

今天,大数据、数据科学、机器学习分析不再只是热词,已经真实地渗透于生活方方面面。根据福布斯,到 2025 年,全球每年将会有 175 泽字节的数据产生。Kyligence 的诞生为企业带来了极速的大数据分析体验 。当企业要对大规模的数据进一步进行更为复杂的分析如对销售额进行预测时,传统的分析工具就捉襟见肘了 。
这篇文章将以基于 Spark 的分布式机器学习平台 Databricks 为例,为您提供一套从以 Kyligence 为数据源到分布式数据分析平台的高效无缝的解决方案。
对企业未来销量进行预测是一个很普遍的分析需求。分析师需要先以不同的时间粒度如日或月,或者是其他维度粒度如地区,商品等聚合数据,然后按不同的算法预测聚合后的数据。相类似的预测、分析场景还有很多,如运维数据的异常值检测,金融数据的反欺诈识别,销售数据的用户画像等。在数据被深入挖掘之前,都需按维度列或时间戳聚合数据。然而想顺滑地聚合如此海量的数据,并且深入挖掘数据并不简单。
对海量数据进行挖掘的难点
聚合大量数据,复杂度高,所耗时间长
当数据量呈规模式增加时,即使是执行一条简单的筛选查询也会消耗很多时间,并且查询语句复杂度越大,执行语句所花时间就会越长。因此,数据科学家稍调整筛选条件,就会重新陷入等待中。
分析维度的粒度很难随意变动
由于高额的查询成本,数据科学家们会更倾向于聚合有潜在关联的数据维度。这种前瞻性在提高数据科学家们分析效率的同时,也局限了他们的数据探索能力,导致错失发现一些不易察觉的数据规律的机会。
无法实现数据源到分析平台的无缝连接
目前,在大数据领域,数据科学家们最常用的预处理数据工具主要有 Hive,Spark,Pig,Scala 等。而如果想对这些数据进一步的分析,需要从这些工具中导出聚合后的数据,再将其导入到机器学习平台。导入导出看似为简单操作,实际上会打破分析人员工作的连贯性,尤其是当导入导出数据量过大时,他们的工作效率会大大降低。
机器学习工具复杂,生命周期难以管理
工具太过复杂、难以跟踪实验、难以重现结果、难以部署模型。很多企业已经开始构建内部机器学习平台来管理机器学习生命周期。但这些内部平台存在一定的局限性:典型的机器学习平台只支持一小部分内置算法或单个机器学习库。用户无法轻易地使用新的机器学习库,或与社区分享他们的工作成果。
