
编者按:本文整理自 8 月 Apache Pulsar Meetup 上,刘燊题为《Apache Pulsar 在微信的大流量实时推荐场景实践》的分享。本文介绍了微信团队在大流量场景下将 Pulsar 部署在 K8s 上的实践与优化、非持久化 Topic 的应用、负载均衡与 Broker 缓存优化实践与 COS Offloader 开发与应用。
在通信社交领域,微信已经成为国内当之无愧的社交霸主。用户人数在 2018 年突破了 10 亿,截至 2021 年第三季度末,微信每月活动账户总数已达到 12.6 亿人,可以说,微信已经成为国人生活的一部分。
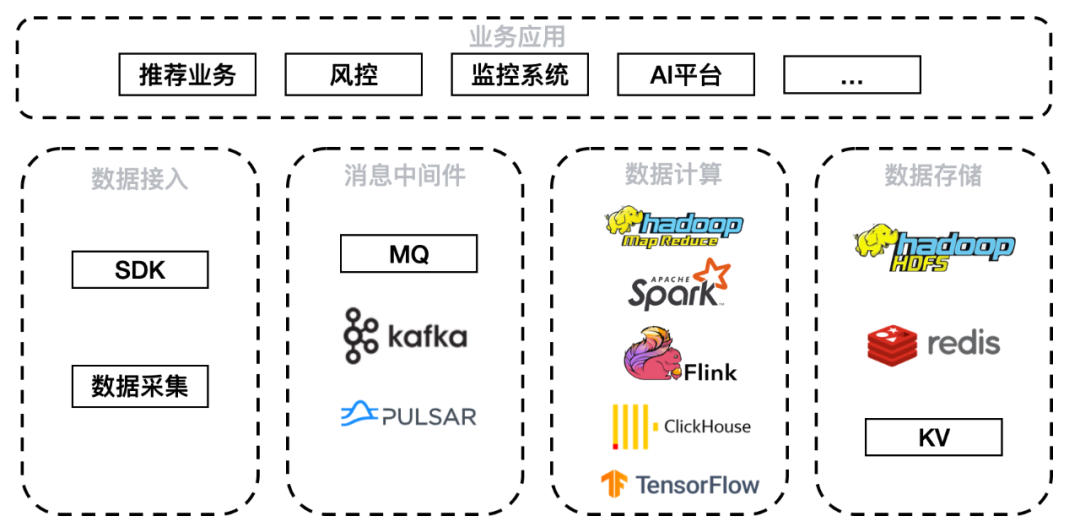
微信的业务场景包括推荐业务、风控、监控系统、AI 平台等。数据通过 SDK 和数据采集方式接入,经由 MQ、Kafka、Pulsar 消息中间件,其中 Pulsar 发挥了很大的作用。中间件下游接入数据计算层 Hadoop、Spark、Flink、ClickHouse、TensorFlow 等计算平台,由于本次介绍实时推荐场景,因此较多使用 Flink 和 TensorFlow。落地存储平台则包括 HDFS、HBase、Redis 以及各类自研 KV。
团队选型 Pulsar 的初期目标是获得一个满足大数据流量场景并且运维管理便捷的消息队列系统。最终选择 Pulsar 的主要原因有五点:
在腾讯自研上云的大背景下,团队非常看重云原生特性。Pulsar 的云原生特性,包括分布式、弹性伸缩、读写分离等都体现出优势。Pulsar 逻辑层 Broker 无状态,直接提供服务。存储层 Bookie 有状态,但是节点对等,且 Bookie 自带多副本容灾;
Pulsar 支持资源隔离,可以软隔离或硬隔离,避免不同业务之间互相影响
Pulsar 支持灵活的 Namespace/Topic 策略管控,对集群的管理和维护有很大帮助;
Pulsar 能够便捷扩容,逻辑层 Broker 的无状态和负载均衡策略允许快速扩容,存储层 Bookie 节点之间互相对等也便于快速扩容,可以轻松应对流量暴涨场景;
Pulsar 具备多语言客户端能力,微信的业务场景中涉及 C/C++、TensorFlow、Python 等语言,Pulsar 可以满足需求。
实践 1:大流量场景下的 K8s 部署实践
