

近年来,蜂窝架构(Cell-Based Architecture)作为一种增加冗余和有效限制站点故障影响范围的方式,在大型的在线服务中越来越流行。为了实现这些目标,在过去的一年半里,我们将 Slack 最关键的面向用户的服务从单体架构迁移到了基于蜂窝的架构。在本系列文章中,我们将解释我们为什么要进行大规模迁移、介绍蜂窝拓扑设计以及我们在此过程中所做出的工程技术权衡,并讨论我们成功对许多相连接的服务进行深度改造所采用的策略。
背景说明:事故

2021 年 6 月 30 日事故中的 TCP 重传图表
在 Slack,我们会在每一次发生明显的服务中断后进行一次事故评审。以下是我们内部事故评审报告的一些摘录,总结了其中的一起事故和我们的发现:
太平洋时间 20121 年 6 月 30 日上午 11 点 45 分,我们的云供应商在美国东海岸的一个可用区域发生网络中断,Slack 的大部分服务都托管在那里。连接一个可用区域和其他几个包含 Slack 服务器的可用区域的网络链路发生了间歇性故障,导致 Slack 服务器之间的连接变慢,进而出现服务降级。
太平洋时间 2021 年 6 月 30 日下午 12 点 33 分,我们的云供应商自动从服务中删除了网络链接,恢复了对 Slack 客户的全部服务。经过他们的一系列自动检查之后,网络链接再次进入服务状态。
太平洋时间 20121 年 6 月 30 日下午 5 点 22 分,网络链路又发生了同样的间歇性故障。下午 5 点 31 分,云供应商永久地从服务中删除了网络链接,恢复了对我们全部的服务。
乍一看,这似乎没什么大不了。我们的服务所使用的一块物理硬件发生了故障,因此出现了一些错误,直到发生故障的硬件被移除。然而,在进行事故评审时,我们不禁问自己:让我们的用户体验到这样的中断是合理的吗?
Slack 运营着一个全球性的、多区域的边缘网络,但我们的大多数核心计算基础设施都位于单个地区(us-east-1)的多个可用区域内。可用区域(AZ)是指单个区域内的隔离的数据中心,它们除了可以提供物理隔离之外,也会限制我们所依赖的云服务组件(虚拟化、存储、网络等)的故障影响范围,这样就不会在多个 AZ 中同时发生故障。在云端托管服务的构建者(如 Slack)可以通过这样的一种方式来构建服务——在一个区域内整个服务的可用性高于任何一个 AZ 的可用性。那么问题来了:为什么这个策略在 6 月 30 日没有奏效?为什么一个 AZ 发生故障会让用户体验到中断?
