
1.概述
人工智能技术迅猛发展,人机语音交互更加自然,搭载语音唤醒、识别技术的智能设备也越来越多。语音唤醒在学术上称为 keyword spotting(简称 KWS),即在连续语流中实时检测出说话人特定片段(比如:叮当叮当、Hi Siri 等),是一种小资源的关键词检索任务,也可以看作是一类特殊的语音识别,应用在智能设备上起到了保护用户隐私、降低设备功耗的作用,经常扮演一个激活设备、开启系统的入口角色,在手机助手、车载、可穿戴设备、智能家居、机器人等运用得尤其普遍。
唤醒效果好坏的判定指标主要有召回率(recall,俗称唤醒率)、虚警率(false alarm,俗称误唤醒)、响应时间和功耗四个指标。召回率表示正确被唤醒的次数占总的应该被唤醒次数的比例。虚警率表示不该被唤醒却被唤醒的概率,工业界常以 12 或者 24 小时的误唤醒次数作为系统虚警率的评价指标。响应时间是指用户说出唤醒词后,设备的反应时间,过大的响应时间会造成较差的用户体验。功耗是指唤醒系统的耗电情况,多数智能设备都是电池供电,且需要保证长时续航,要求唤醒系统必须是低耗能的。一个好的唤醒系统应该保证较高的召回率、较低的虚警率、响应延时短、功耗低。
唤醒技术落地的难点是要求在低功耗下达到高性能要求。一方面是目前很多智能设备为了控制成本,搭载的都是一些低端芯片,计算能力有限,需要唤醒模块尽可能的减少计算计算量以减少能源消耗;一方面用户使用场景多种多样,设备也常没有经过专业声学设计,远场、大噪声、强干扰、高回声、高混响等情况下仍然面临召回率低、虚警率高的问题。
针对此问题,腾讯 AI Lab 近期发表一篇论文,针对复杂声学环境,特别是噪声和干扰人声场景,对送给唤醒模型的声学信号进行前处理,以提升其语音信号质量。本论文已被 Interspeech 2020 接收。

很多智能设备安装有多个麦克风,因此多通道的前端处理技术被应用到唤醒的前端信号处理中。当目标说话人与干扰声源分布在不同方向时,多通道的语音增强技术,例如波束形成(beamformer), 能够有效的增强目标说话人,抑制其它干扰声源。但是这一做法依赖较准确的目标说话人方向定位。在实际环境中,由于有干扰声源的存在,使得很难从带噪数据中准确估计目标说话人的方位,特别是当有多人在同时说话时,也无法判断哪一个是目标说话人。因此本文采用“耳听八方” (多音区) 的思路,在空间中设定若干待增强的方向(look direction),然后区别于传统的波束形成做法(这个做法已发表于 ICASSP 2020 [1]),本文提出了一个基于神经网络的多音区(multi-look)语音增强模型,可同时增强多个指定的方向声源。