

近日,自然语言处理(NLP)领域顶级会议 ACL-IJCNLP 2021 公布了论文接收情况。腾讯有 55 篇论文被接收,又一次刷新了论文录取数量纪录,领跑国内业界 AI 研究第一梯队。
本届 ACL 共收到 3350 篇论文投稿,其中主会论文录用率为 21.3%。腾讯 AI Lab 共入选 27 篇论文(含 9 篇 Findings),包括大会的六篇杰出论文之一,与香港中文大学合作完成的《基于单语翻译记忆的神经网络机器翻译技术(Neural Machine Translation with Monolingual Translation Memory)》。
在今年 6 月线上举办的另一自然语言处理领域顶会 NAACL 2021 中,腾讯 AI Lab 与罗切斯特大学合作的论文《视频辅助无监督语法归纳(Video-aided Unsupervised Grammar Induction)》获得最佳长论文。
本文将对腾讯 AI Lab 主导的两篇论文进行详细解读,并简要介绍部分入选 ACL 2021 的部分论文,包括对话及文本生成、翻译、文本理解等研究方向。
自然语言处理是腾讯 AI Lab 四大基础研究方向之一,主要包括文本理解、文本生成、机器翻译等研究方向,相关研究成果持续通过学术论文、开源数据集、工具及 API 服务等方式对外分享:
国内首个线上公开落地的交互翻译系统TranSmart:提供辅助翻译输入法、约束解码、翻译记忆融合等亮点功能,已支持了包括联合国文件署、Memsource、华泰证券、店小秘、阅文集团等在内的 B 端客户,以及腾讯内部众多的翻译业务。
文本理解系统TexSmart:与国内外的同类系统相比,不仅在在效果和速度上位居前列,更具有细粒度命名实体识别、语义联想、深度语义表达等特色功能。其 API 和 SDK 被腾讯内外众多业务和用户所调用。
包含八百万词汇的中文词向量开源数据集受到业界的广泛关注、讨论和使用,在多项应用得到性能提升。
ACL 2021 杰出论文:基于单语翻译记忆的神经网络机器翻译技术

论文地址:https://arxiv.org/pdf/2105.11269.pdf
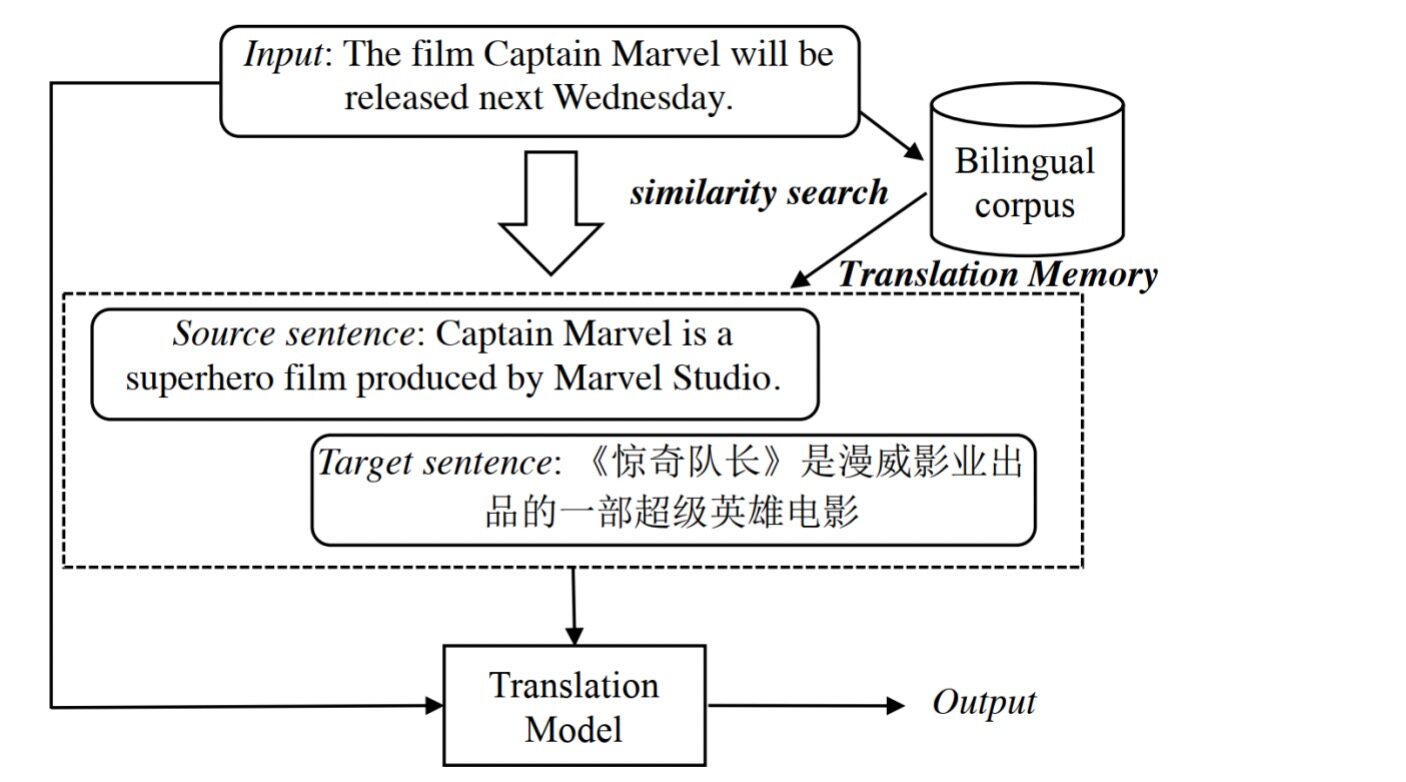
从 2017 年开始,包括微软、Facebook、腾讯在内的多支研究团队均致力于尝试利用检索式对话系统的结果引导生成式模型,以生成更加相关且更为丰富的对话回复。无独有偶,在机器翻译领域,来自 CMU、NYU、腾讯的多个团队也一直在推进利用翻译记忆 (Translation Memory) 提升翻译效果的研究工作。无论是对话还是翻译领域,之前他们的工作均集中在利用输入端相似度的检索方式从平行语料中检索数据,并以某种方式输入到深度生成网络来提升生成/翻译效果( 如下图所示)。
不同于上述工作,在本论文中,作者提出了一种全新的基于单语翻译记忆的翻译框架——训练过程中利用一个双塔结构(dual-encoder framework)的检索模型将源端句子和目标端句子在向量空间对齐,而推理过程中与源端句子在向量空间中距离最近的 k 条目标端句子,则会被选中作为翻译记忆。需要注意的是,该模型的检索范围并不限定在训练集的句子中,而可以来自任意的单语语料。随后,为了将检索模型与下游翻译模型统一为一个可以端到端训练的整体,检索模型输出的相似度分值将引导翻译模型的注意力(attention)集中到更为有用的检索结果上。基于这样的方式,检索模型可以通过如下逻辑被优化:对最终翻译过程有帮助(能提升参考译文似然度)的检索结果应该被奖励,而那些无用的检索结果则应被惩罚。
实验结果表明,本论文提出的模型即使不使用额外单语数据,翻译效果都要超出目前最好的,而在低资源场景下,一旦模型获得了更多额外的单语语料,模型的翻译效果会大幅度提升。最后,该模型只需对翻译记忆进行热切换就可以实现领域自适应,而不需要对模型进行任何微调。
一、模型设计
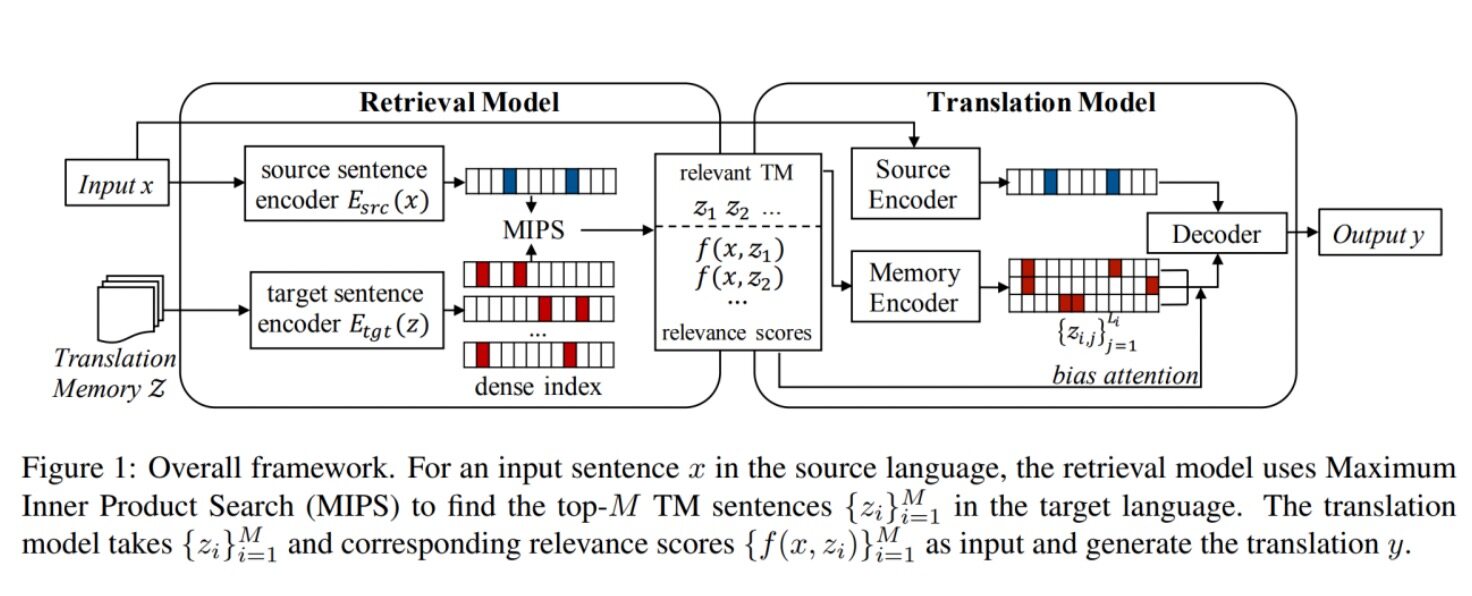

检索模型
本论文采取了双塔框架模型进行检索,该框架的优点在于能将搜索问题转化为最大内积搜索(Maximum Inner Product Search)。源端句子和目标端句子的相似度可以通过对应的向量表示的点积得到:

翻译模型
在翻译过程中,本论文为标准翻译框架(包括一个源端编码器和一个解码器)添加了一个额外的记忆编码器来输入翻译记忆。为了使检索模型和翻译模型能够一同被最终的翻译目标所优化,我们将检索模型得到的相关性分数加入到注意力中的计算中

