

本文主要介绍索信达 AI 创新中心将可解释算法应用于流失预警模型后进一步探索出的一套能进行单个客户流失归因的流失预警及归因建模方案。与传统的流失预警模型相比,该方案最大的特点在于它不仅精度很高,还可以对每个流失客户进行归因,再根据每个客户的流失原因制定挽留措施,从而提高营销效果。
导读
客户流失预警一直是包括银行业在内的众多行业的重点话题,传统的流失预警建模方案往往存在难以得知客户流失原因的问题。为了得到精度高和解释性好的模型,我们将可解释算法应用于流失预警模型,进一步探索出一套能进行单个客户流失归因的流失预警及归因建模方案。本方案最大的特点在于它不仅有很高的精度,还可以对每个流失客户进行归因,再根据每个客户的流失原因制定挽留措施,从而提高营销效果。本文的工作如下:
(1)分析流失预警在银行业的重要意义和目前常用的流失预警方案难以知晓客户流失原因的问题。
(2)介绍定义客户流失的方法和检验定义效果的思路,比较基于降级的定义和基于降幅的定义,我们推荐基于降幅的定义,同时从覆盖率和误判率两个角度检验定义效果。
(3)重点介绍了由机器学习算法+可解释算法组成的客户流失预警及归因的建模方案,其中机器学习算法部分主要是使用精度很高的机器学习二分类模型,如 LightGBM;可解释算法部分先使用 SHAP 寻找导致每个客户发生流失的重要特征,再使用 woe 量化重要特征的不同取值对流失的影响。该方案不仅有很高的精度,还能对每个流失客户进行归因,再根据流失原因制定有针对性的挽留措施,这能提高营销效果。同时以一个案例的形式展示我们的方案在银行业务场景中的应用。
