

滴滴 AI Labs 语音团队在论文《使用无监督预训练提升基于 Transformer 的语音识别》中,新提出一种基于 Transformer 的无监督预训练算法,创新性地将自然语言处理中的 BERT 等算法的思想推广到了语音识别领域。能利用极易获取的未标注的语音数据,大幅提升了语音识别精度。
论文结果显示,通过简单的无监督预训练,中文语音识别任务能得到 10%以上的性能提升。具体地,在中文语音识别数据集 HKUST 上的结果显示,当仅使用 HKUST 数据库数据做预训练时,字错误率能达到 23.3%(目前文献中最好的端到端模型的性能是字错误率为 23.5%);当使用更大无监督数据库做预训练时,字错误率能进一步降低到 21.0%。
该论文工作不仅向学术界提出一种使用无监督预训练提升语音任务精度的方法,从实验结果中也可以发现识别性能能够随着无监督数据量的增加而提升。这是一个工业界上标注资源有限条件下的探索和尝试,具有非常强的业务落地价值:在工业界产品中可以减少对标注数据的依赖,在特定领域下,标注数据需求可能从上万小时下降到千小时、百小时,这可以有效降低搭建高质量语音识别系统的成本。
以下是对论文的详细解读:

语音识别技术已广泛的应用在各领域的工业产品。搭建一套高质量的语音识别系统通常需要花费巨大的投入来获取足够的标注数据。同时,通过各已有的在线工业系统,可以轻松的获取大量的未标注的语音数据。无论是在学术界还是在工业界,探索如何有效的使用这些未标注数据来提升语音识别系统精度,都是十分有价值的。
无监督预训练近年来在计算机视觉(CV)、自然语言处理(NLP)等领域出现了大量突出的工作。其中 BERT 采用一种掩蔽语言模型(Masked Language Model,MLM)预训练的方式进行无监督预训练,在众多 NLP 任务上取得了突破性的成绩。语音任务同自然语音处理任务事实上有很多的共同特点。比如语音识别任务,是一个典型的语音序列到文本序列转换的任务,在处理时先使用 Encoder 对语音信息进行特征表示,然后使用 Decoder 转换成文本。而在 NLP 任务中,会先使用 BERT 等工具预训练文本的特征表示,再在下游任务上进行微调。受 BERT 等无监督预训练工作的启发,论文提出了一种通过无监督预训练学习语音特征表示,再结合下游特定语音识别任务进行微调的新语音识别框架。
无监督预训练端到端语音识别框架
我们先介绍基于 Transformer 的语音识别预训练系统架构和具体实现,这是这篇论文的核心创新。
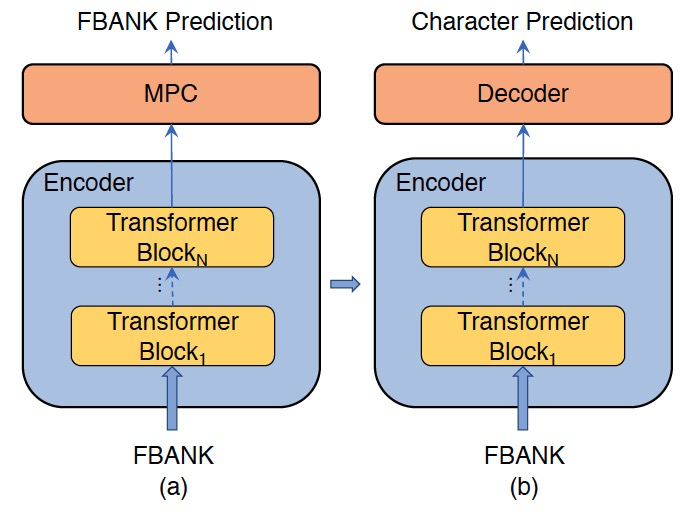