跨语言对齐预训练任务
本论文提出的模型存在冷启动问题,因此作者提出了两种跨语言对齐预训练任务为检索模型热身。作者称这两个预训练任务在实践中缺一不可。
二、实验
本论文共进行了三种不同设置的实验:1)传统设置:所有模型都只能用训练集作为翻译记忆库,2)低资源设置:双语训练对数量较少,但模型可以使用额外的单语数据作为翻译记忆,3)利用单语数据实现翻译模型的非参数领域自适应。请注意已有的方法仅能直接适用于第一种设置,而 2) 3)两种设置只能依赖本论文提出的模型才成为可能。
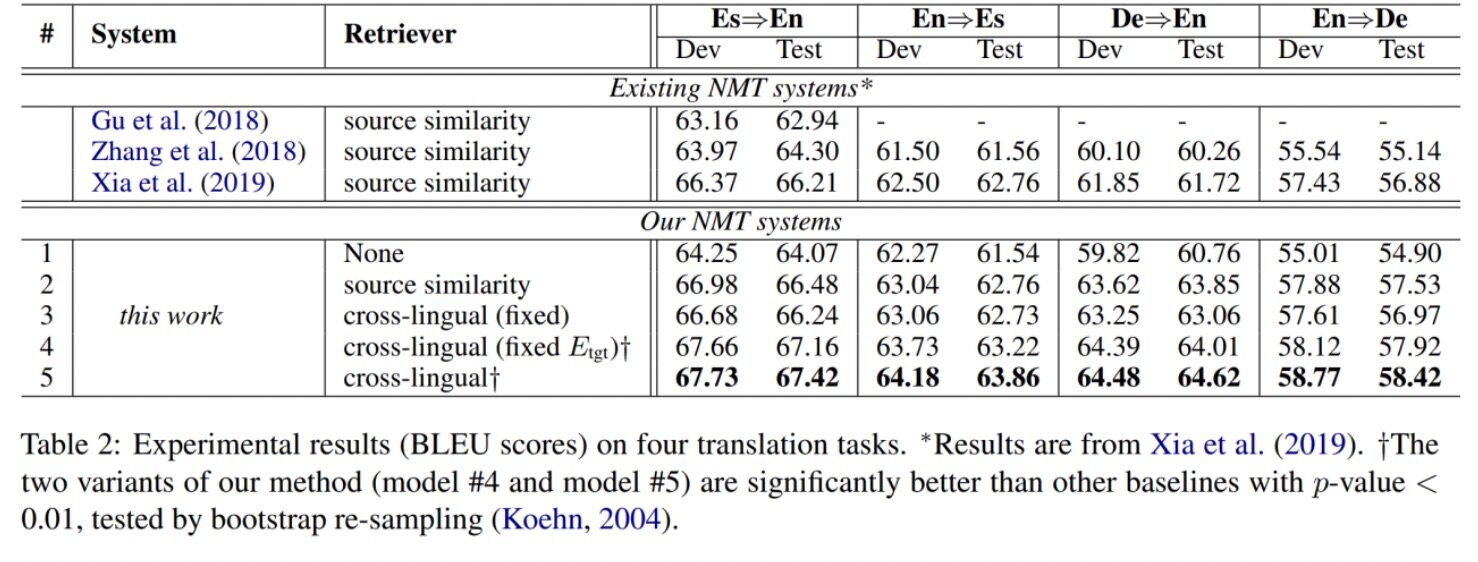
实验一:传统设置
本实验使用了翻译记忆的经典数据集 JRC-Acquis,并挑选了西英,英西,德英,英德四个翻译方向进行实验。实验中,作者复现了三种经典的基线模型的实验结果,并实现了一系列模型的变种来验证模型不同模块对翻译性能的影响。上表中的 Model 1-5 分别表示:
1. 没有使用翻译记忆的基本翻译模型 Transformer base。
2. 使用双语翻译记忆的基本翻译模型。
3. 本论文提出的模型,但不进行端到端优化,训练时仅更新翻译模型不更新检索模型。
4 & 5: 本论文提出的模型,区别在于异步更新策略 (因字数限制,该部分介绍被省略,详情请参阅原论文)
从实验结果可以看出,在所有任务上,本论文提出的完整模型均取得了最好效果,相对于不使用翻译记忆的基线模型(Model #1)平均提升了 3.26 BLEU 值。其中端到端训练是关键所在,Model #4 & 5,相对于没有进行端到端训练的 Model 3 都有超过 1 BLEU 值的性能提升。最令人惊奇的是,仅仅只使用单语翻译记忆的 Model #4 和 #Model 5 在性能上居然超过了使用双语翻译记忆的 Model 2 以及三种复现的基线模型。这可以归因于是端到端训练使跨语言检索模型能更好的适应下游的翻译任务。
实验二:低资源设置
如前文所说,本论文提出的模型最大优势在于能够将单语数据作为翻译记忆。为了证明单语翻译记忆的有效性,作者进行了低资源场景实验,实验中模型只能获得部分双语数据以及额外的单语数据作为翻译记忆。
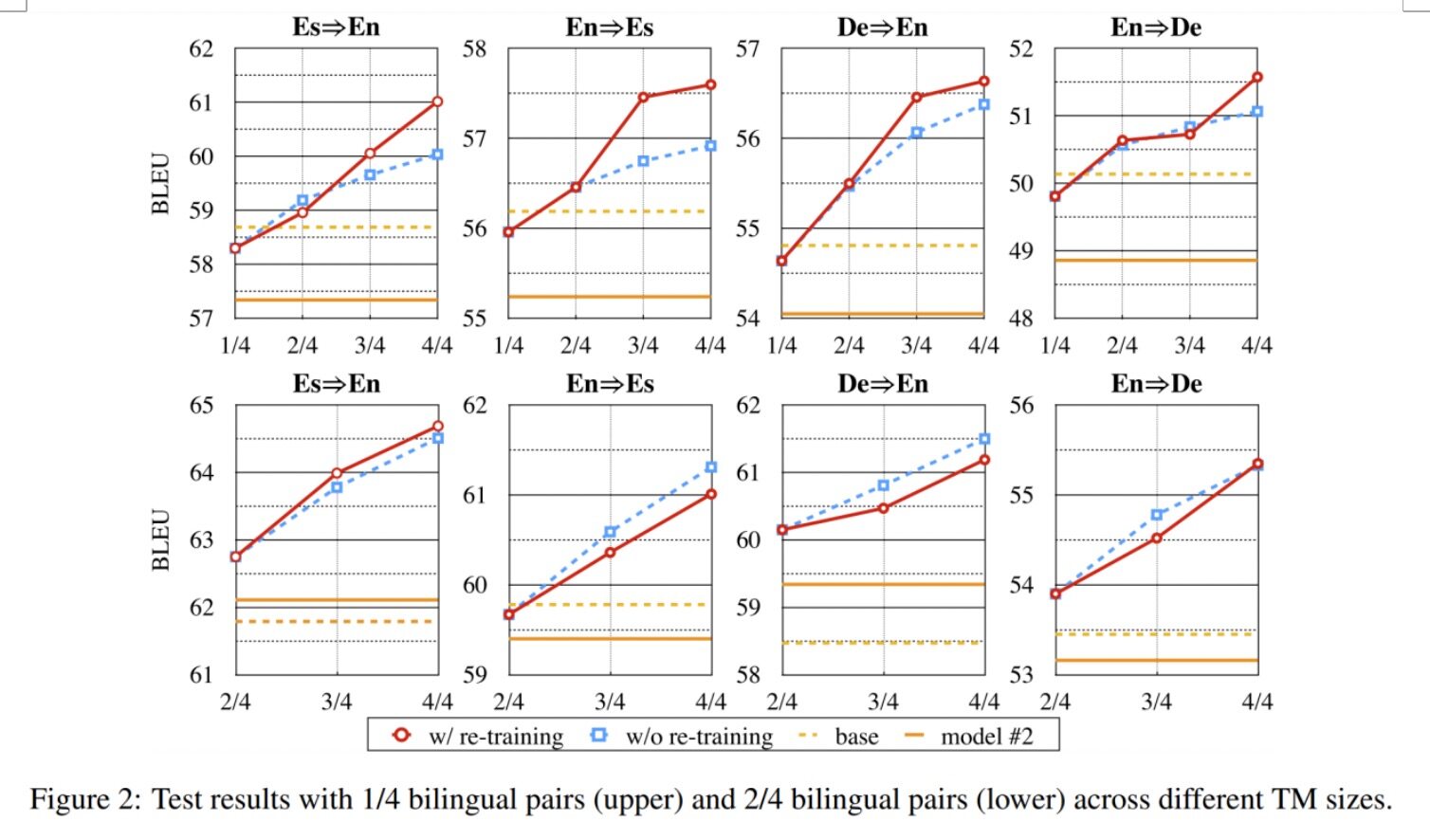
本场景下仍然有两种不同的训练选择:1)切换翻译记忆时不重新训练翻译模型;以及 2)切换翻译记忆时重新训练翻译模型。在上图中,蓝色虚线代表选择 1,而红色实线代表选择 2。可以看到,翻译质量随着翻译记忆库规模的增大而显著提升。另一个有趣的现象是,即使使用选择 1) 的方式训练,模型的性能也不会受到很大影响。
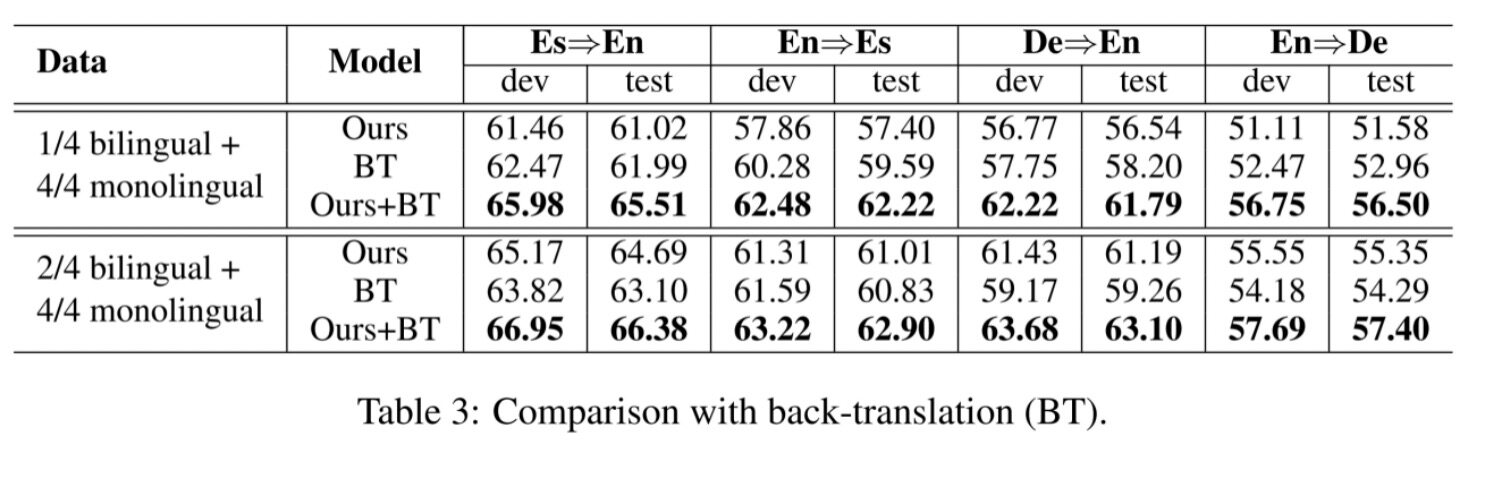
与 Back-translation 方法的对比:本论文也与 back-translation (BT) 方法进行了对比。如上表所示,本论文提出的方法与 BT 方法各有所长,但令人惊喜的是,结果表明两种方法是互补的,他们的结合使翻译性能取得了进一步的巨大提升。
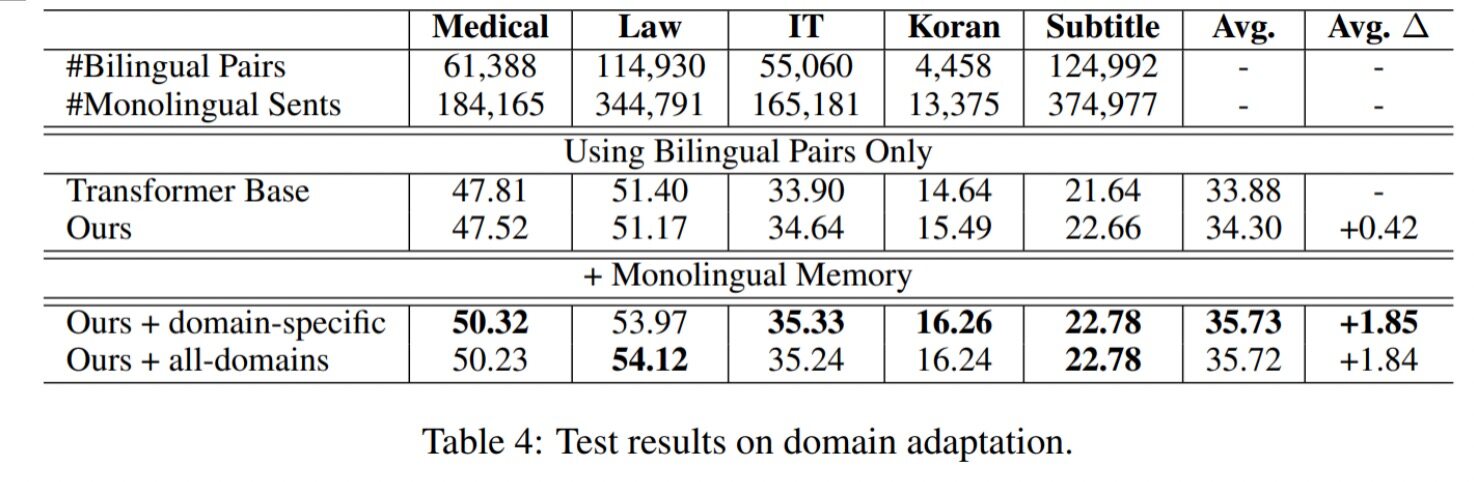
实验三:非参数领域自适应
本论文提出的模型的另一个独特优点是可以通过切换翻译记忆,不改变或增加参数即可以适用于特定领域。在最后一个实验中,作者通过切换翻译记忆,实现了翻译领域的自适应。上表中的实验结果表明,只使用双语翻译记忆时,基于翻译记忆的模型和不使用翻译记忆的模型效果各有千秋,但一旦增加了额外的单语翻译记忆,本论文提出的模型在五个领域上的平均 BLEU 值提升了 1.87。
三、总结
本论文首次提出了利用单语翻译记忆提升翻译模型,并发现跨语言的检索模型可以通过端到端的方式进行优化。本论文提出的方法在低资源场景下取得了巨大的性能提升,并且可以实现一个模型适用于所有领域。
作者指出了两个未来可能的提升方向:1)为了保证公平,本研究中所用到的编码器均从随机参数开始训练,使用预训练语言模型将进一步提升翻译性能;2)增大翻译记忆的多样性有可能显著提升翻译性能,但本论文中的模型结构并未考虑这一点。
NAACL 最佳论文:视频辅助无监督语法归纳

论文地址:https://arxiv.org/abs/2104.04369v2
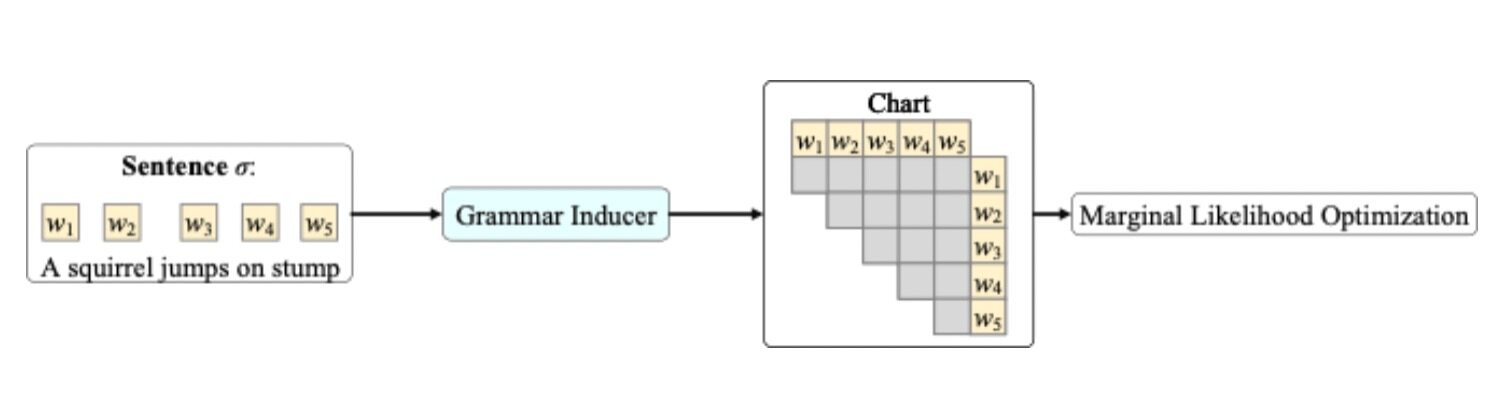
