

接下来继续为大家分享机器学习系列课程,第一章的第二节,机器学习如何做:
机器如何学习?

首先了解下,机器是如何做到学习的。在上一节中,跟大家分享了机器为什么能够学习。那么机器如何一步步做的呢,我想给大家分享一个非常有趣的案例:假设机器可以穿越时空回到 17 世纪,在 17 世纪有一个重大的科学发现,就是牛顿的力学三定律。那么我们的机器是否能够学习牛顿学习这个世界的过程?也就是机器能否发现学习到牛顿的力学三定律。以牛顿第二定律来做一个说明,牛顿第二定律是指,物体加速度的大小跟作用力成正比,与物体质量的倒数成正比,即 a = F * 1/m。大家可以看右边的图,大家都学过模拟当初牛顿发明第二定律的过程。在实验中,我们得到了数据表格,表格中的五个点分别对应了当时的力和加速度。对于机器来说任务是这样的:我们期望通过观测到的五个数据进行归纳学习,学习到物体的加速度 a 与作用力 F 之间的关系。当机器掌握其本质性的关系之后,就可以进行演绎,就可以知道当对质量为 3Kg 的物体施加 4N 的作用力时,会产生多大的加速度。最终机器通过这样的学习可以预测任何物体在某一个作用力下的加速度。
机器的学习方案
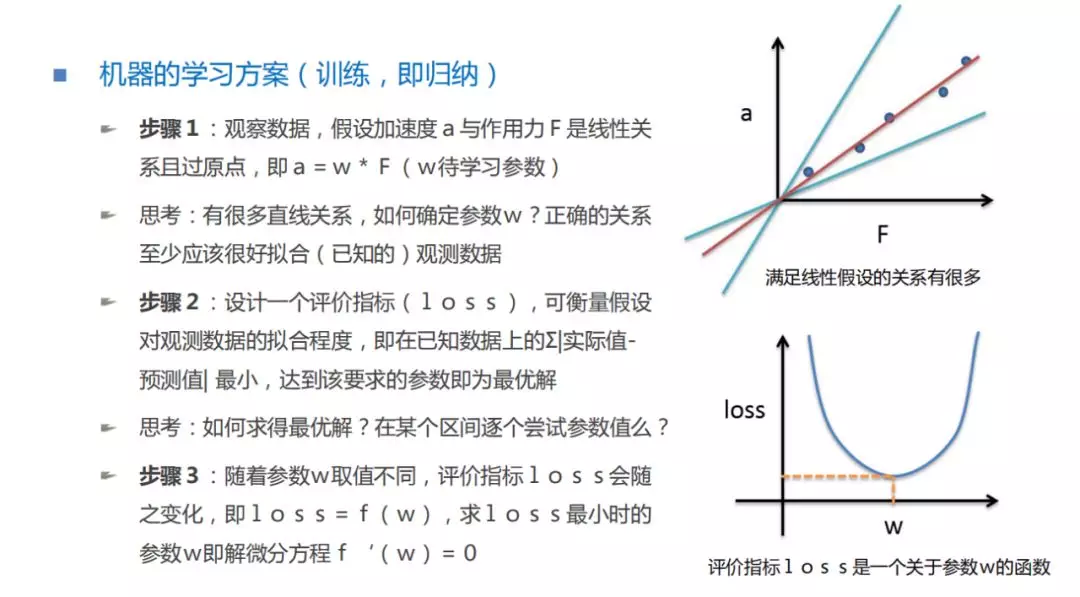
如何为机器设计一套步骤,让机器学到这个事情?
