

北京时间 2023 年 3 月 23 日 11:00,在英伟达 GTC 开发者大会上,来自快手的软件架构师梁潇分享了题为《针对大型推荐模型的性能优化》的演讲,介绍了快手如何通过平衡 CPU 和 GPU 的工作负载,实现大型推荐模型的性能优化。
在本文中,我将分享改进大模型推荐服务的一些经验——包括如何通过平衡 CPU 和 GPU 之间的工作负载,使得资源利用更加平衡,并提高系统吞吐。也希望能提供一些在日常工作中充分利用 GPU 算力的经验。
快手作为热门的短视频平台,日活用户就达到了 3.6 亿,日均时长为 129 分钟。为了提高用户体验,我们需要在个性化推荐领域做出非常多的努力。
与业界很多场景的推荐方案不同,我们的推荐服务主要面临两个挑战:
首先我们必须提供实时训练,以确保新近上传的视频可以在短时间内被推荐出来;
其次是模型的规模——个性化推荐需要大量特征进行准确预测,从而导致模型非常庞大。
例如,我们的精排模型使用了超过 1000 亿个特征,大约 1.9 万亿个稀疏参数。对于这样一个模型,常规的做法导致 80% 以上的时间都花在 CPU 计算上(包括特征抽取和 Embedding 处理),而只有 20% 的时间用于模型推理。这导致整个系统是一个高度内存密集型的系统。如果我们仅仅将模型推理部分移到 GPU 上,CPU 仍然会是整个系统的瓶颈,导致 GPU 的利用率受到限制。
为了解决这些问题,我们对这个系统做了很多改进:消除 CPU 瓶颈的最基本的想法是将 CPU 工作负载转移到远程服务器上。
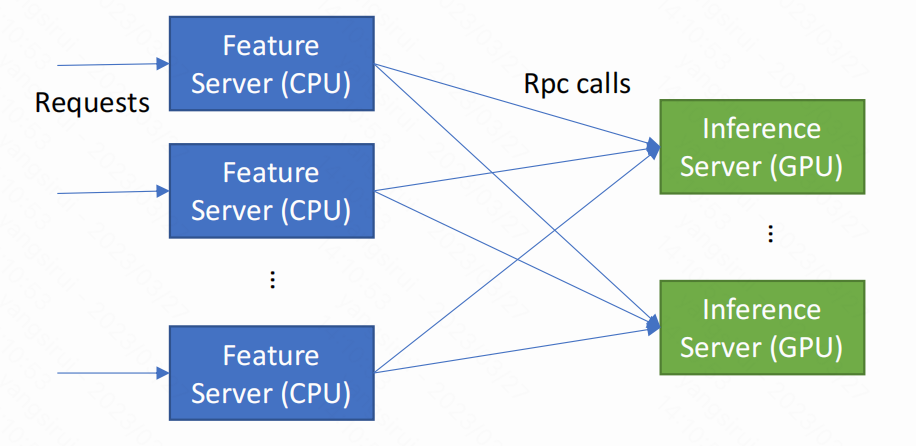
有了这些远程服务器,我们可以很容易地通过调整两种服务器的实例个数来平衡系统,从而最大限度地减少对现有代码的修改。然而,在实际工作中,这种方法并不奏效。
首先,因为模型特征的数量很大,会导致这两种服务器之间的网络流量很高。
