

重新认识可观测性
管理学大师彼得德鲁克有一句话:“如果你无法衡量它,你就无法管理它”。在企业中,无论是管理人,还是管理事,抑或是管理系统,首先都需要衡量。衡量的过程其实是搜集信息的过程,有了足够的信息才能做出正确的判断,有了正确的判断才能做出有效的管理和行动方案。
下面我用一个简单模型来说明我对可观测性的理解:
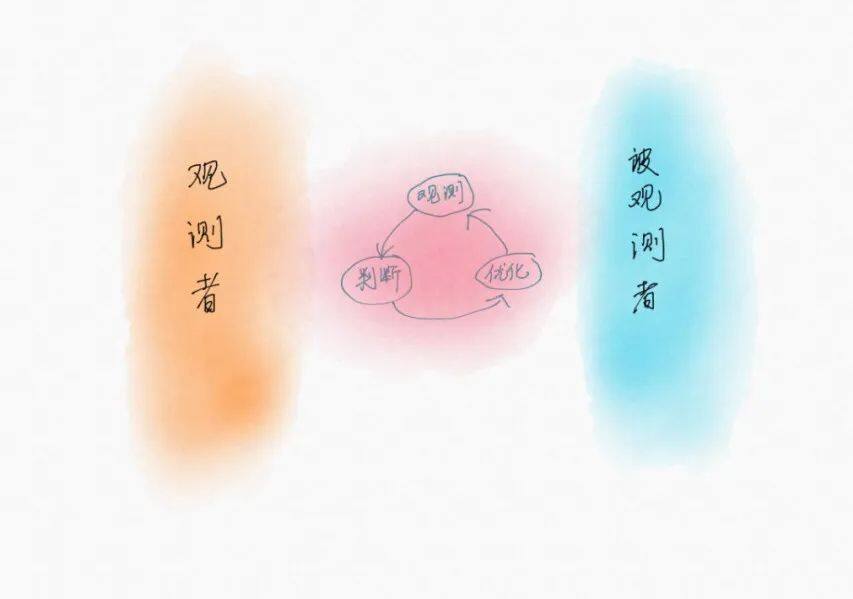
可观测性描述的就是“观测-判断-优化-再观测”这个闭环的连续性、高效性。如果只有观测而无法基于观测做出判断,则不能称其具备可观测性。如果只有经验判断而没有数据支撑,也不能称其具备可观测性,这样会导致组织高度依赖个人能力而带来管理风险。如果优化之后无法反馈到观测上,或者因优化引入新的技术而导致无法观测,则其可观测性不可持续。如果在观测、判断、优化的闭环中需要付出很高的成本和承担很大风险,则其可观测性的价值为负。
所以,当我们在谈可观测性的时候,其实更多考虑的是观测者、管理者的感受,也就是说在我们遇到问题的时候,能否轻而易举地在观测平台找到答案,没有阻力也没有困惑,这就是可观测性。随着企业的发展,组织架构(角色、观测者)和管理对象(系统、被观测者)都会随之发展变化,当使用了一堆传统的观测工具,却仍然无法满足观测者、管理者新的需求的时候,我们不禁要问:“可观测性何在?”。
“可观测”不等于“可观测性”
下面,我们来看一下我们习以为常的观测方式。
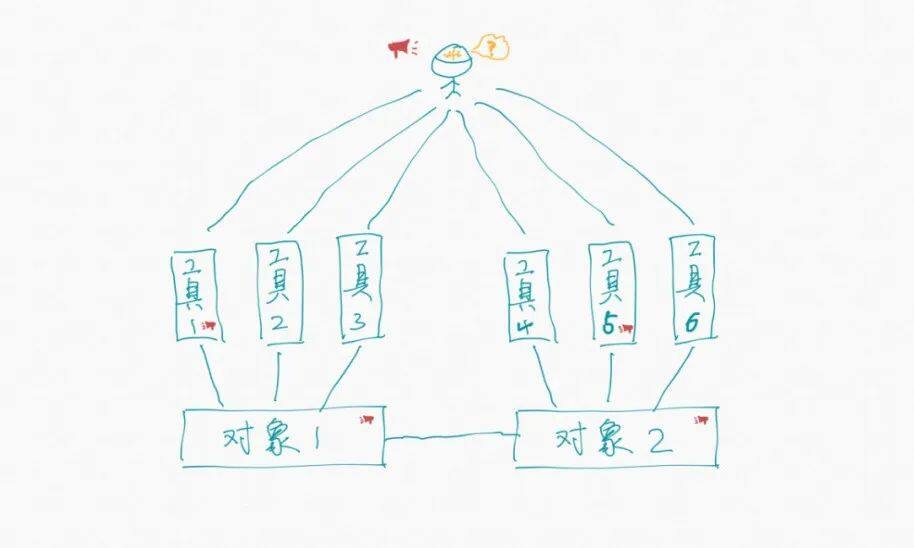