图 2.论文中系统的训练流程:(a)预训练:使用 MPC(Masked Predictive Coding)来预测 FBANK 特征(b)微调:Encoder 后添加一个 Decoder,整个模型对字的预测进行优化
整个系统如图 2 所示,主要包括两个阶段:无监督数据预训练;有监督数据微调。为了减少对 Transformer 识别系统的修改,文章直接使用 FBANK 作为 Encoder 的输入及输出。同时,Encoder 输出的 FBANK 维度同输入 FBANK 维度相同。无监督预训练完成以后,移除 FBANK 预测编码层,添加 Transformer Decoder 对下游的语音识别任务进行微调。在微调阶段,整个模型的所有参数都是端到端可训练的。
采用 MPC 对基于 Transformer 的模型进行预测编码
论文使用同 BERT 中 Masked-LM(MLM)类似的结构,提出 MPC(Masked Predictive Coding,掩蔽预测编码)来对基于 Transformer 的模型进行预测编码。下面详细介绍 MPC 结构。
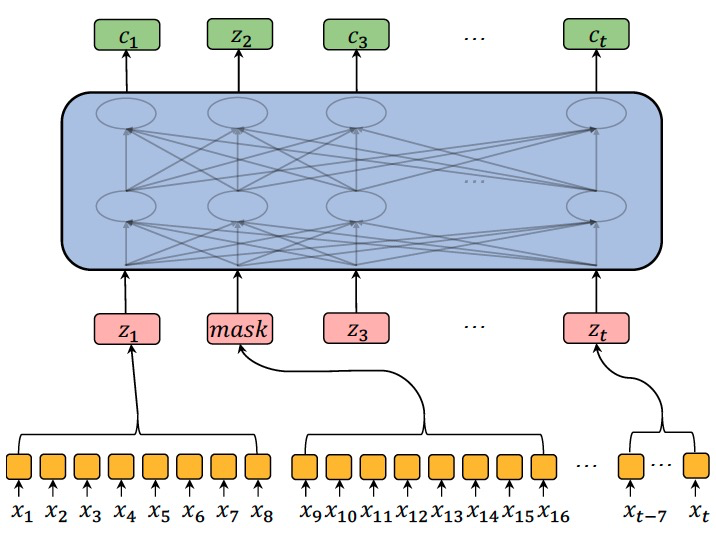
图 1.八倍下采样的 MPC(掩蔽预测编码)
图 1 为 MPC 的结构示意图。在预训练的过程中,每个序列 15%的标记会被随机掩蔽。论文中,在选出的掩蔽帧中 80%的帧以零向量来表示,10%的掩蔽帧使用随机的其它帧的信息来表示,而其余 10%的掩蔽帧不做任何变化。采用 L1 Loss 来计算掩蔽的输入 FBANK 特征和对应位置 Encoder 的输出的差异。
论文为了使 MPC 无监督预训练能对下游的语音识别任务带来更大的提升,在无监督预训练时,对数据进行了同语音识别 Encoder 相同程度的下采样,如图 1 中,在无监督预训练时,作者对输入语音的帧序列做了 8 倍的下采样。
实验结果
下面将呈现无监督预训练的实验及结果,具体的实验设置可以参考原论文。
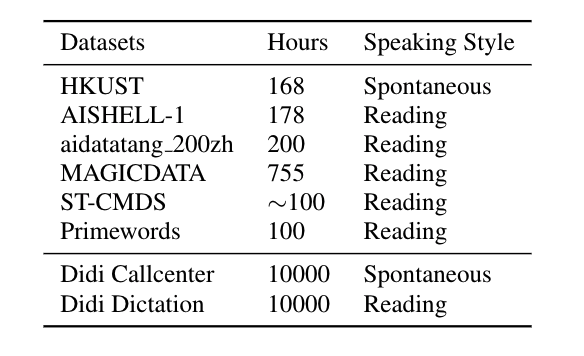
表 2.论文中使用的开源中文数据集及滴滴内部数据集"
表 2 为论文中使用的数据集情况。为了验证论文提出的无监督预训练方案的有效性,文中收集了大量开源的普通话数据集。
为了进一步探索此方案在无监督数据量大小及风格不同的情况下的效果,论文中引入了滴滴内部 1 万小时 Spontaneous 风格的 Callcenter 数据及 1 万小时 Reading 风格的 Dictation 数据。
最后带监督的微调实验是在 HKUST 及 AISHELL-1 数据集上进行,并分别使用对应的测试集进行性能评估。