步骤 1:首先,我们把观测到的五个数据画在图中,会发现这样的五个数据很像经过原点的直线(为什么经过原点?因为当作用力为 0 时,加速度也是 0,所以会经过原点)。所以我们大胆的假设,作用力和物体加速度的关系就是一个线性关系。这个线性关系可以用 a = w * F 来表示,w 是什么,我们还不知道。我们知道经过原点的直线有很多条,那么我们选择出的正确关系,至少应该很好的拟合我们已知的观测数据。
步骤 2:设计一个评价指标(loss),可以衡量假设与观测数据的拟合程度,即假设一条经过原点的直线,把观测数据上的每个点与这条直线的偏离程度(相减)都进行求解之后,再进行加和,当加和是最小值时,我们假设的这条直线就很好的拟合了我们观测到的数据,这时这条直线的参数,就是我们想求的最优解。
步骤 3:如何把最好的假设找出来?随着参数 w 的变化,评价指标 loss 也随之变化,说明 loss 是关于参数 w 的一个函数,如果通过计算发现,loss 和 w 的关系是这样一条曲线的话,我们想求的就是 loss 最小时对应的 w 值。如何求解?这里需要引入微积分。当求一条曲线的极值时,最好的方式就是求导。在曲线有一个特点,当曲线取最大值或者最小值时,曲线的斜率为 0,即切线是水平的。因此,我们可以构造一个微分方程,对 loss 函数求导,f’(w)=0 时,参数 w 的值就是 loss 达到极值点最小值时参数的取值。这时我们就可以确定 a 和 F 之间究竟是怎样的关系。
学习过程中隐藏了什么?

刚刚介绍了在机器学习过程中的三个步骤。通过这三个步骤,机器学到了现实世界中的知识,也就是牛顿力学第二定律。大家是否感觉这个过程有点神奇?在这个过程中究竟这三个步骤隐藏了什么样的信息和知识?
总结下:首先明确一点,学习的过程其实是归纳的过程,机器是不是在学给机器看的这些数据?其实不是的,机器是通过数据的表象想抓住了数据背后的本质的规律。这里举个比较有趣的例子,就是张三丰在教张无忌太极拳的时候,按照正常人的理解,应该学的越好,会的招数越多。但是,每次张三丰问张无忌的时候,张无忌说学到的招数越来越少了,直到最后全部忘记了。这时张三丰说,你终于学会了。在我理解金庸先生对学习这件事情的认知是非常透彻的。张三丰想教给张无忌的不是太极拳的那些招式,而是背后借力打力的武学系统的本质。只有当一个人忘掉了这些具体招式的时候,他才真正的掌握招式背后的本质。对于机器学习也是这样,我们刚刚是学到了牛顿力学第二定律这样的本质公式,而不是具体的几个样本,给出多少作用力的时候,它具体的加速度是多少。