其次,为了处理网络数据包,GPU 服务器也会承担额外的内存访问开销,从而导致实际性能收益降低。我们对此做过评估,远程服务器的方案会对系统带来 20% 的额外开销,效果并不理想。
另外一种方案是通过平衡 CPU 和 GPU 的工作负载来优化整个系统——所有的工作都在同一台服务器上完成。这样做非常易于部署,并能同时充分利用 CPU 和 GPU 资源。这个方案的实现关键是:将部分负载转移到 GPU 上。为了做到这一点,我们首先要深度于优化 CPU 算法,并且提升模型在 GPU 上推理的效率。推理所需的时间越少,就意味着有更多的 GPU 算力可以用来承载从 CPU 上迁移的算法。此外,我们还尝试在 GPU 端缓存数据,从而减少对 DRAM 的访问量。
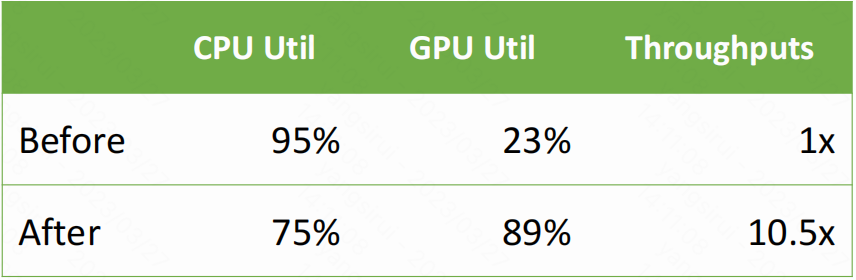
在实施这些优化之后,GPU 利用率从 20% 大幅提高到近 90%,整个系统的吞吐量提高了 10 倍以上。
大家可以先看一下系统的整体流程。
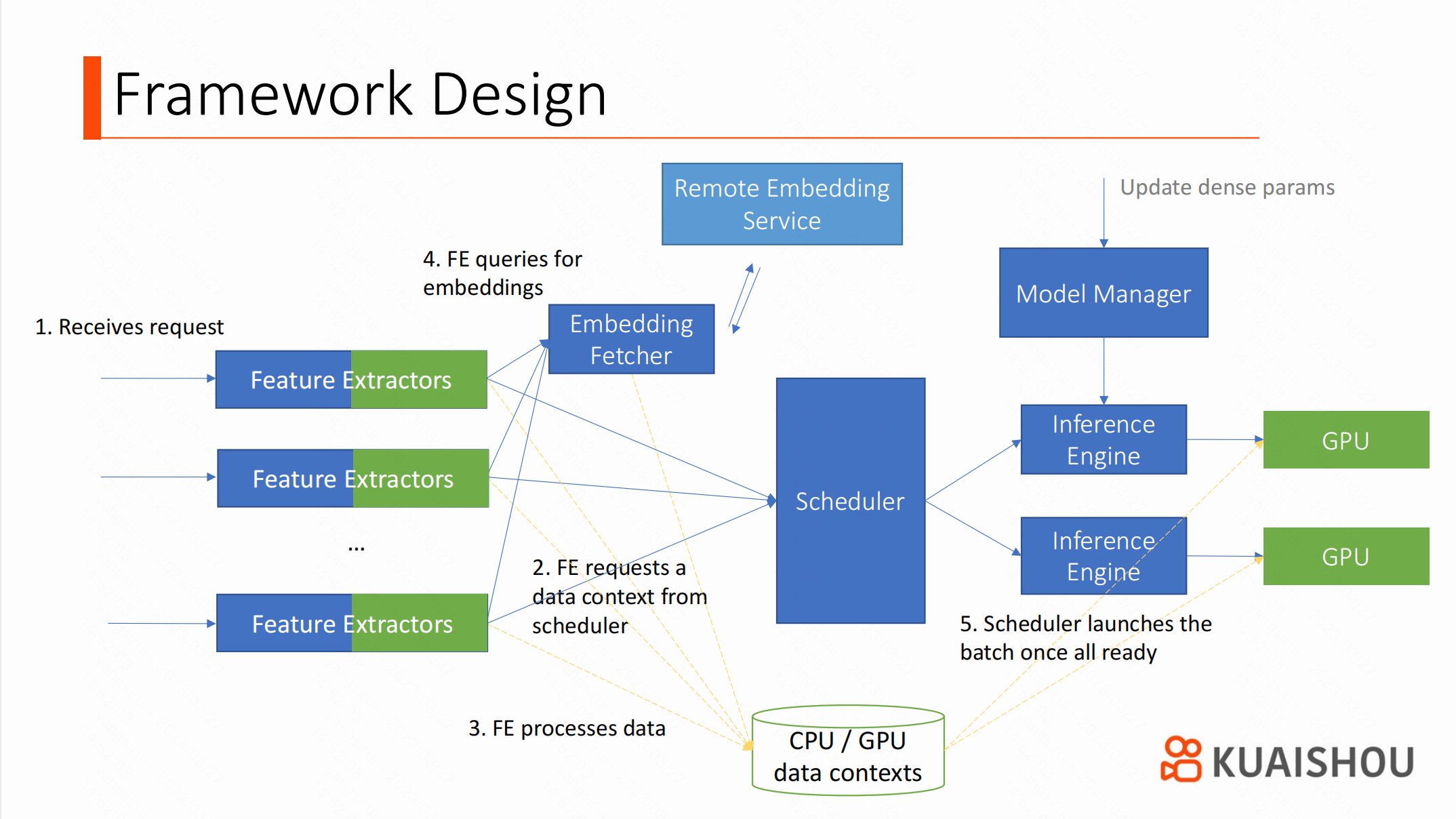
当服务接收到一个请求的时候,Feature Extractor 会向调度器请求 Data Slots。Data Slot 是 Data Context 的一部分,而一个 Data Context 可以理解为批任务(Batching)的数据存储单元,它被同时映射到 CPU 和 GPU 地址段上,因此调度器可以将 Context 中的数据在 CPU 和 GPU 之间自由迁移。调度器等这个 Data Context 填充完毕,就会将它发送到推理引擎。
与很多方案不同,在特征抽取开始之前,Data Context 就已经分配好了。虽然这会导致分配更多的内存(因为占用时间变长了),但是它让调度器对这个批任务有了更加充分的信息,可以选择更好的推理策略。特征抽取是在 CPU 或 GPU 上运行的算法,运行结果也可以直接保存在 GPU 内存中。在引擎部分,我们同时支持 TensorRT 和 Tensorflow。TensorRT 性能较好,但因为 Tensorflow 的兼容性更好,我们仍然需要它做一些对性能不太敏感的实验或验证。
