

本文最初发表于 Towards Data Science 博客,经原作者 Youness Mansar 授权,InfoQ 中文站翻译并分享。
众所周知,深度学习在应用于文本、音频或图像等非结构化数据时效果很好,但在应用于结构化或表格化数据时,深度学习有时会落后于其他机器学习方法,如梯度提升等。在本文中,我们将使用半监督学习来提高深度神经模型在低数据环境下应用于结构化数据时的性能。我们将展示通过使用无监督的预训练,可以使神经模型的性能优于梯度提升。
本文是基于以下两篇论文:
《AutoInt:基于自注意力机制神经网络实现的自动特征交互学习》(AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks)
《TabNet:专注的可解释表格学习》(TabNet: Attentive Interpretable Tabular Learningz)
我们实现了一个类似于 AutoInt 论文中提出的深度神经结构,使用了多头自注意力和特征嵌入。预训练部分取自 TabNet 的论文。
方法说明
我们将处理结构化数据,这意味着可以将数据写成具有列(数字、分类、序号)和行的表。我们还假设我们有大量的未标记样本,可以用于预训练,以及少量的标记样本,可用于监督学习。在接下来的实验中,我们将模拟这个环境来绘制学习曲线,并在使用不同大小的标记集时对该方法进行评估。
数据准备
让我们用一个例子来描述在将数据提供给神经网络之前我们是如何准备数据的。
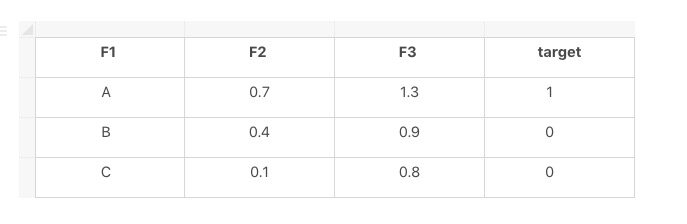
在这个例子中,我们有三个样本和三个特征 {F1,F2,F3} 和一个目标。F1 是分类特征,而 F2 和 F3 是数字特征。
我们将为 F1 的每个模态 X 创建一个新特征 F1_X,如果 F1==X,则为其赋值 1,否则等于 0。
转换后的样本将写入一组 (Feature_Name, Feature_Value)
例如:
第一个样本 → {(F1_A, 1), (F2, 0.3), (F3, 1.3)}
第二个样本 → {(F1_B, 1), (F2, 0.4), (F3, 0.9)}
第三个样本 → {(F1_C, 1), (F2, 0.1), (F3, 0.8)}
特征名称将被馈送到嵌入层,然后与特征值相乘。
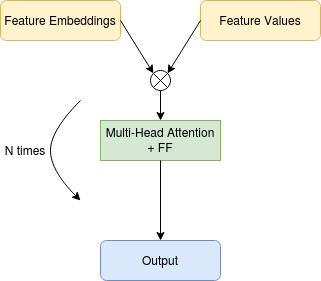
模型:
这里使用的模型是一个多头注意力块序列和逐点前馈层。在训练时,我们也使用池化的注意力跳过连接。多头注意力模块允许我们对特征之间可能存在的交互进行建模,而池化的注意力跳过连接允许我们从一组特征嵌入中获得单个向量。
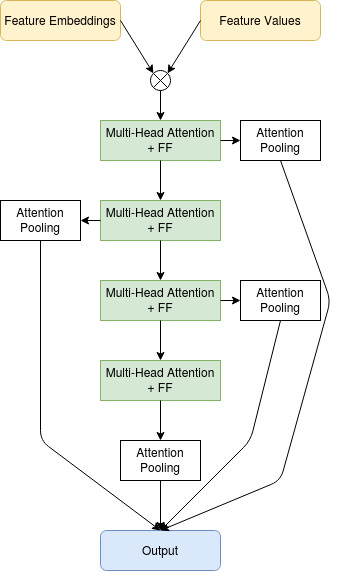
预训练
