

本文承接《国际酒店用户服务能力提升(一)》中对 L-D 环节顺畅度的提升。上文中分析了顺畅度情况较差的原因,下文会详细说明我们究竟做了什么来提升顺畅度。
2. 售前服务
2.2 L-D 环节顺畅度提升
(2)报价抓取调度机制改造
③ 离线抓取方案设计
既然使用了缓存,并且存在缓存和真实库存情况不一致的问题,那么说明缓存中的数据不是最新的真实库存情况。这里我们定义了一个概念叫缓存报价的新鲜度,缓存新鲜度 = 缓存报价被使用时刻的时间-抓取回数时刻的时间,只要保证缓存足够新鲜,发生变价和房态变化的概率将会越低。而缓存的新鲜度受抓取的频次影响,抓取频次受两次抓取的时间间隔(下文统称 cache time)影响。
上文有提到在原有机制中 cache time 是由人工进行配置并且是不可靠的,脱离原有机制思考一下都有哪些因素会影响 cache time:
城市、酒店、日期的的热度不同(相对热门库存变化会更快);
代理商差异(qps 能力不同、覆盖的城市和酒店不同)。
基于上面的因素,可以在较冷门的报价上减少 qps 资源的投入,而让 qps 资源更多地向热门倾斜。
如何更合理地让 qps 资源向热门倾斜呢?热门其实对于搜索来说,说明用户的搜索频次越高。那么将更多的 qps 资源分配给搜索频次更多的报价就可以实现该目的。如下图,对于某一个 wrapper(针对一个代理商),将用户搜索过它所能覆盖的酒店以 酒店+入离店日期 的维度进行排序,能得到如下图的曲线。那么每一个最小维度应该分配的 qps = (最小维度的搜索量(count)/ 总搜索量(S))× qps 总量。qps 是每秒应该抓取报价的次数,cache time 是报价抓取的间隔,有了 qps 就能知道 cache time 应该是多少。
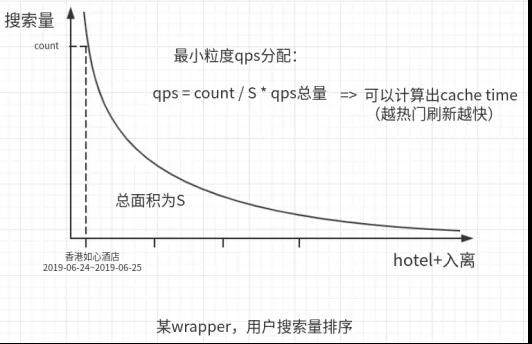
在这里我们并没有直接使用单纯的搜索量排序, 因为当天的搜索量在报价抓取的时刻是处于未来时刻的,我们使用的是通过历史数据对于未来流量的一种预测模型。参考算法模型在预测未来趋势时使用的趋势特征和实时特征:我们将过去 n 天的搜索量数据作为趋势特征,并且使用搜索日期和入店日期的相对日期来和实时日期进行拟合;将过去 1 天的搜索量数据作为实时特征。加权搜索量 = 过去 n 天搜索量 × 权重 1 + 过去 1 天搜索量 × 权重 2。
计算 cache time 的时序图如下,其中 rank 指的是上文中的加权搜索量。
有了合理的 cache time 后,还需要一种机制能保证报价可以按照预想的 cache time 的进行更新。为此我们做了当报价缓存时间到达预设的 cache time 后进行更新的离线抓取能力,来保证 qps 资源能充分得到利用,报价的抓取间隔达到预期。至此,对于抓取调度的改造基本完成。整体 cache time 的闭环如下图所示:
