

本次分享内容:
时序数据如何与滴滴实时计算平台产生联系;
当前使用的技术方案;
基于当前技术方案能够达到的效果。
首先了解到该平台的历史使命:作为业务的双眼,能够及时的发现数据的变化,同时拥有配套的报警能力,一旦发现数据的异常能够及时的通知到相关人员。
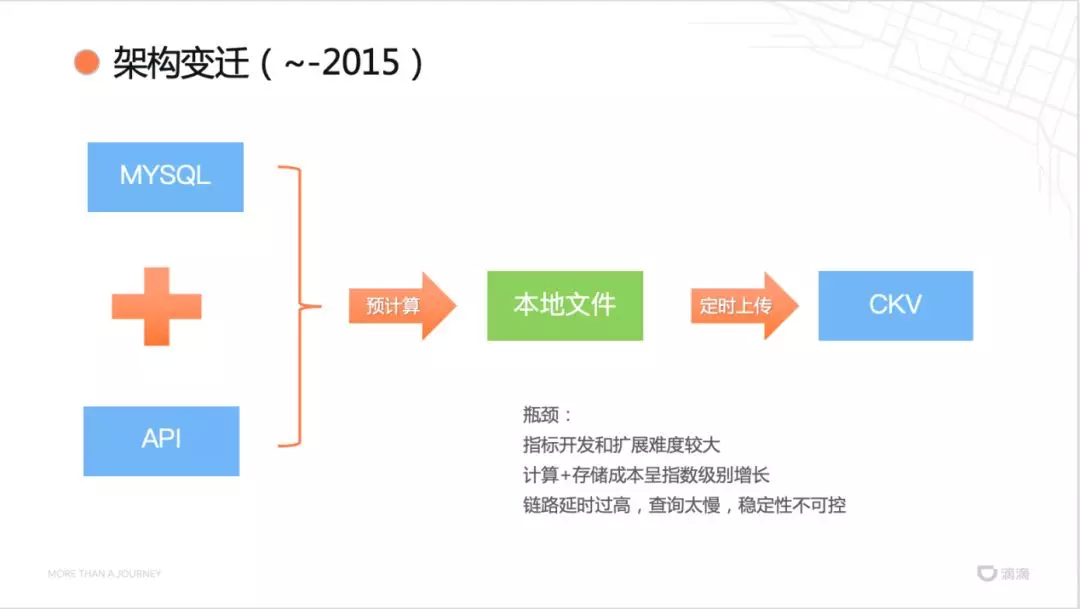
然后看一下该数据平台的技术架构演进历史,初始的架构采用扫描 MySQL 从表加拉取 API 的数据的方式,对数据进行预计算,按照一定规则存储到本地文件(例如:对城市级别进行订单量统计,一级目录为城市 ID,二级目录为日期,保存文件)。将本地文件定期上传到 CKV 数据库,对指标进行查询。
该架构的瓶颈很显然,随着数据增长:
指标开发和扩展难度大,新增和功能扩展指标需要修改的部分涉及很多;
计算和存储成本呈指数增长;
链路延时高,查询慢,稳定性不可控。
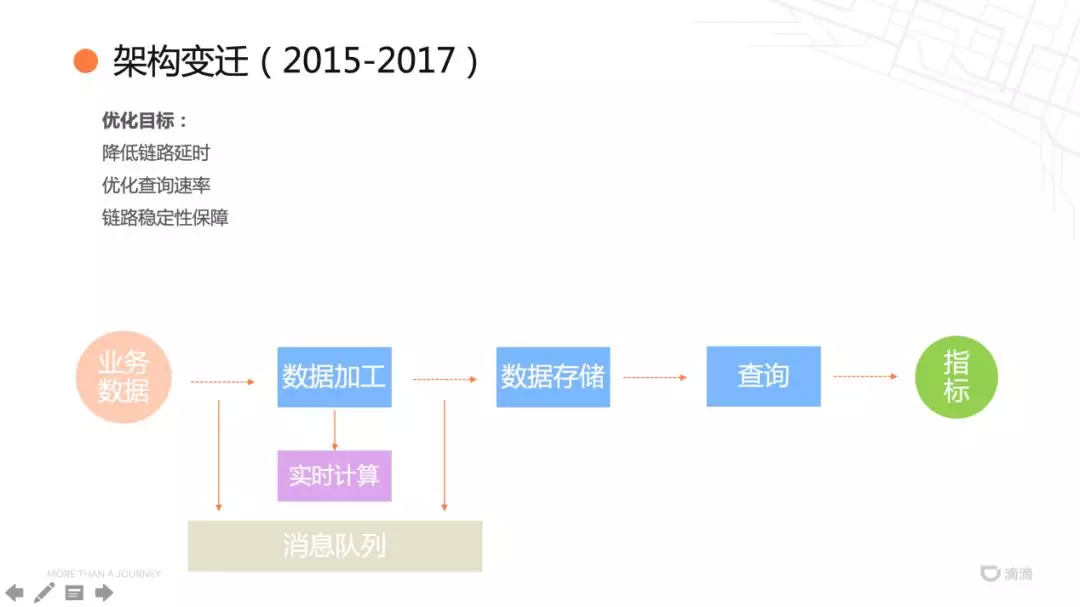
对于实时监控系统需要保证及时性和稳定性,基于这两点对系统进行优化。