微信团队使用了 Pulsar 官网提供的 K8s Helm chart 部署方式。
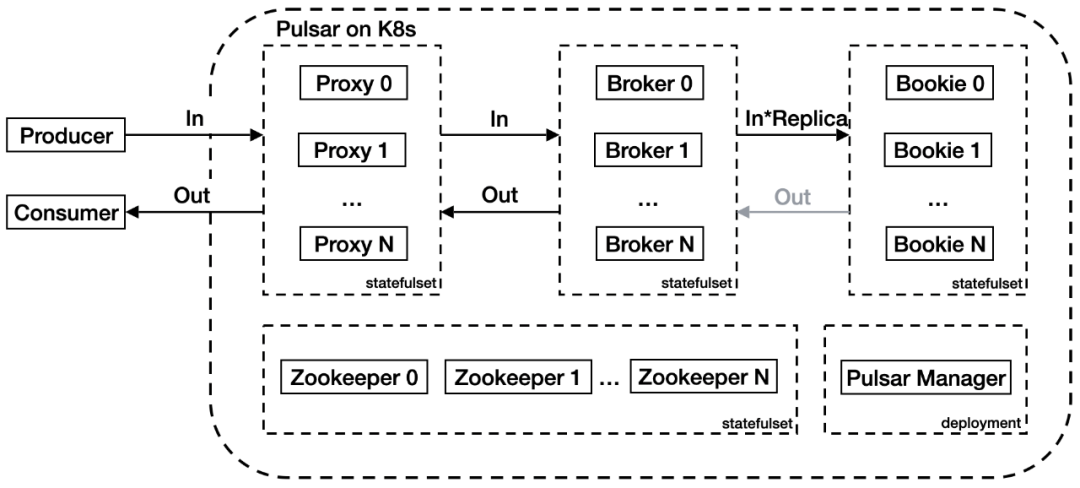
原生部署架构中,流量从 Proxy 代理层进入,经过 Broker 逻辑服务层写入 Bookie 存储层。Proxy 代理层代理客户端和 Broker 之间的连接,Broker 层管理 Topic,Bookie 层负责持久化消息存储。在上图中,入流量和出流量分别用 In 和 Out 进行标记,Replica 是配置的副本。
在应用的过程中团队发现了两个问题:首先 Proxy 代理了 Pulsar 客户端的请求,导致 Broker 无法获取客户端 IP,增加了运维难度;其次,当集群流量较大时,集群内部带宽会成为瓶颈。上图架构内,集群入流量为 (2+ 副本数)倍;出流量最大为 3 倍,Consumer、Proxy、Broker 和 Bookie 间分别有一倍流量,但是仅极端情况下流量会全量从 Bookie 流出。假设出入流量都是 10 GBps,副本数为 3,集群内入流量会放大为 50 GBps,出流量会放大为 30 GBps。另外默认情况下 Proxy 服务只有一个负载均衡器承载所有流量,压力巨大。
这里可以看出瓶颈主要出现在 Proxy 层,该层造成了很大流量浪费。而 Pulsar 实际上支持 Broker 直连,因此团队在此基础上进行了一些优化:
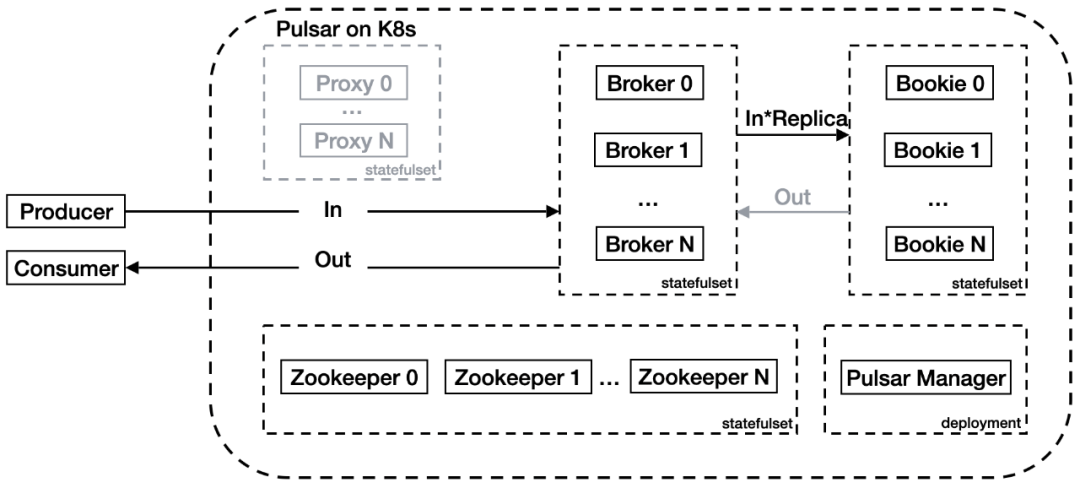
团队利用了腾讯云 K8s 集群的能力,给 Broker 配置了弹性网卡,并使 Broker 的 IP 直接暴露在集群外,可以被外部客户端直接访问。Broker 服务也配置了负载均衡器。这样客户端可以直接访问负载均衡器 IP,再经过 Pulsar 内部协议的 Lookup 操作找到要访问的 Topic 所处的 Broker。由此节省了 Proxy 带来的额外带宽消耗。
团队在 K8s 部署方面还做了以下优化工作:
如上文所述去 Proxy;
Bookie 使用多盘多目录 + 本地 SSD 提升性能,由于原社区版本 Pulsar 不支持多盘多目录,这里团队做了改进支持并合并入社区 (https://github.com/apache/pulsar-helm-chart/pull/113);
