网络,具体内容如下:
用变分自编码器生成图像
GAN 简介
如何用 GAN 生成图像
比较 VAE 与 GAN 的异同
CGAN、DCGAN 简介
8.1 用变分自编码器生成图像
变分自编码器是自编码器的改进版本,自编码器是一种无监督学习,但它无法产生新的内容,变分自编码器对其潜在空间进行拓展,使其满足正态分布,情况就大不一样了。
8.1.1 自编码器
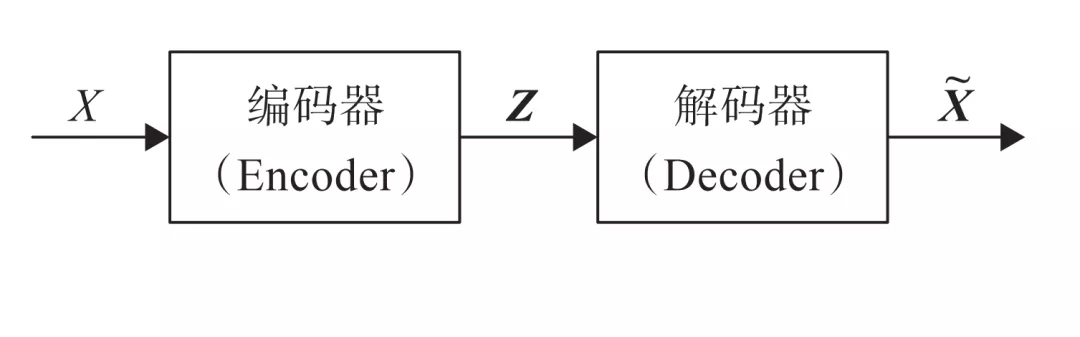
自编码器是通过对输入 X 进行编码后得到一个低维的向量 z,然后根据这个向量还原出输入 X。通过对比 X 与 X~ 的误差,再利用神经网络去训练使得误差逐渐减小,从而达到非监督学习的目的。
图 8-1 自编码器的架构图
自编码器因不能随意产生合理的潜在变量,从而导致它无法产生新的内容。因为潜在变量 Z 都是编码器从原始图片中产生的。为解决这一问题,研究人员对潜在空间 Z ( 潜在变量对应的空间 ) 增加一些约束,使 Z 满足正态分布,由此就出现了 VAE 模型,VAE 对编码器添加约束,就是强迫它产生服从单位正态分布的潜在变量。正是这种约束,把 VAE 和自编码器区分开来。
8.1.2 变分自编码器
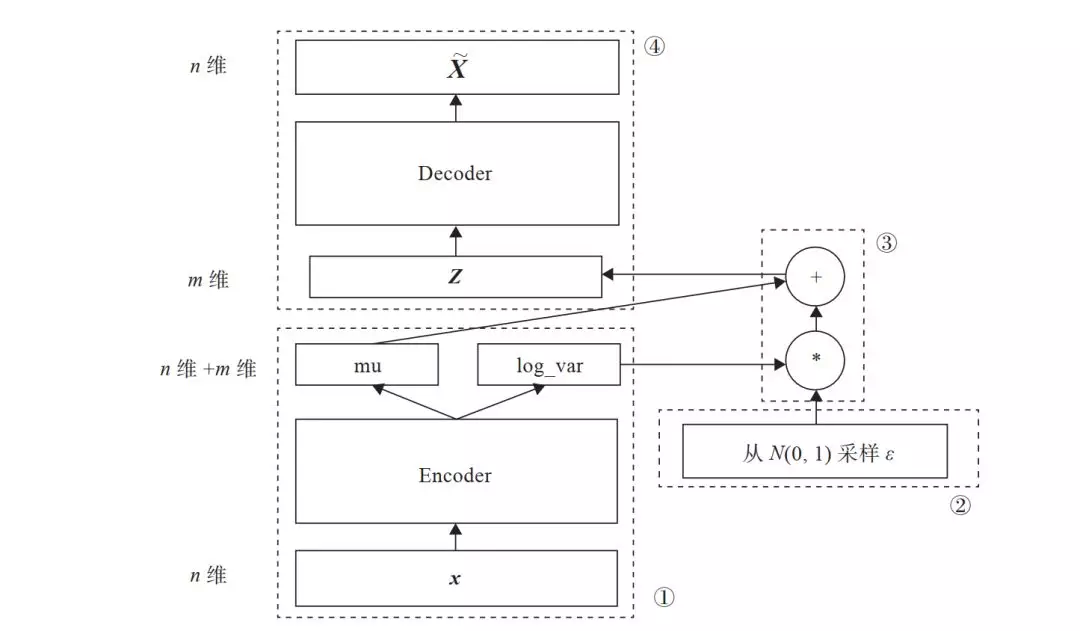
变分自编码器关键一点就是增加一个对潜在空间 Z 的正态分布约束,如何确定这个正态分布就成主要目标,我们知道要确定正态分布,只要确定其两个参数均值 u 和标准差。那么如何确定 u、σ?用一般的方法或估计比较麻烦效果也不好,研究人员发现用神经网络去拟合,简单效果也不错。图 8-2 为 AVE 的架构图。
图 8-2 AVE 架构图
在图 8-2 中,模块①的功能把输入样本 X 通过编码器输出两个 m 维向量 ( mu、log_var ),这两个向量是潜在空间 ( 假设满足正态分布 ) 的两个参数 ( 相当于均值和方差 )。那么如何从这个潜在空间采用一个点 Z?