在预训练步骤中,我们使用完整的未标记数据集,输入特征的损坏版本,并训练模型来预测未损坏的特征,类似于在去噪自动编码器中所做的操作。
监督式训练
在训练的监督部分,我们在编码器部分和输出端之间添加跳过连接,并尝试预测目标。
实验
在接下来的实验中,我们将使用四个数据集,其中两个用于回归,两个用于分类。
Sarco:有大约 5 万个样本,21 个特征和 7 个连续目标。
Online News:有 4 万个左右的样本,61 个特征和 1 个连续目标。
Adult Census:有大约 4 万个样本、15 个特征和 1 个二元目标。
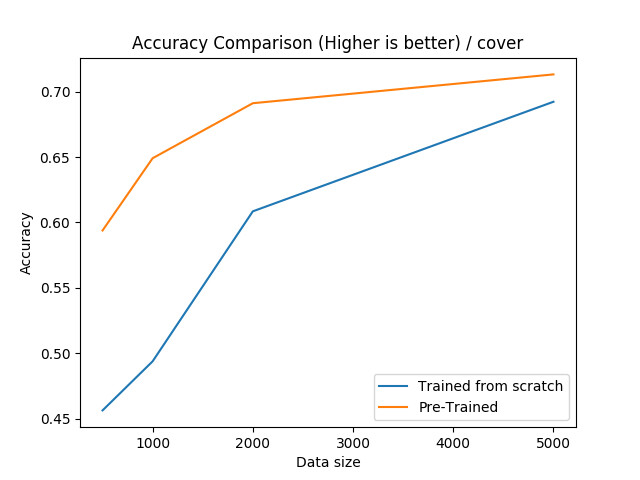
Forest Cover:有大约 50 万个样本,54 个特征和 1 个分类目标。
我们将比较一个预训练神经模型和一个从零开始训练的神经模型,将重点关注地数据状态下的性能,这意味着几百到几千个标记样本。我们还将于一个流行的名为lightgbm的梯度提升实现进行比较。
Forest Cover:
Adult Census:
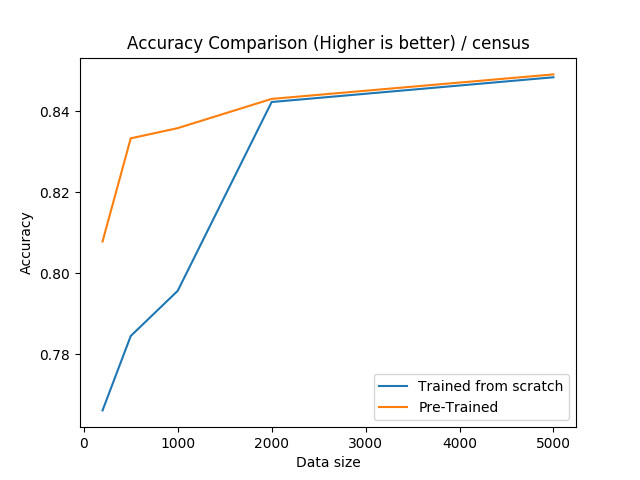
对于这个数据集,我们可以看到,如果训练集小于 2000,那么预训练是非常有效的。
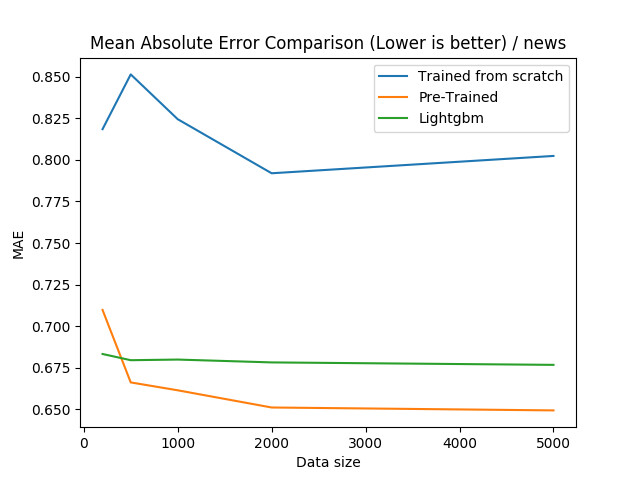
Online News:
对于 Online News 数据集,我们可以看到,预训练神经网络是非常有效的,甚至在所有样本大小为 500 或更大的情况下都超过了梯度提升。
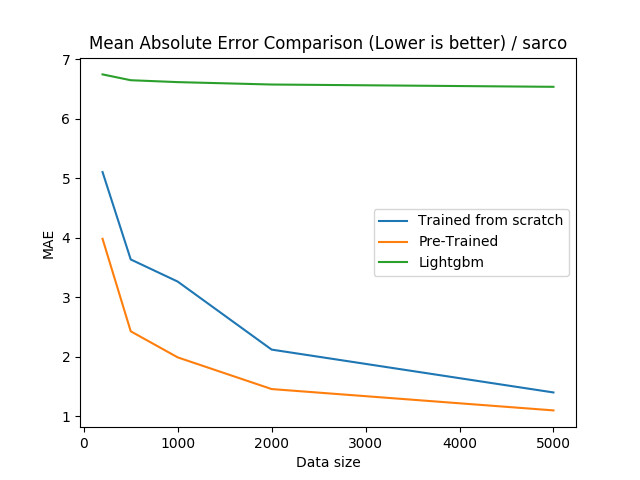
对于 Sarco 数据集,我们可以看到,预训练神经网络是非常有效的,甚至在所有样本大小的情况下超过了梯度提升。
旁注:用于重现结果的代码
重现结果的代码可以在这里找到:
https://github.com/CVxTz/DeepTabular
使用这段代码,你可以很轻松地训练分类或回归模型:
结论
在计算机视觉或自然语言领域,无监督预训练可以提高神经网络的性能。在本文中,我们展示了它在应用于结构化数据时也能起作用,使其在低数据环境与其他机器学习方法(如梯度提升)具有竞争力。
作者简介:
Youness Mansar,供职于 Fortia Financial Solutions 的数据科学家。巴黎中央理工学院(Ecole Centrale Paris)应用数学硕士学位和巴黎-萨克雷高等师范学校(École normale supérieure Paris-Saclay)机器学习硕士。作为 Fortia 的数据科学家,曾参与过多个涉及自然语言处理和深度学习的项目。
原文链接:

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论