(4)做出两点扩展思考:①从营销成本的角度,建议在营销成本充足的条件下进行单个客户的流失归因,在营销成本不足条件下建议进行客群的流失归因;②将单个客户的流失原因和关联规则相结合,寻找流失原因中的频繁项,再根据频繁项对未来可能出现的流失原因进行提前预防。
目录
1 研究背景
2 流失定义
2.1 基于降级的定义
2.2 基于降幅的定义
2.3 检验定义效果
2.3.1 覆盖率检验
2.3.2 误判率检验
3 流失预警及归因建模方案
3.1 流失预警建模方案
3.2 基于 SHAP 的流失归因
3.3 基于 woe 的流失归因
4 案例展示
4.1 数据准备
4.1.1 流失定义
4.1.2 数据获取
4.1.3 缺失值处理
4.2 流失预警及归因
4.2.1 流失预警模型
4.2.2 基于 SHAP 寻找导致流失的重要因素
4.2.3 基于 woe 量化特征的不同取值对流失的影响
4.3 营销建议
5 扩展思考
5.1 个体解释与客群解释
5.2 流失归因 SHAP 结合关联规则
6 全文总结参考资料
1 研究背景
在目前各行各业中,客户关系管理(CRM)中的客户流失预警一直都是非常重要的一环,在竞争激烈的银行业更是如此。一方面,金融产品同质化和利率市场化导致银行利差缩窄,各商业银行间的竞争变得非常激烈;另一方面,互联网金融自 2013 年兴起后不断蓬勃发展,互联网金融凭借其自身优势,给商业银行带来了不小的冲击。在这些背景下,银行原有个人客户(尤其是中高端客户)的忠诚度逐渐下降,流失倾向变强。客户流失对银行利润有着重大的影响,有研究表明中高端客户流失率减少 5%,利润可以增长 25%以上。例如,某银行的中高端客户有 60 万,没有采取挽留措施时每个季度的流失率是 20%,采取了挽留措施后流失率降为 10%,平均每个中高端客户每个季度对该银行的贡献是 1000 元,采取挽留措施后每个季度能给银行带来的直接利润是 6000 万,每年带来的利润是 2.4 亿。