在整个系统中,调度器(Scheduler)是最为关键的组件:因为我们需要对请求进行打包批处理(Batching),从而提高 GPU 的利用率。然而,在不同的时间段,每个请求中的候选视频个数并不均匀。调度器需要将请求定向到不同的 Batch,以确保尽可能将每个 Batch 填满。
为了提高性能,我们使用的是 Fixed-Size Model 进行推理(即输入 Tensor 的 bs 维度是固定的,不能改变),然后再通过调度器加载多个不同 Batch Size 的模型。例如,如果有 5 个请求,总计 200 个候选视频组成了 Batch,我们可以使用一个 bs = 256 的模型来推理。如果有 900 个候选视频,则会选择 bs = 1024 的模型。调度器负责维护不同 bs 的模型,并根据不同批次的大小选择合适的模型。
其次,调度器需要支持 dense 参数的实时更新,因此需要能够降低更新时对服务稳定性的影响(尤其是当有许多模型实例一起服务时,这种影响更加明显)。最后,调度器需要在内存密集型系统中考虑 NUMA 和 PCI-e 的亲和性。跨 NUMA 访问对系统延迟和吞吐的影响很大,调度器需要知道处理线程在哪个 CPU 上,并尽量把结果放在相应的 NUMA 节点上。根据测试,我们设计的调度器的吞吐量大约是 Tensorflow-Serving 的 2 倍。
TensorRT 的性能很好,但它对算子的支持能力有限,因此加载模型相对复杂。目前,官方并不提供从 Tensorflow 到 TensorRT 的解析器,我们实验后决定不从 ONNX 模型进行解析。最主要的原因是希望保留 Tensorflow 中的高语义运算符,这些运算符更易于编写 Kernel Funsion。