日志采集使用腾讯云 CLS(日志服务),统一的日志服务可以简化分布式多节点系统的运维、问题查询操作;
指标采集使用 Grafana + Kvass + Thanos,默认指标采集使用了单机服务,很快出现了性能瓶颈,优化后问题解决且支持水平扩容。
实践 2:非持久化 Topic 的应用
生产者和消费者是同 Broker 中的 Dispatcher 模块交互的,而持久化 Topic 中生产者数据会通过 Dispatcher 进入 Managed Ledger 模块,再调用 Bookie 客户端与 Bookie 交互。非持久化 Topic 中数据不会进入 Managed Ledger,而是直接发送给消费者。在大流量场景中,非持久化 Topic 由于不需要与 Bookie 交互,对集群的带宽压力会明显降低。

非持久化 Topic 在大流量实时推荐场景中有应用,但具体的应用场景必须满足“可容忍少量数据丢失”的要求。实践中有三种场景满足这一要求:
大流量 + 消费端处理能力不足的实时训练任务;
时效性敏感的实时训练任务;
抽样评测任务。
实践 3:负载均衡与 Broker 缓存优化
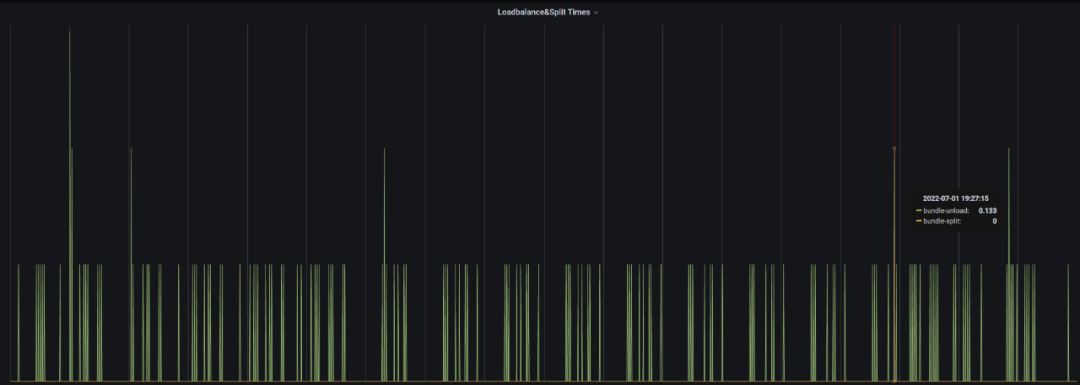
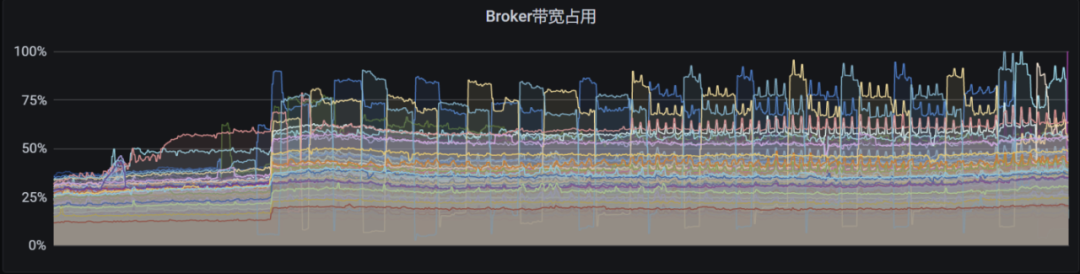
以上是一个线上真实的场景。生产环境中出现了反复 bundle unload 的问题,导致 Broker 负载反复波动。
该场景中使用了以下负载均衡配置:
loadManagerClassName=org.apache.pulsar.broker.loadbalance.impl.ModularLoadManagerImplloadBalancerLoadSheddingStrategy=org.apache.pulsar.broker.loadbalance.impl.ThresholdShedderloadBalancerBrokerThresholdShedderPercentage=10loadBalancerBrokerOverloadedThresholdPercentage=70Load bundle处理类(select for broker):org.apache.pulsar.broker.loadbalance.impl.LeastLongTermMessageRate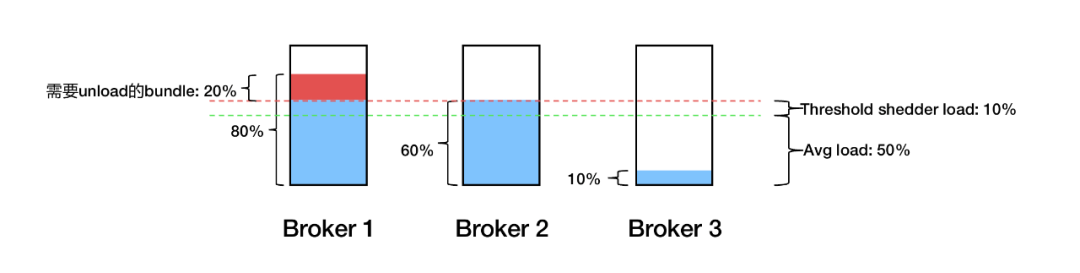