长久以来,句法分析一直都是 NLP 研究的热点话题之一。很多现有的方法都是在有语法标注的数据集上学习。但是这种有监督的学习存在两个弱点:1. 标注这样的数据集需要大量的语言专家,费时费力。2. 只有几个常见语种有标注好的数据集,许多小语种甚至没有足够的语言专家来标数据。因此,近些年来有越来越多的研究试图从海量未标注的文本中来进行无监督的句法学习。以 C-PCFG[1]为例(见下图),给定一个句子,句法抽取器(Grammar Inducer)预测出一个句法图(Chart),并对句子的边缘似然函数进行优化。
除了以上的商业价值以外,无监督句法分析还有着重要的科学价值,长期以来认知科学(cognitive science)界一直争论着人类能习得语言的原因:是人脑中天生就存在某种机制,还是单纯靠统计学习(statistical learning)的方式,而无监督句法分析正是用来验证统计学习理论的重要手段之一。
过去的无监督句法分析的方法都是以纯文本为输入,而视觉中含有很多文本所不具备的知识,因此最近有一些方法[2,3]试图通过图片信息来辅助无监督句法分析。以 VC-PCFG [3] 为例(见下图),它在 C-PCFG 的基础上额外增加了一个图片和句子之间的损失函数,通过图片特征对文本特征进行正则化,可进一步提高句法抽取器的性能。
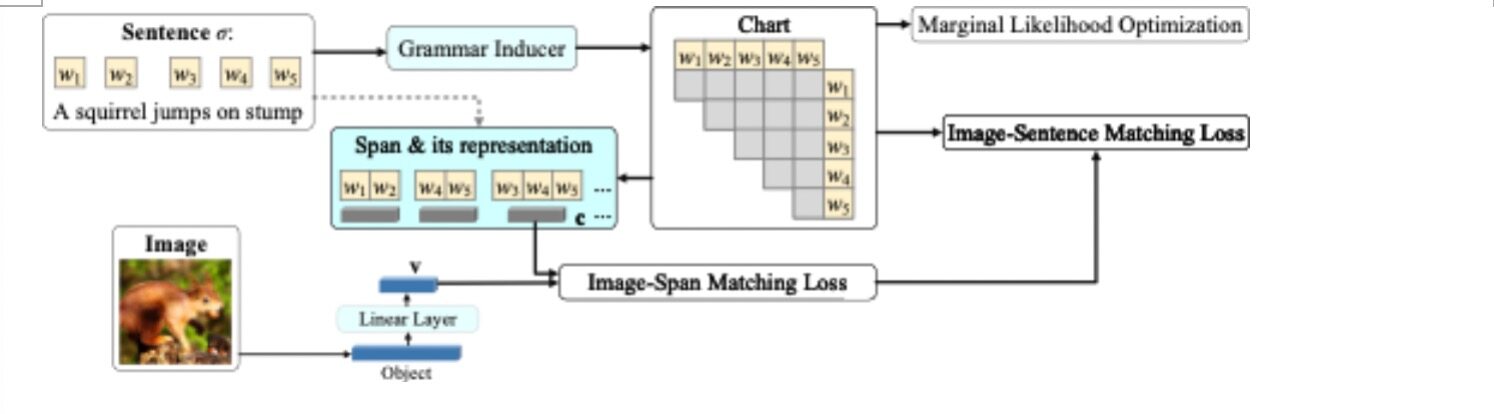
但是这种方法的提升是有局限的。从 VC-PCFG 论文的实验部分可以看到,相较于 C-PCFG,VC-PCFG 主要提升的是 NP 的性能,而在其他常见的短语类型上的提升并不明显,如 VP,PP,SBAR, ADJP 和 ADVP。这一现象也存在在另一篇文章 VG-NSL [2] 中。一个可能的解释是这两篇文章用到的图片特征提取器是在物体分类上训练的,这种特征对于物体有比较准确的描述从而提升了 NP。但对于涉及到物体的动作和变化的短语类型,如 VP,因为图片是静态的,这种物体分类的特征并不不能提供这样的变化信息。但如果我们将静态图片换成动态视频,很有可能对涉及到动词的短语类型也会有所提升。
本文提出了 Multi-Modal Compound PCFGs (MMC-PCFG)用于视频辅助的无监督句法分析 ,框架如下。与 VC-PCFG [3]不同的是,本模型以视频作为输入,并融合了视频多种模态的信息,是 VC-PCFG [3] 在视频上的泛化。
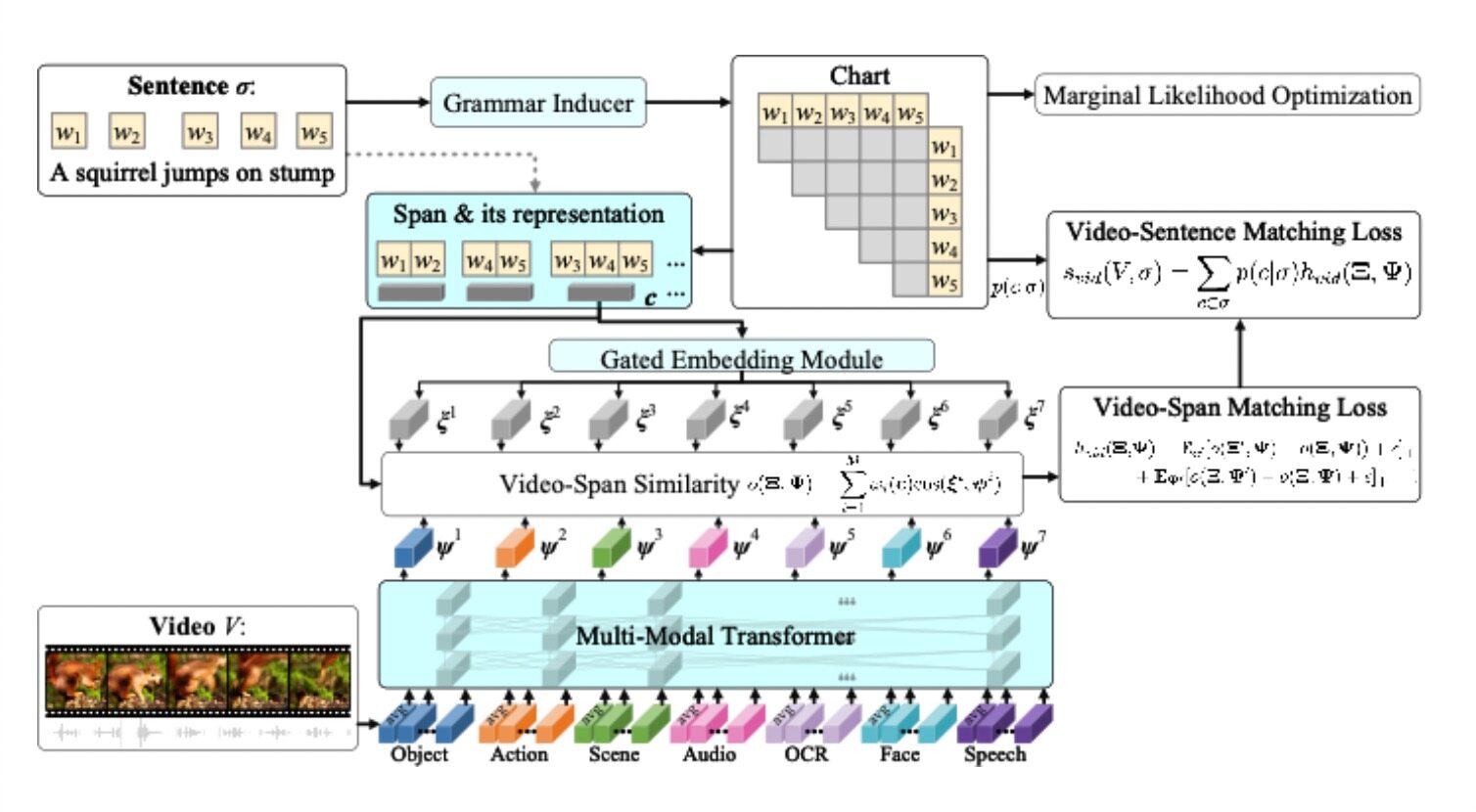
一、模型设计


二、实验
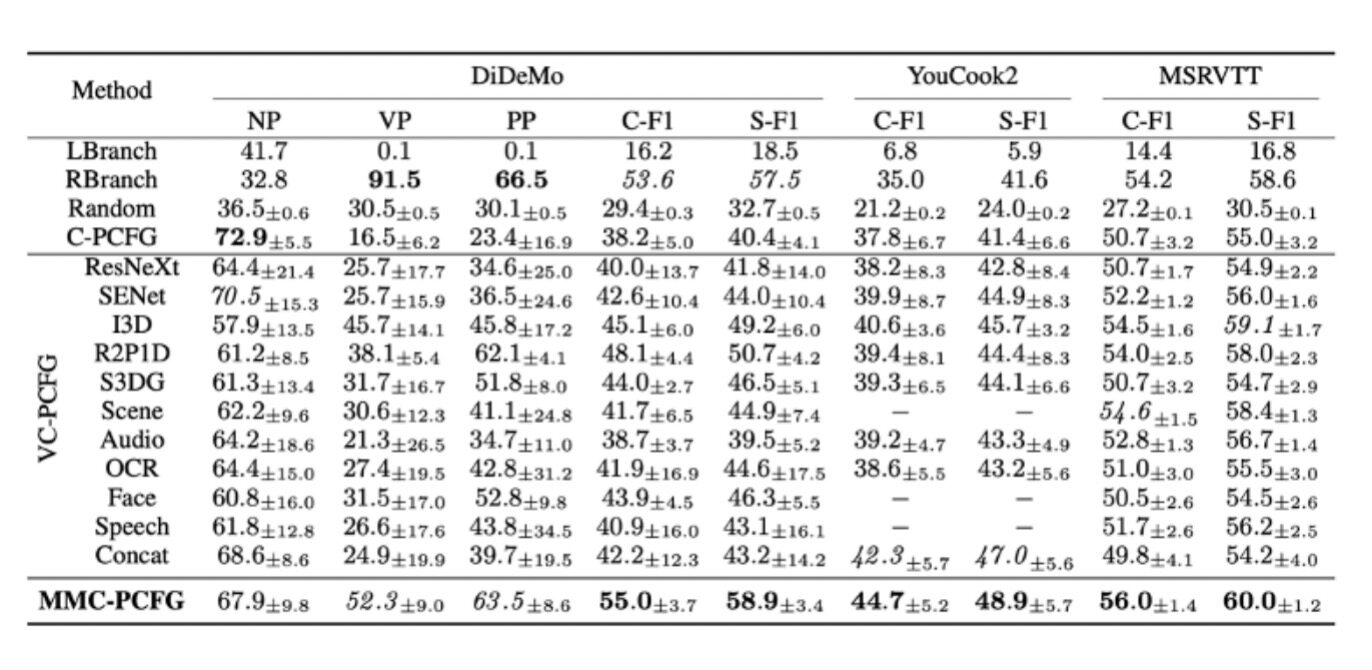
我们在三个数据集(DiDeMo, YouCook2, MSRVTT)上做了实验。因为这些数据集没有语法标注,我们用一个监督学习的方法[5]预测出来的结果当作 reference tree。对于物体和动作特征,我们还用不同模型提取了多种不同的特征,包括物体(ResNeXt-101,SENet-154)和动作(I3D,R2P1D,S3DG)。每组实验都跑 10 个 epoch 并用不同的种子跑了 4 次。实验结果见表 1。LBranch,RBranch 和 Random 代表 left branching tree, right branching tree 和 random tree。因为 VC-PCFG 是为图片设计的,不能直接以视频作为输入。为了对比 VC-PCFG,我们设计了一些简单的 baseline。第一种 baseline 是将单个特征在时间轴上取平均,作为 VC-PCFG 输入 (ResNeXt, SENet …, Speech)。另一个 baseline 是将这些取平均的特征连接在一起然后作为 VC-PCFG 的输入 (Concat)。
首先我们比较 C-F1 和 S-F1 这两个综合评指标。 Right Branching 性能很强主要因为英语很大程度上是 right branching 的。VC-PCFG 整体上要比比 C-PCFG 效果要好,说明利用视频信息是有帮助的。简单的将所有特征连在一起并不能让效果变的更好,有时甚至还不如单个特征(比如 Concat 和 R2P1D)。其主要原因是没有考虑特征直接的关系。而我们提出的 MMC-PCFG 在所有三个数据集中性能都达到了最好的结果,说明我们的模型可以有效利用所有特征的信息。
接下来我们比较这些方法在 NP,VP 和 PP 三种常见短语类型的召回率。对比在单个特征训练的 VC-PCFG,使用物体特征(ResNeXt-101,SENet-154)在 NP 上的效果更好,而使用动作特征(I3D,R2P1D,S3DG)在 VP 和 PP 上效果更好。这验证了不同特征对不同的句法结构贡献不同。和 VC-PCFG 相比,MMC-PCFG 在 NP,VP 和 PP 的召回率都是前两名且标准差较小,再次说明 MMC-PCFG 可以有效利用所有特征的信息,并给出较为一致的预测。