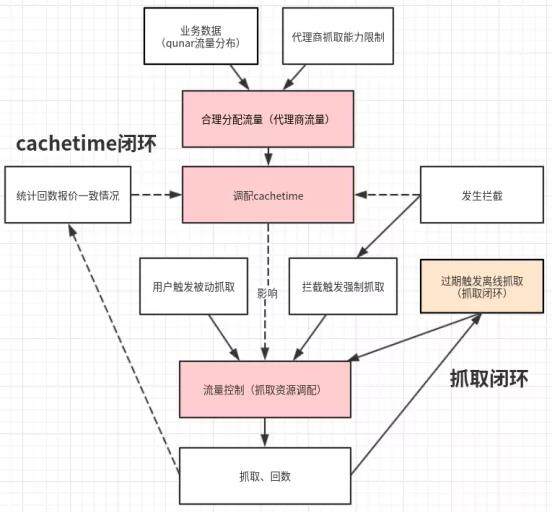
抓取调度机制上线后并,负责报价回数存储缓存的系统线上机器 load 飚高,在使用新的抓取调度机制后 GC 严重。在排查问题后,为了解决问题我们对报价回数存储缓存的系统(rebuild 系统)进行了重构,下文将对这一过程进行说明。
(3)rebuild 系统重构
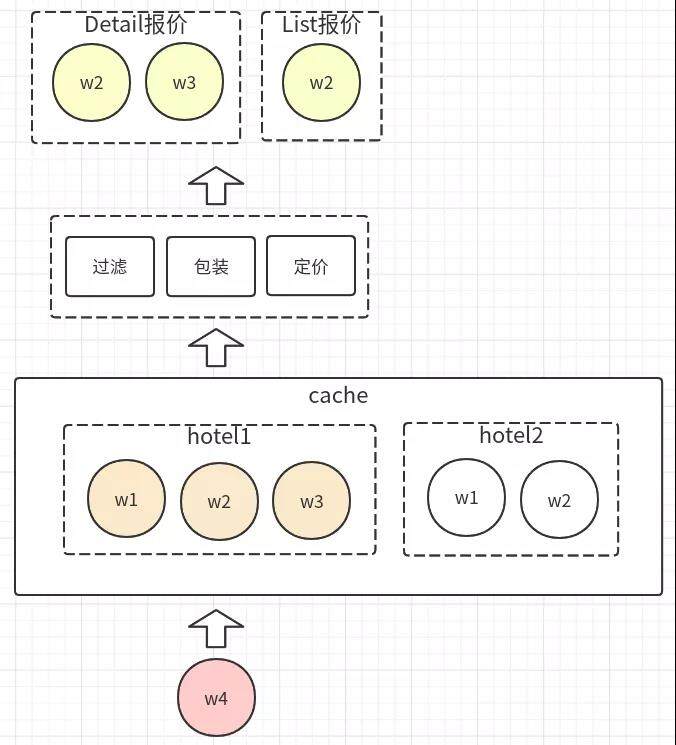
上文有展示过报价的简化结构,在原有的架构中这部分业务都是在 rebuild 系统中进行的。rebuild 系统提供的能力按照功能性分为几个部分:
处理报价回数:先处理 wrapper 维度的回数,再将 wrapper 维度报价与缓存中已有的酒店维度报价缓存更新整合并重新存储到缓存中;
计算最新的酒店维度最低价并用于酒店排序展示;
对于缓存中基础报价的过滤、包装、定价。
其中职能 1 和职能 2 部署在实体机集群上,职能 3 由于历史原因部署在虚拟机集群上,也就是说同样的一套代码分割成了两部分运行在两个性质完全不同的集群上。而出现问题的集群就是实体机集群。我们接着说明,为什么在抓取调度机制上线后,实体机集群会出现机器 load 飚高的问题。
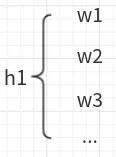
酒店业务是同一个酒店会有多个 wrapper(代理商)同时售卖的。用户搜索一个酒店时,会触发一个酒店下所有能提供该酒店报价的代理商的报价抓取并将结果展示给用户。如下图。
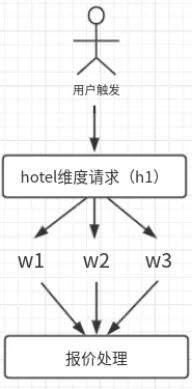
在一次回数过程中,需要将之前存储的酒店维度报价缓存取出后,更新最新的 wrapper 维度报价,再重新存储。这其中就会有大量的序列化/反序列化、GC、IO、业务流程计算等带来的资源的消耗。流程如下图。
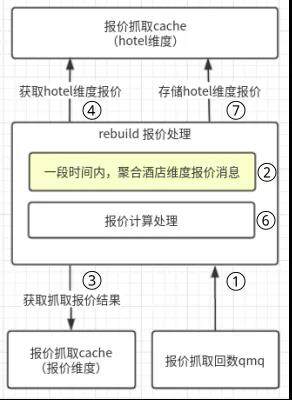
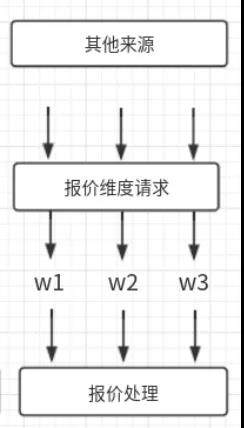
在原有流程中,普遍情况下都是由用户触发抓取和回数,大概率事件是同一个酒店下多个 wrapper 会同时发起抓取报价的请求并且可以在一定时间范围内完成回数。而为了避免对资源的消耗,之前的同事设计了一个回数等待的机制(上图流程 ②)。在一段时间内,会聚合统一酒店维度(酒店+入离店日期)的 wrapper 报价抓取结果,仅对缓存池中的酒店维度缓存报价进行一次读和写操作,这样就减少了对资源的消耗。而新的调度抓取机制并不是依赖用户的搜索触发,在上文介绍抓取调度机制时有提到,新的调度抓取机制会将抓取流量打散,根据抓取的最小粒度(wrapper+酒店+入离店日期)应有的 cache time 进行触发抓取,如下图所示。