而且开发一个新客户的成本比挽留一个老客户的成本高出 3 倍不止,挽留一名即将流失的老客户比拓展一名新客户成本更低,利润也更高。如何提高客户粘性,降低客户流失率对银行来说是一件非常重要的事情。
传统的客户流失预警属于客户关系管理领域,主要是基于人工经验建立一些简单规则来判断客户是否即将流失。这类方法主要存在 2 个问题:一方面,由于识别方法仅仅是基于人工经验建立的简单规则,所以这类方法的精度不高,对流失客户的识别效果可能不够好;另一方面,由于简单的人工经验容易存在误差,所以这类方法难以获知客户流失的真正原因,制定的挽留措施没有针对性,挽留效果也不够好。
为克服传统流失预警方法的不足,学术界和工业界做出了很多探索与研究,其中统计学家将数据挖掘算法引入这一业务场景极大的改进了传统方法的不足。这些数据挖掘算法包括:逻辑回归、生存分析、时间序列等传统统计学模型;也包括聚类、支持向量机、集成模型、神经网络等机器学习算法;还包括 SHAP、lime 等可解释算法。其中,传统的统计学模型理论完备,解释性好,但是精度一般;机器学习算法精度很高,但是解释性差,可能更适合现在的高维大数据;可解释算法可以帮助我们对模型进行解释,在流失预警的业务场景中可以给出导致客户流失的原因。
为了能获得精度高、解释性好的模型,索信达公司凭借在金融大数据领域多年的行业经验和在可解释机器学习领域的探索,将可解释算法应用于流失预警模型,进一步探索出一套能进行单个客户流失归因的流失预警及归因建模方案。在该方案中,可以先使用机器学习算法建立流失预警模型识别有流失信号的客户;再使用可解释算法进行流失归因,流失归因可以具体分析每个流失客户发生流失的原因,针对其流失原因再制定相应的挽留措施,这能提高营销效果。