三、总结
受限于静态图片的表达能力,现有基于图片的无监督句法分析方法对于动词相关的短语提升有限。本文所提出的利用视频来辅助无监督句法分析可有效的解决这个问题。同时本文还提出了 Multi-Modal Compound PCFG 用来集成多种不同的特征。该模型的有效性在三个数据集上得到了验证。
从认知科学的角度看,考虑视觉信息、尤其是视频信息,更加接近人类所处的多模态环境,因此本文的结论推进了语言习得中统计学习理论的可能性,而如果这一理论最终得以验证,那么最终打造一个能实时捕捉多模态信息的机器人去习得人类语言将更有可能。
引用:
[1] Kim et al. Compound Probabilistic Context-Free Grammars for Grammar Induction. ACL 2019
[2] Shi et al. Visually Grounded Neural Syntax Acquisition. ACL 2019
[3] Zhao et al. Visually Grounded Compound PCFGs. EMNLP 2020
[4] Gabeur et al. Multi-modal Transformer for Video Retrieval. ECCV 2020
[5] Kitaev et al. Constituency Parsing with a Self-Attentive Encoder. ACL 2018
腾讯 AI Lab 其他入选论文简介
一、对话及文本生成
1. 文本生成中不需要增强数据的数据增强方法
Data Augmentation for Text Generation Without Any Augmented Data
本文由腾讯 AI Lab 独立完成。数据增强是许多基于神经网络的文本生成模型提高性能的有效方法。然而,目前的数据增强方法需要人工定义或选择适当的映射函数来将原始样本映射到增强数据样本。本文推导出一个目标函数对文本生成任务上的数据增强问题进行建模。该方法可以不使用由映射函数构建的增强数据来达到数据增强的目的,且其目标能在保证收敛的情况下被高效地优化,并能集成到文本生成任务常用的损失函数中。在两个文本生成任务的五个数据集上进行的实验表明,该方法可以接近甚至超过常用的数据增强方法。
2. 利用层次课程学习提升对话回复选择能力
Dialogue Response Selection with Hierarchical Curriculum Learning
本文由腾讯主导,与剑桥大学、香港中文大学合作完成。本文主要研究领域为检索式对话系统中的回复选择问题,提出了一种层次课程学习框架,以“从易到难”的顺序训练回复选择模型。该框架包括两种不同课程:语料级课程和实例级课程。在语料级课程中,该模型逐渐学习到了如何找到与对话上文匹配的回复,而在实例级课程中,模型逐渐学习到了如何发现与对话上文不匹配的回复。我们用层次课程学习框架训练了三个最新的回复选择模型,并在三个标准数据集上验证其效果,实验表明,本文提出的学习框架使模型在各种评价指标上都获得了显著的提升。
3. 利用中心性加权和自身冗余性实现无需训练且无需参考的摘要评测
A Training-free and Reference-free Summarization Evaluation Metric via Centrality-weighted Relevance and Self-referenced Redundancy
本文由腾讯 AI Lab 与香港中文大学合作完成。本文提出了一种无需训练并且无需人工标注参考的摘要评测方法。该方法由中心性加权的相关分数和自我参考的冗余分数组成。对于相关分数,我们会先从输入文档中建立伪参考,然后我们计算给定的摘要与加权过后的伪参考之间的相关分数。对于摘要的冗余分数,我们使用摘要本身计算一个自我掩盖的相似分数来评估该摘要中的冗余信息。最终,我们结合所得到的相关分数和冗余分数来生成给定摘要的最终评测分数。实验证明,在单文档摘要评测和多文档摘要评测中,其性能超过了现存的不需要参考摘要的方法。
4. REAM♯: 面向开放域对话系统中带有参考的评价指标的一种增强方法
REAM♯: An Enhancement Approach to Reference-based Evaluation Metrics for Open-domain Dialog Generation