如上图,假设三个 Broker 平均负载是 50%,则阈值就是 60%,超出 60% 的部分需要均衡。但实际应用中发现 Broker 1 的多余 20% 负载会卸载到 Broker 2 上,之后由于 Broker 2 超载所以又会卸载下来,还会回到 Broker 1 上。结果流量就在 Broker 1 和 Broker 2 上反复横跳。
跟踪代码发现,Load Bundle 处理类是根据 Broker 的消息量判断该承载多余流量的 Broker,但生产中消息量与机器负载并不完全正相关,且 Threshold shedder 是根据 CPU、出入流量、内存等多种指标平均加权得出 Broker 负载,所以 bundle 的加载和卸载逻辑并不一致。
对此团队进行了代码优化改进:
loadManagerClassName=org.apache.pulsar.broker.loadbalance.impl.ModularLoadManagerImplloadBalancerLoadSheddingStrategy=org.apache.pulsar.broker.loadbalance.impl.ThresholdShedderloadBalancerBrokerThresholdShedderPercentage=10loadBalancerBrokerOverloadedThresholdPercentage=70Load bundle处理类(select for broker):在低于平均负载的broker中随机选择loadBalancerDistributeBundlesEvenlyEnabled=false (相同的代码实现:PR-16059)默认情况下,Pulsar 集群希望一个 Namespace 下的多个 bundle 尽量平均分散在多个 Broker 上,但这一逻辑会将上面的 Broker 3 剔除候选均衡 Broker 之列。所以这里修改了这一逻辑,使流量可以平均分布在三个 Broker 上。社区也有类似的代码实现:
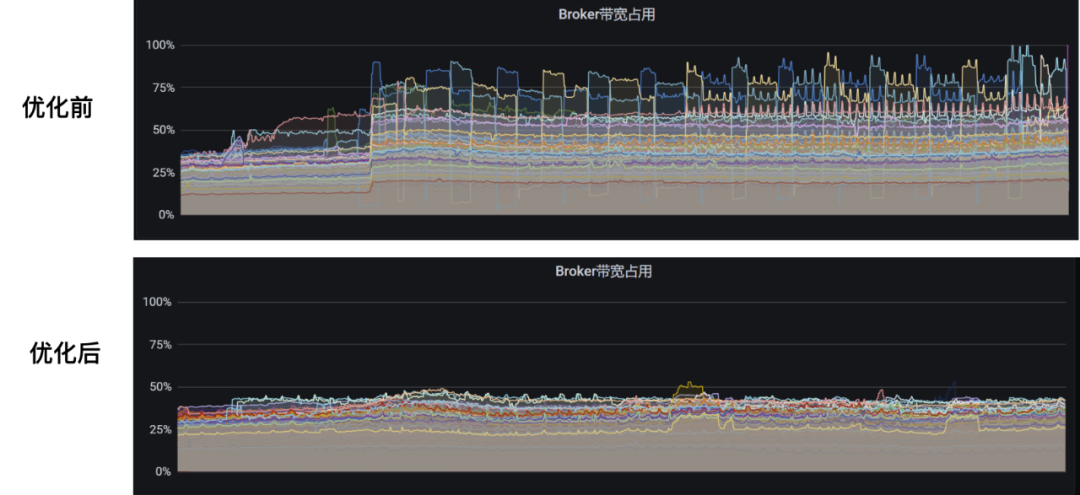