首先理清由输入的业务数据到输出的业务指标,中间主要经过了数据加工、数据存储、指标查询的过程。原始的架构,各个部分的连接通过 HTTP 请求的方式,不能保证吞吐量,并且数据可能遗漏。第一步将数据的连接替换为消息队列的方式,提高了吞吐量的同时,利用 MQ 的 ACK 机制保证数据被消费,降低了链路的时延,提高了稳定性。然后,为了使数据加工的能力匹配消息队列的吞吐量,将离线批式的数据加工替换为实时流计算。
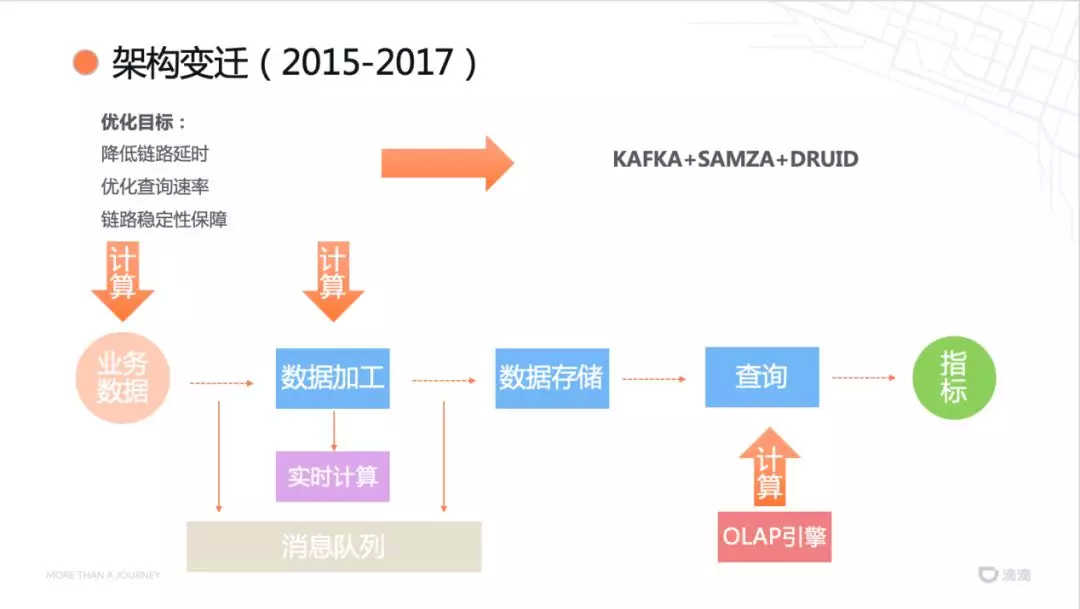
接下来就是考虑到指标的计算,计算可以在业务方进行计算、在数据加工阶段进行预聚合、在查询的阶段得到计算结果。采用了第三种方案(查询时计算)的原因:计算的阶段越靠后,计算前的部分的复用性和性能可以大大提高。例如,实时订单呼叫量、实时订单应答量的统计,如果在数据加工时通过程序处理,一条数据到达需要经过两个实时任务的计算,而且会持续的消耗计算资源。如此,指标的增加,计算资源膨胀严重。而如果实时计算只做简单 ETL 处理后得到订单表,基于此表可以查询多种指标,可以明显提高计算性能,和该表的复用性。
因此对数据库查询的能力有比较高的要求,我们引入了 OLAP 引擎解决。由于业务数据天然的具有时序的特性,采用时序数据库,选取的技术方案为:Kafka+Samza+Druid。