通常我们会基于自己想要的数据去搭建观测工具。当我们想了解掌握基础设施的健康状况的时候,我们会很自然的想到搭建一个仪表盘,实时监测各项指标。当我们想了解业务是如何出问题的,我们会很自然的想到搭建一个日志平台,随时过滤排查业务日志。当我们想了解事务为什么高延迟,我们会很自然的想到搭建一个链路监测平台,查询拓扑依赖和各节点的响应时间。这种模式很好,帮助我们解决了很多问题,以至于我们从不怀疑可观测性,我们信心满满。偶尔遇到大难题,把我们的仪表盘、日志平台、链路平台打开,所有的数据都在这里,我们坚信一定能找到问题的根因。即使花费了很长时间,我们也只是告诉自己要多学习,多了解掌握自己负责的系统,下一次我一定能更快找到根因。是的,当我们想要的数据都摆在面前的时候,我们还有什么理由怪罪观测工具。
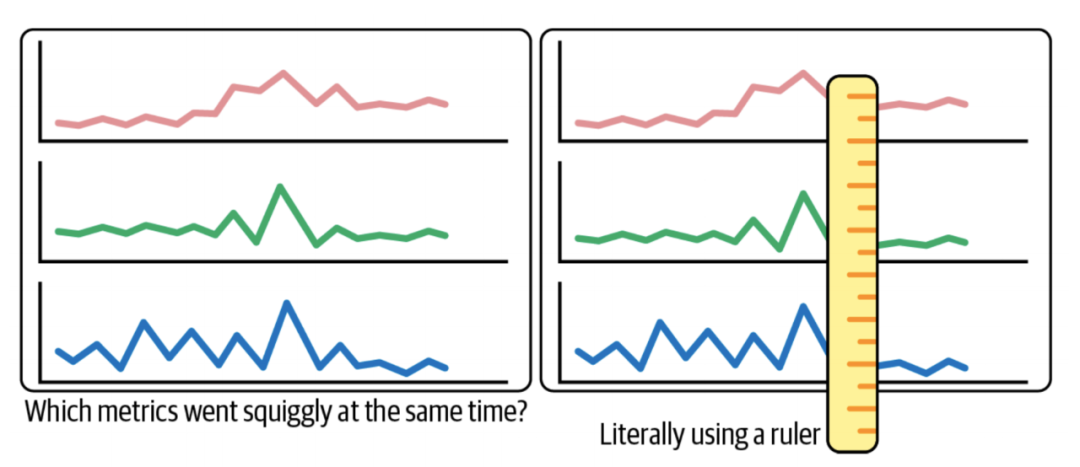
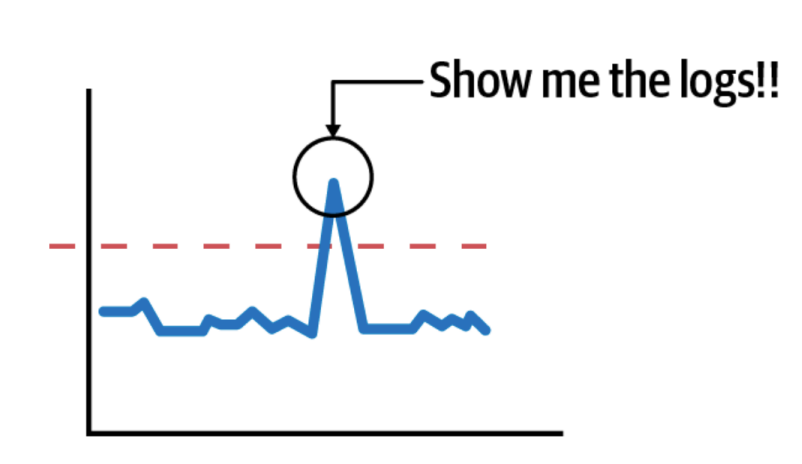
我们会不辞劳苦地在各种指标数据中寻找可能的关联性,得到关键线索后,我们会在大脑中构造出一堆复杂的日志查询条件来验证自己的猜想。就这样比对、猜想、验证,同时还要在各种工具中切换,不可否认很充实。

传统的系统相对简单,上述方式行之有效。现代 IT 系统的关键词是分布式、池化、大数据、零信任、弹性、容错、云原生等,越来越庞大,越来越精细,越来越动态,同时也越来越复杂。通过人去寻找各种信息的关联性,再根据经验判断和优化,显然是不可行的,耗时耗力还无法找到问题根因。
