

某日上午,小集购买a产品失败,页面弹出“系统异常,请稍后重试”的报错,便联系了技术团队的开发小成。
“小成,我刚才尝试买a产品一直显示系统异常,是不是有什么问题呢?”开发小成接到电话后,迅速着手排查,同时也收到了系统监控平台的告警。
小成立刻登录系统应用服务器,发现交易耗时在8s左右。经过一系列紧张的故障排查和恢复工作,虽然过程艰难,但最后还是成功地恢复了业务。
解决过程
【DAY1】
“交易的耗时为什么会这么久?是不是内存资源不足引起的?”
小成立即查看了应用服务所在的公有云服务器的资源状态,发现服务器的 VM 系统大量 OOM 报错,即使尝试重启 Tomcat,也是失败。
“是不是有什么业务层的程序大量消耗资源导致?”
带着这个问题,小成继续一步步排查。半小时左右,小成发现合作机构的前置 T 应用上有大量的 Close_wait 连接,应用提示 open too many files。大量 Java 的应用报错 Java.io.IO.Exception: Broken Pipe.
为了尽快恢复业务,小成尝试重启了 Tomcat 应用,但错误依旧存在,尝试修改 open files 和 max user processes 参数,未见明显效果。小成又再试着在弹性服务器上分别 Telnet 本地端口和对方端口甚至重启了服务器。这些都无济于事,错误依然存在。
发现这些常用恢复方式不起作用,小成调整思路,看业务平台是不是有问题。果不其然发现应用平台上持续大量业务报错,报错信息集中在产品中心的捞取数据同步的定时任务。
“难道是这个定时任务的数据量增大导致的?”
小成确认了当日的定时同步数据的任务业务量级,发现每分钟 1 万左右,平均每秒(QPS)300~350 之间(与日常调用量持平)。
“既然定时任务的量级未变,为什么会大量报错?”
业务恢复争分夺秒,小成申请停掉可疑的定时任务,发现不见效,尝试业务流量切换到备用集群观察。
流量切换后,问题恢复了。
“切换到备用集群竟然可以恢复,难道是老集群的问题?”
想着定时任务还停着,小成建议申请恢复定时任务,数据同步定时任务再次被拉起。
这时已经过去了近两个小时。虽然切换新集群业务恢复,定时任务也恢复运行,但根本原因还是没查明。小成开始复盘整个过程,思考各个疑点。
为什么数据同步定时任务会大量报错?虽然报错,为什么切换到新集群会恢复?
这时电话又响起了:“小成,备用集群也出事了!”
小成脑子快速闪过,“基本确定是定时任务的问题了”。
小成申请再次停止数据同步任务,经同意后,立即执行。执行后,业务开始逐渐正常。时间已经到了下午。
小成和团队人员紧急召开复盘会议,基于业务影响可能性的评估,决策对业务主链路进行隔离。当天下午紧急对业务链路进行隔离操作,并且在 1 个多小时内完成业务流量验证通过。
不知不觉一下午时间就这样过去了,小成理了理思路,决定把问题来龙去脉理清楚,于是发起了次日集中问题排查的会议邀约,参与人员涉及多方技术团队。
【DAY2】
通过对监控数据的梳理,小成发现当天机房的负载均衡服务器和弹性计算服务器有异常流量,且网络还有丢包情况。但是这流量的来源无法查明。另外 T 应用 hang 住的时候关系型数据库服务上的耗时急剧增加。
【DAY3~DAY4】
基于这一点,技术团队就此问题进一步深挖。通过复查所有相关 SQL 语句和查询数据量以及数据库数据量,试图找到病根,但是最终发现并没有异常。
那到底是什么变更导致数据库响应慢的?
技术人员再次调整思路,尝试在 SIT 环境 (线下测试环境)mock SQL 查询超时的情况,果然,重现了关系数据库服务查询耗时急剧增加的现象。并且 T 应用上出现大量 Close_wait 的连接,直到应用服务器上的资源耗尽,导致应用 hang 住。
【DAY5】
业务一切正常,但是 SQL 缓慢的原因还无法具体定位。
不过,业务涉及数据同步定时任务查询的 SQL 倒是还存在不少的优化空间,业务技术人员在当晚就通过索引优化的方式固定执行计划。
【DAY6】