本文主要介绍流失预警及归因业务场景的知识,重点关注机器学习算法和可解释算法在该场景的应用。本文共分为 6 个部分:第 1 部分主要介绍本文的研究背景;第 2 部分主要介绍流失定义,重点关注如何定义客户是否流失;第 3 部分主要介绍流失预警及归因的知识,重点关注机器学习算法和可解释算法组成的流失预警及归因建模方案;第 4 部分主要以案例的形式介绍上述方案的应用,重点关注第 3 部分介绍的流失预警及归因建模方案如何与实际的业务场景相结合;第 5 部分是一些扩展思考;最后第 6 部分是对全文的总结。
注明:在包括流失预警在内的众多银行业务场景中,最常用的指标之一是 AUM,分时点值和均值两种。因为时点 AUM 有很大偶然性,比如某客户在月底将资金全部转出,但两天后又转回来,该客户月底的时点 AUM=0,月日均 AUM 确相对平稳。为保证稳定性,本研究报告中提到的所有 AUM 都指“月日均 AUM”。
2 流失定义
流失预警模型首要任务是如何定义客户是否发生流失。通常有基于降级和降幅两种定义方式,在银行的客户流失预警中,我们推荐基于降幅的方式。
2.1 基于降级的定义
一般来说,在银行的实际业务场景中,会对客户按照资产情况划分等级。例如,某银行按照如表 1 的标准进行等级划分:
表 1 某银行资产等级划分表

银行关注的客户流失通常是以降级来衡量的,即客户在某段时间内由更高的级别降低到更低的级别被认为发生了流失,这是基于银行业务层面可能会给出的定义。
