

作者|吴迪、孙丽川、郭帅
机器学习和深度学习技术在很多领域扮演着越来越重要的角色,以资金适配领域来说,它们在成本节约、推荐排序、收入机会和风险监控等方面可以带来明显的好处。但目前,机器学习和深度学习技术在资金适配方面的应用和探索仍缺乏一些经验。因此,消费分期产品“好分期”团队编写此文进行实践记录,同时也希望大家能提供一些宝贵意见。
业务流程简介
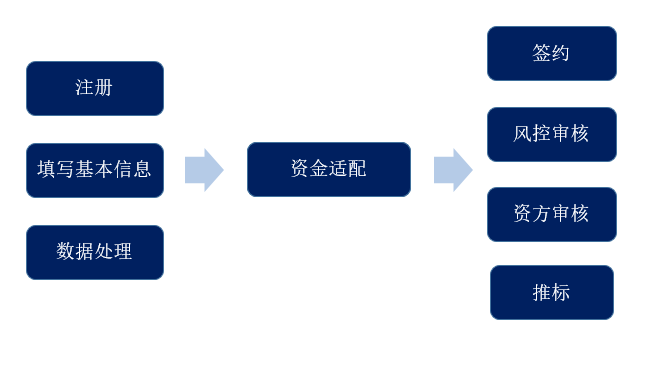
以下是好分期业务的大致流程图,资金方是服务的源头,目前好分期对接数十家资金方,每个资金方对用户的审核规则各有不同。好分期的作用主要是为用户进行适配、挑选最合适的资金方,因此需要在前期进行用户数据收集和分析,从而形成用户画像,通过各种计算方法为用户匹配最合适的资金方。
资金适配的痛点及应用挑战
高效、便捷、最大化的利益是用户关心的重点,资金适配的主要任务就是满足用户的需求,但好分期在实践的过程中还是碰到了一些痛点。
首先,随着接入的资金方越来越多,通过传统的计算方式来从众多资金方中挑选出最适合用户的资金方,变得越来越困难。
其次,传统路由模式中,所有用户共用一套资金体系,虽然支持手动配置,但是效果十分机械化,无法对每个用户进行针对性适配。
在尝试解决这些痛点的过程中,我们面临着新的挑战:
资金方越来越多的情况下,如何为用户进行快速适配;
每个用户都有适合自己的资方,通过数据分析摸索用户之间的关系,找到资金适配的规律。
为解决问题,我们开始将机器学习等技术应用到系统中。
机器学习在资金适配系统的实践
在金融领域,机器学习的应用越来越多,金融领域庞大的数据量也为机器学习提供了支持。机器学习项目的成功主要依赖于构建高效的基础结构、收集适当的数据集和应用正确的算法。
用户画像
想要解决上面所说的问题,需要先尝试生成用户画像,这里面用户数据的收集和清洗是至关重要的。用户的数据安全需要高度重视,凡是涉及到用户隐私的数据都需要进行异常严格的加密机制以及脱敏机制来进行处理。
用户画像建模第一步是要实现统一化。
用户唯一标识是整个用户画像的核心,我们以一个 App 为例,它把“从用户开始使用 App 到下单再到售后、整个流程中用户的所有行为”进行串联,这样就可以更好地去跟踪和分析一个用户的特征。
用户画像建模第二步是要实现标签化。
用户行为分析:
用户标签:它包括了性别、年龄、地域、收入、学历、职业等,这些是用户的基础属性。
消费标签:消费习惯、购买意向、是否对促销敏感。这些用于分析用户的消费习惯。
行为标签:时间段、频次、时长、访问路径。这些是通过分析用户行为,来得到他们使用 App 的习惯。
如果按照数据流处理的阶段来划分用户画像建模的过程,可以分为数据层、算法层和业务层。在不同的层,都需要打上不同的标签。
数据层指的是用户消费以及借款金额、借款用途、常住地等标签,这些可以打上“事实标签”,作为数据客观的记录。算法层指的是透过这些行为算出的用户建模,可以打上“模型标签”,作为用户画像的分类标识。业务层指的是获客、粘客、留客的手段,可以打上“预测标签”,作为业务关联的结果。
拿到用户画像后,再针对资金适配和相关业务场景来选择合适的算法。
基于用户的协同过滤算法