本文由腾讯 AI Lab 主导,与鹏城实验室合作完成。目前开放域对话系统面临的较大困难是缺乏一个可靠的自动评测方法。现有的开放域对话文本评测方法主要是基于参考文本的评测方式,而其可靠性既依赖于其捕捉两个文本语义相似度的能力,也依赖于参考文本集合的质量,本文的目标则是填补当下后者的研究空白。基于“高质量的参考文本有助于提高评测可靠性”的假设,本文提出一种增强方法 REAM♯,设计了一个基于图网络的模型来预测参考集合的可靠分数,以提升参考文本集合的质量。同时作者展示如何使用预测的可靠分数来帮助构建高质量的参考回复集合。实验结果表明,本文提出的模型能够有效提高评测方法的可靠性。
5. 基于隐空间的开放域对话评价
Enhancing the Open-Domain Dialogue Evaluation in Latent Space
本文由腾讯 AI Lab 主导,与北京大学、苏州大学、中国人民大学等合作完成。开放域对话中“一对多”特性导致了其自动评估方法的设计成为一个巨大的挑战。本文提出通过隐空间建模增强的对话评估指标——EMS,利用自监督学习来获得一个平滑的隐空间,既可提取对话的上下文信息,也可以对该上下文可能的合理回复进行建模,然后利用隐空间中捕捉的信息对对话评测过程进行增强。在两个真实世界对话数据集上的实验结果证明了该方法的优越性,其中与人类判断相关的 Pearson 和 Spearman 相关性分数均胜过所有基线模型。
6. 去芜存菁:两阶段同义句生成方法
Keep the Primary, Rewrite the Secondary: A Two-Stage Approach for Paraphrase Generation
本文由腾讯 AI Lab 与剑桥大学、苹果公司合作完成。同义句生成是一个重要且具有挑战性的自然语言生成问题。在这项工作中,我们提出了一个新的“识别-聚集”框架来解决此问题。 在识别步骤中,输入的句子通过一种主/次识别算法被分为主要内容和次要内容。在聚合步骤中,两组内容分别编码,然后再由解码器进行聚合,该解码器会以自回归的方式生成相似句。在两个标准数据集的实验中,我们证明了该模型明显优于先前的研究。我们还发现该方法可以以可解释和可控制的方式生成同义句。
7. 基于分布距离的对话系统评价
Assessing Dialogue Systems with Distribution Distances
本文由腾讯 AI Lab 主导,与中国科学技术大学,意大利特伦托大学,香港中文大学合作完成。本文提出了一种通过计算生成对话与真实对话之间的分布距离来衡量对话系统表现的方法,并提出了两种基于分布距离的评价指标——FBD 和 PRD。多个对话数据集上的实验结果表明,与现有的评价指标相比,该指标与人类的评价具有更好的相关性。
二、翻译
1. 快速且准确的神经翻译记忆模型
Fast and Accurate Neural Machine Translation with Translation Memory
本文由腾讯 AI Lab 与西南大学和南京大学合作完成,提出了一种高效且准确的融合翻译记忆的神经翻译模型。此模型架构简单,仅使用一个双语句子作为其翻译记忆,因而它的训练和推理相当高效;我们还提出了一种新的训练方法来优化模型参数。实验结果表明,相比于几种使用多个双语句子作为翻译记忆的强基线系统,该模型在翻译质量和运行时间方面有极大的优势,且该模型在两个通用任务(WMT Zh->En 和 En ->De)上也能提升翻译质量。
2. 歪打正着:重新审视多模态机器翻译对视觉上下文的需求
Good for Misconceived Reasons: An Empirical Revisiting on the Need for Visual Context in Multimodal Machine Translation
本文由腾讯 AI Lab 与香港大学、华东师范大学合作完成。多模态翻译系统(MMT)在传统的基于纯文本的机器翻译系统上引入了额外的模态信息,从而达到提升翻译效果的目的,但人们仍不清楚这个提升是不是真正来源于引入的多模态信息。本文提出了两个可解释的 MMT 系统,并借此机会重新审视了多模态信息在 MMT 系统中的贡献。模型显示其在解码阶段忽略了多模态信息,却仍然取得了和当前 MMT 模型类似的翻译效果提升。更进一步,作者发现引入多模态信息带来的提升其实来源于正则化效应(regularization effect)。文章详细讨论了该实验发现及其对后续 MMT 研究的影响。