这里假设潜在正态分布能生成输入图像,从标准正态分布 N(0, I) 中采样一个 ( 模块②的功能 ),然后使
**Z = mu + exp(log_var)\*(8-1)**
这也是模块③的主要功能。
Z 是从潜在空间抽取的一个向量,Z 通过解码器生成一个样本 X~,这是模块④的功能。
这里是随机采样的,这就可保证潜在空间的连续性、良好的结构性。而这些特性使得潜在空间的每个方向都表示数据中有意义的变化方向。
以上这些步骤构成整个网络的前向传播过程,那反向传播应如何进行?要确定反向传播就会涉及损失函数,损失函数是衡量模型优劣的主要指标。这里我们需要从以下两个方面进行衡量:
生成的新图像与原图像的相似度;
隐含空间的分布与正态分布的相似度。
度量图像的相似度一般采用交叉熵 ( 如 nn.BCELoss ),度量两个分布的相似度一般采用 KL 散度 ( Kullback-Leibler divergence )。这两个度量的和构成了整个模型的损失函数。
以下是损失函数的具体代码,AVE 损失函数的推导过程,有兴趣的读者可参考原论文:
https://arxiv.org/pdf/1606.05908.pdf
# 定义重构损失函数及KL散度reconst_loss = F.binary_cross_entropy(x_reconst, x, size_average=False)kl_div = - 0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())#两者相加得总损失loss= reconst_loss+ kl_div
复制代码
8.1.3 用变分自编码器生成图像
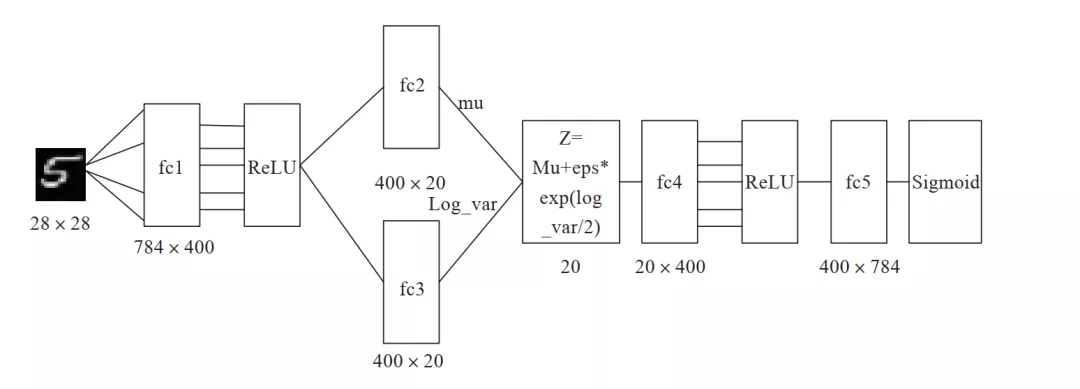
前面已经介绍了 AVE 的架构和原理,至此对 AVE 的“蓝图”就有了大致了解,如何实现这个蓝图?本节我们将结合代码,用 PyTorch 实现 AVE。此外,还包括在实现过程中需要注意的一些问题,为便于说明起见,数据集采用 MNIST,整个网络结构如图 8-3 所示。
先简单介绍一下实现的具体步骤,然后,结合代码详细说明,如何用 PyTorch 一步步实现 AVE。具体步骤如下:
导入必要的包。
import osimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torchvisionfrom torchvision import transformsfrom torchvision.utils import save_image
复制代码
图 8-3 AVE 网络结构图
定义一些超参数。
image_size = 784h_dim = 400z_dim = 20num_epochs = 30batch_size = 128learning_rate = 0.001
复制代码
对数据集进行预处理,如转换为 Tensor,把数据集转换为循环、可批量加载的数据集。
# 下载MNIST训练集,这里因已下载,故download=False# 如果需要下载,设置download=True将自动下载dataset = torchvision.datasets.MNIST(root='data', train=True, transform=transforms.ToTensor(), download=False) shuffle=True)
#数据加载data_loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=batch_size,
复制代码
构建 AVE 模型,主要由 Encode 和 Decode 两部分组成。
# 定义AVE模型class VAE(nn.Module): def __init__(self, image_size=784, h_dim=400, z_dim=20): super(VAE, self).__init__() self.fc1 = nn.Linear(image_size, h_dim) self.fc2 = nn.Linear(h_dim, z_dim) self.fc3 = nn.Linear(h_dim, z_dim) self.fc4 = nn.Linear(z_dim, h_dim) self.fc5 = nn.Linear(h_dim, image_size) def encode(self, x): h = F.relu(self.fc1(x)) return self.fc2(h), self.fc3(h) #用mu,log_var生成一个潜在空间点z,mu,log_var为两个统计参数,我们假设#这个假设分布能生成图像。def reparameterize(self, mu, log_var): std = torch.exp(log_var/2) eps = torch.randn_like(std) return mu + eps * std def decode(self, z): h = F.relu(self.fc4(z)) return F.sigmoid(self.fc5(h)) def forward(self, x): mu, log_var = self.encode(x) z = self.reparameterize(mu, log_var) x_reconst = self.decode(z) return x_reconst, mu, log_var
复制代码