但是从降级角度来定义客户流失有时可能不够合理。比如一个客户原有 AUM 为 760 万,属于黄金级别,AUM 减少了 700 万,该客户仍然属于黄金级别,从基于降级给出的定义来看,该客户没有流失,但是该客户 AUM 流失比例高达 92%,严格意义上讲这已经属于“真正的流失”了。再比如一个客户原有 AUM 为 50.5 万,属于黄金级别,AUM 减少 1 万,该客户降至白银级别,从基于降级给出的定义来看,该客户发生了流失,但是该客户 AUM 流失比例只有 2%,严格意义上看这不算“真正的流失”。所以,从业务层面给出的基于降级的流失定义有时可能不够合理,我们推荐使用降幅来定义流失。
2.2 基于降幅的定义
基于降幅的定义重点是要寻找到一个合适的阈值,当客户的 AUM 流失比例达到(或超过)该阈值时被认为发生流失。我们可以先如表 2 的形式计算某月较上月发生资产减少的客户资产降幅的分布情况:
表 2 第 i 月较第 i-1 月发生资产减少的客户资产降幅分布情况表
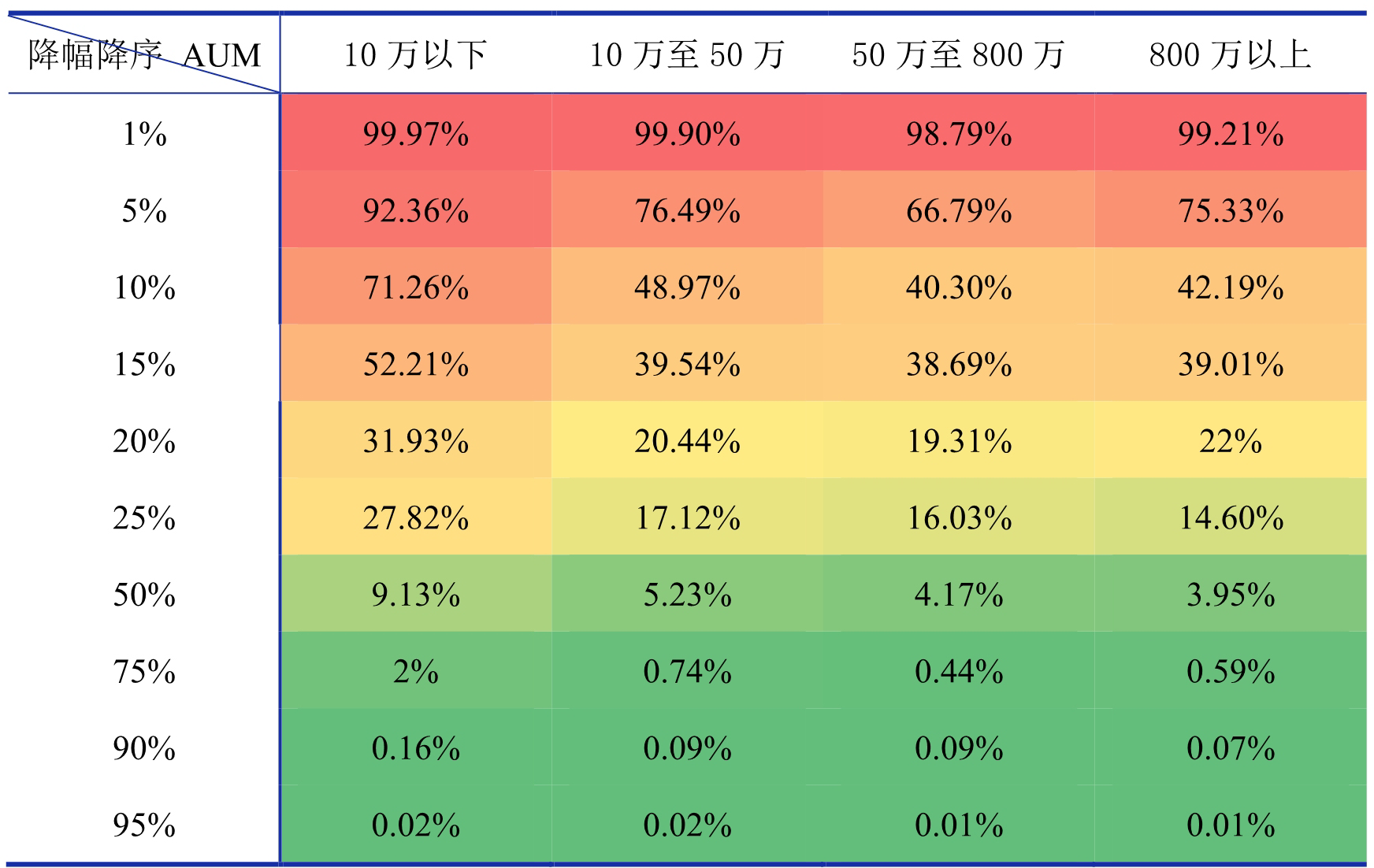
表 2 每行代表降幅最严重的前百分之几,每列按照表 1 的资产等级进行划分。例如,横轴取“25%”,纵轴取“10 万至 50 万”的值为 17.12%,该值的含义表示在当月 AUM 为 10 万至 50 万的客户中流失最严重的前 25%的客户的 AUM 较上月的平均降幅为 17.12%。通常我们会对比连续 3 个月的数据,计算第 i 月对比第 i-1 月和第 i-1 月对比第 i-2 共计 2 张发生资产减少的客户资产降幅分布情况表用于查看资产降幅的变化情况是否稳定。