传统的工具是垂直向的,引入一个新的组件的同时也会引入一个与之对应的观测工具,这样是保证了数据的全面性,但丢失了数据的关联性和分析排查的连贯性(换句话说,我们方方面面都监控到了,但遇到问题,还是不能很好地发现和定位)。此时我们很自然的想到做一个统一的数据平台,想象中把所有数据放在一个平台就能解决关联性的问题,但往往实际情况是我们只是把数据堆在一个地方,用的时候还是按传统的方式各看各的。我们只是把无数根柱子(工具),融合成了三根柱子:一个观测指标、日志、链路的统一平台,数据统一了,但关联性还得靠人的知识和经验。
这里边最关键的其实是解决数据关联的问题,把之前需要人去比对、过滤的事交给程序去处理,程序最擅长此类事同时也最可靠,人的时间更多的用在判断和决策上。这在复杂系统中,节省的时间会被放大很多倍,就这点小事就是可观测性看得见的未来。
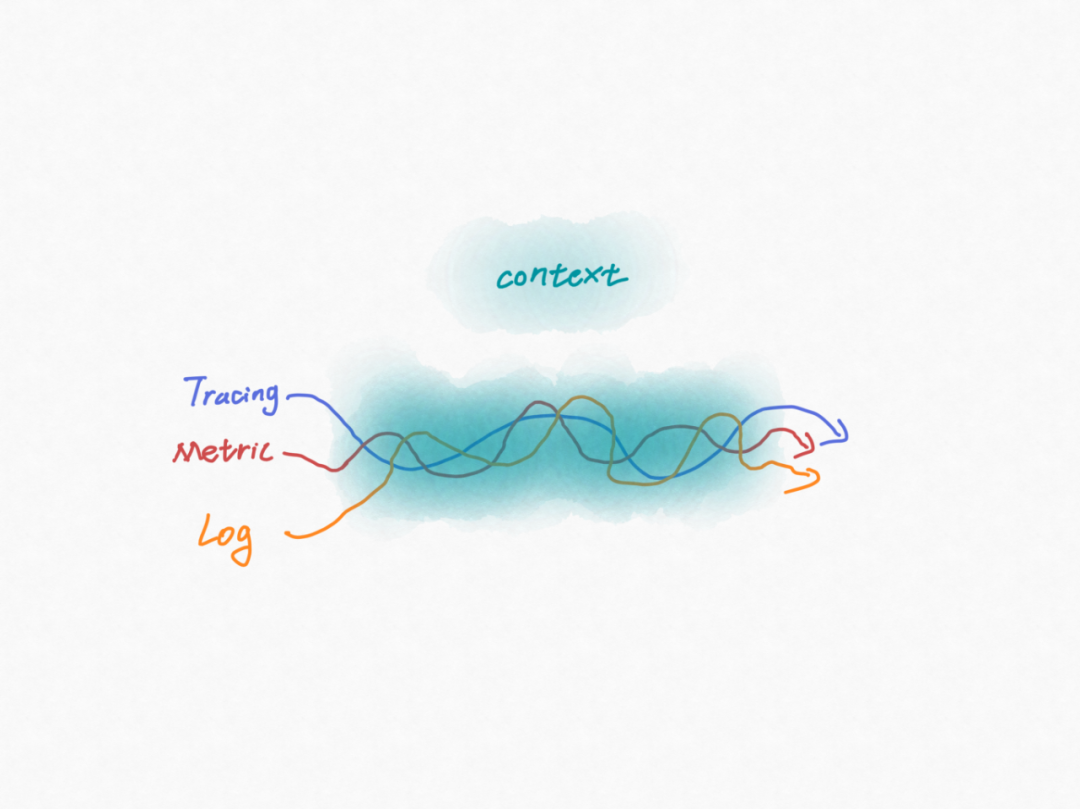
那么,如何做数据关联呢?说起来很容易,那就是做时间+空间的关联。在我们的统一数据平台上,由于数据是来自于各种观测工具的,虽然我们在数据格式上统一成了 metric、log、trace,但不同工具的 metric、log、trace 的元数据截然不同,而如果我们在这个统一数据平台上去梳理和映射这些元数据的话,这将是庞杂、难维护、不可持续的。那该如何做呢?答案就是标准化。只有将标准化、结构化的数据喂给观测平台,观测平台才能从中发现巨大价值。统一数据平台只是在数据格式上进行了标准化,而要想将 trace、metric、log 关联还必须建立 context 的标准化,context 就是数据的空间信息,再叠加上时间信息的关联就可以发挥真正的观测价值。
Opentelemetry 做了什么?