选择 GPU 及优化器。
# 设置PyTorch在哪块GPU上运行,这里假设使用序号为1的这块GPU.torch.cuda.set_device(1)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = VAE().to(device)optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
复制代码
训练模型,同时保存原图像与随机生成的图像。
with torch.no_grad(): # 保存采样图像,即潜在向量Z通过解码器生成的新图像 z = torch.randn(batch_size, z_dim).to(device) out = model.decode(z).view(-1, 1, 28, 28) save_image(out, os.path.join(sample_dir, 'sampled-{}.png'.format(epoch+1))) # 保存重构图像,即原图像通过解码器生成的图像 out, _, _ = model(x) x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3) save_image(x_concat, os.path.join(sample_dir, 'reconst-{}.png'.format(epoch+1)))'
复制代码
展示原图像及重构图像。
reconsPath = './ave_samples/reconst-30.png'Image = mpimg.imread(reconsPath)plt.imshow(Image) # 显示图像plt.axis('off') # 不显示坐标轴plt.show()
复制代码
这是迭代 30 次的结果,如图 8-4 所示。
图 8-4 AVE 构建图像
图 8-4 中,奇数列为原图像,偶数列为原图像重构的图像。从这个结果可以看出重构图像效果还不错。图 8-5 为由潜在空间通过解码器生成的新图像,这个图像效果也不错。
图 8-5 AVE 新图像
显示由潜在空间点 Z 生成的新图像。
genPath = './ave_samples/sampled-30.png'Image = mpimg.imread(genPath)plt.imshow(Image) # 显示图像plt.axis('off') # 不显示坐标轴plt.show()
复制代码
这里构建网络主要用全连接层,有兴趣的读者,可以把卷积层,如果编码层使用卷积层 ( 如 nn.Conv2d ),解码器需要使用反卷积层 ( nn.ConvTranspose2d )。接下来我们介绍生成式对抗网络,并用该网络生成新数字,其效果将好于 AVE 生成的数字。
8.2 GAN 简介
8.1 节介绍了基于自动编码器的 AVE,根据这个网络可以生成新的图像。本节我们将介绍另一种生成式网络,它是基于博弈论的,所以又称为生成式对抗网络 ( Generative Adversarial Nets,GAN )。它是 2014 年由 Ian Goodfellow 提出的,它要解决的问题是如何从训练样本中学习出新样本,训练样本就是图像就生成新图像,训练样本是文章就输出新文章等。
GAN 既不依赖标签来优化,也不是根据对结果奖惩来调整参数。它是依据生成器和判别器之间的博弈来不断优化。打个不一定很恰当的比喻,就像一台验钞机和一台制造假币的机器之间的博弈,两者不断博弈,博弈的结果假币越来越像真币,直到验钞机无法识别一张货币是假币还是真币为止。这样说,还是有点抽象,接下来我们将从多个侧面进行说明。
8.2.1 GAN 架构
VAE 利用潜在空间,可以生成连续的新图像,不过因损失函数采用像素间的距离,所以图像有点模糊。那能否生成更清晰的新图像呢?可以的,这里采用 GAN 替换 VAE 的潜在空间,它能够迫使生成图像与真实图像在统计上几乎无法区别的逼真合成图像。
GAN 的直观理解,可以想象一个名画伪造者想伪造一幅达芬奇的画作,开始时,伪造者技术不精,但他将自己的一些赝品和达芬奇的作品混在一起,请一个艺术商人对每一幅画进行真实性评估,并向伪造者反馈,告诉他哪些看起来像真迹、哪些看起来不像真迹。
伪造者根据这些反馈,改进自己的赝品。随着时间的推移,伪造者技能越来越高,艺术商人也变得越来越擅长找出赝品。最后,他们手上就拥有了一些非常逼真的赝品。
这就是 GAN 的基本原理。这里有两个角色,一个是伪造者,另一个是技术鉴赏者。他们训练的目的都是打败对方。
因此,GAN 从网络的角度来看,它由两部分组成。
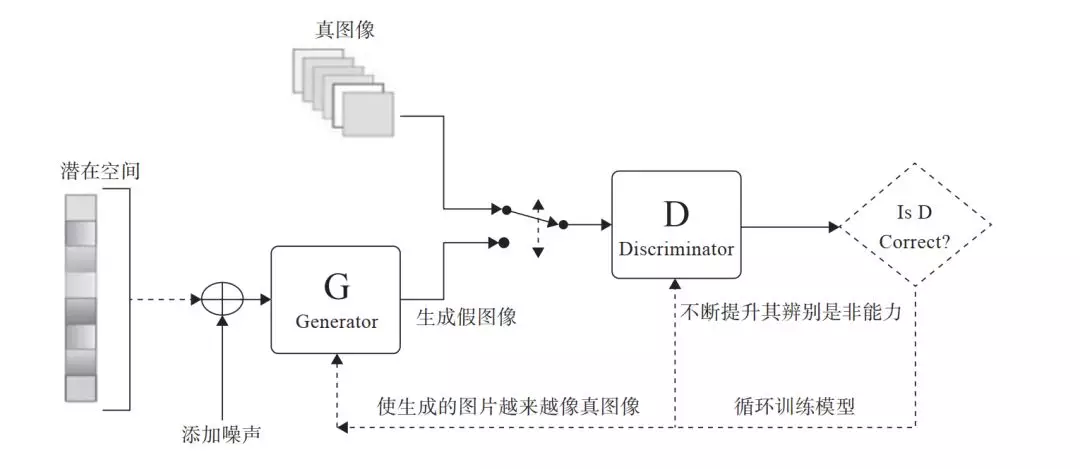