事实证明,在分布式系统中检测故障是一个难题。来自用户的一个针对 Slack API 的请求(例如,在一个频道中加载消息)可能会扇出数百个发给后端服务的 RPC,每个 RPC 都必须完成调用才能向用户返回正确的响应。我们的服务前端不断尝试检测和排除发生故障的后端,但在能够排除发生故障的服务器之前必须先将故障记录下来!让事情变得难上加难的是,我们的一些关键数据存储(包括我们的主数据存储 Vitess)提供了高度一致的语义,这对应用程序开发人员来说非常有用,但也要求任何写入都要有可用的后端。如果一个分片主节点对应用程序前端不可用,那么到该分片的写入将会失败,直到主分片返回错误或一个次分片被提升为主分片。
我们可以将上述的中断归类为灰色故障。在发生灰色故障时,系统可用性对于不同的组件来说是不一样的。在我们的事故中,受影响 AZ 内的系统看到其 AZ 内的后端完全可用,但 AZ 外的后端不可用。反过来,未受影响 AZ 内的系统看到受影响的 AZ 是不可用的。即使是同一个受影响的 AZ 内的客户端能够看到的后端可用性也是不一样的,这取决于它们的网络流量是否碰巧流经发生故障的设备。这就好比要求分布式系统在为我们的客户处理消息和提供小动物动图的同时处理好一切故障,这是一个相当复杂的任务。
我们对这个难题的解决方案并不是试图去自动修复灰色故障,而是通过利用人类的判断力来让计算机的工作变得更容易。工程师们很清楚,在发生宕机时,主要的问题在于一个 AZ 不可达——我们汇总的目标 AZ 的每一张图表都与上面的重传图很相似。如果我们有一个可以告诉所有系统“这个 AZ 已坏,请避开它”的按钮,我们肯定会把它盘得发亮!因此,我们开始着手构建这样的按钮,可以将流量从 AZ 中抽走。
我们的解决方案:AZ 就是会被引流的蜂窝单元
与其他许多基础设施一样,AZ 引流按钮在概念上很简单,但在实践中却很复杂。我们的设计目标是:
尽可能在 5 分钟内减少 AZ 内的流量。Slack 的 99.99%可用性 SLA 只允许我们每年不到 1 小时的总体不可用,因此,为了有效地保持这种可用性,我们需要能够快速奏效的工具。