Opentelemetry(以下简称:OTel)就是解决数据标准化问题的一个项目,OTel 由以下几部分组成:
跨语言的标准规范(Specification):定义了数据、上下文、API、概念术语等的规范。这是 OTel 的核心,它使得所有观测数据有机地统一起来,这样观测平台才能自动比对、自动过滤,同时也为 AI 提供了高质量的数据。
接收、处理、输出观测数据的工具(Collector):一个用于接收 OTel 观测数据的工具,并支持通过配置 pipeline 对观测数据进行处理,输出给指定的后端。
各种语言的 SDK(SDK):基于 OTel 标准的 API 实现的各种语言的 SDK,用来支持自定义开发观测数据采集器。
采集器(Instrumentation):开箱即用的观测数据采集器。
OTel 是开源项目,所有内容都可以在 Github 找到,下面我介绍几个关键的概念:
属性
从数据的角度看属性是一个键值对,本质上属性描述了空间信息,方便从空间上做数据关联。OTel 定义了很多通用的属性,如果定义不明确或数据不一致时,是没法自动关联分析的。下面是 Otel 定义的 K8S 的 Pod 属性:

资源
从数据的角度看资源是一个键值对集合,本质上资源描述的是观测对象。相同观测对象的 Metric、log、trace 都有相同的资源数据(或称:相同上下文),这样就可以自动发现相关性。
事件
从数据的角度看事件是一个时间戳和一组属性组成的,用来描述某个时间发生了某件事。本质上事件是一个时间+空间的组合。
指标
从数据的角度看指标是事件的聚合,在一个活跃的系统中,相同的事件会不断发生,指标提供了一个跨时间和空间的总览。沉浸在细节不一定有见解,跳出来,从更高的维度鸟瞰可能寻找到灵感。
跨度
从数据的角度看跨度由:操作名称、开始时间、持续时间、一组属性组成。跨度(又称:span)描述的是一个过程,如果说事件是在一个时间点构建了时间和空间的相关性,那么跨度就是在一个时间段上构建了时间和空间的相关性。
信号
信号是对标准遥测数据的抽象,相同数据模型的数据被归为一个信号。如:一个 Metric 是一个信号,所有 Metric 都具有统一标准的数据模型。一个 Trace 是一个信号,所有 Trace 都具有统一标准的数据模型。信号有一个重要的特性就是供应商无关,任何可观测系统供应商要支持 OTel,都必须要按 OTel 的信号模型收集、上报、处理数据,这是保障高效数据关联的关键。
上下文
所有信号都基于相同的上下文,如:在同一个服务中采集的 Metric、log、trace 具有相同的上下文(如:service.id 和 service.name)。这其实就是在空间上建立的数据的关联。
敬畏工程
OTel 在数据层面提供了标准规范和许多拿来即用的工具,大大方便了构建可观测平台,但是真正落地去构建适合自己的、全面可扩展的、稳定可靠的、低成本高效益的可观测平台是一个大工程,不是简单引入就可以的。这其中涉及到大数据引擎、高基数分析引擎、关系引擎、AI 引擎等系统难题。此外,如何设计一个简单、高效、准确、协同、专业的平台也不是一蹴而就的,需要懂数据也要懂技术还要懂设计。
我把可观测平台分以下层次:
数据展示+人工关联比对+人工判断:大多数传统观测平台在这一层。
信息关联展示+人工判断:部分观测平台通过梳理映射可以做一些相关性展示,减少人工发现的时间成本。
信息判断 x 人工判断:极少部分观测平台做了数据的高度标准化,可以根据相关性给出见解和建议。
信息判断+行动:没有观测工具能只依靠工具做判断。
博睿数据在数据采集层有十多年的技术积累,探针稳定可靠,部署简单。在数据处理方面也经受住了大业务量的客户考验,技术上不断创新形成了极具优势的架构。在数据标准化、结构化设计方面也形成了自己的体系。可以说我们刚跨越了第 2 层来到第 3 层,我们将从观测广度和深度两个方面丰富标准化的数据,基于此同时不断深化数据相关性,加上我们自研的 SwiftAI 中台赋能,未来将给出更多更精准的信息判断,帮助客户快速落地高效可持续的观测--判断--优化闭环。
作者介绍:
刘亚辉,博睿数据产品经理。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论