3. 面向通用辅助翻译场景的词级别自动提示
GWLAN: General Word-Level AutocompletioN for Computer-Aided Translation
本文由腾讯 AI Lab 独立完成。计算机辅助翻译(CAT)的核心是根据人工译员提供的文本片段提示翻译结果的自动补全功能。本文中从真实的 CAT 场景中提出了一个通用词级自动补全任务(GWLAN),并构建了第一个公开基准以促进该领域的研究。此外,作者为 GWLAN 任务提出了一种简单有效的方法,并将其与几个基线进行比较。实验证明,在构建的基准数据集上,该方法可以比基线方法提供更准确的预测。
4. 神经机器翻译中基于单语数据不确定性的自学习采样方法
Self-Training Sampling with Monolingual Data Uncertainty for Neural Machine Translation
本文由腾讯 AI Lab 主导,与香港中文大学合作完成。传统自训练需要从大规模单语数据中随机采样一个子集进行伪双语数据的构建。为提升现有的采样策略,本文尝试从真实双语数据中提取双语词典,并基于这个双语词典计算单语句子的不确定性。直觉上,具有较低不确定性的单语句子一般包含比较容易翻译的特征,不能够给真实双语带来额外的增益。于是作者提出一个基于不确定性的采样策略,给予那些不确定性更高的单语句子更高的采样概率。为了验证该方法的有效性,作者在两个千万级数据集(WMT 英⇒德和英⇒中)上进行实验,对比随机采样和语言模型采样等方法,还能更进一步提高翻译系统的性能。后续的分析实验显示,该方法有效提升了具有高不确定性句子的翻译质量,同时能够帮助目标端语言低频词的预测。
论文代码已开源:https://github.com/wxjiao/UncSamp。
5. 低频词起死回生:充分利用平行数据提升非自回归翻译
Low-Frequency Words Rejuvenation: Making the Most of Parallel Data in Non-Autoregressive Translation
本文由腾讯 AI Lab 主导,与悉尼大学、澳门大学合作完成。知识蒸馏(KD)常用于构造合成数据来训练非自回归翻译(NAT)模型。但该数据和原始数据在低频词分布上存在差异,从而产生更多的低频词翻译错误。本文提出借助预训练直接将原始数据暴露给 NAT。有向对齐分析发现 KD 使源端低频源词更确定性地与目标端对齐,但反向对齐较差。因此,我们提出反向 KD 来激活更多目标端低频词的对齐。最后我们充分利用真实数据和合成数据进一步提高 NAT 性能。我们在 5 个标准数据集上对两个代表性的 NAT 框架进行实验。结果表明,提出的方法降低了低频词的翻译错误,从而显著提高了翻译质量。
6. 预训练复制行为对神经机器翻译的影响
On the Copying Behaviors of Pre-Training for Neural Machine Translation
本文由腾讯 AI Lab 主导,与澳门大学、悉尼大学合作完成。我们发现预训练语言模型(LM)和神经机器翻译模型(NMT)训练目标之间存在较大差异。LM 的训练目标学习重建一部分源端单词并复制其中的绝大部分,而 NMT 的训练目标只复制小部分源端单词。因此,LM 初始化 NMT 会影响模型解码中的复制行为。我们引入复制率(Copying Ratio)指标对复制行为进行定量分析,从而验证了我们的假设。针对该问题,我们提出了一种简单且有效的复制惩罚(Copying Penalty)方法来控制 NMT 模型解码中的复制行为。实验结果表明该方法可以控制模型的复制行为并提高模型的翻译性能。
7. 神经机器翻译中的语言覆盖偏差
On the Language Coverage Bias for Neural Machine Translation
本文由腾讯 AI Lab 与清华大学合作完成。用于训练机器翻译模型的双语数据通常源自不同的语言,从而产生语言覆盖偏差(Language Coverage Bias),对机器翻译模型的忠实度影响很大。本文发现显式区分两类训练数据(source-original vs. target-original)可以有效缓解语言覆盖偏差对机器翻译模型的负面效应。实验证明我们的方法还可以进一步提高单语数据增强的方法(forward-translation & back-translation)。
8. 非自回归翻译中的渐进式多粒度训练方法