引流不能导致对用户可见的错误。引流是一种通用的缓解措施:只要故障包含在单个 AZ 内,即使尚未清楚导致故障的根本原因是什么,也可以有效地使用引流来缓解故障。这是一种实验性的方法,在发生故障期间,运维人员可以尝试对 AZ 进行引流,看看故障是否能够恢复,如果不能,则进行放流。如果引流会导致额外的错误,那么这种方法就没有用了。
引流和放流必须是增量的。在放流时,运维人员将流量的 1%分配给 AZ,看看它是否已经恢复。
引流机制不能依赖于被引流的 AZ 内的资源。例如,只是通过向每台服务器发送 SSH 命令并强制其关闭健康检查机制来激活引流是不行的。这是为了确保即使 AZ 完全离线也可以进行引流。
一种符合这些需求的简单实现是向每个 RPC 客户端发送一个信号,当客户端接收到这个信号时,它们会让流向特定 AZ 的一定百分比的流量失败。这个方案隐含了很多复杂性。Slack 没有共享代码库,甚至没有共享运行时,处理用户请求的服务使用多种语言编写,如 Hack、Go、Java 和 C++,这就需要为每一种语言单独实现客户端。除此之外,我们还支持许多内部服务发现接口,包括 Envoy xDS API、Consul API,甚至 DNS。况且,DNS 没有为 AZ 或部分引流等机制提供抽象,客户端只希望能够解析 DNS 地址并接收 IP 列表。最后,我们在很大程度上依赖了开源系统,如 Vitess,要修改代码,就需要在内部维护分支,并做一些额外的工作,将变更合并到上游,这并不是一份令人愉悦的差事。
我们采用的主要策略叫作“筒仓(Siloing)”。如果服务只从其所在的 AZ 内接收流量,并且只向该 AZ 内的服务器发送流量,那么这个服务就可以被称为一个筒仓。从整体上看,这种架构的效果是:每个服务似乎都有 N 个虚拟服务,每个 AZ 中有一个。重要的是,我们可以通过对某个 AZ 内的用户请求进行重定向来有效地将 AZ 内所有筒仓服务的流量抽走。如果没有来自用户的新请求到达筒仓所在的 AZ,那么这个 AZ 的内部服务自然会停止,因为它们没有新的工作要做。
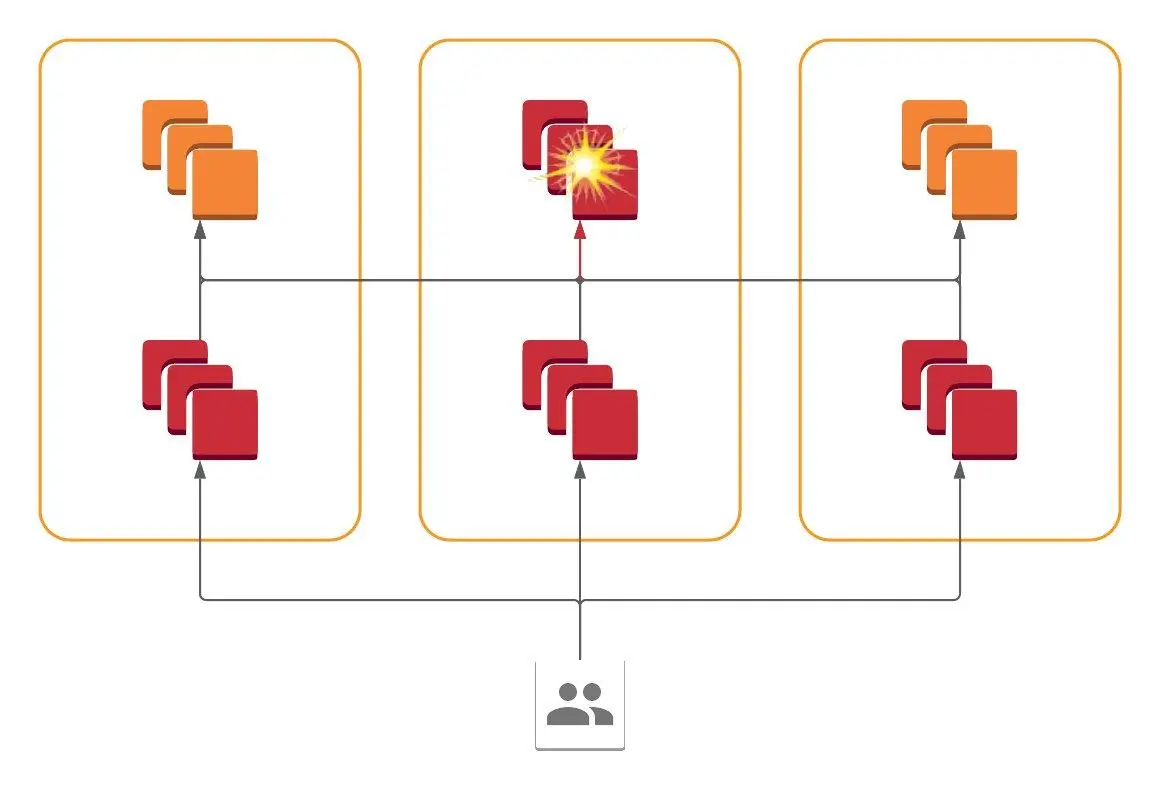
我们最初的架构,后端分布在各个 AZ 中,因此错误会出现在所有 AZ 的前端