原有的流程 ② 中减少机器消耗资源的能力对新的抓取调度机制不再生效,最终导致了机器的 load 飚高,处理能力降低,不足以支撑报价抓取回数时的计算能力。原有抓取回数的 qps 峰值约 8k,当新的抓取调度切量到 5k 时,整个实体机的集群 FullGC 大大增多,如下图所示。究其根本,就是请求被打散,消息聚合能力下降导致处理能力降低。当然,最简单的提高集群处理能力的手段就是在集群中新增机器来解决,但是初步估算想要支撑新的抓取调度机制完全切换,需要将原有集群扩容到两倍以上,而实体机的成本又较高,同时这部分的问题是由于代码逻辑与业务逻辑不匹配导致的,所以我们决定对 rebuild 系统进行重构用来支撑业务。
总结一下,支撑我们对 rebuild 系统进行重构的原因如下:
1、业务瓶颈
(1)现有 rebuild 系统不足以支撑新的抓取调度机制;
(2)回数的链路较长,虽然上文中的流程 ② 解决了资源消耗的问题但是拉长了回数链路,缓存(用户)无法及时看到最新的报价;
(3)rebuild 在处理回数时存在缓存清理的逻辑,这部分逻辑原本的意图是防止缓存时间过长用户看到的报价不够新鲜,但是在新的报价抓取调度机制下是可以避免这种问题的,而对缓存的清理会加剧不同环节下访问缓存报价的不一致问题发生。
2、系统瓶颈
(1)rebuild 系统处理回数的实体机器群不易扩容,应对突发情况不能在短时间做出响应;
(2)rebuild 系统处理能力差,在估算下该系统使用几台虚机就可以完成业务诉求,并不需要大量的实体机集群支撑;
(3)rebuild 系统职责不单一,多个职能分布在物理环境不同的集群上但是又共用同一套代码,扩展性较差。
3、学习、维护成本高
系统的设计较为复杂,比如上文提到的流程 ② 使用了环状内存缓存队列并且存在多种情况会对队列进行出队操作完成酒店维度报价的聚合,并且系统由于迭代的时间较久,人员更替较多,部分代码成为祖宗代码。
我们的重构就为了解决上述问题而实施方案,其中最主要的的一点就是将原有的酒店维度报价缓存更替为 wrapper 维度报价缓存,如下图。
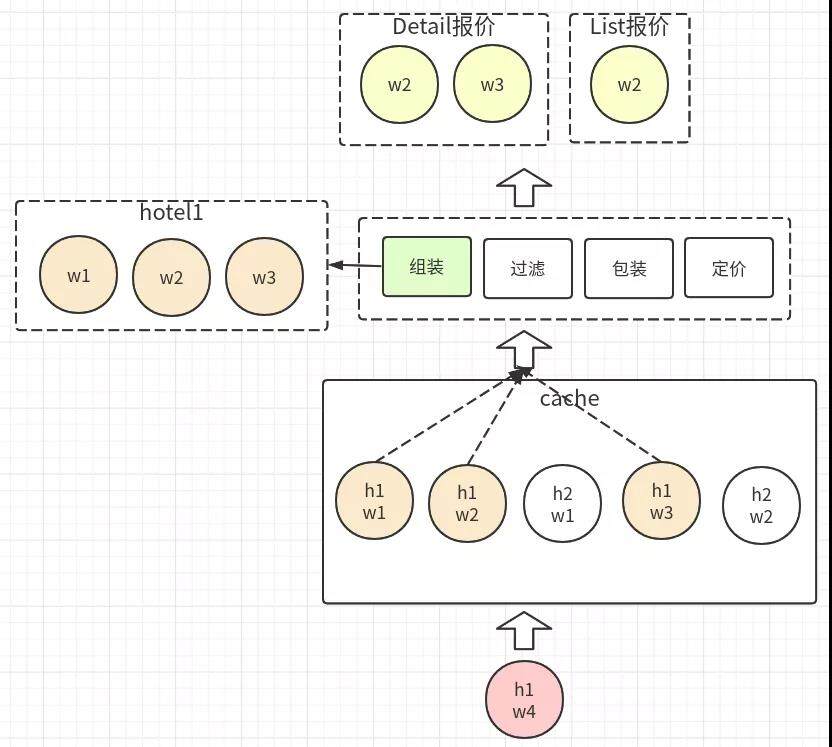
