

1 引言
随着贝壳找房的快速发展,QueryEngine 的 Adhoc 查询需求越来越多,每次请求的数据量也越来越大,QueryEngine 的查询压力越来越大,查询分析的速度随之也慢了。与此同时,由于频繁的从 HDFS 中获取数据,也对大数据集群造成了一定的网络与磁盘 IO 的压力。为了提升 QueryEngine 的分析查询效率,同时减轻 HDFS 集群及网络的 IO 压力,我们引入了智能缓存加速系统 Alluxio 作为 QueryEngine 与大数据集群的缓存中间件。通过暂时将数据存储在内存或其它接近计算服务所属介质中的方法, 起到加速访问并提供远程存储本地化提升性能的能力。本文重要分享 alluxio 在 QueryEngine 的主要底层引擎之一 Spark SQL 中分析加速的应用实践。
2 介绍
2.1 alluxio 是什么
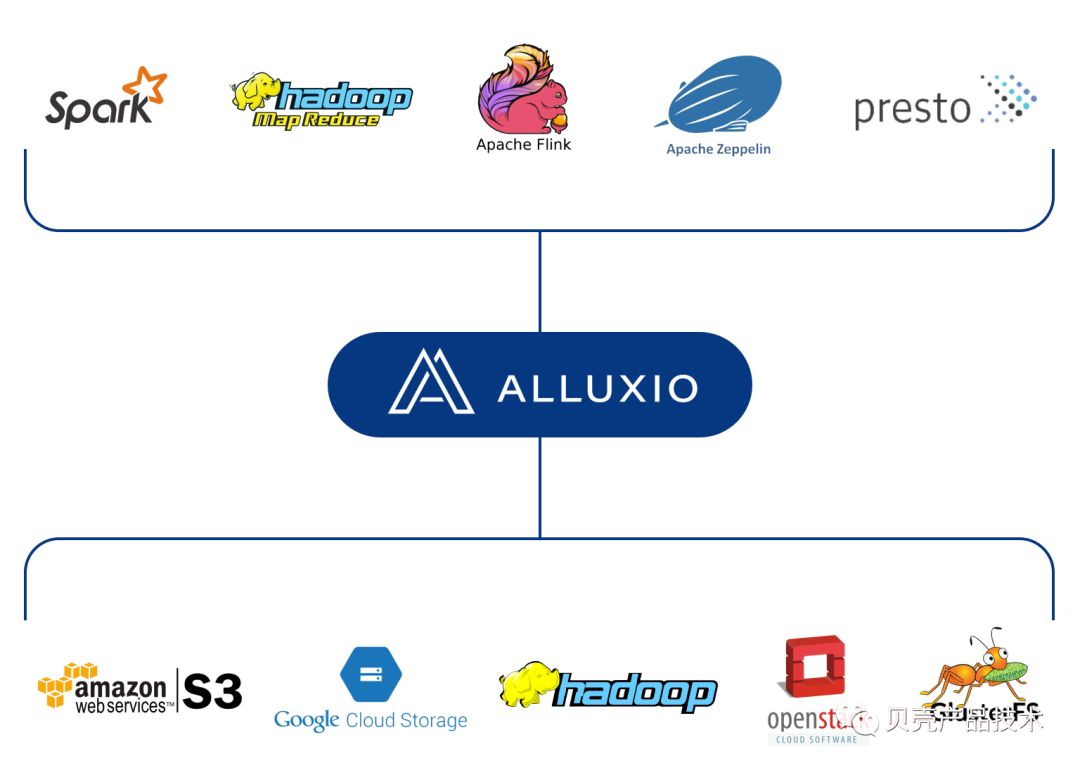
Alluxio(之前名为 Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。应用只需要连接 Alluxio 即可访问存储在底层任意存储系统中的数据。此外,Alluxio 的以内存为中心的架构使得数据的访问速度能比现有常规方案快几个数量级。在大数据生态系统中,Alluxio 介于计算框架(如 Apache Spark,Apache MapReduce,Apache HBase,Apache Hive,Apache Flink)和现有的存储系统(如 Amazon S3,OpenStack Swift,GlusterFS,HDFS,MaprFS,Ceph,NFS,OSS)之间。Alluxio 为大数据软件栈带来了显著的性能提升。Alluxio 与 Hadoop 是兼容的。现有的数据分析应用,如 Spark 和 MapReduce 程序,可以不修改代码直接在 Alluxio 上运行。如图,为 alluxio 在大数据生态中的地位。