再来看看得到这样的结果,我们经历了怎样的过程?我们的目标是确定 x 和 y 之间的关系,也就是确定加速度和作用力的关系。那我们怎么做的?首先第一步,做了一个假设,就是他俩的关系应该是一个线性的。那做这个假设相当于什么?相当于 x 跟 y 有很多很多的关系集合,可能 或 或 等等更复杂的可能。但是这个时候我们首先做了一个假设,y=wx 它们之间的关系是一个线性的,那这相当于什么?相当于在所有的假设空间中,画了一个圈,把其他可能都排除在外了,它俩之间的关系只可能在这个圈内,这个圈内是什么?这个圈就是我们的线性关系,就是 y=wx,但是接下来,即使在这个圈里也是不行的,圈里依然有非常多的假设可能,如 y=x,y=2x…,那究竟参数 w 是多少?首先需要确定一个优化目标,也就是刚才说的评价指标 loss 来衡量我们每一个假设好还是不好,对于刚才具体的问题什么样算好的?尽可能拟合我们已经观测到的数据就是好的。所以 loss 的设计就是看每一个具体的观测的样本点距离假设的这条直线之间的一个差距,把所有的差距加和在一起,就得到了衡量假设直线好和不好的指标,这个指标就作为我们一个评价的指标。有了评价指标后,最后需要做的事情就是在假设空间中,找到能够使优化目标 loss 最小的一个假设,就是我们想求的最好的假设,那怎么找到?就是我们需要有一套寻解的算法,那这寻解的算法按刚才所说,因为 loss 跟参数值 w 之间是一个函数关系,我们想求的是当 loss 最小值的时候,参数的一个取值。这时,我们实际上就是对整个 loss 函数去求导,当导数等于 0 时,这里用到了微积分,当函数取到极值时,斜率是为零的,就是切线是平行的。最后解这样的微分方程,就可以求解得到参数值。这里用到的优化目标其实是我们每一个样本点的实际值减去假设这条线性关系的一个预测值,它俩差值的平方的加和,为什么不是它俩差值的绝对值加和呢?在接下来会和大家具体介绍,因为取平方的加和可能在后续的寻解算法优化过程中会得到一个更便利的结果,但它实际得到的最优点的值跟取绝对值做优化的结果是一致的。
这里就跟大家又明确了刚才隐藏在机器学习三个步骤背后的三个重要的核心构建:
假设空间
优化目标
寻解算法
机器学习就是首先确定一个假设空间,把所有的关系中可能是这个关系的空间画出来,画一个圈。第二步就是确定这个圈中的假设哪个好哪个不好,需要设计一个优化目标,或者是一个评价指标,或者叫 loss,来衡量哪个假设更好,和哪个假设更差。最后需要一种寻解算法,能够高效的从这个圈中找到使得评价指标最好的那个假设。这就是机器学习至少是监督学习算法的设计框架,之后会给大家介绍一些非常实用的算法,大家会发现这些算法其实都是这样设计出来的,只是在这三个环节上不一样。
这里稍微说一下,为什么这个课程跟其它机器学习教材或者算法课不同。一个很重要的原因就是一些算法课,我们每翻开任何一本书,会发现它都是今天介绍 A 算法、B 算法、C 算法,从来不给大家介绍究竟这些科学家当时是怎么想到这个算法的。本课程系列虽然可能不会给大家介绍太多的算法,但我们的设计原则就是为大家介绍这些算法背后的逻辑,让大家了解这些算法到底应该如何应用。
三个核心要素:多种多样的可能
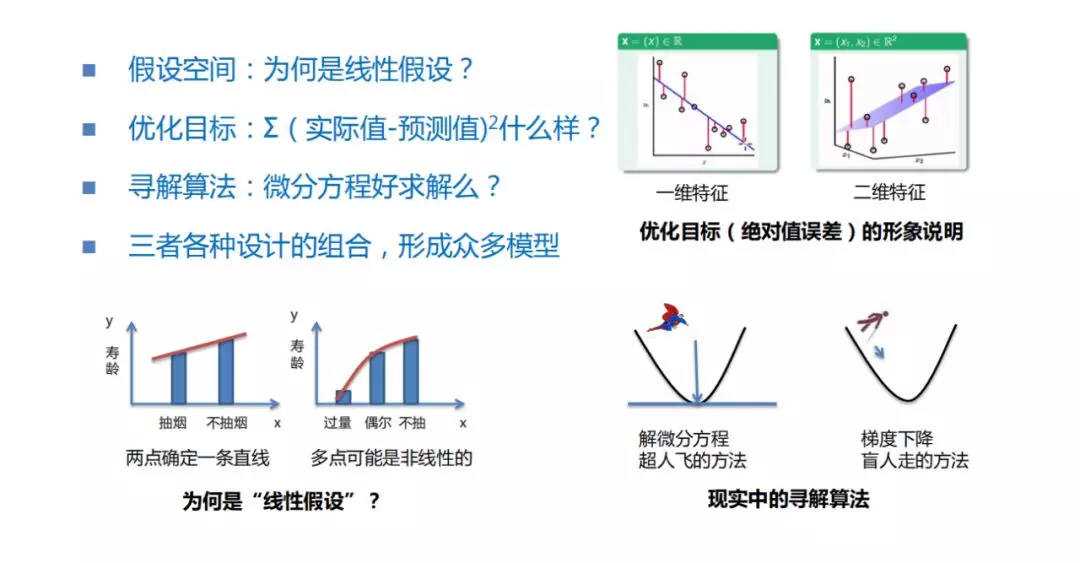