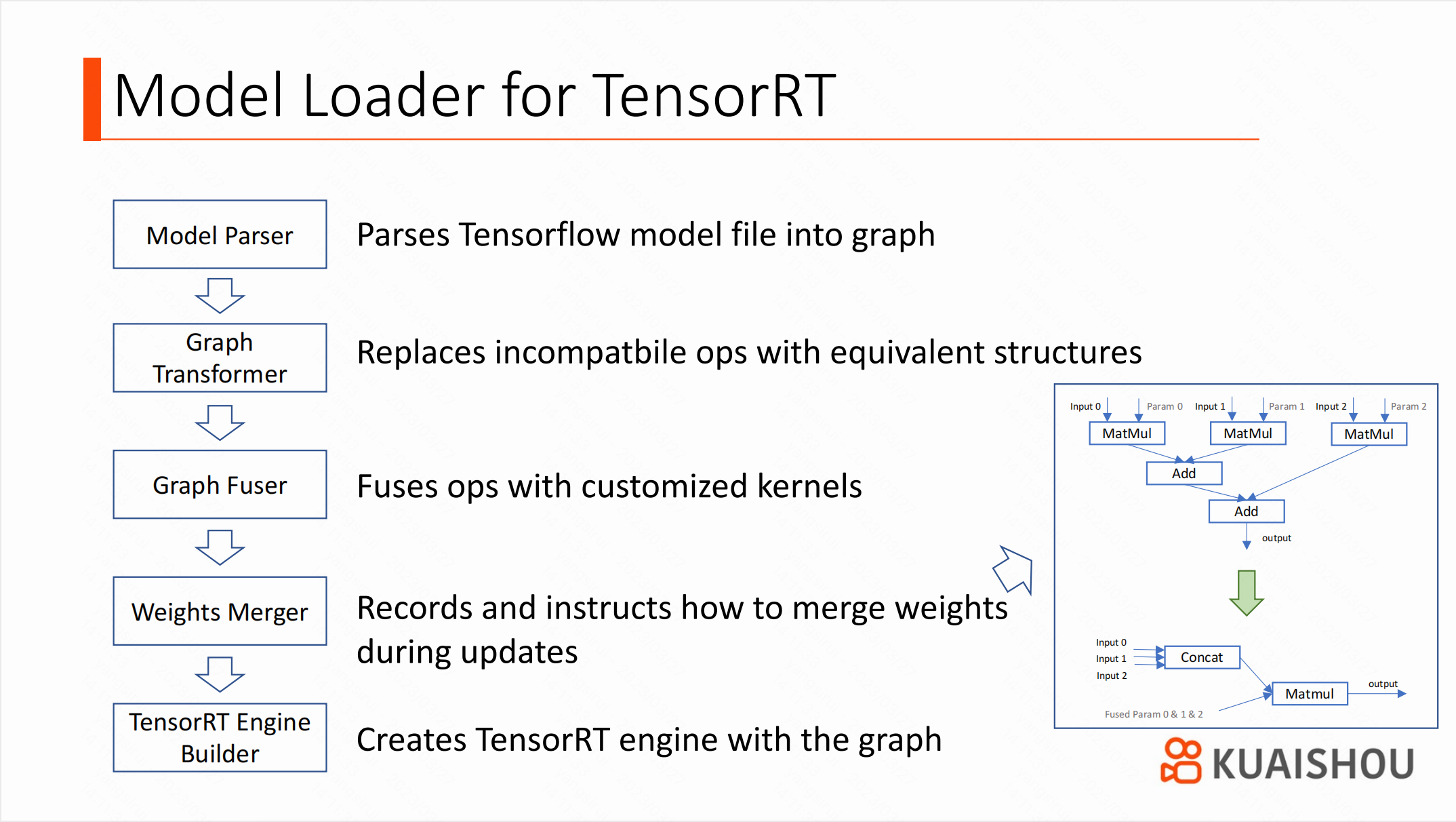
我们设计的模型加载器包含多个模块:首先是一个简单的 Parser,将 Tensorflow 模型文件解析成内存中的图结构(Graph),然后将图传递给 Graph Transformer,后者用来解决算子不兼容问题。假设某个算子不被 TensorRT 支持,Transformer 就会进行基于规则进行局部搜索,以确定是否能将某个包含这个算子的子图替换成另一个完全等价、且与 TensorRT 兼容的子图。Graph Fuser 用于算子融合,但对于实时更新的系统,有一些需要进行权重变换的融合并不容易实现。例如,右图所示的融合方式,需要将权重融合到一起。Weights Transformer 会记录这些融合步骤,并在参数更新期间按照这些步骤依次执行,从而保持训练侧不需要改变。经过这些步骤之后,Graph 就可以被 TensorRT 加载了。Builder 会负责将其转换成 TensorRT 的 Engine。
在针对 TensorRT 的性能调参中,我们总结了一些相关经验以供参考。或许在不同的项目里面,其他的参数配置性能更好,所以建议在做出决定前尝试每个参数。
首先,我们发现 Model Refit 对于实时更新权重更加友好。因为 Model Reload 非常耗时,从而导致更新期间的 P99 时延升高。即便使用了 TensorRT 8 中的 Timing Cache 机制,耗时仍然不可接受。然而,开启 Refit 会禁用掉一些 Point-wise Fusion,后续需要手工实现这些 Fusion。
其次,我们更加推荐使用 Explicit Batch,而不是 Implicit Batch。不仅因为 Explicit Batch 在设计图时更加灵活,还因为它的性能更好——如果模型图中的 shape 是固定的,TensorRT 可以优化得更好。缺点如前所提,如果使用 Explicit Batch 就需要调度器加载不同 Batch Size 的多个模型实例以适应不同 Batch。