2.2 alluxio 特性
1)层次化存储
通过分层存储,Alluxio 不仅可以管理内存,也可以管理 SSD 和 HDD,能够让更大的数据集存储在 Alluxio 上。数据在不同层之间自动被管理,保证热数据在更快的存储层上。自定义策 略可以方便地加入 Alluxio,而且 pin 的概念允许用户直接控制数据的存放位置。
2)灵活的文件 API
Alluxio 的本地 API 类似于 java.io.File 类,提供了 InputStream 和 OutputStream 的接口和对内存映射 I/O 的高效支持。我们推荐使用这套 API 以获得 Alluxio 的最好性能。 另外,Alluxio 提供兼容 Hadoop 的文件系统接口,Hadoop MapReduce 和 Spark 可以使用 Alluxio 代替 HDFS.
3)统一命名空间
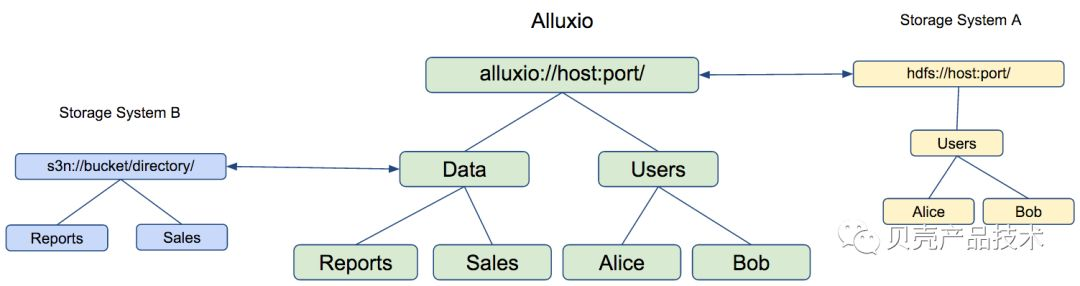
Alluxio 通过挂载功能在不同的存储系统之间实 现高效的数据管理。并且,透明命名在持久化这些对象到底层存储系统时可以保留这些对象的文件名和目录层次结构。如图所示,Alluxio 可以支持目前几乎所有的主流分布式存储系统,可以通过简单配置或者 Mount 的形式将 HDFS、S3 等挂载到 Alluxio 的一个路径下。这样我们就可以统一的通过 Alluxio 提供的 Schema 来访问不同存储系统的数据,极大的方便了客户端程序开发。
4)数据共享