解决方案:Kyligence + Spark
在分析师拉取数据之前,通过 Kyligence 将所需要的所有分析数据都已经以不同的维度、粒度提前聚合好,使得分析师们在极短时间内能直接获取数据。在获取聚合好的数据后,分析师们也无需先将数据导出,再导入专业的支持机器学习的分析平台,也无需再因为适配不同的机器学习方法而安装各种环境。而是直接在该专业的数据分析平台上获取数据,在适配好的环境中,用不同的方法进行近一步预测和分析。
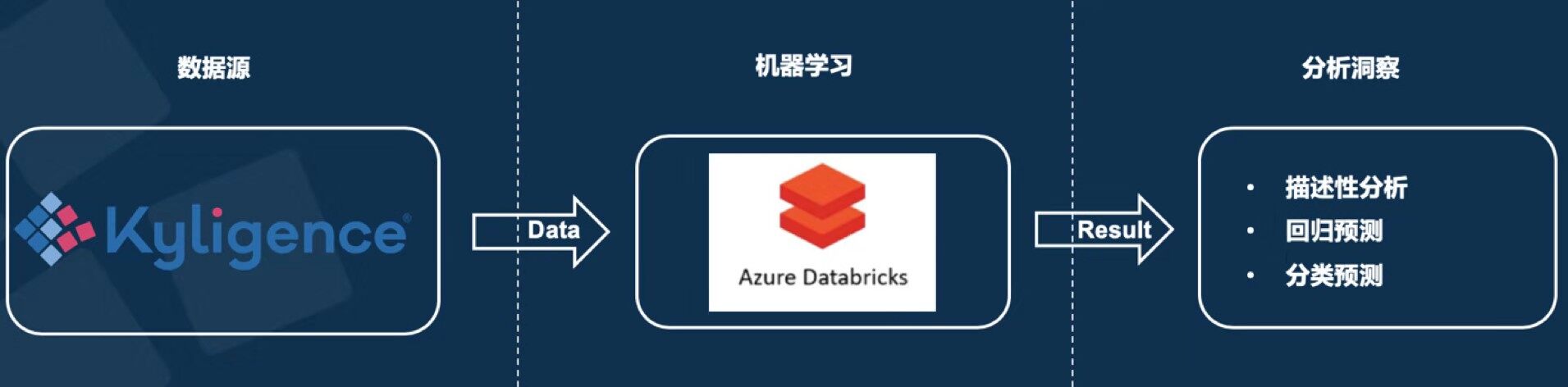
Kyligence 与 Databricks 数据处理流程
应用门槛低,学习成本小
大数据分析普遍会采用分布式存储及计算,使用者需要用了解 Java, Hadoop, Hive, Pig,Spark 等等大数据知识。而 Kyligence 为用户提供了 SQL 查询接口,Databricks 也提供了支持各种机器学习语言的环境,用户无需了解底层原理,就能处理分析海量数据,拥有极佳的用户友好度。
亚秒级查询,随意转换特征值
相较于传统的将数据聚合过程放在数据分析中,此方案在分析师分析数据之前已完成数据处理及聚合。Kyligence 可提前以不同的维度,维度粒度预聚合数据。因此,无论分析师要求获得以何种维度聚合的数据,都能在亚秒级内得到返回结果。数据量,时间成本不再是试错特征值的制约条件。
数据源与分析平台无缝连接
以往的大数据在被分布式计算后,如果想用机器学习进一步分析,往往需要将数据导出,再导入机器学习分析平台。而 Kyligence 和 Databricks 的组合允许用户直接从数据分析平台上获取数据,无需导入导出。在 Databricks 的 notebook 中,用户可通过 SQL 语句直接获取被 Kyligence 预聚合的数据,省去迁移数据,转换数据格式的麻烦。
专业机器学习分析平台
Databricks 基于 Spark 提供用户一个专业的分布式机器学习分析平台,支持完整的机器学习生命周期。为用户提供完备的机器学习环境,用户无需自配置环境就可使用各种流行算法。
应用案例
一家名为 “Contoso ”的企业 拥有超过 100,000 的产品,数据集就包含多个事实表和维度表,数据量最大的事实表包含 2 千万条在线销售数据。(Contoso 是微软虚拟的一家公司,其产生的数据主要用于模拟各种企业场景下的数据分析。)