基于用户行为分析的推荐算法是个性化推荐系统的重要算法,我们一般将这种类型的算法称为协同过滤算法(Collaborative Filtering Algorithm)。顾名思义,协同过滤就是指用户可以齐心协力,通过不断地和网站互动,使自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
既然是基于用户的行为分析,就必须要将用户的行为表现出来,下面给出了一种用户行为的表现方式(当然,在不同的系统中,每个用户所产生的行为也是不一样的),它将用户行为表现分为 6 部分,即产生行为的用户和行为的对象、行为的种类、产生行为的上下文、行为的内容和权重。
随着对协同过滤算法的深入研究,学术界提出了很多方法,比如基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph) 等。在这些方法中,最著名的、在业界得到最广泛应用的算法是基于邻域的方法,而基于邻域的方法主要包含下面两种算法:
基于用户的协同过滤算法(User-based Collaborative Filtering),简称 UserCF 或 UCF,这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于物品的协同过滤算法(Item-based Collaborative Filtering),简称 ItemCF 或 ICF,这种算法给用户推荐和他之前喜欢的物品相似的物品。
在一个个性化推荐系统中,当一个用户 A 需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户 A 没有听说过的物品推荐给 A。这种方法称为基于用户的协同过滤算法。
基于用户的协同过滤算法主要包括两个步骤:
找到和目标用户 A 兴趣相似的用户集合。
找到用户集合中其他用户喜欢的且目标用户没有听说过的物品推荐给目标用户。
步骤 1 的关键就是计算两个用户的兴趣相似度。这里协同过滤算法主要利用行为的相似度来计算兴趣的相似度。
通过以上概念,我们可以作出设想,协同过滤算法通过找到用户感兴趣的物品,计算用户之间的相似度,进行推荐,那么,好分期在资金适配的时候,也可以引入此方法,从而提高计算效率。比如可以通过用户 A 的基本信息,找到和用户 A 基本信息相似的用户,此类用户会成为一个集合,然后统计此类用户适配的资金方,通过计算,得到一个资金方对此类用户集合的排序,从而可以为 A 用户提供更优秀的计算顺序。
(1)基于用户的最近邻推荐概述
基于用户的最近邻推荐(user-based nearest neighbor recommendation)主要思想是:首先,对输入的评分数据集和当前用户 ID 作为输入,找出与当前用户过去有相似偏好的其它用户,这些用户叫做对等用户或者最近邻;然后,对当前用户没有适配过的每个资金方 P,利用用户的近邻对资金方 P 的评分进行预测;最后,选择所有资金方评分最高的 TopN 个推荐给当前用户。
(2)前提/假设
如果用户过去有相似的偏好,那么该用户在未来也会有相似的偏好,用户的偏好不会随着时间而变化。
(3)计算方式
使用皮尔森/皮尔逊相关系数(Pearson Correlation Coefficient)来表示两个用户之间的相关性,取值范围为[-1,+1],-1 表示强负相关,+1 表示强正相关,0 表示不相关。
应用实践
下图展示了好分期数据平台的总体架构。对于数据平台来说,最重要的是保证数据的时效性和准确性。
