

购物是我们日常生活的一部分,我们过去常在实体店购买商品,并咨询我们信任的人,如朋友、家人或店员。互联网彻底改变了我们的购物方式,线上购物如今变得稀松平常。只需点击搜索按钮,数以千计的相关商品便会立即弹出来。在这个过程中,无论我们是否意识到,我们都正在使用推荐系统(Recommendation System,RS)。事实上,推荐系统是无处不在的。当我们在淘宝或京东上购买家电,在携程上搜寻旅店,在微博上浏览相片,我们都在使用推荐系统,并在同时为推荐算法做出贡献。
推荐系统到底是什么?
简单地说,推荐系统是一种信息过滤工具,可以利用整个社区的用户画像和习惯给特定用户呈现其可能感兴趣的最相关内容。一个有效的推荐系统包含三个主要功能:
• 克服信息过载问题。随着互联网上信息的爆炸式增长,用户不可能浏览所有的内容。推荐系统可以过滤掉低价值的信息,从而节省用户的时间。
• 提供定制化推荐。具有特定偏好的用户通常难以找到他们喜爱的商品。推荐系统应该帮助用户更好地根据自己的品味找到真正感兴趣的商品。
• 合理利用资源。根据长尾效应,最受欢迎的商品吸引了最多的注意力,而不那么受欢迎的商品,也就是其他大部分商品,将很少有人光顾。这是一种极大的资源浪费。推荐系统应该平衡受欢迎程度和实用性,让人们对这些不那么受欢迎的商品给予更多关注。
一个高效的推荐系统对平台和公司都有好处。用户更有可能根据他们的偏好来点击或购买被推荐的商品,并且会重新访问那些更了解他们的网站。总之,推荐系统在各种信息检索系统中都发挥着至关重要的作用,可以促进业务的发展和决策的制定。
然而,在推荐系统中,仍然有许多尚未解决的问题,冷启动和用户数据隐私是其中的两个主要问题。用联邦学习同时解决这两个问题是可行的。假设我们正通过联邦学习,用多方数据来训练一个全局模型。对于冷启动问题,我们可以从其他参与方借鉴相关信息和知识,以帮助对新商品进行评分或对新用户进行预测。对于数据隐私问题,用户的私有数据被保存在客户端设备中,只有更新的模型才会通过安全协议上传。此外,联邦学习将模型的学习过程分布到各个客户端上,大大降低了中央服务器的运算压力。
推荐模型
在详细介绍联邦推荐系统之前,我们首先介绍现有的推荐模型。一般来说,推荐模型可以分为四种:协同过滤、基于内容的推荐系统、基于模型的推荐系统和混合推荐系统。
1. 协同过滤(Collaborative Filtering,CF)
它通过对用户与商品的历史互动进行建模来实现推荐。也就是说,基于用户-商品矩阵,协调过滤会给同一位用户推荐类似的商品,或者给类似的用户推荐同一商品。然而,在实际生活中,每一位用户通常只会与几件商品有交互,这使得用户-商品矩阵高度稀疏。低秩因子分解方法(Low-rank factorization),也称为矩阵因子分解,已被证明是解决稀疏性问题的一种有效方法。