PR-16281:loadBalancerLoadPlacementStrategy=org.apache.pulsar.broker.loadbalance.impl.LeastResourceUsageWithWeight优化后的效果如下,可以看到集群流量稳定许多:
团队还在实时推荐场景下优化了 Broker 缓存。这种场景有以下特征:
消费任务数量众多;
消费速度参差不齐;
消费任务经常重启。
对此,社区原有的 Broker 缓存逻辑效果不佳。以下是 Broker 缓存的原有驱逐逻辑:
void doCacheEviction(long maxTimestamp) { if (entryCache.getsize() <= 0) { return; } // Always remove all entries already read by active cursors PositionImpl slowestReaderPos = getEarlierReadPositionForActiveCursors); if (slowestReaderPos != null) { entryCache.invalidateEntries(slowestReaderPos): } // Remove entries older than the cutoff threshold entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);}默认策略会找出当前消费不活跃(由阈值控制,Cursor 消费的 entry 超过阈值即被认为是不活跃)的 Cursor,对 Cursor 之前的数据做驱逐。对此,腾讯工程师向社区提交了代码改进:
void doCacheEviction (long maxTimestamp){ if (entryCache.getSize() (= 0) { return; ) PositionImpl evictionPos; if (config.isCacheEvictionByMarkDeletedPosition()){ evictionPos=getEarlierMarkDeletedPositionForActiveCursors().getNext(); } else { // Always