第 6 天,小成邀请了数据库团队和公有云等技术专家团队参与到了问题排查中。
终于问题的根源逐渐水落石出,数据库和云服务器专家们就这个可疑的数据库服务响应慢的问题进行层层排查。
深入分析
(1)应用服务器单台网卡为什么有大量异常流量?
这是因为服务器主机的日志同步机制运行时,会每 5 分钟读取一次日志,从而引起异常流量。
(2)应用服务端为什么会大量 Close Wait?
Close Wait 产生的原因在于数据库服务端等待超时后,主动断开连接,如果应用服务端在数据库断开之后能够响应及时关闭,就不会积攒大量 Close Wait,但是应用服务端在当天问题发生时并未马上关闭无用连接,所以大量的 CloseWait 状态过多,导致主机资源耗尽。
当天排查也发现合作机构前置应用在网关关闭连接后,业务查询还未结束时,前置应用的网关连接不会关闭。这一事实佐证了上面这一点。
(3)应用服务端为什么会大量报错“open too many files”?
应用服务器可以 open 的文件数有上限,通常不会到达这个阀值。如果出现那可能就是有文件句柄没有及时释放。由于前面有大量处于 close_wait 的 tcp 连接,每个连接对应一个套接字(socket),也对应一个文件句柄,这是导致报错的主要原因。
(4)数据库服务的耗时是否和数据库主机的 CPU 利用率有关?
分析:
数据库主机的各个逻辑 CPU 在问题发生期间的监控数据都是正常,该因素排除。
监控佐证:
图 3-1 所示是数据库实例采集到的 CPU 的平均利用率监控信息,从监控来看,并没有明显变化。
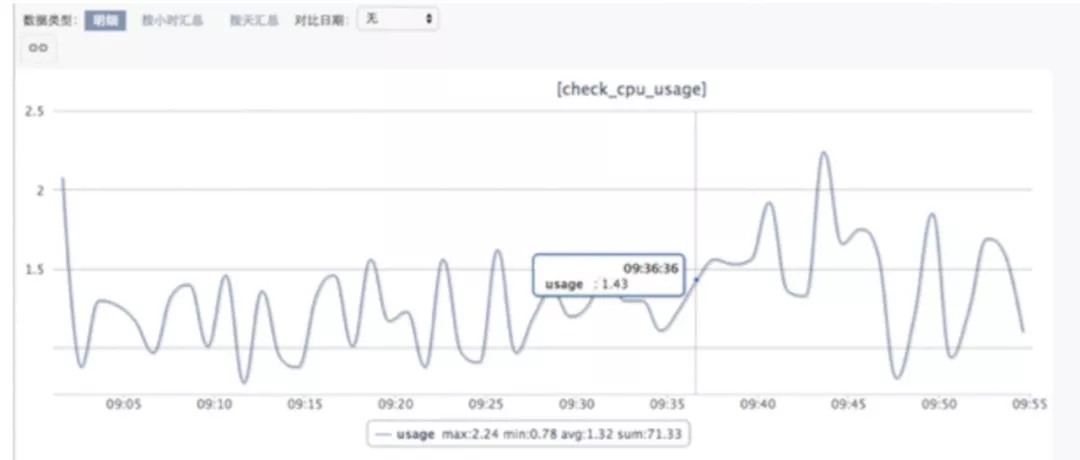
图 3-1 CPU 平均利用率
(5)会不会是数据库主机磁盘 IO 有问题?
分析:
磁盘 IO 监控包括每秒读写 IO 次数,每秒读写 IO 吞吐量、每个读写 IO 的平均响应时间,磁盘当前队列长度。
数据库服务的 DB 文件分为数据文件和日志文件,日志文件存放于 D 盘,数据文件存放于 E 盘,Tempdb 的文件在 D 盘。
模拟当天业务场景和大致时间点,从监控(如图 3-2 所示)可以看出,在 09:25 以前 D 盘的活动比较多,但总体都在正常范围。25 分之后,E 盘在 45 分左右有个高峰,但是峰值依然远低于磁盘的能力(最大 IOPS14000)。磁盘 IO 平均响应时间供参考。当磁盘 IO 压力过大或者出现访问问题时,那个响应时间会有值。正常情况下,数据都非常小(小于 1),总体来说数据库主机的 IO 负载也很低,此因素排除。
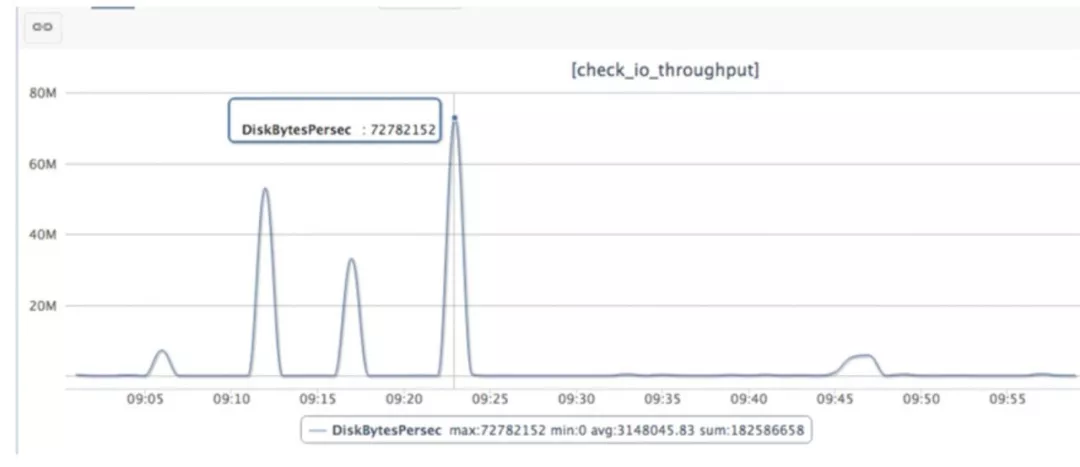
图 3-2 C 和 D 盘的每秒写吞吐量
(6)是不是和业务 SQL 性能有关 ?
分析:
关于 SQL 变慢,通过分析数据库日志发现,拉取同步数据的关键 SQL 缺乏正确的索引,进而导致其执行计划不是最优,理论分析这个执行计划也是不稳定的。随着业务同步数据的全量替换,以及表统计信息短时间内不能及时更新,SQLserver 可能会根据查询参数比对统计信息而调整执行计划。
推测在 09:35 左右,这个 SQL 的执行计划发生变化导致性能出现更差的情形,而高并发的访问加剧了这个性能的问题。这一点表现在 DB 上就是 CPU 利用率升高,CPU 利用率变高,反过来会影响 SQL 的性能(针对全体 SQL)。
09:37 前后相邻的两个诊断报告的等待事件表明 Buffer Latch 最大等待延迟也增加 180ms(这表示 Buffer Latch 等待更严重)。调用端观察结果就是 SQL 执行时间变长的 SQL 比例越来越多。
关于 SQL 变慢,还需要关注的是,相对于问题发生前一天,数据库连接增长了 300, CPU 利用率也同比增长很多,从现有的数据很难断定是访问请求增加导致实例压力变化,还是实例压力变化导致访问增多(触发重试逻辑)。
这是一个恶性循环的过程,根源就是 SQL 执行缺乏正确的索引且并发很高!
监控佐证(如图 3-3、3-4、3-5 所示)。