这些多个方向增强输出的信号再通过注意力机制进行特征融合送予唤醒模型。由于前端的增强是通过神经网络处理的,这样多音区的增强模型与唤醒模型可以进行联合优化,实现真正的前后端一体的多音区语音唤醒。
基于神经网络的多音区语音增强模型是首个完全基于神经网络的多音区语音增强模型。相比于特定方向的语音增强,本文提出的模型可同时增强多个方向声源。同时这种基于神经网络的方法,在性能上显著优于基于传统的波束形成做法。完全基于神经网络的多音区前端,与唤醒模型联合训练,前后一体的做法进一步提升模型的鲁棒性和稳定性。此模型适用于多麦克风设备的语音唤醒。
以下为方案详细解读。
2.方案详解
传统的多音区语音处理的思路,是在空间中设定若干待增强的方向(look direction),每个方向分别应用一个波束形成,增强这个方向的声源,最终本文将每个方向增强输出的信号轮流送给唤醒模块,只要有一个方向触发唤醒,则唤醒成功。这种基于多音区的多波束唤醒技术大大提高了噪声下的唤醒性能,然而需要多次调用唤醒模块,因此计算量较单路唤醒也成倍增加,功耗变大制约了应用。针对这一情况,作者在早前一点的工作中[1]将注意力(attention)机制引入到唤醒框架下,如图 1 所示,多个 look-direction 增强的信号提取特征后通过 attention 层映射成单通道输入特征,再送入单路唤醒网络层,与单路唤醒相比仅仅增加了一层网络,既保证了唤醒性能,计算量又大大降低。
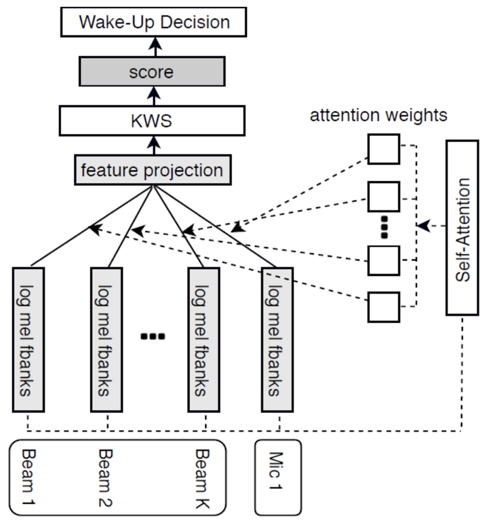
图 1:基于多波束特征融合的唤醒模型[1]
以上介绍的基于波束形成的多音区唤醒[1],前端的信号处理(波束形成)和唤醒模块还没有做到联合调优。因此本文提出了一个基于神经网络的多音区语音增强模型。该模型读取单个通道的语谱特征和多通道的相位差特征,同时根据预设的若干音区方向(look direction),作者分别提取对应的方向特征(directionalfeature)。这些方向特征表征每个时频点是否被特定音区方向的声源信号占据,从而驱动网络在输出端增强距离每个音区方向最近的那个说话人。为了避免因为音区和说话人的空间分布导致目标说话人经过多音区增强模型处理后失真,实验中使用一个原始麦克风信号与多个方向增强输出的信号一起通过注意力机制进行特征融合送予唤醒模型,由于前端的增强是通过神经网络处理的,这样多音区的增强模型与唤醒模型可以进行联合优化,实现真正的前后端一体的多音区语音唤醒。完整的模型结构在图 2 中描述。