不同应用程序,不同框架的数据,可以通过 alluxio 内存文件系统进行高速共享。比如,不同 spark 程序之间的中间结果可以通过简单的存储到 alluxio 达到共享的目的,而且不影响程序的性能。
5)高效的读写性能
对于热点数据,alluxio 可以提供达到内存级别高效的读写性能,对于关键业务能够起到很好的加速作用。
6)可插拔,容错
在容错方面,Alluxio 备份内存数据到底层存储系统。Alluxio 提供了通用接口以简化插入 不同的底层存储系统。
7)读写分离,加速
随着大数据的发展,读写分离的架构越来越普遍,但是读写分离有一个问题就是会影响程序的读写性能。alluxio 在这种读写分离的场景下,具有很好的适用性。可以做到一次读取,多次使用,最大限度的提升。
3 实践
3.1 为什么使用 Alluxio
QueryEngine 底层目前使用三种查询引擎:MR、Tez 和 Spark SQL,根据用户的选择及查询的代价来智能的选择执行引擎。为了降低对 Spark SQL 的影响,Spark SQL 引擎使用的是独有的 Yarn 集群。原始架构有如下问题:
1)数据量大,而且请求量变大,查询性能变差;
2)Spark SQL 计算与存储分离,每次查询都需要远程加载数据,数据本地行查,性能差;
3)目前的分析基本都是 T+1 的数据,数据基本不变,每次查询都要远程拉取数据,对大数据存储集群和网络 IO 压力很大;
4)对相同的数据会有多次的访问查询。
基于上面 Alluxio 的特性分析,alluxio 非常适合我们的业务场景,可以用于加速 QueryEngine 的查询分析。
3.2 性能评估
1)测试环境
硬件环境:
3 台服务器(48 核 cpu 128G 内存 5.4T HDD(11 块) 3T SSD 千兆网卡)