相对于原有的过滤、包装、定价三个大环节的基础上增加了酒店维度报价的组装。存储 wrapper 维度报价,读取时按酒店维度读取对应 wrapper 报价再组装。这样,存储报价时仅面向 wrapper 维度报价,不再处理酒店维度的业务。原有的酒店维度低价计算(上文提到的 rebuild 系统职能 2)和报价回数存储逻辑进行拆分,简化了回数链路,职责单一,并且便于后续对低价计算的重构和优化。读取时,由于 wrapper 报价维度从酒店维度中拆散,可以并行的从缓存中读取。例如:香港的热门酒店,一个酒店会有几十个代理商提供报价,原有的酒店维度报价的报文大小 MB 级别,读取时网络 IO 的时间也比较久。而拆散后,可以并行的读取报文再拼装,减低了读取数据时整体耗时。并且在重构的过程中,针对已有的业务进行代码的重新编写,避免了祖宗代码的保留,大大提高了代码的可读性,降低了学习成本。
由于变动了缓存的结构,并对核心主流程的代码进行了重构,为了避免线上出现问题,需要进行可靠的验证。我们 diff 了新老结构、流程中酒店维度的报价报文字段,做到 100%的准确无误。关注了缓存从酒店维度拆解成 wrapper 维度的压缩率以及对缓存存储空间的占用大小。并且对整体报价读取的响应时间进行了评估。
正式上线后,基本符合预期:
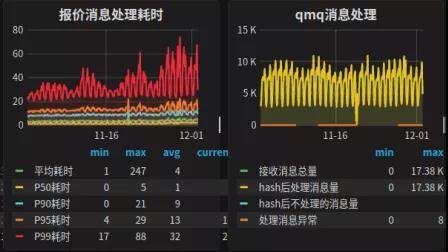
报价回数存储基本不存在延迟,平均回数处理时长 4ms;
新系统集群由 20 台虚拟机构成,可以处理线上 17k 的报价回数消息并且远远没有触达系统瓶颈,而原有集群的 13 台实体机处理 8k 消息已经触达系统瓶颈;
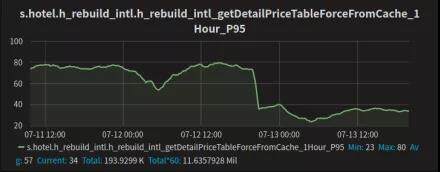
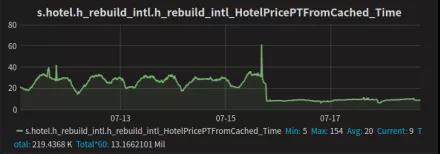
酒店缓存报价读取 P95 时长从原有的 80ms 降低到 35ms,平均时长从 30ms 降低到 10ms;
系统代码文件数从 1001 个文件减少到 171 个文件。
在对 rebuild 系统进行重构后,新的抓取调度机制得以顺利上线。
2.3 项目成果
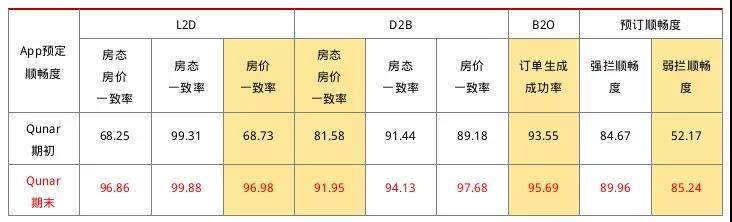
当然,除了 L-D 环节的顺畅度以外,其他同事也在其他环节上做出了努力与贡献。为了解决 D-B、B-O 环节的顺畅度问题,还做了禁售、实时报价库存更新、报价容差等一系列的项目。从结果上来看通过大家的不懈努力,将国际酒店整体顺畅度提升到了 87%,极大改善了 Qunar 用户在国际酒店售前环节的体验。
售前服务的提升告一段落,后续的文章《国际酒店用户服务能力提升(三)》会聊一聊在售后服务的提升过程中我们做了哪些事情以及在技术上的探索和尝试。
头图:Unsplash
作者:张楚宸
来源:Qunar 技术沙龙 - 微信公众号 [ID:QunarTL]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论