在连续 3 个月资产降幅变化稳定的情况下,我们一般会查看流失最严重的前 10%、15%、20%和 25%这几档的平均降幅,结合业务需求来确定合适的阈值。比如,业务上通常希望能挽留尽可能多的流失客户,但是流失客户过多营销人员的维护压力会很大,所以,通常考虑挽留降幅最严重的前一部分客户。例如,综合考虑下,该业务需求希望挽留流失最严重的前 15%的客户,这部分客户的资产降幅情况对应表 2 第 4 行,这种情况下我们结合表 2 的结果初步给出的定义为:AUM 处于 10 万以下的客户降幅达到 50%及以上的认为发生流失;AUM 位于 10 万以上的客户降幅达到 40%或以上的认为发生流失。
2.3 检验定义效果
在使用降幅初步定义流失后,一般需要通过查看降幅定义对降级客户的覆盖率和降幅定义的误判率来进一步检验其合理性。
2.3.1 覆盖率检验
因为在银行的客户流失业务场景中,客户发生流失最直观的表现就是发生降级,所以,银行从业务层面给出的定义通常是“是否发生降级”。虽然我们在前面分析了直接以降级来定义流失有时可能不够合理,但出于银行业务需求的考虑,我们建议查看基于降幅给出的定义对降级客户的覆盖率来进一步说明降幅定义的理性。可以如表 3 所示的内容计算降幅定义与降级的关系:
表 3 基于降幅给出的流失定义对降级客户的覆盖率表
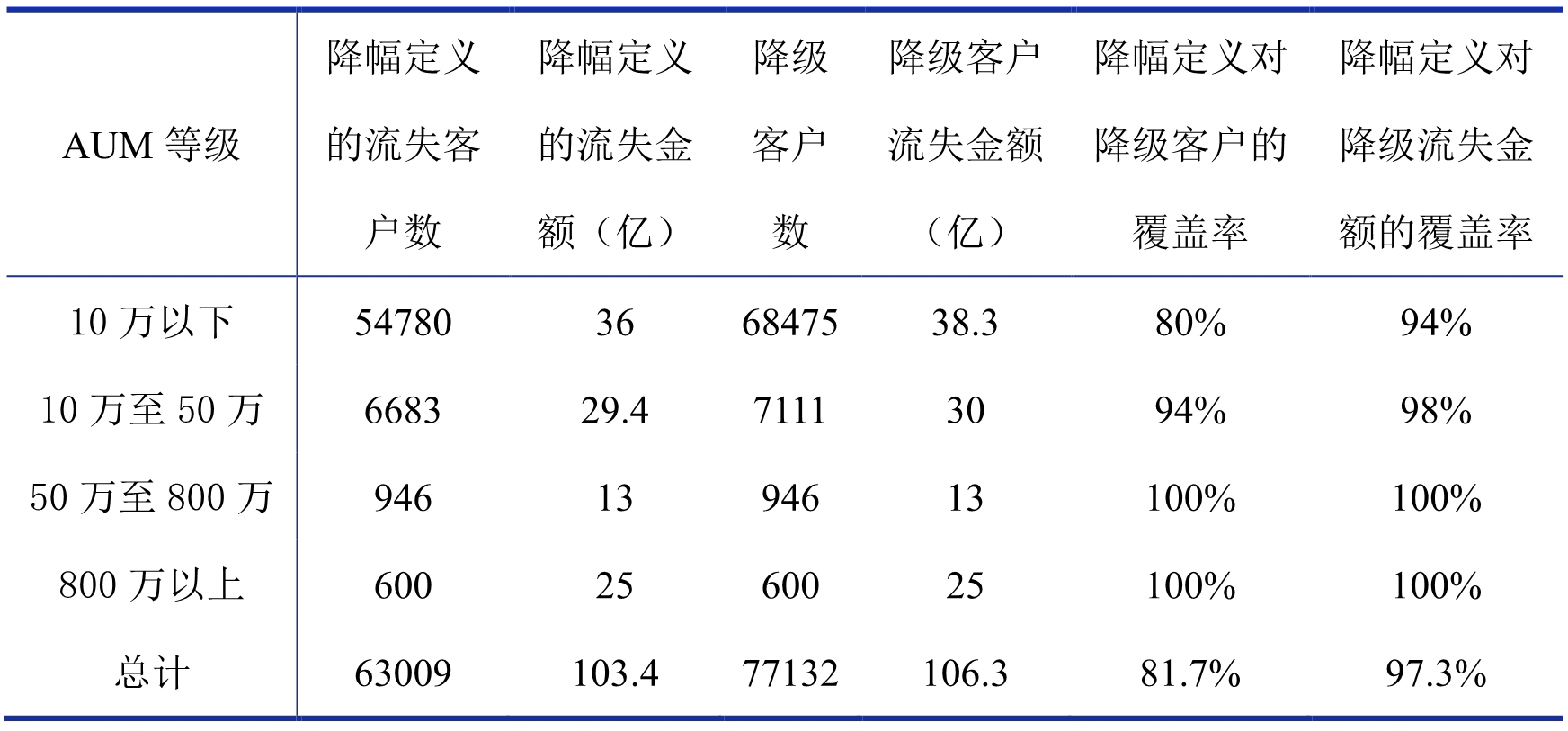
注:为保证覆盖率结果的准确性,表 3 中降幅定义的流失客户和流失金额都剔除了满足降幅定义但未发生降级客户的数据。例如,某 AUM 在 800 万以上的客户 AUM 降幅为 90%,但未发生降级,如果该客户没有被剔除,此时降幅定义的客户数和降级客户数虽然都是 600,但不表示降幅定义的客户对降级客户的覆盖率为 100%,这会导致覆盖率的结果会变得混淆。
