

本文最初发表在 Towards Data Science 博客,由 InfoQ 中文站翻译并分享。
语言模型 BERT 可以大幅提升许多任务的性能,那么它成功的背后是什么呢?
什么是 BERT?
BERT,全称 Bidirectional Encoder Representation from Transformers,是一款于 2018 年发布,在包括问答和语言理解等多个任务中达到顶尖性能的语言模型。它不仅击败了之前最先进的计算模型,而且在答题方面也有超过人类的表现。
BERT 是一个可以将文字转换为数字的计算模型。这个过程是至关重要的,因为机器学习模型需要以数字而非文字为输入,而一款可以将文字转换为数字的算法让人们可以直接使用原始的文本格式数据训练机器学习模型。
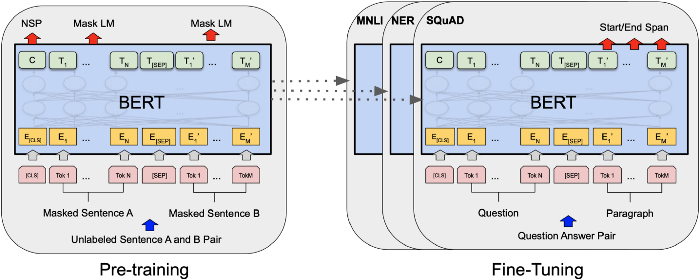
BERT 是可以将文字转换为数字的计算模型,图源Devlin et al., 2019
BERT 为何如此优秀?
对作者来说,BERT 的优秀之处主要在于以下三点:
第一:使用大量数据预训练
第二:可以处理文字语意
第三:开源
1:BERT 使用海量数据预训练
BERT 提供两种不同大小模型,BERT-base(使用 BookCorpus 数据集训练,约 8 亿字)以及 BERT-large(使用英文维基百科训练,约 25 亿字)。两种模型均使用了巨大的训练集,而任何一个机器学习领域的人都明白,大数据的力量是相当无敌的。正所谓“熟读唐诗三百遍,不会做诗也会吟”,在见过 25 亿单词之后,再看到新单词时你也能猜到它会是什么意思。
因为 BERT 的预训练非常优秀,所以即使是应用在小型数据集上也能保持不错的性能。举例来说,作者最近参与了一个开发新冠(COVID-19)自动问答系统的项目,在没有进一步微调的情况下,BERT-base 在作者使用的数据集中的 15 个类别上,准确率达到 58.1%。更令人惊叹的时,“COVID”这个词甚至不在 BERT 的词汇库中,但它依然获得了相当高的准确率。
2: BERT 可以处理语意
之前的词嵌入方法,无论一个词处于什么样的语境下,都会返回同一个向量。而 BERT 则会根据上下文,为同一个词返回不同的向量。例如,在下面的例子中,旧方法会为“trust”返回相同的嵌入。
I can’t trust you.(我不能相信你。)
They have no trust left for their friend. (他们对自己的朋友已经没有信任感。)
He has a trust fund. (他有一个信托基金。)
相比之下,BERT 可以处理语意,根据“trust”语境的不同返回不同的嵌入。如果算法可以分辨出一个词使用情况的不同,就能获得更多的信息,性能也有可能得到提升。另一个可以处理上下文的语言建模方法是ELMo。
3:BERT 是开源的
开源是个大加分项。机器学习领域中的很多项目都被开源化,因为代码开源可以让其他的研究人员轻松应用你的想法,从而促进项目的发展。BERT 的代码发布在了GitHub上,同时还附有代码使用相关的 README 文件,这些深入信息对于任何想要使用 BERT 的人来说有很大帮助。
在作者最开始使用 BERT 时,只花费了几分钟下载能运行的 BERT 模型,然后只用不到一小时的时间成功写出可以用在数据集中的代码。
一个非常强大的语言模型会同时具备上文中提到的全部三个方面,而这个模型可以在 SQuAD、GLUE 和 MultiNLI 等大名鼎鼎的数据集上会达到最顶尖的性能。它所拥有的这些巨大优势是让它如此强大和适用的原因所在。
BERT 利用大量数据进行预处理,用户可以直接将其应用在自己相对较小的数据集上。BERT 有上下文嵌入,性能会很不错。BERT 是开源的,用户可以直接下载并使用。它的应用范围如此之广,这就是为什么说 BERT 彻底改变了 NLP。
谷歌的研究人员,也是 BERT 的最初创造者,计划利用它来理解谷歌搜索,并提高谷歌自动问答服务的准确性。后来人们发现,BERT 的用处不仅仅只局限于谷歌搜索。BERT 有望改善计算机语言学的关键领域,包括聊天机器人、自动问答、总结和文本情感分析。自一年多前 BERT 的发布以来,其论文的引用已超过 8,500 次,其广泛实用性不难看出。此外,自 BERT 发表后,最大的国际 NLP 会议 Association for Computational Linguistics(ACL)的投稿量也翻了一番,从 2018 年的 1544 篇直接增到 2019 年的 2905 篇。
BERT 将继续为 NLP 领域带来革命性的变化,它为小型数据库中各种类型的任务提供实现高性能的机会。
延伸阅读:
Devlin et al.原论文(https://arxiv.org/pdf/1810.04805.pdf)
ELMo,使用上下文嵌入的类似语言模型:
https://arxiv.org/pdf/1802.05365.pdf
原文链接:
https://towardsdatascience.com/bert-why-its-been-revolutionizing-nlp-5d1bcae76a13

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论