生成器网络:它一个潜在空间的随机向量作为输入,并将其解码为一张合成图像。
判别器网络:以一张图像 ( 真实的或合成的均可 ) 作为输入,并预测该图像来自训练集还是来自生成器网络。图 8-6 为其架构图。
如何不断提升判别器辨别是非的能力?如何使生成的图像越来越像真图像?这些都通过控制它们各自的损失函数来控制。
训练结束后,生成器能够将输入空间中的任何点转换为一张可信图像。与 VAE 不同的是,这个潜空间无法保证带连续性或有特殊含义的结构。
GAN 的优化过程不像通常的求损失函数的最小值,而是保持生成与判别两股力量的动态平衡。因此,其训练过程要比一般神经网络难很多。
图 8-6 GAN 架构图
8.2.2 GAN 的损失函数
从 GAN 的架构图 ( 图 8-6 ) 可知,控制生成器或判别器的关键是损失函数,而如何定义损失函数就成为整个 GAN 的关键。我们的目标很明确,既要不断提升判断器辨别是非或真假的能力,又要不断提升生成器不断提升图像质量,使判别器越来越难判别。那这些目标如何用程序体现?损失函数就能充分说明。
为了达到判别器的目标,其损失函数既要考虑识别真图像能力,又要考虑识别假图像能力,而不能只考虑一方面,故判别器的损失函数为两者的和,具体代码如下:D 表示判别器、G 为生成器、real_labels、fake_labels 分别表示真图像标签、假图像标签。images 是真图像,z 是从潜在空间随机采样的向量,通过生成器得到假图像。
# 定义判断器对真图像的损失函数outputs = D(images)d_loss_real = criterion(outputs, real_labels)real_score = outputs # 定义判别器对假图像(即由潜在空间点生成的图像)的损失函数z = torch.randn(batch_size, latent_size).to(device)fake_images = G(z)outputs = D(fake_images)d_loss_fake = criterion(outputs, fake_labels)fake_score = outputs # 得到判别器总的损失函数d_loss = d_loss_real + d_loss_fake
复制代码
生成器的损失函数如何定义,才能使其越来越向真图像靠近?以真图像为标杆或标签即可。具体代码如下:
z = torch.randn(batch_size, latent_size).to(device)fake_images = G(z)outputs = D(fake_images) g_loss = criterion(outputs, real_labels)
复制代码
8.3 用 GAN 生成图像
为便于说明 GAN 的关键环节,这里我们弱化了网络和数据集的复杂度。数据集为 MNIST、网络用全连接层。后续将用一些卷积层的实例来说明。
8.3.1 判别器
获取数据,导入模块基本与 AVE 的类似,这里就不展开来说,详细内容读者可参考 pytorch-08-01.ipynb 代码模块。
定义判别器网络结构,这里使用 LeakyReLU 为激活函数,输出一个节点并经过 Sigmoid 后输出,用于真假二分类。
# 构建判断器D = nn.Sequential( nn.Linear(image_size, hidden_size), nn.LeakyReLU(0.2), nn.Linear(hidden_size, hidden_size), nn.LeakyReLU(0.2), nn.Linear(hidden_size, 1), nn.Sigmoid())
复制代码
8.3.2 生成器
生成器与 AVE 的生成器类似,不同的地方是输出为 nn.tanh,使用 nn.tanh 将使数据分布在 [–1,1] 之间。其输入是潜在空间的向量 z,输出维度与真图像相同。
# 构建生成器,这个相当于AVE中的解码器G = nn.Sequential( nn.Linear(latent_size, hidden_size), nn.ReLU(), nn.Linear(hidden_size, hidden_size), nn.ReLU(), nn.Linear(hidden_size, image_size), nn.Tanh())
复制代码
8.3.3 训练模型
for epoch in range(num_epochs): for i, (images, _) in enumerate(data_loader): images = images.reshape(batch_size, -1).to(device) # 定义图像是真或假的标签 real_labels = torch.ones(batch_size, 1).to(device) fake_labels = torch.zeros(batch_size, 1).to(device) #==================================================================== # # 训练判别器 # #==================================================================== # # 定义判别器对真图像的损失函数 outputs = D(images) d_loss_real = criterion(outputs, real_labels) real_score = outputs # 定义判别器对假图像(即由潜在空间点生成的图像)的损失函数 z = torch.randn(batch_size, latent_size).to(device) fake_images = G(z) outputs = D(fake_images) d_loss_fake = criterion(outputs, fake_labels) fake_score = outputs # 得到判别器总的损失函数 d_loss = d_loss_real + d_loss_fake # 对生成器、判别器的梯度清零 reset_grad() d_loss.backward() d_optimizer.step() #==================================================================== # # 训练生成器 # #==================================================================== # # 定义生成器对假图像的损失函数,这里我们要求 #判别器生成的图像越来越像真图片,故损失函数中 #的标签改为真图像的标签,即希望生成的假图像, #越来越靠近真图像 z = torch.randn(batch_size, latent_size).to(device) fake_images = G(z) outputs = D(fake_images) g_loss = criterion(outputs, real_labels) # 对生成器、判别器的梯度清零 #进行反向传播及运行生成器的优化器 reset_grad() g_loss.backward() g_optimizer.step() if (i+1) % 200 == 0: print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}' .format(epoch, num_epochs, i+1, total_step, d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item())) # 保存真图像 if (epoch+1) == 1: images = images.reshape(images.size(0), 1, 28, 28) save_image(denorm(images), os.path.join(sample_dir, 'real_images.png')) # 保存假图像 fake_images = fake_images.reshape(fake_images.size(0), 1, 28, 28) save_image(denorm(fake_images), os.path.join(sample_dir, 'fake_images-{}.png'.format(epoch+1))) # 保存模型torch.save(G.state_dict(), 'G.ckpt')torch.save(D.state_dict(), 'D.ckpt')
复制代码
8.3.4 可视化结果
可视化每次由生成器得到假图像,即潜在向量 z 通过生成器得到的图像,其可视化结果如图 8-7 所示。
reconsPath = './gan_samples/fake_images-200.png'Image = mpimg.imread(reconsPath)plt.imshow(Image) # 显示图片plt.axis('off') # 不显示坐标轴plt.show()
复制代码
图 8-7 GAN 的新图像
可见图 8-7 明显好于图 8-5。AVE 生成图像主要依据原图像与新图像的交叉熵,而 GAN 真假图片的交叉熵,同时还兼顾了不断提升判别器和生成器本身的性能上。
8.4 VAE 与 GAN 的优缺点
VAE 和 GAN 都是生成模型 ( Generative Model )。所谓生成模型,即能生成样本的模型,利用这类模型,我们可以完成图像自动生成 ( 采样 )、图像信息补全等工作。
VAE 是利用已有图像在编码器生成潜在向量,这个向量在服从高斯分布的情况下很好地保留了原图像的特征,在解码器得到的图片会更加的合理与准确。
VAE 适合于学习具有良好结构的潜在空间,潜在空间有比较好的连续性,其中存在一些有特定意义的方向。VAE 能够捕捉到图像的结构变化 ( 倾斜角度、圈的位置、形状变化、表情变化等 )。这也是 VAE 的一大优点,它有显式的分布,能够容易地可视化图像的分布,具体如图 8-8 所示。
图 8-8 AVE 得到的数据流形分布图