此外,我们没有使用 Dynamic Shape,因为在项目实际测试中,Dynamic Shape 的性能比 Fixed Shape 低。使用如上设置后,TensorRT 在大部分场景下比 TensorFlow XLA 快 20%。
在 GPU 中缓存 Embedding 也是减少 CPU 负载和内存访问的有效方式。由于 Embedding 数量很大,我们使用远程服务器存储,本地使用了 Embedding Cache 的机制来降低网络访问量,这种方式还减少了远程调用过程中网络包解析带来的带宽影响。在我们的系统中,使用了 1GB 的缓存大小,就已经缓存了大约 60% 的 Hot Embedding。为了进一步减少 CPU 的工作量,我们将 Embedding 量化为 8bit,并且没有使用 LRU 的更新策略。

如下是一些测试结果:与完全没有缓存的版本相比,如果完全缓存在 CPU 内存中,可以节省 5% 的 CPU 利用率。这主要来自远程调用量的降低。如果将 Embedding Data 转移到 GPU 上,可以再节省 5% 的 CPU 利用率,以及 50% 的 H2D 带宽。如果将 Cache Index 也转移到 GPU 上,效果将更加明显。这项工作仍在进行着,从初步结果来看,与目前工业界解决方案相比,性能有 1.2 倍的改进。相关细节信息可以在我们的论文中查看。
将特征抽取算法转移到 GPU 上也可以改善系统性能。通常来讲,在 GPU 上实现特征抽取算法并不容易,因为这些算法有很多条件分支,难以并行化。然而,在我们的场景中,这件事情仍然很有意义:在特征抽取后,数据量会显著增加,导致 H2D 的同步时间变长。另外,访问 GPU 内存比访问 CPU 内存快很多,这对于内存密集型的系统有明显的收益。 此外,迁移后 CPU 的工作量降低可以进一步提高系统各个运算单元的平衡。