最终,我们得到了一个蜂窝架构。所有服务都存在于所有 AZ 中,但每个服务只与其 AZ 内的服务通信。一个 AZ 内的系统故障被包含在该 AZ 内,我们可以动态路由流量以避开这些故障,只需在前端重定向即可。
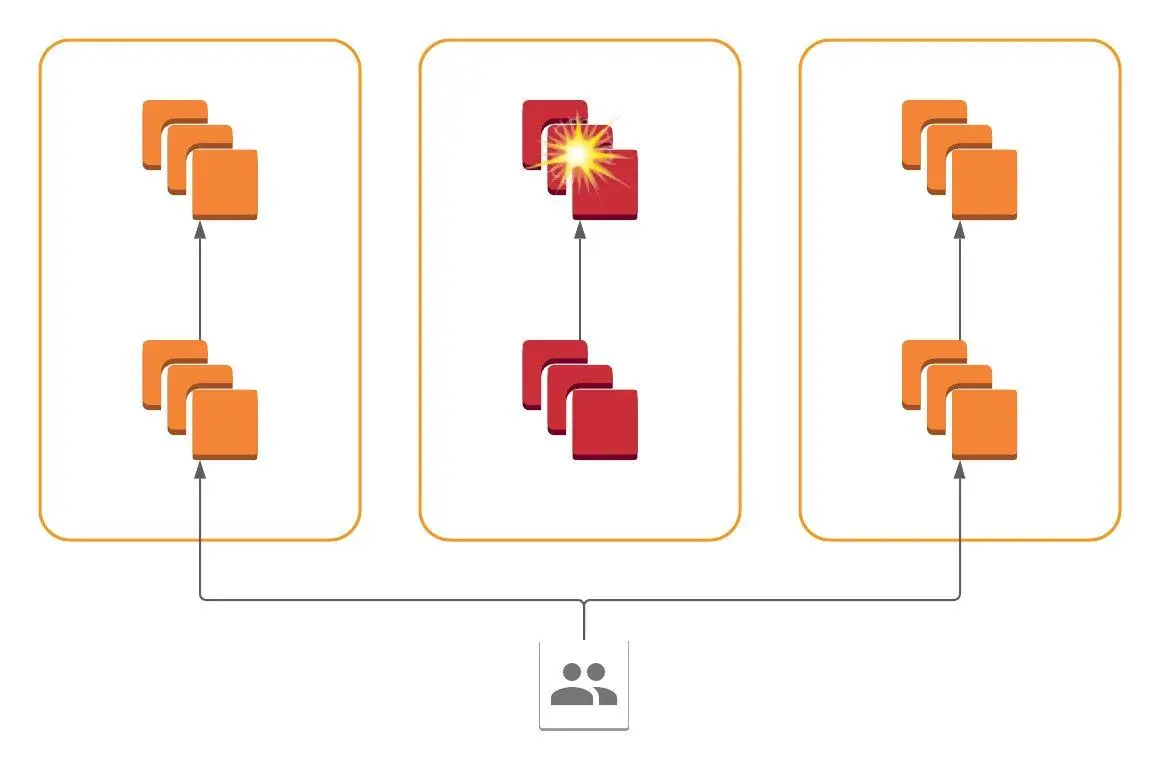
筒仓架构,一个 AZ 中的故障被包含在该 AZ 中,流量可能被抽走
有了筒仓架构,我们就可以将精力集中在一个地方来实现流量转换:将来自用户的查询路由到 us-east-1 区域的核心服务。在过去的几年里,我们进行了大量投入,从 HAProxy 迁移到了 Envoy/xDS 生态系统,因此我们所有的边缘负载均衡器现在都在运行 Envoy,并从我们内部的 xDS 控制平面 Rotor 接收配置。因此,我们能够通过简单地使用两个开箱即用的 Envoy 功能来进行 AZ 引流:加权集群和基于 RTDS 的动态权重分配。在对一个 AZ 进行引流时,我们只需通过 Rotor 向边缘 Envoy 负载均衡器发送一个信号,指示它们在 us-east-1 重新分配每个 AZ 的目标集群权重。如果 us-east-1 某个 AZ 的权重变为零,Envoy 将继续处理请求,但会将所有新请求分配给另一个 AZ,也就完成了对这个 AZ 的引流。我们来看看这是如何满足我们的目标的:
通过控制平面的传播为秒级,Envoy 负载均衡器将立即应用新的权重。
引流不会丢失请求,负载均衡层不会放弃任何一个查询。
权重提供粒度为 1%的增量式引流。
边缘负载均衡器完全位于不同的区域,控制平面有区域副本,可以抵御任意的单 AZ 故障。
下图是我们逐步将流量从一个 AZ 引到另外两个 AZ 时每个 AZ 的带宽情况。注意图中的“膝盖”部分,它反映了 Envoy/xDS 实现为我们提供的快速、大粒度的传播保证。
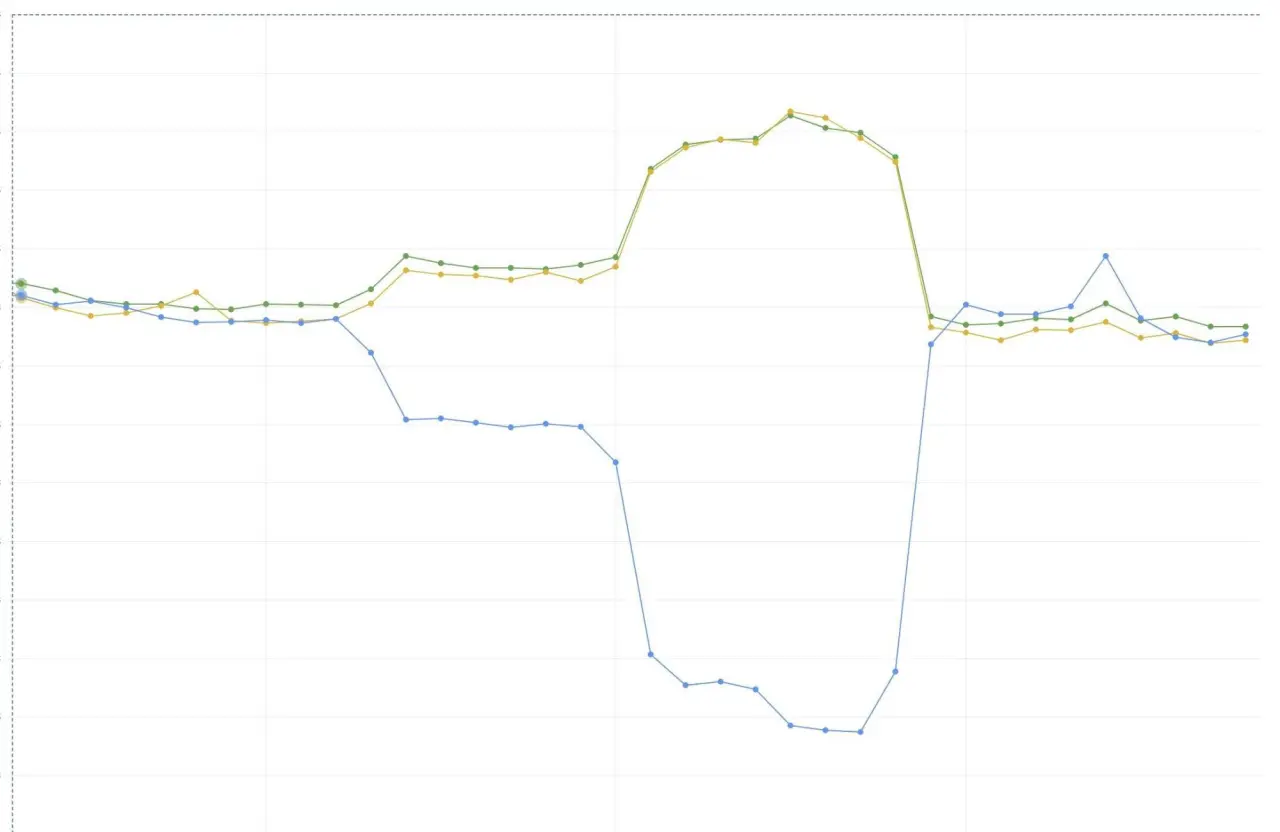
单 AZ 的每秒查询走势
原文链接:
https://slack.engineering/slacks-migration-to-a-cellular-architecture/
相关阅读:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论