刚才已经说过,假设空间、优化目标和寻解算法是各种监督学习设计的三个通用组件,随着三个组件设计的不同,会形成非常非常多的算法。给大家举些例子说明,就是刚刚我们假设作用力跟加速度之间是一个线性关系,但大家都知道,在我们这个世界中大量存在的关系其实是一种非线性的。比如之前说的吸烟和寿龄的关系,大家可能很快就能领悟到,如果我们多取几个吸烟程度的变量值,比如把偶尔吸烟算做一种人、把从来不吸烟的算做一种人,把非常大量非常疯狂吸烟的算做一种人,算出这三类人之后,我们发现这三类人对寿命的减少程度是不一样的。也就是说我们如果通过这样一个特征,这个特征有三个取值,这个作为 x 去算这三个取值跟寿龄 y 的一个关系,它们其实是一个非线性的关系。那么这样一种非线性的关系,就不可能通过线性模型去解决。也就是说我们后续会有很多相当强大的模型,它们的假设空间就是一个非线性的空间。
第二步,我们今天给大家设计了一个优化目标,这个优化目标尽可能拟合我们现在已有的观测数据。如何判断优化目标 loss 拟合观测数据的程度?就是每一个观测点的实际值 y 跟我们做了一个假设之后,产生对每个节点的预测值,它们之间做相减,在这个图中大家可以看到就是一条条的红色线段。对于一维特征,它是一个平面的,对于二维特征,它其实是一个更立体的感觉。但是这些线段也是一样的,就是观测到这些数据点与真实预测的假设之间的一个差距。简单的想法就是拟合最好的假设应该是这些线段加和最小的,由于每个加和有正有负,为了方便取平方进行加和,可能还会跟后续的一些寻解算法上的方便,做了一些平衡。所以,第二步是指定了这样的优化目标,认为能使得 loss 最小时是一个非常好的假设。
第三步,就是得到最好的假设。刚刚介绍了解微分方程这个方法,用个形象的比喻,就像是超人直接找到了最优的解。但实际上,微分方程在数据量非常大,特征维度非常多的时候,其实不是特别容易解的,我们通常用的另外一种相对容易的方法类似于一个盲人逐渐探索,探索到最好的使 loss 函数最小的参数取值上,虽然看不到最低点在哪,但是知道现在这一步应该往哪个方向走,或者是参数应该怎么样调整,可以使得 loss 一步步变好,最后变到一个所有组合可能中最小的位置。
机器学习整个学习框架中的三个核心元素,它们不同的设计组合就会形成众多的模型。在后面系列课程第二部分,会向大家介绍更多各样的算法模型,大家会发现不管这些算法模型是如何实现的,这些模型都是符合这样的设计架构的。
学习到的知识如何记录?

通过刚才的学习过程,我们学习到的知识如何去记录、表示呢?看这个式子,加速度就相当于预测值 y,F 是特征 x,对于这个问题来说,x 非常少,只有一个作用力,这个参数非常有意思,参数 w 经过计算发现恰好就是物体质量的倒数,也就是说机器学到的东西跟当时牛顿学习、认知到的牛顿第二定律是一样的。机器如果能够回到 17 世纪,用机器学习的方式,是可以把牛顿的这些定律再重新学习出来,让机器学会的。