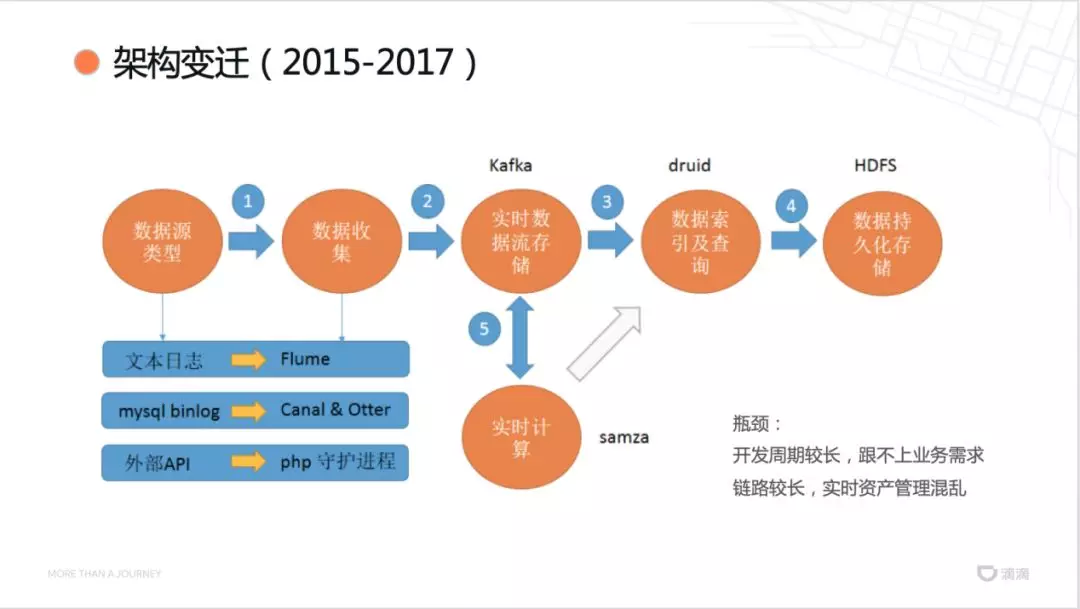
第二阶段的平台架构如上图所示,但是存在以下开发瓶颈:
开发周期比较长,每个需求的实现都需要投入相应的人力;
链路比较长,不同的模块有不同人员负责,管理比较混乱。
因此考虑到将平台的能力开放出来,让所有人都可以参与到实时数据的加工和报表的产出。
考虑到 Druid、实时计算引擎、开发语言等不是所有人都了解,需要一定的学习成本。而且大部分人参与进来,对资产管理提出了新的挑战。从而提出了滴滴实时计算开发平台(Woater)。主要目标:降低开发难度和资产管理模式的优化,得到当前的技术方案如下:
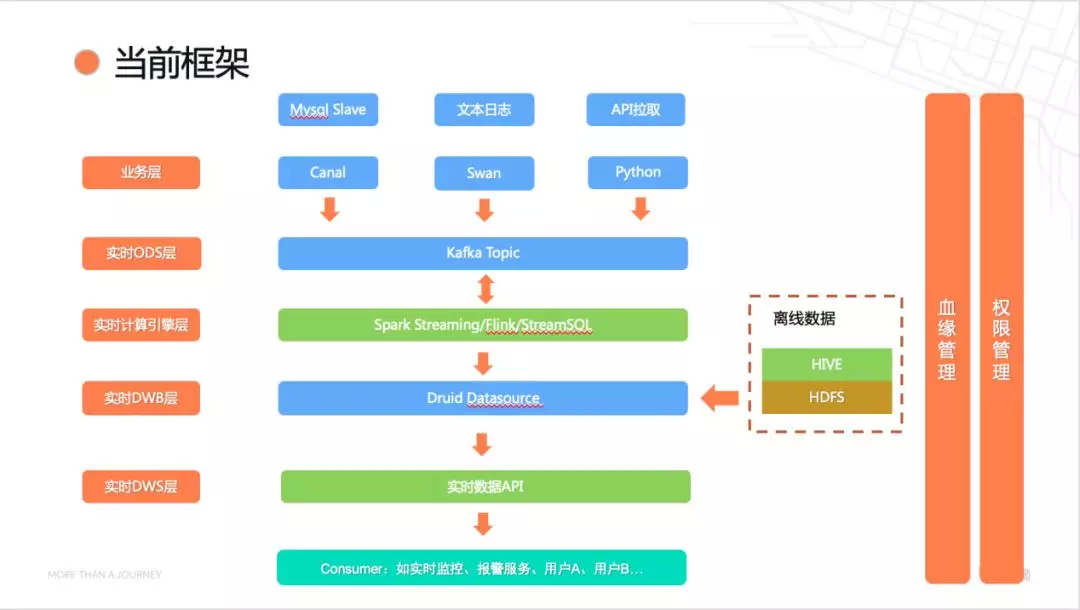
数据通过多种方式接入到 Kafka,通过 Spark streaming 或 Flink 处理后写入 Druid。考虑到 Kafka 对消息保存的生命周期,添加了对 Druid 数据进行一些离线的处理(Hive+Druid),保留历史数据的信息。数据落地存储后,通过统一的实时数据 API 对第三方开放(开通权限后可用)。