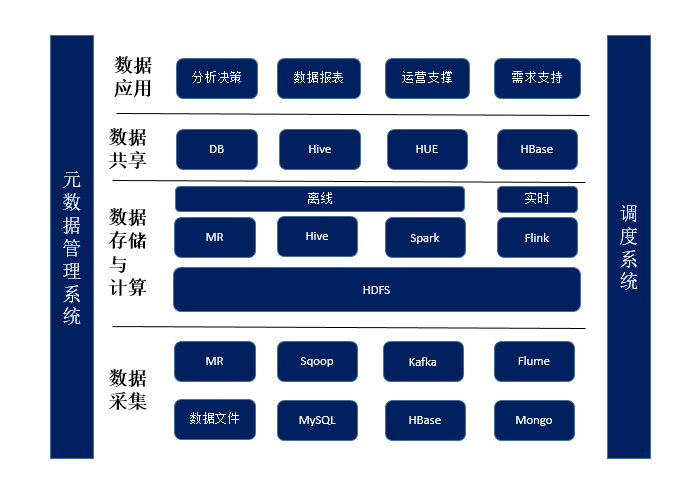
拿到数据之后,根据费率、利息、金额、用途等一系列条件,进行实时计算(结合每个资金方的特定准入条件),根据用户的情况和资金方的情况进行适配性打分,最终为用户适配到最合适的资金方。下面用基于用户的协同过滤算法介绍好分期的计算逻辑:
举例而言,当需要为用户 A 匹配资金方时,首先检查它们之间的相似度。当我们发现用户 A、用户 B、用户 C 的相似度较高时,就可以将这三个用户看作一个群体,他们拥有相同的偏好。分析这个群体之前已经适配过的资金方,优先对该资金方进行计算和排序,可以大大提高计算效率。
资金适配中,我们可以将用户的用途、费率、户口所在地、住址等基本条件进行分类。本文只通过用途和费率举例。
相似度计算举例:
根据用户的基本信息。检查它们之间的相似度列表,同时也可以对类别进行标签和分组,最终得到用户与资金方的适配度,比如 A 用户的标记性信息有 N1、N2、N3,D 用户的标记信息有 N2、N3、N4。
接下来尝试计算 A 和 D 之间的相似度:
从“基本信息”可以看出,A 和 D 都拥有的基本信息是 N2。用户 A 标记性信息=3,用户 D 标记性信息=3。所以 A 和 D 的相似度为 1/3。
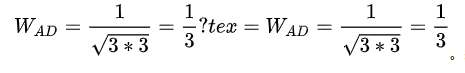
在得到用户之间的相似度之后,接下来要做的就是进行适配性推荐了,假设用户 C 和用户 D(群体)都已成功与资金方 X 进行适配(之前计算的最合适的资金方),那么就优先去计算用户 A 与资金方 X 的适配程度。最后,根据适配度计算的结果,进行相应的推荐,把相对应的资金方适配给用户。
计算示例:
效果如下:
张峰海与 userColA 集合的相似度为:0.8654335698926632
张峰海与 userColB 集合的相似度为:0.6558297417698652
张峰海与 userColC 集合的相似度为:0.3202118523990502
张峰海与 userColD 集合的相似度为:0.5862446890012758
当然,基于用户的协同过滤并不会这么简单,判断两个用户的相似度也不是简简单单的使用余弦相似性就可以了。实际业务场景中我们还需要用到更复杂的逻辑,才能达到最终的目的。本文只是让读者有一个简单的概念,具体企业应用中的变化,就不详细开展了。
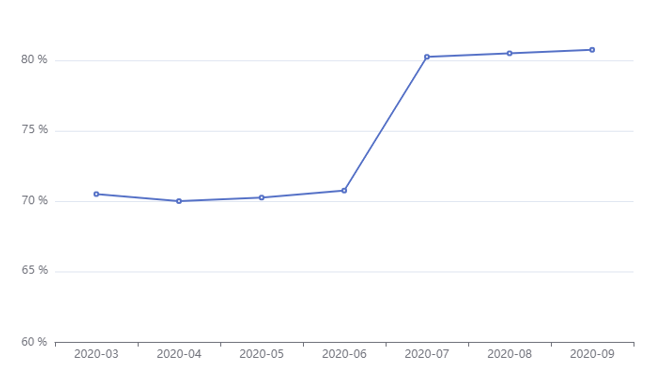
通过对数据的收集和清洗,以及一系列计算规则(包括上面所说的相似度计算),最后我们发现资金方的适配成功率提高了将近 10%。X 轴为时间,Y 轴为适配成功率,如图所示:
总结
总的来说,资金适配的应用实践是有一定效果的。对于未来可能面临的情况,我们也展开了一些思考。未来将会有更多的资金方接入到系统中来,用户对于线上的金融需求也会越来越多。挖掘用户信息、提供更高效、更优质的服务将一直是好分期追寻的目标。未来我们会探索更多的模型、更优秀的计算方式,并将其运用到资金适配系统中来。
作者介绍
吴迪,微财科技技术总监
孙丽川,微财科技资深工程师
郭帅,微财科技高级工程师

InfoQ中文站编辑

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论