通过表 3,我们可以看到基于降幅给出的流失定义对降级客户的覆盖率很好:降幅定义对降级客户的覆盖率有 81.7%、对降级流失金额覆盖率达到 97.3%;而且 50 万以上的客户降幅定义对降级客户和降级流失金额的覆盖率都达到了 100%,这说明该定义与银行业务需求有很好的契合度。
2.3.2 误判率检验
在银行业务场景中,有一些客户发生流失后资产可能会在未来回升,所以我们需要查看基于降幅定义的流失客户在未来的资产回升水平来评估误判率,可以由表 4 的方式计算客户资产在第 i 月流失后在未来两个月内回升至第 i 月水平的关系:
表 4 客户资产在第 i 月流失后在未来两个月内回升至第 i 月水平的关系表
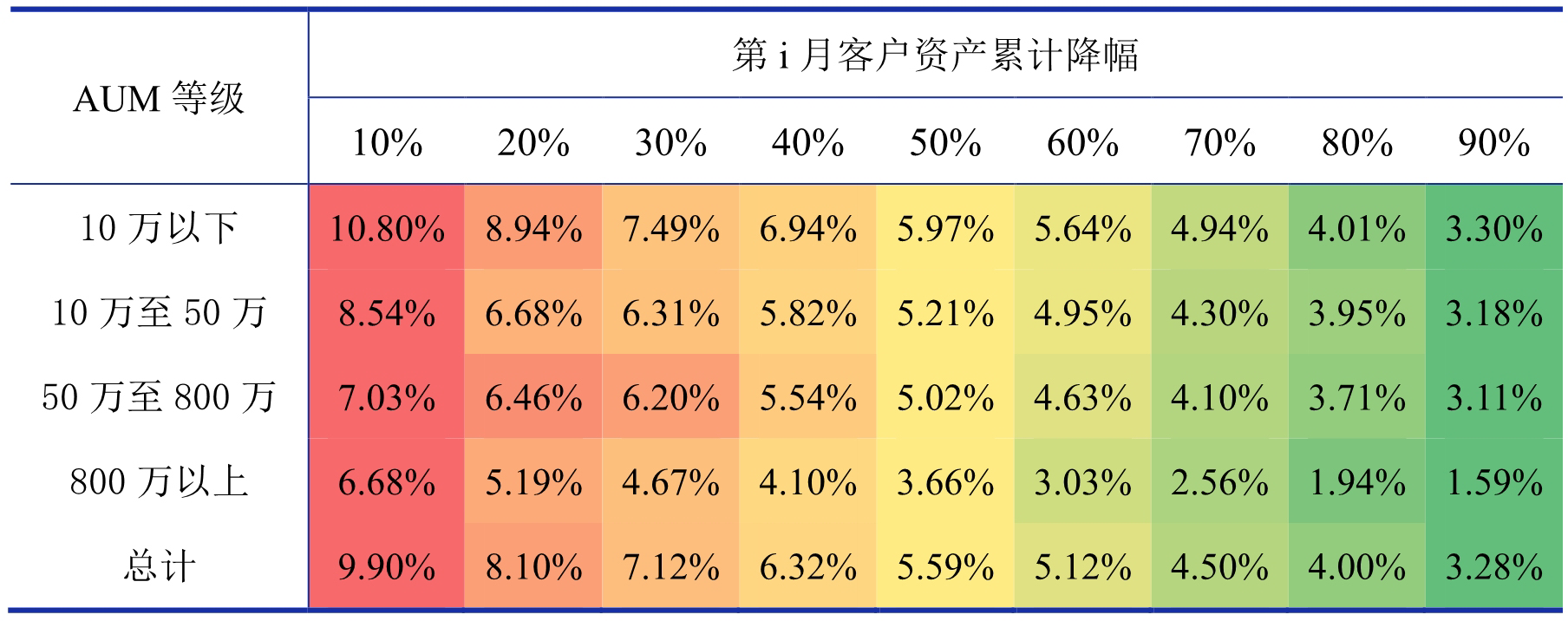
在表 4 中,如横轴取“10 万至 50 万”,纵轴取“20%”的值为 6.68%,该值的含义表示在第 i 月按照降幅定义发生流失的客户在未来 2 个月内有 6.68%的比例会回升至第 i 月的水平。我们之前定义:AUM 处于 10 万以下的客户降幅达到 50%及以上的认为发生流失;AUM 位于 10 万以上的客户降幅达到 40%或以上的认为发生流失。从表 4 可以看出,根据此定义,仅有不到 6%的客户在资产流失后的 2 个月内资产会回升到流失前,这说明我们根据降幅得到的流失定义误判率很低。
在经过降级客户覆盖率和误判率检验后,我们认为之前按照降幅得到的流失定义具有很好的合理性。实际的项目中,我们也建议按照本节介绍的基于降幅的思路来定义流失,但是在初步定义好之后需要进行降级客户覆盖率和误判率检验来进一步检验定义的合理性。
3 流失预警及归因建模方案