在主线功能之外,提供了两个支线功能:权限管理和血缘管理。权限可以管理到模块粒度上的开放和使用,通过血缘可以清晰的看到数据的流动路径,查找数据的上下游信息。
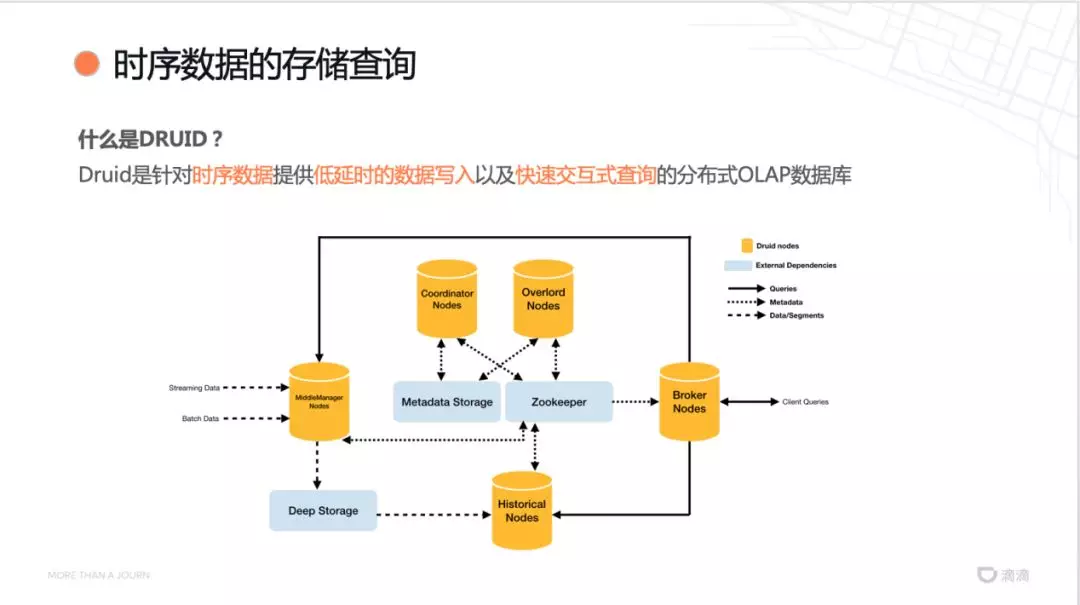
什么是 Druid?Druid 是针对时序数据提供低延迟的数据写入以及快速交互式查询的分布式 OLAP 数据库。核心思想是:Druid 的数据会按时间写入不同的分片,一次查询会拆分为多个子查询,并汇总结果后返回。

为什么选择 Druid?Druid 对时序数据做了一些优化,所有的数据包括三个部分:时间戳(Timestamp)、维度(Dimensions)、指标(Metrics),使用列存储,针对每一列的数据能够提供很高的压缩比。
以上图的维度列 Page 为例,实际存储的不是真实字符串,会先解析列值生成映射表:{“Justin bieber”:0,“Ke$ha”:1},实际存储 [0,0,1,1],代表了 [“Justin bieber”, “Justin bieber”, “Keha”, “Keha”],节省存储空间,提高压缩比。同时会维护一个倒排索引,如 “Justin bieber”=[1,1,0,0],代表了第一、二行是该值,第三、四行不是该值。当多个列组合查询时,可以通过位的与、或运算,得到结果行的集合。