remove all entries already read by active cursors evictionPos=getEarlierReadPositionForActiveCursors(); } if (evictionPos != null) { entryCache.invalidateEntries(evictionPos); } // Remove entries older than the cutoff threshold entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);}这里将选择非活跃 Cursor 的逻辑改成了寻找需要删除的数据位置。这样消费速度相对较慢的数据就不会穿越到 Bookie 中增加集群压力,只要数据有 Backlog 就会被缓存。但这种方法会导致缓存空间吃紧,因为消费任务重启期间仍旧要无意义地保留缓存,占用缓存空间。
对此微信团队在社区改进的基础上又做了调整:
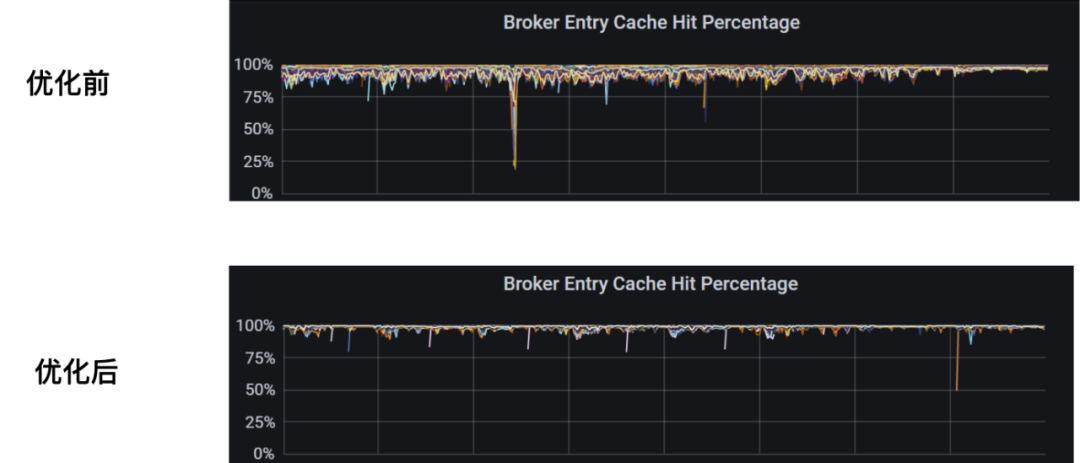
void doCacheEviction(long maxTimestamp){ if (entryCache.getSize() <= 0) { return; } if (factory.getConfig().isRemoveReadEntriesInCache()){ PositionImpl evictionPos; if (config.isCacheEvictionByMarkDeletedPosition()){ PositionImplearlierMarkDeletedPosition=getEarlierMarkDeletedPositionForActiveCursors(); evictionPos = earlierMarkDeletedPosition != null? earlierMarkDeletedPosition.getNext() : null; } else { // Always remove all entries already read by active cursors evictionPos=getEarlierReadPositionForActiveCursors(); } if (evictionPos != null) { entryCache.invalidateEntries(evictionPos); } } //Remove entries older than the cutoff threshold entryCache.invalidateEntriesBeforeTimestamp(maxTimestamp);}这里简单地将一定时间内的数据缓存到 Broker 中,有效提升了场景中的缓存效率:
实践 4:COS Offloader 开发与应用
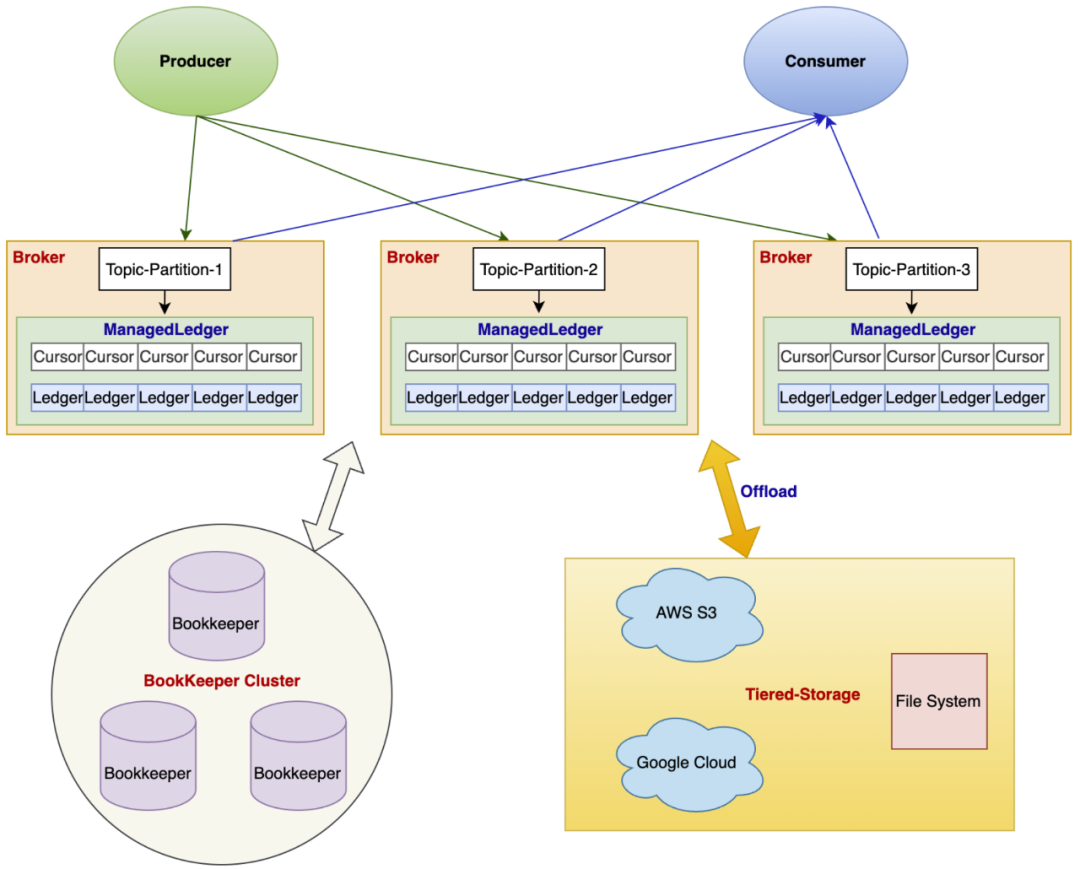
Pulsar 提供了分层存储能力,可以将存储转移到廉价的存储层。Pulsar Offloader 可以将超过一定时长的 Ledger 搬运到远端存储,不再停留在 Bookie 层,由 Broker 接管这部分的数据管理。
团队使用 Pulsar Offloader 的原因有:
Bookie Journal/Ledger 盘都使用 SSD,成本较高;
业务需求存储时间长、数据存储量大;
数据消费任务异常,需要容忍较长时间的数据 Backlog;
数据回放需求。
Pulsar 社区版本并不支持腾讯云对象存储(COS),所以团队开发了内部云上 COS Offloader 插件并应用于线上。
未来展望与计划
团队在部署与使用过程中一直和社区密切沟通,团队未来计划跟进社区版本升级与 bug 修复。微信团队将着重参与一些特性,比如 PIP 192(https://github.com/apache/pulsar/issues/16691)Broker 负载均衡与缓存优化,计划重构负载均衡器;PIP 180(https://github.com/apache/pulsar/issues/16153) 通过影子 Topic 解决读放大问题,帮助精细化管理 Topic。微信团队也在关注 Pulsar 生态进展,如 Flink、Pulsar、数据湖全链路打通。
作者简介:
刘燊,腾讯微信高级研发工程师,Apache Pulsar Contributor。
今日好文推荐
60 岁周星驰招聘 Web3.0 人才,要求“宅心仁厚”;马斯克计划裁掉推特 75% 的员工;Linus 致开发者:不要再熬夜了 | Q 资讯