软件环境
Hadoop-2.7.3
Alluxio-1.7.1
Spark-2.3.0
2)测试数据量
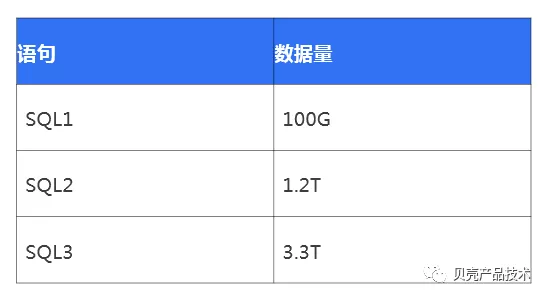
Alluxio 支持分层存储,包括内存,SSD 和磁盘,Alluxio 自身提供了 LRU、LFU 等高效的替换策略,能够保证热数据位于速度较快的内存层中,提高了数据访问速率。为了测试 Alluxio 不同场景下,不同数据量,出现数据置换和非置换,冷读与缓存读等的加速效果。本测试选取了 3 种大小数据量,如表所示:
3)测试场景
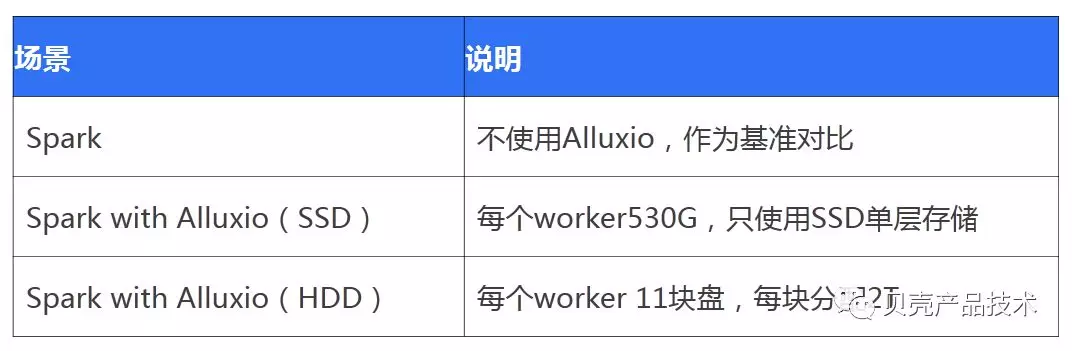
为了测试 Alluxio 的冷读效率和缓存效率,每个场景的不同数据量均进行二次测试
4)测试结果
测试结果如下图所示:
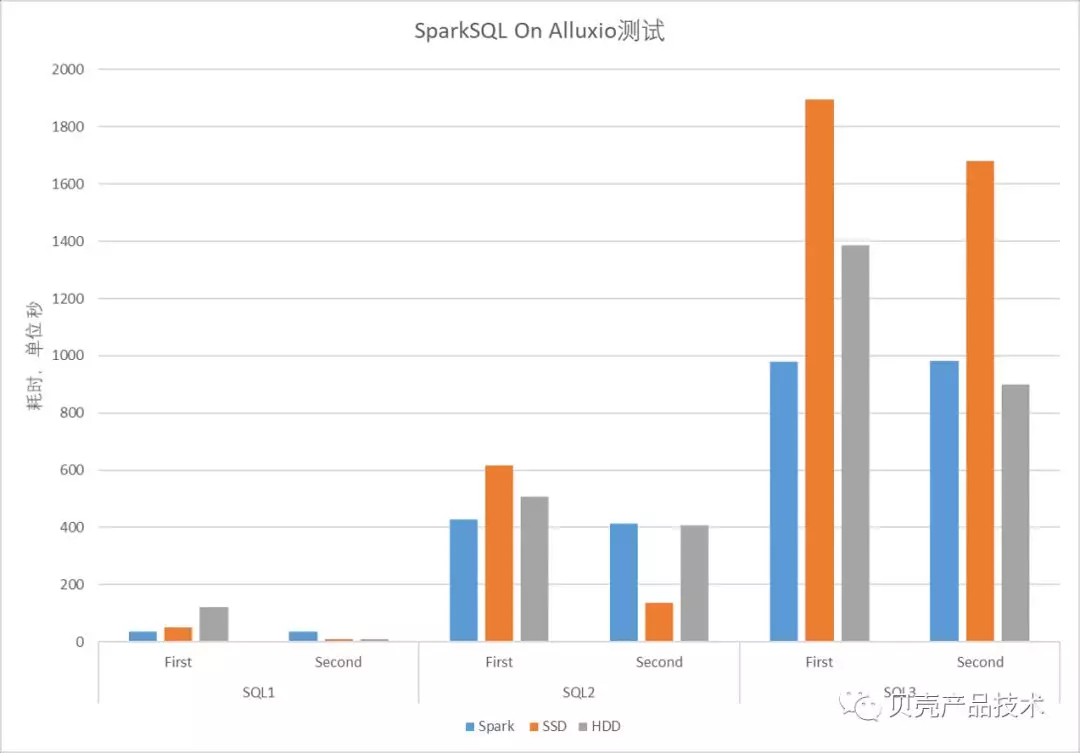
从测试中可以看出:
根据测试结果(三种 SQL 数据量的 First 场景,即冷读)可以看出,冷读的情况下,使用 Alluxio 的时候效率不如不使用 Alluxio。因此,生产部署时需要提前加载需要加速缓存的数据。
在 SQL2 和 SQL3 数据量下,Spark 和 SSD 场景对比可以看出:Alluxio 的淘汰置换效率很低。因此在生产部署需要做好数据量规划,尽量防止数据淘汰置换的发生。测试中还发现,数据会出现一定的膨胀(passive cache 引起的多副本),数据量规划规划的时候需要考虑这个因素。
SSD 场景下,在没有发生淘汰置换的时候,Alluxio 加速效果比较明显,有 2~5 倍的速度提升。