Druid 其他的优化点如上图所示,除了前面提到的列式存储的优势,还有 Rollup 预聚合存储机制和 Bitmap 索引压缩优化,按照时间对数据进行分片,能够加速查询,达到数据实时可查询的效果,亚秒级查询(集群规模:700+数据源,日查询 2000 千万),数据压缩至原始的 1/30。
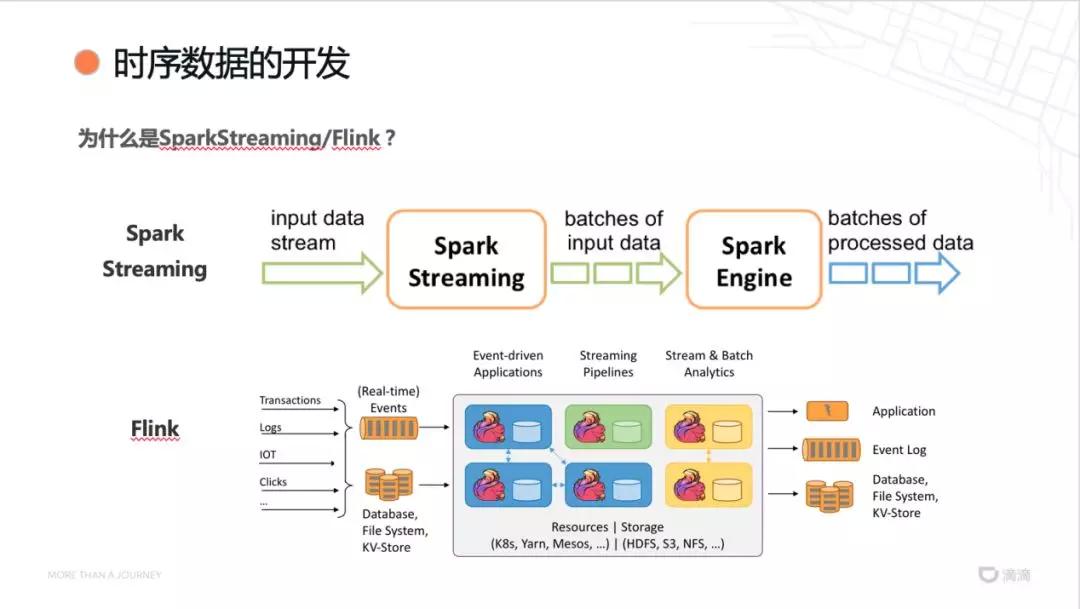
Druid 在查询方面表现很好,但是计算能力偏弱,例如两表 Join 查询的场景支持不够。因此计算的能力由 Spark streaming 和 Flink 来提供。
Spark streaming 基于 Spark 发展而来,将实时流数据拆分为微批数据进行处理。适用于有 Spark 经验的开发人员,对实时要求不高的场景。
Flink 是纯流式处理,每接收到一条数据,就立即计算。同时提供了 Exactly-once 的语义。可以使用于延时要求高的场景。
为什么同时用?适用于不同场景和不同的开发人员,所以两种都支持。