大家想想,如果再多一个变量,这个事情会变成什么样呢?比如这个变量加上物体的摩擦力,当然物体的摩擦力跟两个因素有关,一个是物体的摩擦系数,用 u 去表示,一个是物体本身给地面的正压力,用另外一个特征 表示。我们会发现,这个式子就变成 ,这是今天和大家举的一个参数很少的例子。随着未来学习的关系和案例变得越来越复杂,实际上就是更多的影响变量 x,以及更复杂的 x~y 之间的关系,就需要有更多待学习的参数 w 以及收集更多的训练样本,甚至使用更复杂的模型假设进行更耗时耗力的寻解计算。
但是这个简单的案例,已经把机器学习的本质,如何一步步学到的本质理念跟大家都说了,这里引用道家的一句古话就是:“道生一,一生二,二生三,三生万物”,也就是说所有的看起来很复杂的事物,它本质的关系用一个非常简单的案例就可以表示,就是我今天跟大家分享的牛顿第二定律的整个机器去学习的过程。
最后跟大家稍微解释一下,后续可能会用到的一些专业名词,输入是特征,输出的结果叫预测值,输入和预测值中间的需要去学习确定的关系叫参数。
附录:机器学习过程的案例
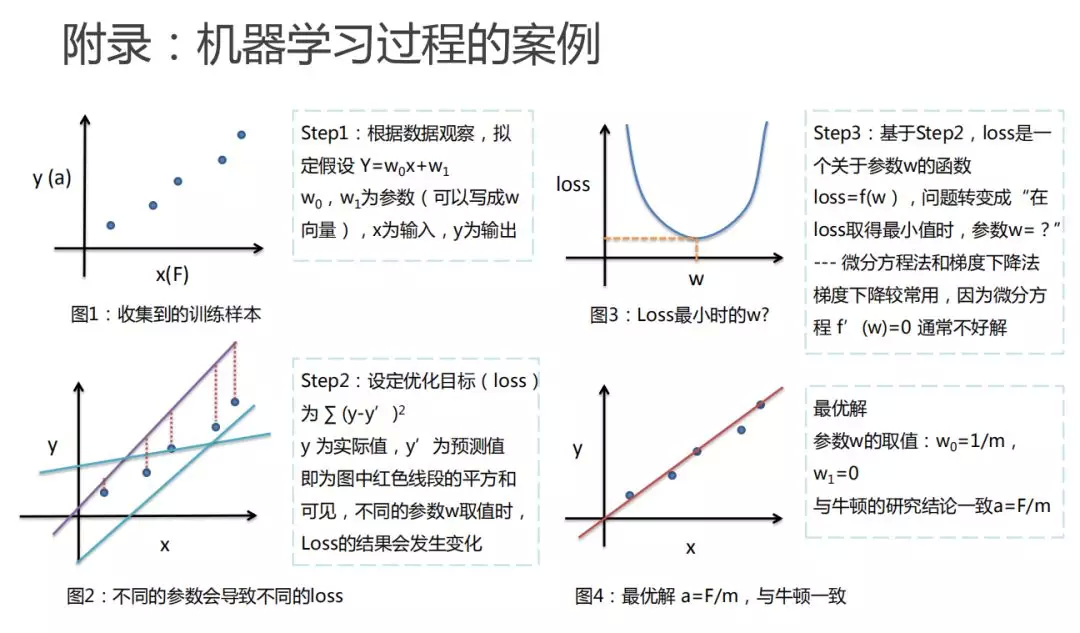
最后,再通过专业的解释,把整个机器学习的过程再给大家回述一遍:
第一步,把收集到的样本画出来,就是通过做实验得到这些加速度和力的关系画出来。通过作图,我们发现 x 和 y 之间很可能是一个线性的关系,而且这个线性是通过原点的。这时可以做线性假设,认为 x 跟 y 之间就是一个线性的关系,可以写成一个线性方程,就是 y=wx。
第二步,要设定一个优化目标,因为随着参数的不同,我们发现有很多种可能满足我们的假设。但是不同的假设,能够拟合已观测数据的程度是不一样的,我们期望能够找到最拟合观测数据的那条具体的假设。这时我们就需要设定一个优化目标 loss,或者认为它是一个评价指标,评价哪一个假设能更好的衡量我们已知的观测数据。今天设计的优化目标 loss 就是每一个节点的真实值和我预测值差距的一个平方,最后把所有的这些节点产生的误差加和作为衡量的方式,loss 越小就意味着这个假设更好的能拟合观测数据。通过刚才设计的 loss 优化目标,我们发现 loss 优化目标会随着参数的取值不同而发生变化。我们真正想做的是找到一个参数的可能,在这个参数的情况下,评价指标 loss 函数达到最小,能最好的拟合数据。
第三步,既然 loss 是一个关于参数 w 的函数,就可以用一些数学的手段,比如刚才说的求导。当导数等于 0 时,来求解参数 w 最好的取值,也就是 loss 的最小值。
最后,把刚才得到的最好的参数画到图中,大家可以看到结果就是这样的。当参数取物体质量的倒数时,我们发现这个直线的假设是最好的能拟合我们已观测的数据,这时机器就学到最好的假设 a=F/m。这与牛顿当年得到的假设完全一样,也就是说机器通过刚才学习我们设计的三个步骤,是完全可以模仿当时的牛顿,去把这个世界的知识学习到手。
本文来自 DataFun 社区
原文链接:

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论