HDD 的场景下,对于查询加速还是有一定的效果。根据和同行的交流,Alluxio Worker 的数量越多,Alluxio On HDD 的加速效果会更加明显。
4 落地
通过测试,我们发现单层存储效率最高。为了尽可能的避免数据置换,生产中我们采用单层 SSD 存储架构,RAM 资源交给 linux 系统自己缓存。
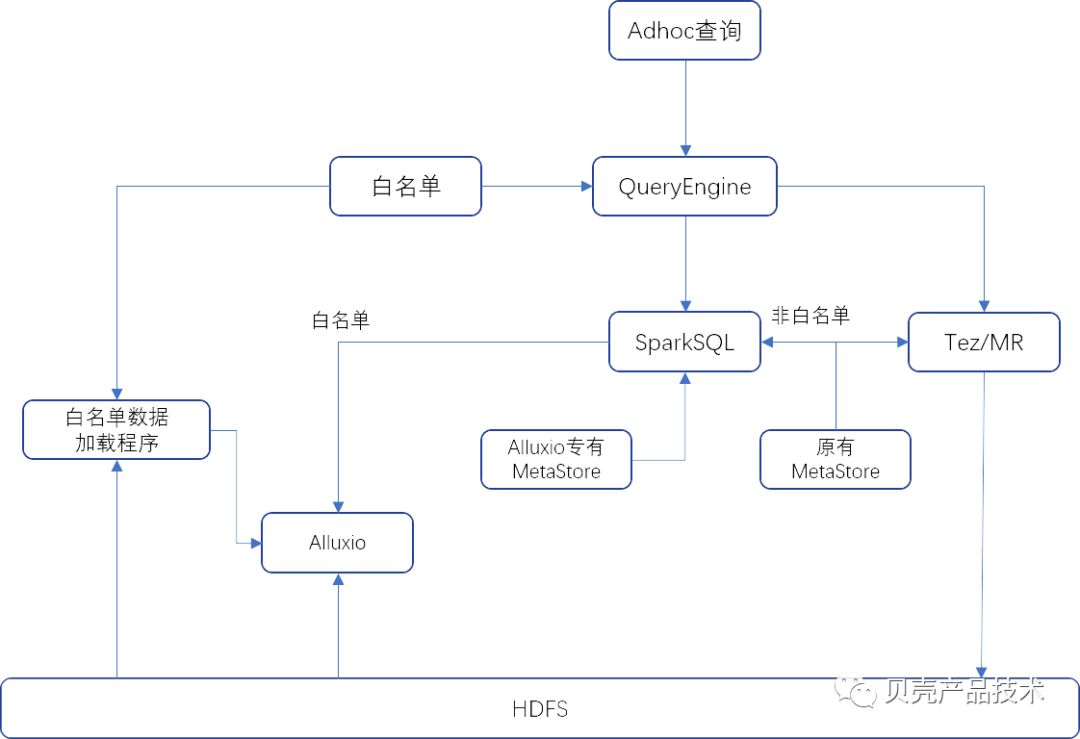
考虑到成本问题,SSD 的存储有限,而 adhoc 查询的数据量却非常庞大,高达数百 TB。因此我们基于过去 30 天内的 adhoc 查询记录,分析出表的访问频率和分区范围以及表的大小等三个维度的信息,只对中小表、高频访问的热表以及每个表的高频分区进行 Alluxio 缓存加速,针对进入 Spark SQL 的非白名单查询,则访问 HDFS 中的数据。
针对 Spark SQL 的查询,我们使用的是 Spark ThriftServer。为了使进入白名单的数据查询 Alluxio 中的数据,而不是 HDFS 中的数据,我们修改了 HiveMetaStore 的相关源码,使数据地址指向 alluxio 中的数据地址,而非 HDFS 中数据的地址。这样进入白名单表的查询,使用修改源码的 HiveMetaStore,而非白名单表的查询使用原始的 HiveMetaStore,从 HDFS 读取数据。
考虑到 Alluxio 冷读较直接访问 HDFS 有性能损失,因此我们每天都会定期提前加载新白名单中的数据,缓存到 Alluxio 中,并且淘汰旧的不需要的分区中的数据。
使用中我们发现,使用 Alluxio 官方提供 AlluxioFileSystem 的加载数据的方式非常缓慢。经查看代码,加载数据的这部分逻辑使用单线程去实现。为了提高数据缓存的效率,我们使用 Spark 程序并行的去缓存数据,大大提高了数据缓存的效率。