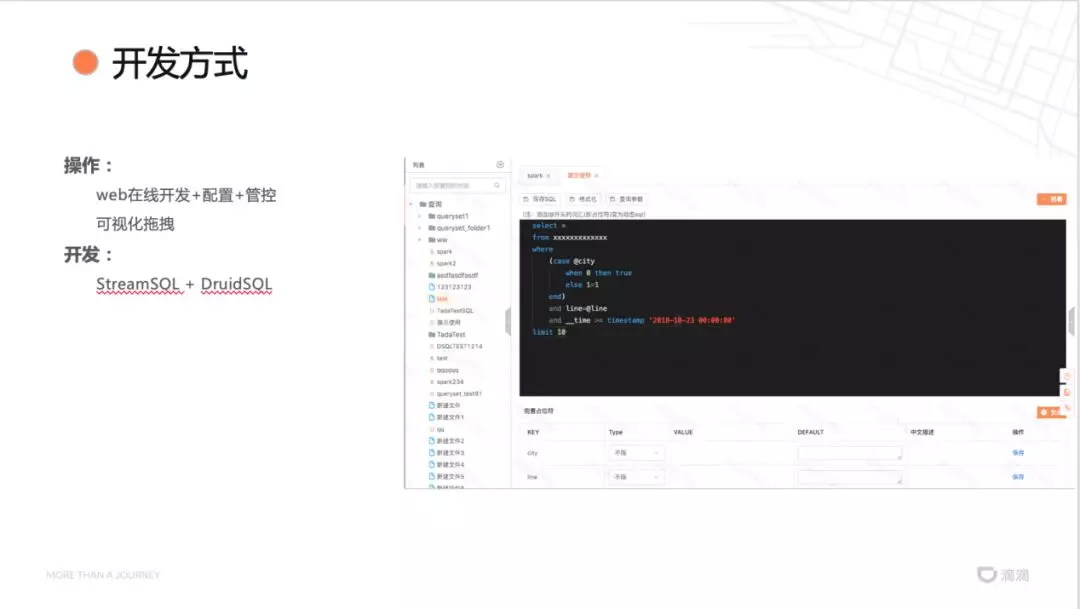
总结该平台开发的开发方式提供了:
Web 在线开发,适用于有一定开发经验的人员;
StreamSQL+DruidSQL,适用于有一定 SQL 能力的开发人员;
可视化拖拽适用于初级用户。
同时,还提供了配置和资源管控的能力。
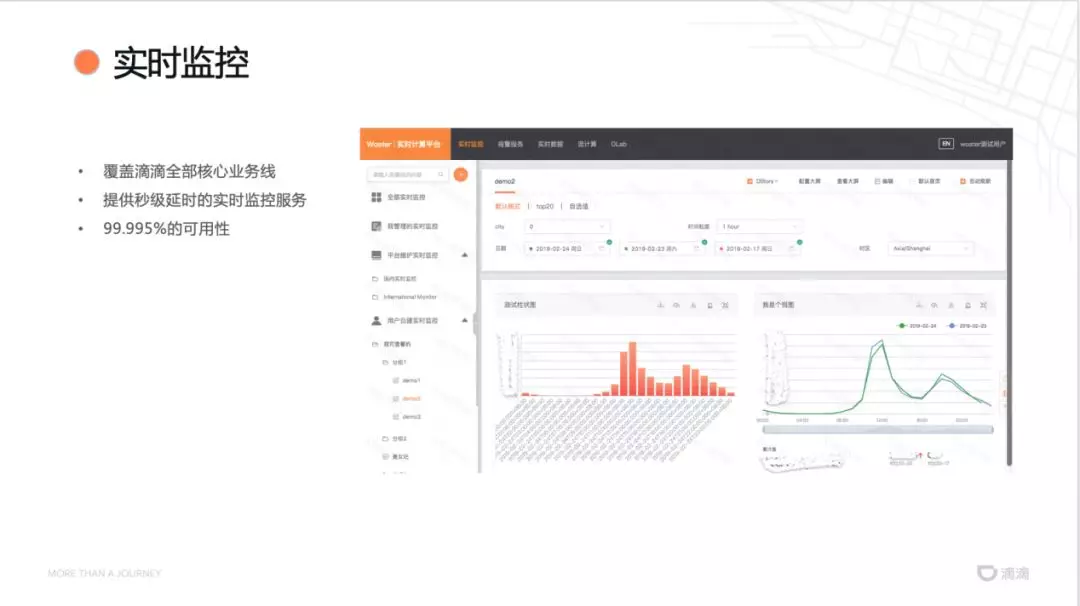
目前该平台的现状:
平台覆盖了滴滴全部核心业务线,提供秒级延时的实时监控服务,达到 99.995%的可用性。
SLA 以业务是否发生了真正的问题来评价报警质量。报警服务在准确性上达到了一个月不超过 3 次误报和 1 次漏报,在 1 分钟内能够及时的响应。
其他功能如:大中小屏一体化解决方案,更丰富的图表和配置功能。
作者介绍:
张婷婷,滴滴高级研发工程师,参与并负责了滴滴实时数据开发平台的从 0 到 1 的建设工作,对实时数据计算领域有丰富经验。
本文来自 张婷婷 在 DataFun 社区的演讲,由 DataFun 编辑整理。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论