2. 基于内容的推荐系统(Content-based Recommendation System)
它对商品的描述和用户的画像进行匹配来进行推荐。其核心思想是,如果一位用户喜欢一件商品,也会喜欢相似的商品。在基于内容的推荐系统里,商品由若干个关键词进行标记,而用户画像由描述该用户喜欢的商品种类的关键词组成。模型通过关键词对齐方法,推荐商品描述与用户画像相匹配的商品。
3. 基于模型的推荐系统(Model-based Recommendation System)
它使用机器学习和深度学习技术,对用户-商品关系进行直接建模。该方法有若第 8 章 联邦学习与计算机视觉、自然语言处理及推荐系统 121 干优点:与前两种线性方法相比,这种方法适用于对非线性关系进行建模;深度学习模型可以学习文本、图像及音频等异构信息的潜在表征,从而得到更好的推荐模型;RNN 等深度学习模型能够对序列数据进行处理,适用于如预测下一商品等序列模式挖掘任务。
4. 混合推荐系统(Hybrid Recommendation System)
它是指集成两个或多个推荐策略的模型,通常被认为是更有效的。一种简单的混合方法是,先分别进行基于内容过滤预测和协同过滤预测,再将二者的结果聚合在一起。以电影推荐为例,混合模型基于与被推荐用户相似的用户的电影观看和搜索记录(协同过滤),以及与被推荐用户喜欢的电影类似的电影(基于内容过滤),来为用户进行电影推荐。
联邦推荐系统
在本节中,我们将会使用联邦协同过滤作为例子,简要描述联邦推荐系统是如何工作的。假设一个电子商务公司想要训练一个协同过滤(CF)模型,让用户可以根据个人喜好和商品流行程度来找到想要的商品。由于数据的隐私安全问题等原因,无法直接收集到用户的原始数据,因此可以利用联邦学习训练协同过滤模型。通常,一个协同过滤模型可以表示为,由多个用户因子向量(每个向量表示一个用户)组成的用户因子矩阵(user factor matrix)、由多个商品因子向量(每个向量表示一件商品)组成的商品因子矩阵 (item factor matrix) 的组合。联邦协同过滤由所有用户共同地学习这两个矩阵得到,如图 8–4 所示。包含以下五个步骤:
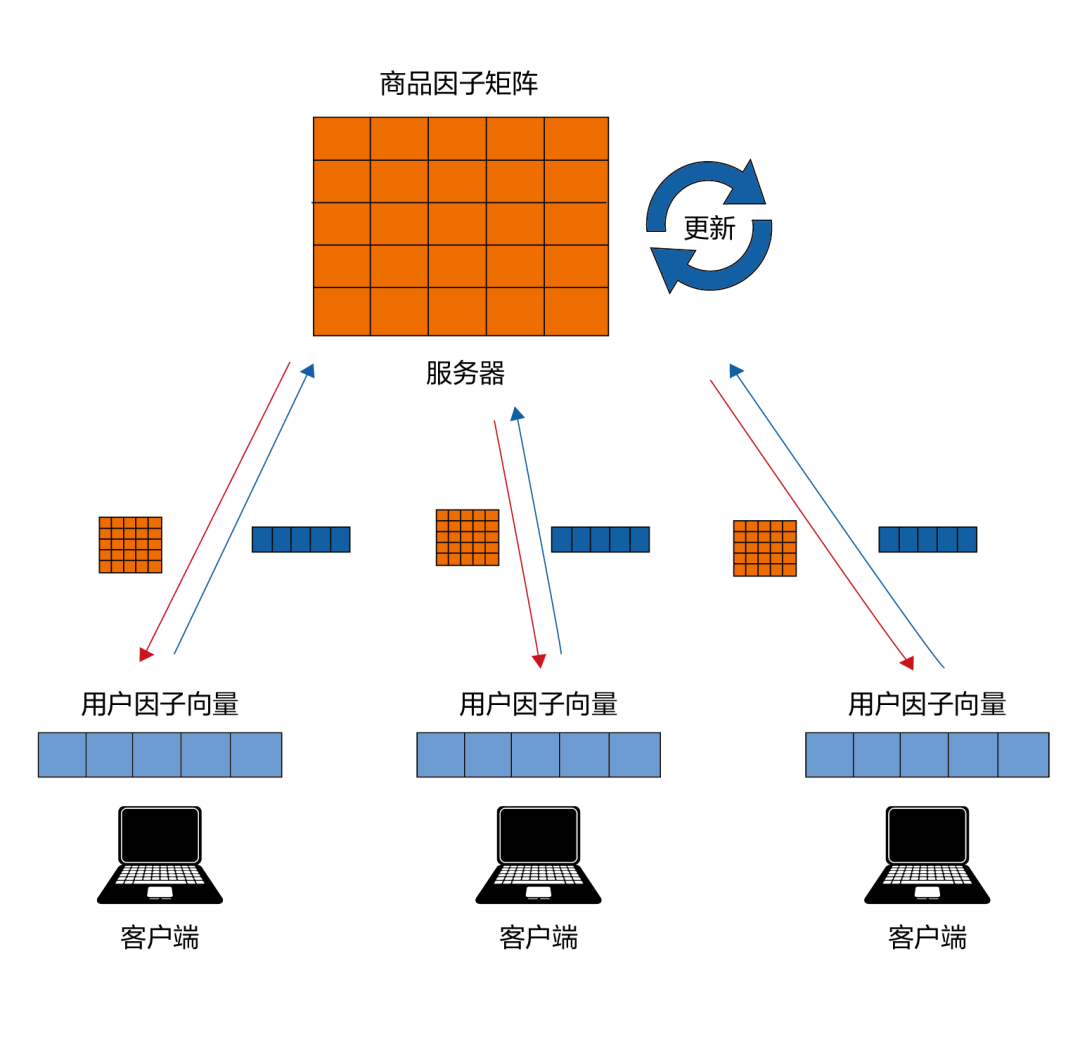
步骤 1:1 每一个客户 (例如,用户的本地设备) 从服务器下载全局商品因子矩阵。该矩阵可以是随机初始化的模型或预训练模型。
步骤 2:每一个客户聚合显式数据和隐式数据。显式数据包括用户的反馈,例如对商品的评分和评论。隐式数据由用户订单历史、购物车清单、浏览历史、点击历史、搜索日志等信息组成。