但是图像在训练的时候损失函数只能用均方误差 ( MSE ) 之类的粗略误差衡量,这就导致生成的图像不能很好地保留原图像的清晰度,就会使得图片看上去有点模糊。
GAN 生成的潜在空间可能没有良好结构,但 GAN 生成的图像一般比 VAE 的更清晰。
在 GAN 的训练过程中容易发生崩溃,以及训练时梯度消失情况的发生。生成对抗网络的博弈理论只是单纯的让 G 生成的图像骗过 D,这个会让 G 钻空子一旦骗过了 D 不论图像的合不合理就作为输出,于是模型坍塌 ( Generative Model ) 就发生了。
GAN 生成器的损失函数 ( Loss ) 依赖于判别器 Loss 后向传递,而不是直接来自距离,因而若判别器总是能准确地判别出真假,则向后传递的信息就非常少,导致生成器无法形成自己的 Loss,这是 GAN 比较难训练的原因。当然,针对这一不足,近些年人们采用一个新的距离定义 ( Wasserstein Distance ) 应用于判别器,而不是原型中简单粗暴的对真伪样本的分辨正确的概率。
综上所述,两者的优缺点可归结为以下两点:
GAN 生成的效果优于 VAE。
GAN 比 VAE 更难训练。
8.5 ConditionGAN
AVE 和 GAN 都能基于潜在空间的随机向量 z 生成新图片,GAN 生成的图像比 AVE 的更清晰,质量更好些。不过它们生成的都是随机的,无法预先控制你要生成的哪类或哪个数。
如果在生成新图像的同时,能加上一个目标控制那就太好了,如果希望生成某个数字,生成某个主题或类别的图像,实现按需生成的目的,这样的应用应该非常广泛。需求就是最大的生产力,经过研究人员的不懈努力,提出一个基于条件的 GAN,即 Condition GAN,简称为 CGAN。
8.5.1 CGAN 的架构
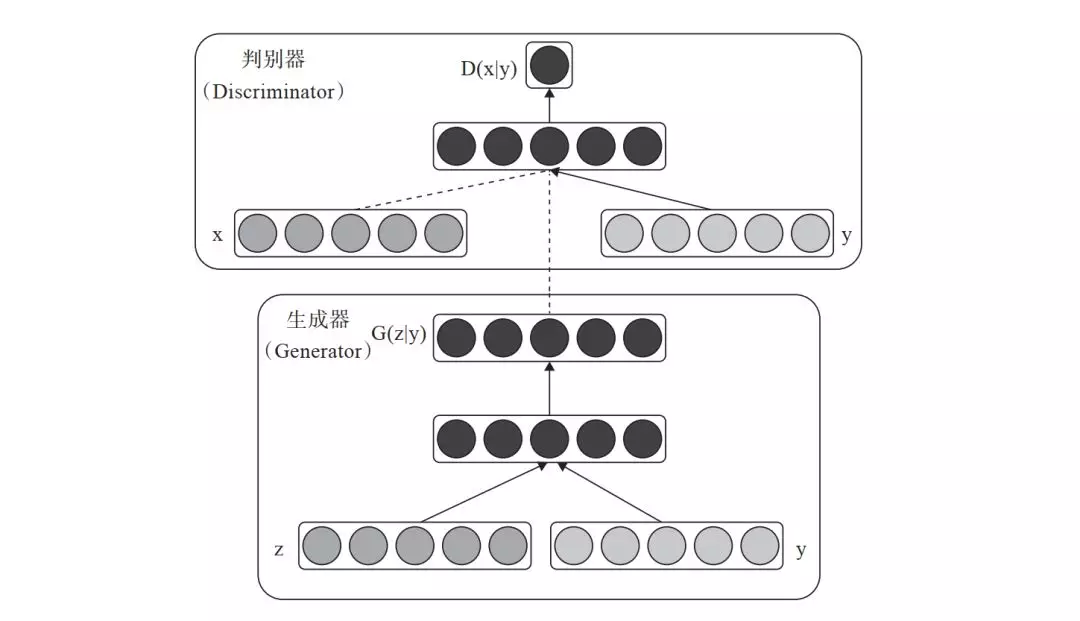
在 GAN 这种完全无监督的方式加上一个标签或一点监督信息,使整个网络就可看成半监督模型。其基本架构与 GAN 类似,只要添加一个条件 y 即可,y 就是加入的监督信息,比如说 MNIST 数据集可以提供某个数字的标签信息,人脸生成可以提供性别、是否微笑、年龄等信息,带某个主题的图像等标签信息。以下用图 8-9 来描述 CGAN 的架构。
图 8-9 CGAN 架构图
对生成器输入一个从潜在空间随机采样的一个向量 z 及一个条件 y,生成一个符合该条件的图像 G(z/y)。对判别器来说,输入一张图像 x 和条件 y,输出该图像在该条件下的概率 D(x/y)。这只是 CGAN 的一个蓝图,那如何实现这个蓝图?接下来采用 PyTorch 具体实现。
8.5.2 CGAN 生成器
定义生成器 ( Generator ) 及前向传播函数。
class Generator(nn.Module): def __init__(self): super().__init__() self.label_emb = nn.Embedding(10, 10) self.model = nn.Sequential( nn.Linear(110, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 512), nn.LeakyReLU(0.2, inplace=True), nn.Linear(512, 1024), nn.LeakyReLU(0.2, inplace=True), nn.Linear(1024, 784), nn.Tanh() ) def forward(self, z, labels): z = z.view(z.size(0), 100) c = self.label_emb(labels) x = torch.cat([z, c], 1) out = self.model(x) return out.view(x.size(0), 28, 28)
复制代码
8.5.3 CGAN 判别器
定义判断器 ( Discriminator ) 及前向传播函数。
class Discriminator(nn.Module): def __init__(self): super().__init__() self.label_emb = nn.Embedding(10, 10) self.model = nn.Sequential( nn.Linear(794, 1024), nn.LeakyReLU(0.2, inplace=True), nn.Dropout(0.4), nn.Linear(1024, 512), nn.LeakyReLU(0.2, inplace=True), nn.Dropout(0.4), nn.Linear(512, 256), nn.LeakyReLU(0.2, inplace=True), nn.Dropout(0.4), nn.Linear(256, 1), nn.Sigmoid() ) def forward(self, x, labels): x = x.view(x.size(0), 784) c = self.label_emb(labels) x = torch.cat([x, c], 1) out = self.model(x) return out.squeeze()