例如,对于 Sum-Pooling 算法,最初的 CPU 版本改写成 GPU 版本后,CPU 内存访问减少了近 1GB/s,耗时降低了 45%。如果对实现高性能的特征抽取算法有兴趣,可以参考 cuDF 和 Velox。
下图总结了各个性能优化方案的效果。
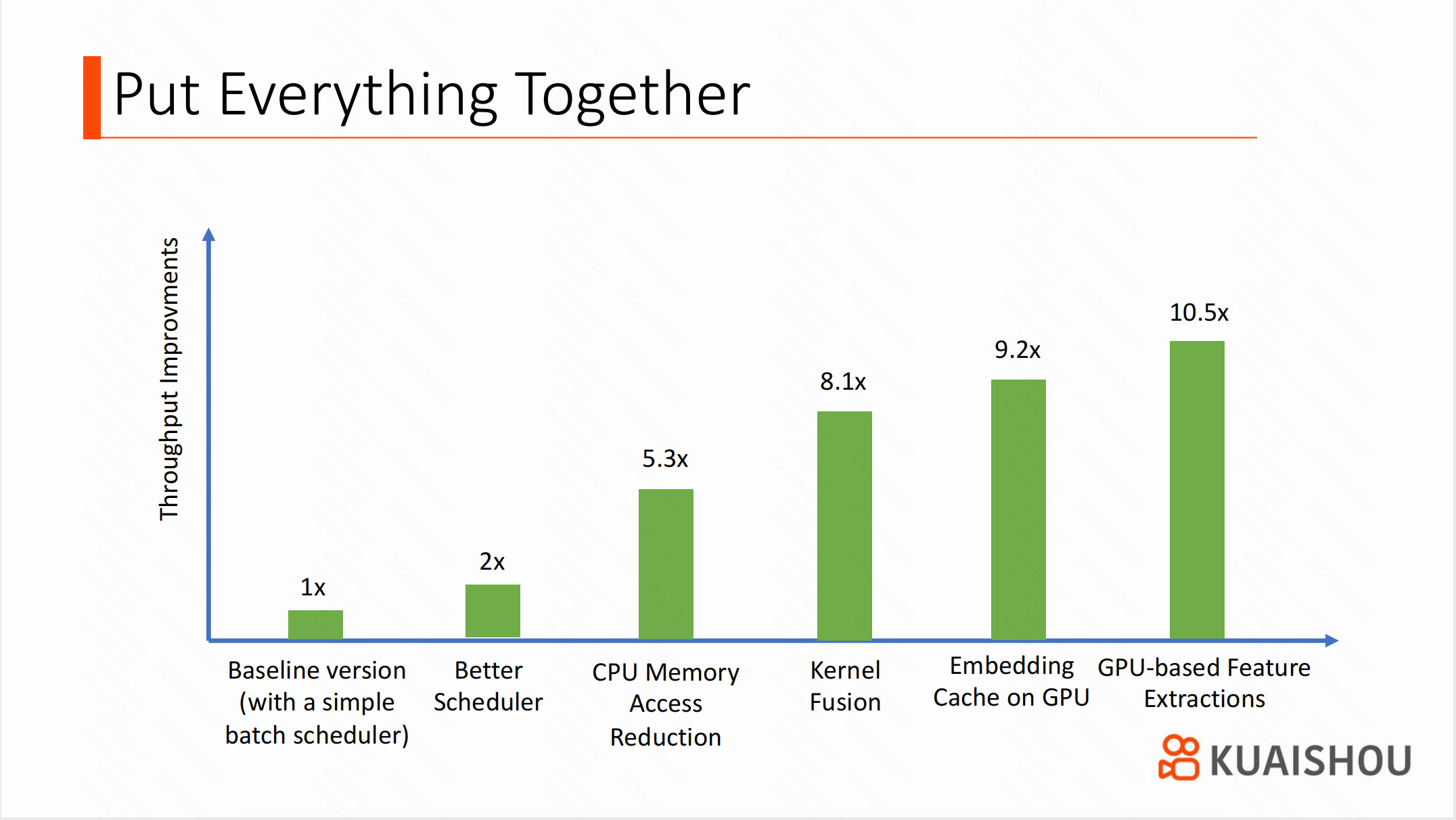
我们的主要任务是平衡 CPU 和 GPU 之间的工作负荷,因此需要迭代式地对 CPU 和 GPU 代码进行优化。比如,在进行 Kernel Fusion 之前,我们花了大量精力优化 CPU 端的算法,大幅降低了内存访问压力。否则,在 GPU 上优化的性能收益会因为 CPU 瓶颈被掩盖。在图中,可以看出 Scheduler 是其他优化的基础,之后我们通过减少 CPU 内存访问和 GPU 上 Kernel Fusion 的方式提升了整体的吞吐。当这些事情做完之后,CPU 仍然是系统的瓶颈。我们尝试通过在 GPU 上进行数据缓存和将特征抽取算法转移到 GPU 上来减少 CPU 的工作量。上述优化总计优化了系统整体吞吐约 10.5 倍。
以下为内容的总结。我们讨论了几种改善内存密集型系统吞吐量的方法。
首先,需要优化 CPU 算法,降低访存量;
其次,需要提高 GPU 推理效率,使 GPU 腾出算力承载更多算法;
再次,可以将 CPU 的算法迁移到 GPU 上,减轻 CPU 的工作压力;
最后,在 GPU 中缓存数据可以减少 H2D 的同步时间,并降低 DRAM 的访问量。
以上这些优化方法,可以使得整体系统更平衡,并帮助我们在成本可控的情况下,为用户提供更好的服务。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论