步骤 3:每一个客户使用本地数据和全局商品因子矩阵对本地用户因子向量进行更新。
步骤 4:每一个客户使用本地数据和本地用户因子向量,计算全局商品因子矩阵的本地更新,并通过一个安全协议将更新上传至服务器。
步骤 5:服务器通过联邦加权算法(如联邦平均算法[13])聚合从各个客户端上传的本地模型更新。并使用聚合的结果对全局商品因子矩阵进行更新。之后,服务器将全局商品因子矩阵发送给各个客户。
上述过程是联邦协同过滤的一般情况。我们可以利用更强大的模型来代替协同过滤模型,如深度因子分解机(Factorziation Machine, FM)模型以进一步提高性能。除了定制化的推荐任务,联邦推荐系统还可以利用来自不同参与方的不同特征提高推荐的精确度。
挑战与展望
我们可以看到,研究人员在结合联邦学习和推荐系统等方面进行了一些创新性的研究工作,但这个领域仍有许多空白需要填补。一个普遍的问题是:建立实用的隐私保护和安全的推荐系统需要什么?我们怎样才能建立这些系统?该问题可以进一步细分为几个具体的方面:如何在保护数据安全和隐私的同时,达到高准确度和低通信成本?我们应该选择哪种安全协议?哪种推荐算法更适用于联邦学习?
这里提出了一些未来可能的研究方向。首先,不完整的数据会在多大程度上影响推荐系统的性能?换句话说,我们需要从用户那里收集多少数据,才能建立一个精准的推荐系统。其次,传统的推荐器会利用用户的社交数据、时空数据等,然而目前还 124 不清楚这些数据中哪一部分更有用。最后,联邦学习框架与传统的推荐系统的设定有很大不同。因此,如何在联邦学习框架下,设计高效并且精确的推荐算法也是一项很有挑战性的研究工作。如何学习联邦学习首部全面、系统论述联邦学习的中文著作《联邦学习》现已上市,可以作为广大学习者入门和探究联邦学习的第一本书!
本书详细描述了联邦学习如何将分布式机器学习、密码学、基于金融规则的激励机制和博弈论结合起来,以解决分散数据的使用问题。介绍不同种类的面向隐私保护的机器学习解决方案以及技术背景,并描述一些典型的实际问题解决案例。
作者团队
杨强 / 微众银行的首席人工智能官(CAIO),香港科技大学(HKUST)计算机科学与工程系讲席教授。
刘洋 / 微众银行 AI 项目组的高级研究员。
程勇 / 微众银行 AI 项目组的高级研究员。
康焱 / 微众银行 AI 项目组的高级研究员。
陈天健 / 微众银行 AI 项目组的副总经理。
于涵 / 新加坡南洋理工大学(NTU)计算机科学与工程学院助理教授,微众银行特聘顾问。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论