分析目标:根据 2007 年 1 月到 2009 年 5 月 31 日的在线销售数据预测下半年的销售额
Step 1: 数据处理
先将数据导入 Kyligence 中,然后转到 Azure Databricks 的页面,通过 PyPI 连接 Kyligence,输入 SQL 获取聚合数据数据,并且这一过程的数据导入所耗时间不超过两秒。SQL 返回的数据集存储为 Pandas 数据表格,然后对该数据表格处理为我们想要的格式,即对销售量按月聚合,产生每月销售量的数据集。然后用 LSTM 进行销量预测。

step 2: 数据分析
生成模型训练数据集

训练集的窗口长度是指需要几个时间点的值来预测下一个时间点的值。在这里窗口长度为 1,即用 t 次的时间间隔进行模型训练,然后用 t+1 次的时间间隔对结果进行验证。数据集格式为:dataX 为训练数据,dataY 为验证数据。我们选取数据集中前 36 的数据作为训练集,后 6 的数据作为测试样本集。
LSTM 模型结构与参数设置

选定模型训练的 epoch(总的训练轮数)为 100 和 batch size(每次训练的样本数)为 1,并在 LSTM 层的输出后面加入一个普通的神经网络全连接层用于输出结果的降维。
step 3: 结果展示
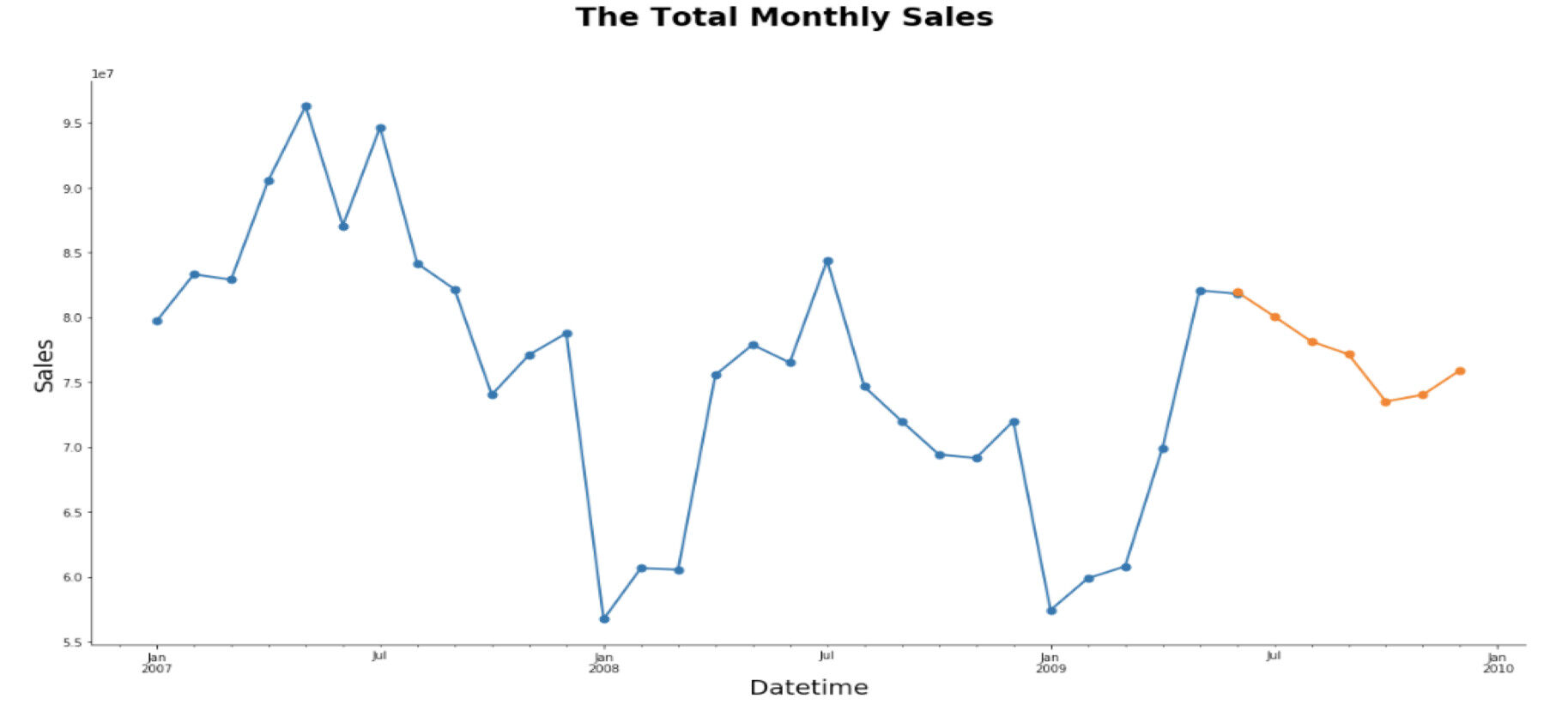
上图蓝线为真实值,黄线为预测值。可以看出最终的预测曲线与实际的曲线趋势情况基本吻合,销售量从每年的七月开始下滑,10 月会有反弹,且总体的销量趋势呈下滑状态,拟合效果很好,将原始数据的季节性,总体趋势及周期性都预测出来了。
当分析人员需要细化维度到产品时,如预测产品 ‘LitwareRefrigerator 24.7CuFt X980 Brown’ 2009 年下半年的销量,分析人员只需要修改 SQL 代码,就可重获聚合数据,操作简单,执行快速。
Kyligence 与 Apache Spark 可优化从数据源到数据分析平台的整套大数据机器学习生态环境,让大数据挖掘摆脱数据量的束缚,变得轻松高效。
本文转载自公众号 Kyligence。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论