表 1.使用无监督预训练方法在 HKUST 和 AISHELL-1 测试集上的字错误率(CER,%)。结果中‘8k’表示训练数据采样率下采样成 8kHz。论文的基线系统是未使用预训练数据得到的结果。相对错误下降率(RERR,%)指相对于基线系统错误率下降的百分比
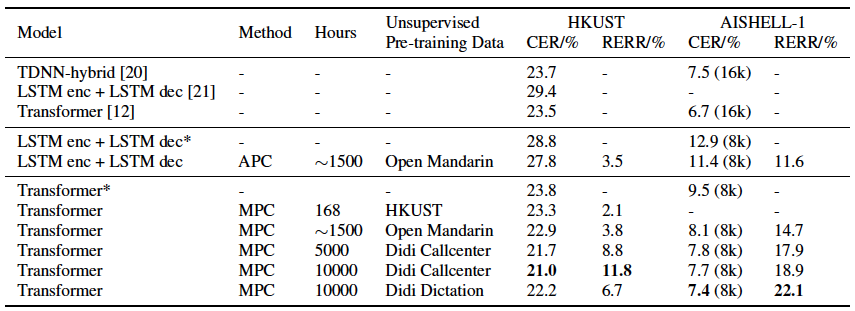
论文在 HKUST 和 AISHELL-1 数据集上的实验结果如表 1 所示。
在 HKUST 任务上,之前最好的研究结果是 Transformer[12],该工作基于 Transformer 端到端识别框架,训练时对训练数据进行了变速处理,解码时加入了语言模型。本论文采用类似的模型框架作为基线系统,训练时同样对训练数据进行了变速,解码时未使用任何语言模型。
从各无监督预训练实验结果可以看到:
l 无监督预训练能有效提升系统精度
l 随着无监督预训练数据量的增大,精度提升更加明显
l 使用领域风格更类似的无监督数据,提升效果更加突出
AISHELL-1 数据集上的实验结果及现象同 HKUST 类似。
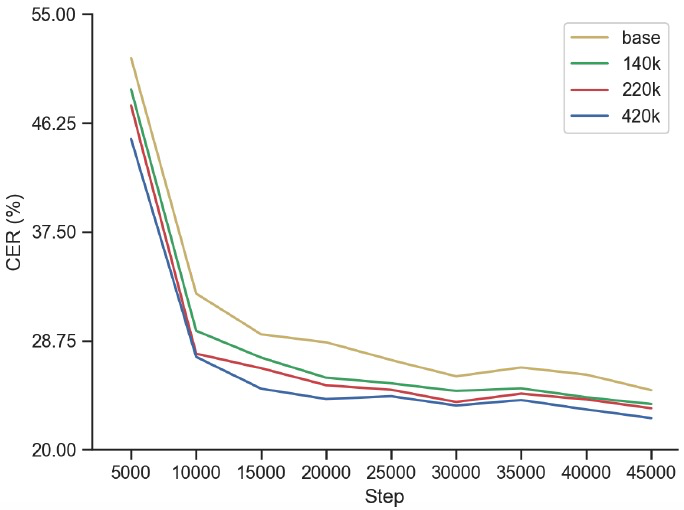
图 3.不同步数的无监督预训练模型下微调模型的收敛曲线"
论文对比了训练了不同步数的无监督模型,对下游微调模型收敛的影响。图 3 的结果可以看出,使用无监督预训练可以有效提升下游识别任务的收敛速度和效果,同时更多的预训练步数能使收敛速度更快。
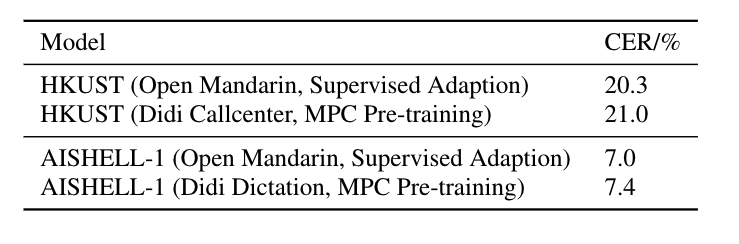
论文最后对比了无监督预训练和有监督自适应两种方法。表 3 的实验结果表明,有监督自适应方法结果还是略好于无监督预训练方法。然而,无监督预训练方式不需要任何的标注,这种方式可以有效的降低构建高质量语音识别系统的成本。
工作总结
论文提出了一种可用于语音任务的无监督预训练方法 MPC,此方法和 BERT 中常用的 MLM 类似。从实验结果来看,论文的无监督预训练方案可以大幅提升语音识别的精度。
下一步团队还将继续探索比如:
1) 论文方法应用到工业界产品上,减少搭建高质量语音识别系统时需要的标注数据量。
2) 继续扩大无监督数据量(比如十万小时、百万小时),探索是否可以进一步提升语音识别精度。
3) 探索无监督数据领域及风格,对无监督模型鲁棒性的影响。比如是否可以像 NLP 任务一样,混合各领域无监督数据训练通用的无监督模型。
论文地址:
https://arxiv.org/pdf/1910.09932.pdf

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论