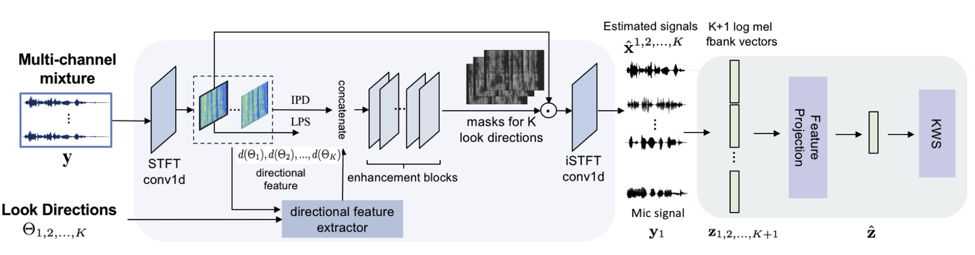
图 2: 本文提出的基于神经网络的多音区语音增强和唤醒模型[2]
图 3 是一个多音区增强的实例。两个说话人分别位于图(a)所示位置,麦克风采集的两人同时说话信号谱如图(b). 作者设定了 4 个待增强的方向(0 度,90 度,180 度和 270 度)。多音区增强模型将会在 0 度和 90 度方向增强蓝色说话人,180 度和 270 度方向将会增强黑色说话人, 增强后的 4 个方向语谱如图(c)。
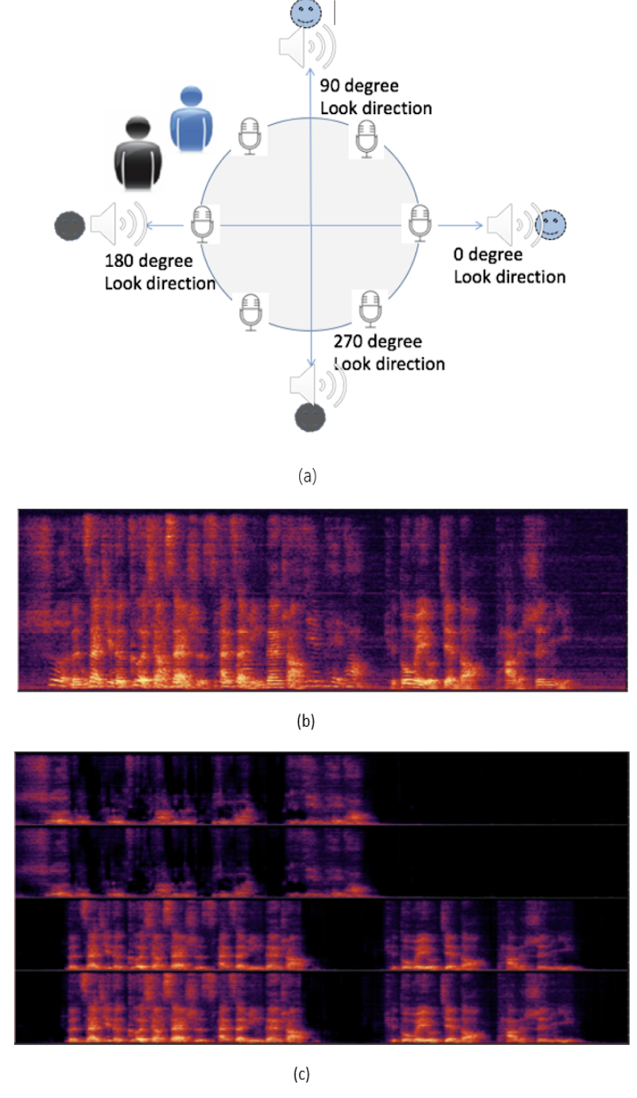
图 3: 多音区增强网络输出实例
在图 4 中,作者对比了基于神经网络的多音区增强唤醒模型与基于波束形成的多音区增强唤醒模型和基线的单通道唤醒模型。可以看出特别是在小于 6dB 的信干比声学环境下,本文提出的做法显著超越其它方法。不同方法唤醒率测试均在控制误唤醒为连续 12 小时干扰噪声下 1 次的条件下进行的。
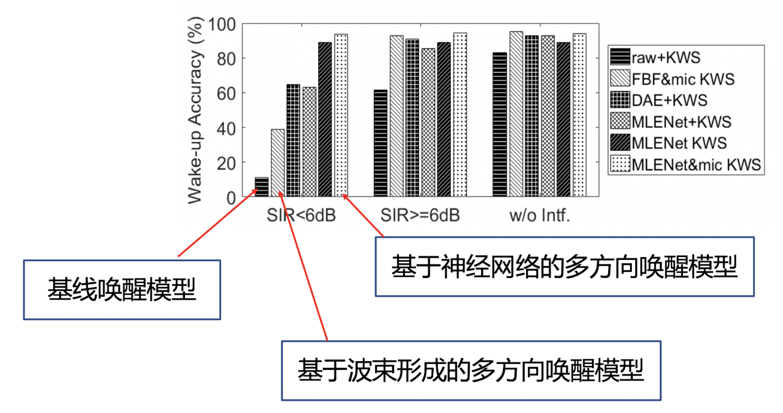
图 4:多音区唤醒模型的性能对比
3.总结及展望
本文提出的多音区语音增强和唤醒的做法,大幅降级了唤醒前端语音增强与唤醒结合使用的计算量,在未知目标声源方位的情形下,同时增强的多个方向声源信号的特征融合可保证目标语音得到增强,给准确的唤醒提供了保障。在论文中测试的多说话人带噪声的复杂声学环境下,唤醒率达到 95%。
多音区的语音增强模型已经与声纹模型结合,形成多音区的说话人验证,提升声纹系统在复杂远场声学环境下的鲁棒性。未来这一工作可与语音识别等其它语音任务相结合。
参考文献:
[1] Integration ofMulti-Look Beamformers for Multi-Channel Keyword Spotting,Xuan Ji, Meng Yu, JieChen, Jimeng Zheng, Dan Su, Dong Yu, ICASSP 2020
[2] End-to-EndMulti-Look Keyword Spotting, Meng Yu, Xuan Ji, Bo Wu, Dan Su, Dong Yu, Interspeech2020