使用过程中,我们还发现了一个问题,就是 Alluxio 和 HDFS 中数据的同步问题。刚开始我们以为数据都是 T+1 的,基本上不会涉及到更新的问题,所以为了更好的性能,我们将 alluxio.user.file.metadata.sync.interval 设置为了 1 天,禁止了 alluxio 和 hdfs 的元数据的自动同步。但是有些情况,业务方会发现数据有问题,然后会重新初始化相关的数据到 HDFS 中,这样就导致了 Alluxio 中的数据使旧的数据,无法得到更新。
为了满足业务方的这方面的需求,我们将 alluxio.user.file.metadata.sync.interval 设置为了一个小时。
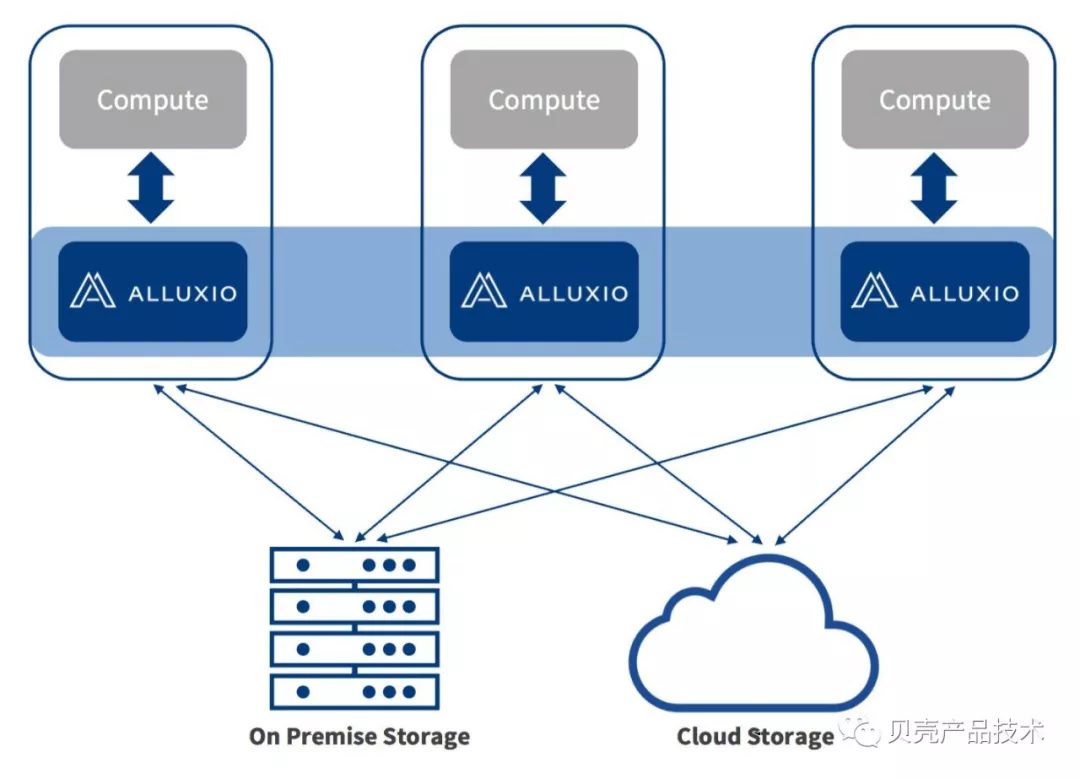
引入 Alluxio 内存加速以后的架构如下图所示:
5luxio 其他场景
1)加速贝壳的机器学习、深度学习场景的迭代计算;
2)多种数据框架,应用之间的数据共享;
3)优化 spark 程序的 shuffle 或者 jvm 内存压力;
4)不同文件系统的统一整合。
6 总结
Alluxio 作为一款优秀的内存文件系统,还有很多场景可以挖掘使用。
作者介绍:
尤达(企业代号名),贝壳找房大数据团队工程师,目前主要负责数据集成、分析及大数据应用拓展。
本文转载自公众号贝壳产品技术(ID:gh_9afeb423f390)。
原文链接:
https://mp.weixin.qq.com/s/h7Kxmr4zCsD_xA5uSfJFIQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论