Progressive Multi-Granularity Training for Non-Autoregressive Translation
本文由腾讯 AI Lab 主导,与悉尼大学、澳门大学合作完成。非自回归翻译(NAT)是一种新的译文生成新范式,为优化 NAT 在学习高模态知识(如一对多翻译)的效果,本文提出了针对 NAT 的渐进式多粒度训练方法。基于 NAT 模型更倾向于学习细粒度的低模态知识的特性,作者将句子级样本分解为三种类型,即单词、短语、句子,并随着训练的进行,逐渐增加粒度,以充分利用训练数据。在罗马语-英语、英语-德语、汉语-英语和日语-英语的实验表明,该方法提高了短语翻译的准确性和模型译文调序能力,从而在强 NAT 基线系统上获得了更好的翻译质量。此外,我们还表明,更具确定性的细粒度知识可以进一步提高性能。
三、文本理解
1. 基于非自回归序列预测的中文语法纠错
Tail-to-Tail Non-Autoregressive Sequence Prediction for Chinese Grammatical Error Correction
本文由腾讯 AI Lab 独立完成,研究了中文语法纠错(CGEC)问题,并提出了一个名为 Tail-to-Tail 的非自回归序列预测的新框架。考虑到原句大多数词是正确的,可以直接从源头传达给目标层,我们采用基于 BERT 初始化的 Transformer 编码器作为骨架模型。考虑到仅仅依靠替换不能处理可变长度的纠错情况,一个条件随机场层被堆叠在尾部进行非自回归的序列预测。为了缓解类别不平衡问题,focal loss 被整合到损失函数中。此外,我们构建了一个可变长度的语料库来进行实验。在两个数据集上的实验结果,证明了 TtT 在错误检测和纠正任务的有效性。
2. 端到端的语义图的指代消解
End-to-End AMR Coreference Resolution
本文由腾讯 AI Lab 和西湖大学合作完成。尽管用 AMR 作为句子级表示在很多句子级任务展现出正面的效果,很少有工作关注如何用 AMR 表示多个句子(如文档),本文提出第一个端到端的 AMR 指代消解模型用于实现多句级别的 AMR 图的构建,跟之前的 pipeline 方法和基于规则的方法相比,该模型能够更好地缓解错误传播,并且它在本领域和跨领域上都展示了更加鲁棒的效果,在下游的文档摘要任务中发现,该模型产生的文档级 AMR 比其他之前方法产生的文档级 AMR 会得到更好地摘要生成效果。
3. 提升用户参与度:社交媒体推文的投票问题生成
Engage the Public: Poll Question Generation for Social Media Posts
本文由腾讯 AI Lab 与香港理工大学和微软研究院合作完成,研究生成社交媒体帖子的投票问题,可用于收集人们对重要社会话题的态度以及提升交互体验。针对简短、口语化和稀疏的社交文本,我们利用神经主题模型从评论中挖掘潜在的固有主题;然后把主题特征输入到神经网络模型,利用帖子作为输入去生成问题,并且我们还用双解码器拓展了模型架构以便额外输出投票选项(答案)。实验显示我们的模型超越了现有基线模型,并且论证了评论主题信息和双解码器的有效性。人工测评也进一步验证了该方法的优越性,它可以产生高质量的问题并提升用户的参与度。
4. 对话建模中的语义表达
Semantic Representation for Dialogue Modeling
本文由腾讯 AI Lab 和西湖大学合作完成。尽管神经网络模型在对话建模上已经取得了很不错的结果,他们在表示对话核心语义方面依然只表现出有限的能力,比如他们经常会忽略对话中的重要实体。本文尝试抽象语义图(AMR)来帮助对话建模,跟只考虑对话的纯文本特征相比,AMR 能够提供核心的语义知识并显著减少数据稀疏问题。作者开发了一种能根据句子级 AMR 构建对话级 AMR 的算法,并且尝试两种方法将对话级 AMR 融入到对话系统中去,在对话理解和对话回复生成这两个实验上的结果展示了我们方法的优越性,据我们所知,我们是第一个将一种形式语义表示应用到对话建模中的。
5. CLINE:通过对比否定语义样本增强自然语言理解能力
CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding
本文由腾讯 AI Lab 与清华大学合作完成。预训练模型容易受到噪声样本的攻击。而作者实验发现对抗训练对模型识别微小语义变化是无用甚至有害的。针对这一问题,本文提出了反语义对比学习策略(CLINE),通过比较具有相似和相反语义的实例,提升模型识别微小扰动引起的语义变化的能力。实验结果表明,我们的方法在情感分析、推理和阅读理解任务上的效果都有很大的提升。同时,CLINE 还保证了具有相同语义句子表示的紧凑性和不同语义的可分性。
6. 面向对话理解的领域适应预训练方法
Domain-Adaptive Pretraining Methods for Dialogue Understanding
本文由腾讯 AI Lab 和香港城市大学合作完成。现存的一些基于开放域语料的预训练模型,例如 BERT,SpanBERT 等,已经在许多 NLP 任务上取得了不错的效果。本文将探索基于领域适应的预训练方法对于下游任务的有效性。具体包括三种预训练目标,其中包括一种新颖的,主要关注于谓词-论元关系建模的预训练方法。在两个具有挑战性的下游对话理解任务上的评测结果表明,选择合适的预训练目标可以大幅提升下游对话理解任务的性能,并得到当前最优的效果。
7. 从知识图谱到文本生成中的图与文本联合特征学习
JointGT: Graph-Text Joint Representation Learning for Text Generation from Knowledge Graphs
本文由腾讯 AI Lab 和清华大学合作完成。已有的知识图谱到文本生成的预训练模型仅仅在知识图谱到文本生成的数据上微调一个文本到文本的预训练模型,如 BART 和 T5,这样在编码过程中大幅度的忽略了图结构信息、以及图到文本的对齐信息。为了解决这个问题,我们提出了图和文本联合表示学习模型 JointGT。在编码过程中,我们在 Transformer 框架内设计并加入了结构敏感的语义规约模块。与此同时,我们提出三种预训练的任务来显示的捕捉图和文本之间的对齐关系,包括对应的图、文本重建,以及通过 Optimal Transport 来在 embedding 层面让他们对齐。实验显示 JointGT 在几个知识图谱到文本的数据集上取得了最好的性能。
【点击“阅读原文”查看以下三篇论文详细解读】
8. PLOME:一种面向中文拼写纠错融合易错知识的预训练语言模型
PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction
本文由腾讯 AI Lab 独立完成。本文提出了首个联合汉字预测和拼音预测的中文纠错模型 PLOME,基于混淆集的 MASK 策略,该模型可在预训练时学习到纠错相关的知识。另外,我们还显式建模了拼音和笔画序列,让模型能够自动学习任意两个汉字在发音和字形上的相似度。实验表明 PLOME 纠错效果显著优于 SOTA 方法,证明了模型的有效性。本文代码和模型已开源:https://github.com/liushulinle/PLOME
9. 应用于层次文本分类的基于概念的动态路由标签嵌入技术
Concept-Based Label Embedding via Dynamic Routing for Hierarchical Text Classification
本文由腾讯 AI Lab 独立完成。本文探索了 HTC(Hierarchical text classification,分层文本分类)中的概念信息,这是一种在类别层次体系中被共享的领域特异性的细粒度信息。我们提出了一种基于概念的类别标签向量化模型,以提取概念并显式地建模概念的共享机制。在两个广泛使用的公开数据集上的实验结果表明模型的有效性。可视化结果显示了所提出的模型具有较好的可解释性。
10. UniKeyphrae: 一种联合抽取与生成的关键短语预测方法
UniKeyphrase: A Unified Extraction and Generation Framework for Keyphrase Prediction
本文由腾讯 AI Lab 主导,与北京邮电大学合作完成。本文提出了一种新的端到端联合模型 UniKeyphrase,采用预训练语言模型作为 backbone,明确建模了这两个任务之间的相互关系。这为不同类型的 keyphrase 预测带来帮助:present keyphrase 可以为 AKG 提供文档的重要信息,而 absent keyphrase 则被视为高级潜在主题,而这种信息可以为 PKE 任务提供全局语义信息。此外,我们设计了一种词袋约束来联合训练这两个任务,实验表明了所提出模型的有效性。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论