复制代码
8.5.4 CGAN 损失函数
定义判别器对真、假图像的损失函数。
#定义判别器对真图像的损失函数real_validity = D(images, labels)d_loss_real = criterion(real_validity, real_labels)# 定义判别器对假图像(即由潜在空间点生成的图像)的损失函数z = torch.randn(batch_size, 100).to(device)fake_labels = torch.randint(0,10,(batch_size,)).to(device)fake_images = G(z, fake_labels)fake_validity = D(fake_images, fake_labels)d_loss_fake = criterion(fake_validity, torch.zeros(batch_size).to(device))#CGAN总的损失值d_loss = d_loss_real + d_loss_fake
复制代码
8.5.5 CGAN 可视化
利用网格(10×10)的形式显示指定条件下生成的图像,如图 8-10 所示。
图 8-10 CGAN 生成的图像
from torchvision.utils import make_gridz = torch.randn(100, 100).to(device)labels = torch.LongTensor([i for i in range(10) for _ in range(10)]).to(device) images = G(z, labels).unsqueeze(1)grid = make_grid(images, nrow=10, normalize=True)fig, ax = plt.subplots(figsize=(10,10))ax.imshow(grid.permute(1, 2, 0).detach().cpu().numpy(), cmap='binary')ax.axis('off')
复制代码
8.5.6 查看指定标签的数据
可视化指定单个数字条件下生成的数字。
def generate_digit(generator, digit): z = torch.randn(1, 100).to(device) label = torch.LongTensor([digit]).to(device) img = generator(z, label).detach().cpu() img = 0.5 * img + 0.5 return transforms.ToPILImage()(img)generate_digit(G, 8)
复制代码
运行结果如下:
8.5.7 可视化损失值
记录判别器、生成器的损失值代码:
writer.add_scalars('scalars', {'g_loss': g_loss, 'd_loss': d_loss}, step)
复制代码
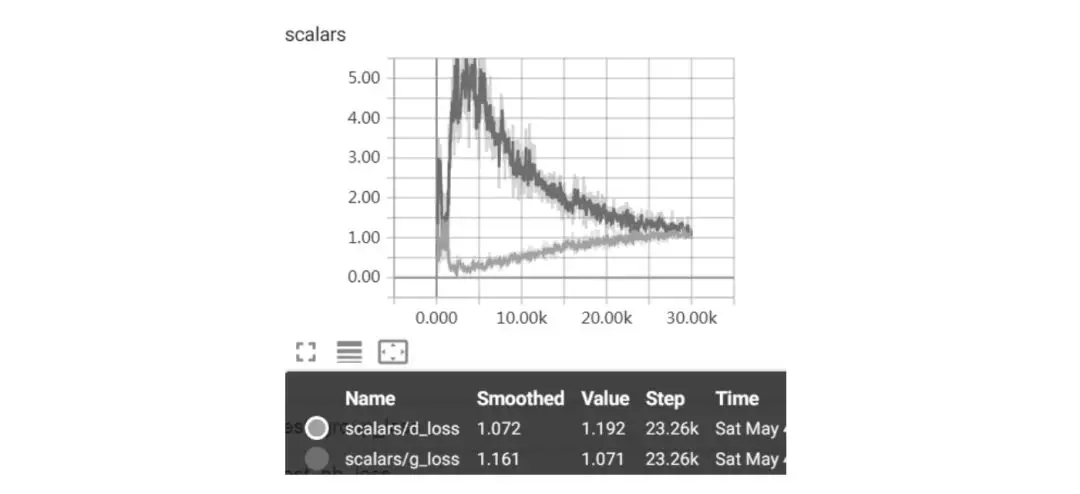
运行结果如图 8-11 所示。
图 8-11 CGAN 损失值
由图 8-11 可知,CGAN 的训练过程不像一般神经网络的过程,它是判别器和生成器互相竞争的过程,最后两者达成一个平衡。
8.6 DCGAN
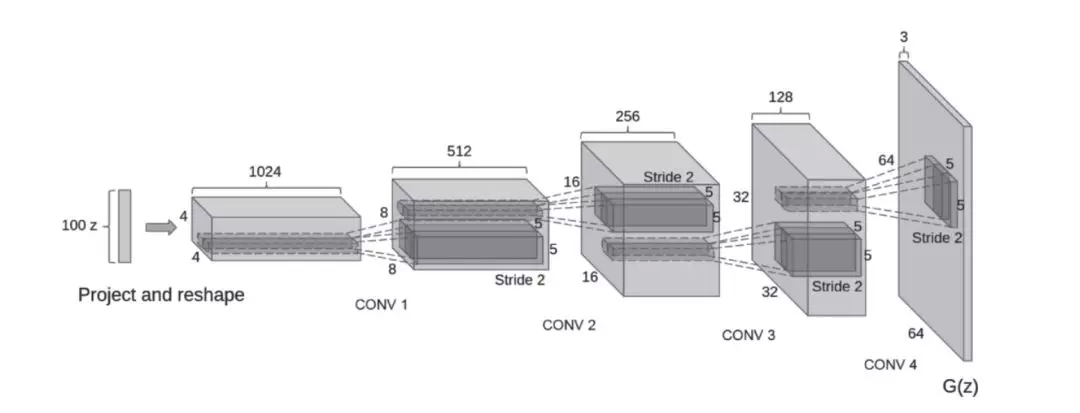
DCGAN 在 GAN 的基础上优化了网络结构,加入了卷积层 ( Conv )、转置卷积 ( ConvTranspose )、批量正则 ( Batch_norm ) 等层,使得网络更容易训练,图 8-12 为使用卷积层的 DCGAN 的生成器网络结构示意图。
图 8-12 使用卷积层的 DCGAN 的结构图
pytorch-08-01.ipynb 代码中含有使用卷积层的实例,有兴趣的读者可参考一下。下面是使用卷积层的判别器及使用转置卷积的生成器的一个具体代码。
使用卷积层、批规范层的判别器:
class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.main = nn.Sequential( # 输入大致为 (nc) x 64 x 64,nc表示通道数 nn.Conv2d(nc, ndf, 4, 2, 1, bias=False), nn.LeakyReLU(0.2, inplace=True), # ndf表示判别器特征图的大小 nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 2), nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 4), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False), nn.BatchNorm2d(ndf * 8), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False), nn.Sigmoid() ) def forward(self, input): return self.main(input)