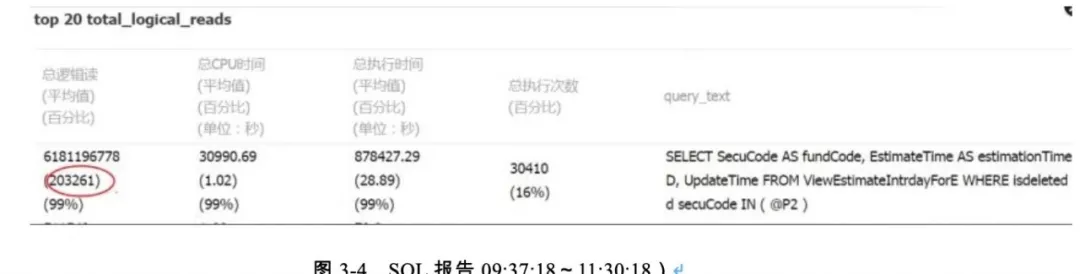
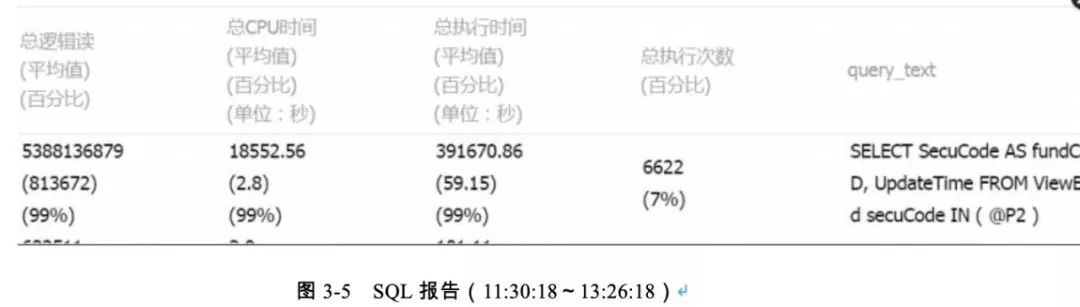
重点问题 SQL,SQL 请求很高,且没有走上合适的索引(如图 3-6 所示)。

图 3-6 问题 SQL
问题当日 09:02~09:37 期间总执次数:71163 次(实际从 09:25 开始),平均消耗时间 0.72s。
问题当日 09:31~09:56 期间总执次数:22914 次,平均消耗时间 16.0s。
分析:
视图 ViewEstimateIntrdayForE 的定义(如图 3-7 所示)。

图 3-7 视图定义
表 FundData.dbo.SecuCodeRelationSMCode 的索引(如图 3-8 所示)。

图 3-8 SQL 索引情况
小结
本文这个案例的发生,一层层剥开来看,最后还是 SQL 执行计划不佳引起。因为缺乏合适的索引,所以原 SQL 的执行计划很可能处于不稳定的状态,即 SQLServer 可能会根据压力状况、数据量、统计信息以及传参数值来判断当前的执行计划是否为最优,如果数据库基于内存中的信息判断有更好的选择(从数据库角度判断,这很可能是个更加错误的选择),就改变当前执行计划,从而导致性能上可能出现更大的延时,再加上高并发,就进一步放大了这一性能问题。
本文转载自技术锁话公众号。
原文链接:https://mp.weixin.qq.com/s/8uFKZcPWN2P4_BKhWHZmhg

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论