复制代码
使用转置卷积、批规范层的生成器:
class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.main = nn.Sequential( # 输入Z,nz表示Z的大小。 nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False), nn.BatchNorm2d(ngf * 8), nn.ReLU(True), # ngf为生成器特征图大小 nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf * 4), nn.ReLU(True), # state size. (ngf*4) x 8 x 8 nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf * 2), nn.ReLU(True), # state size. (ngf*2) x 16 x 16 nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False), nn.BatchNorm2d(ngf), nn.ReLU(True), #nc为通道数nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False), nn.Tanh() ) def forward(self, input): return self.main(input)
复制代码
8.7 提升 GAN 训练效果的一些技巧
训练 GAN 是生成器和判别器互相竞争的动态过程,比一般的神经网络挑战更大。为了克服训练 GAN 模型的一些问题,人们从实践中总结一些常用方法,这些方法在一些情况下,效果不错。当然,这些方法不一定适合所有情况,方法如下。
批量加载和批规范化,有利于提升训练过程中博弈的稳定性。
使用 tanh 激活函数作为生成器最后一层,将图像数据规范在–1 和 1 之间,一般不用 sigmoid。
选用 Leaky ReLU 作为生成器和判别器的激活函数,有利于改善梯度的稀疏性,稀疏的梯度会妨碍 GAN 的训练。
使用卷积层时,考虑卷积核的大小能被步幅整除,否则,可能导致生成的图像中存在棋盘状伪影。
8.8 小结
变分自编码和对抗生成器是生成式网络的两种主要网络,本章介绍了这两种网络的主要架构及原理,并用具体实例实现这两种网络,此外还简单介绍了 GAN 的多种变种,如 CGAN、DCGAN 等对抗性网络,后续章节还将介绍 GAN 的其他一些实例。
文章摘自:《 Python 深度学习:基于 Pytorch 》 机械工业出版社.2019.11
作者介绍:
吴茂贵
资深大数据和人工智能技术专家,就职于中国外汇交易中心,在 BI、数据挖掘与分析、数据仓库、机器学习等领域工作超过 20 年。在基于 Spark、TensorFlow、PyTorch、Keras 等的机器学习和深度学习方面有大量的工程实践实践。著有《 Python 深度学习:基于 TensorFlow 》《深度实践 Spark 机器学习》《自己动手做大数据系统》等著作。
郁明敏
资深商业分析师,从事互联网金融算法研究工作,专注于大数据、机器学习以及数据可视化的相关领域,擅长 Python、Hadoop、Spark 等技术,拥有丰富的实战经验。曾获“江苏省 TI 杯大学生电子竞技大赛”二等奖和“华为杯全国大学生数学建模大赛”二等奖。
杨本法
高级算法工程师,在流程优化、数据分析、数据挖掘等领域有 10 余年实战经验,熟悉 Hadoop 和 Spark 技术栈。有大量工程实践经验,做过的项目包括:推荐系统、销售预测系统、舆情监控系统、拣货系统、报表可视化、配送路线优化系统等。
李涛
资深 AI 技术工程师,对 PyTorch、Caffe、TensorFlow 等深度学习框架以及计算机视觉技术有深刻的理解和丰富的实践经验,曾经参与和主导过服务机器人、无人售后店、搜索排序等多个人工智能相关的项目。
张粤磊
资深大数据技术专家,飞谷云创始人,有 10 余年一线数据数据挖掘与分析实战经验。先后在咨询、金融、互联网行业担任大数据平台的技术负责人或架构师。
本文来自 DataFun 社区
原文链接:
https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247495441&idx=1&sn=cb5397860421a579bc4f1834afb4f09d&chksm=fbd75d7dcca0d46b90b4d397be1b3064bc9d411af534afc5c27fe550f0adf25efbab605a4939&scene=27#wechat_redirect





















评论