流失预警模型目前业内的主流方案主要是使用机器学习模型学习历史数据的规律,再用得到的模型对未来数据进行预测。流失归因主要是借助一些可解释算法来实现的。我们将可解释算法应用于流失预警模型,进一步探索出一套能进行单个客户流失归因的流失预警及归因建模方案,该方案最大特点在于它可以对每个流失客户进行归因,再根据每个客户的流失原因制定挽留措施,从而提高营销效果,本节主要介绍该方案的理论知识。
3.1 流失预警建模方案
目前业内主流的流失预警的建模方案主要是基于机器学习模型搭建的。我们首先介绍常规的建模方案流程,如图 1 所示:
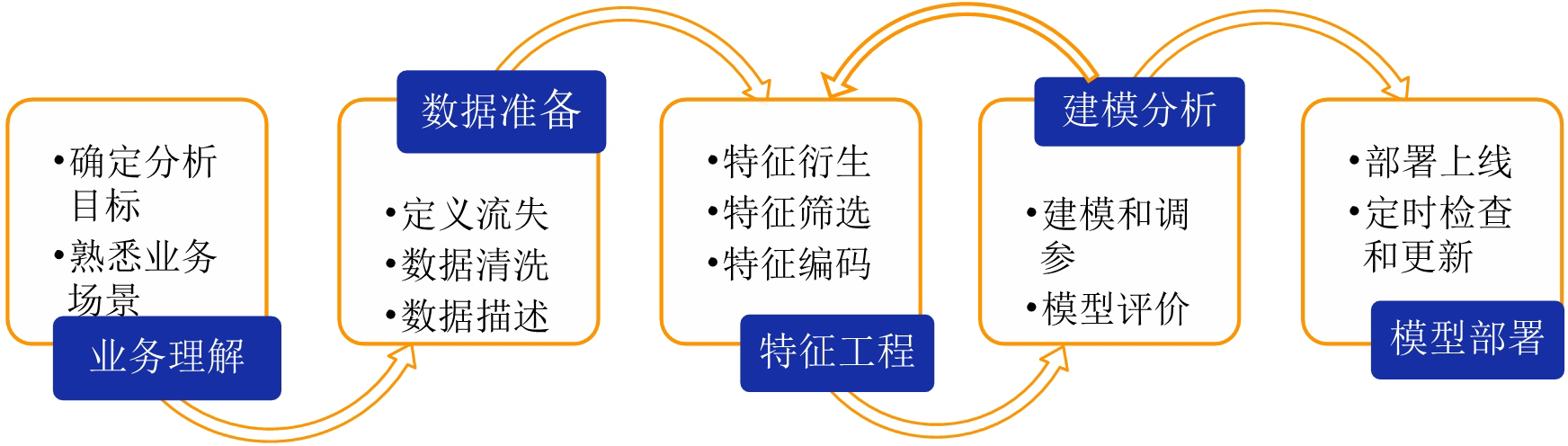
图 1 流失预警建模方案流程图
图 1 所示的建模方案中比较重要的步骤是数据准备、特征工程和建模分析,接下来对这 3 个部分再做进一步介绍。
① 对于数据准备部分,流失的定义方法在第 2 节已经进行过详细的介绍,这里重点介绍关于数据时间窗口划分的方法:在流失预警建模中,我们通常会把数据按照时间窗口划分为观察期和表现期:
观察期是收集用户行为信息的时间窗口,通常是 6 至 12 个月,用此期间的数据进行建模。表现期是评价模型效果的时间窗口,通常是 3 个月,用观察期的数据建立的模型预测用户在表现期的结果,将预测结果与用户在表现期的实际结果进行对比来评价模型的效果。二者的时间顺序关系如图 2 所示:

图 2 观察期和表现期的时间顺序关系图
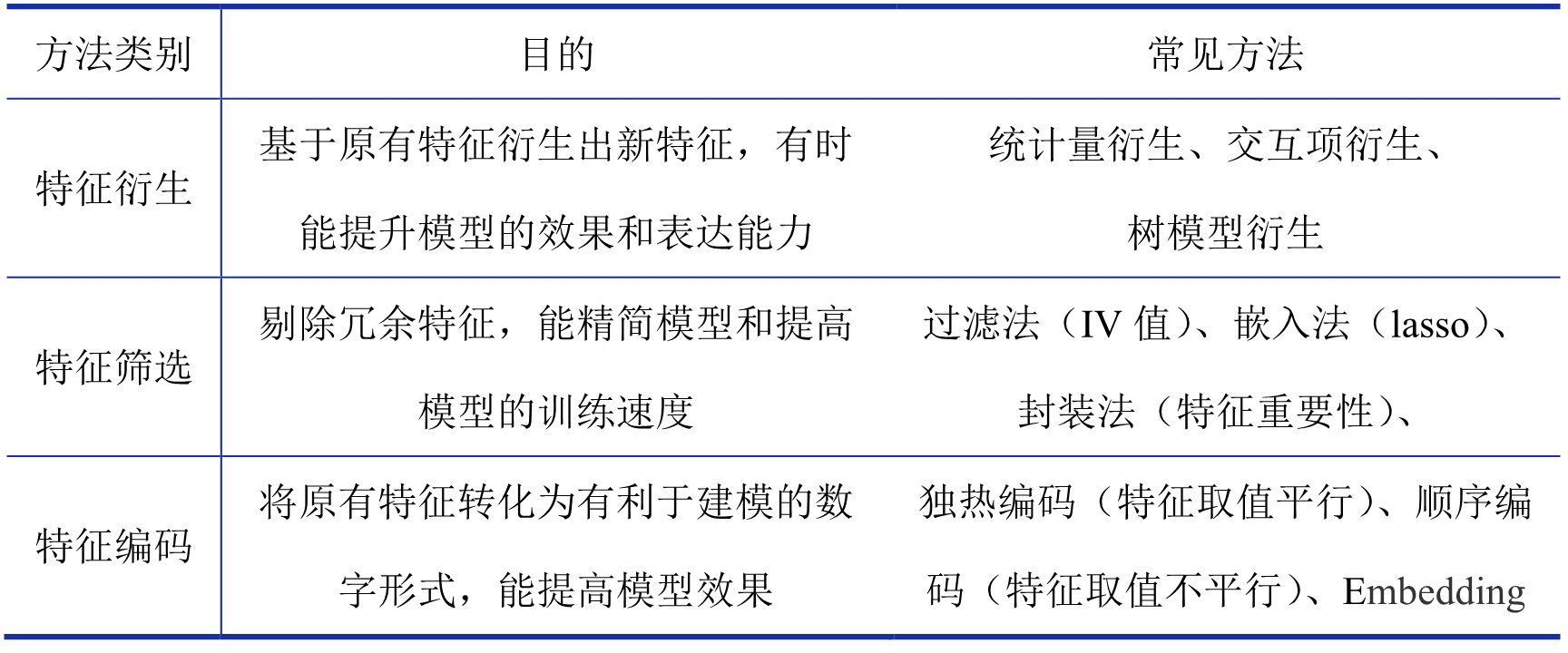
② 对于特征工程部分,主要包括特征衍生、特征筛选、特征编码共 3 块内容,这些内容的常见处理方法如表 5 所示:
表 5 特征工程常见方法汇总表
③ 对于建模分析部分,李航老师的《统计学习方法》一书中对常见的模型有很全面的介绍,我们这里只简要介绍常见的建模方法及其主要优缺点,如表 6 所示:
表 6 常见建模方法汇总表
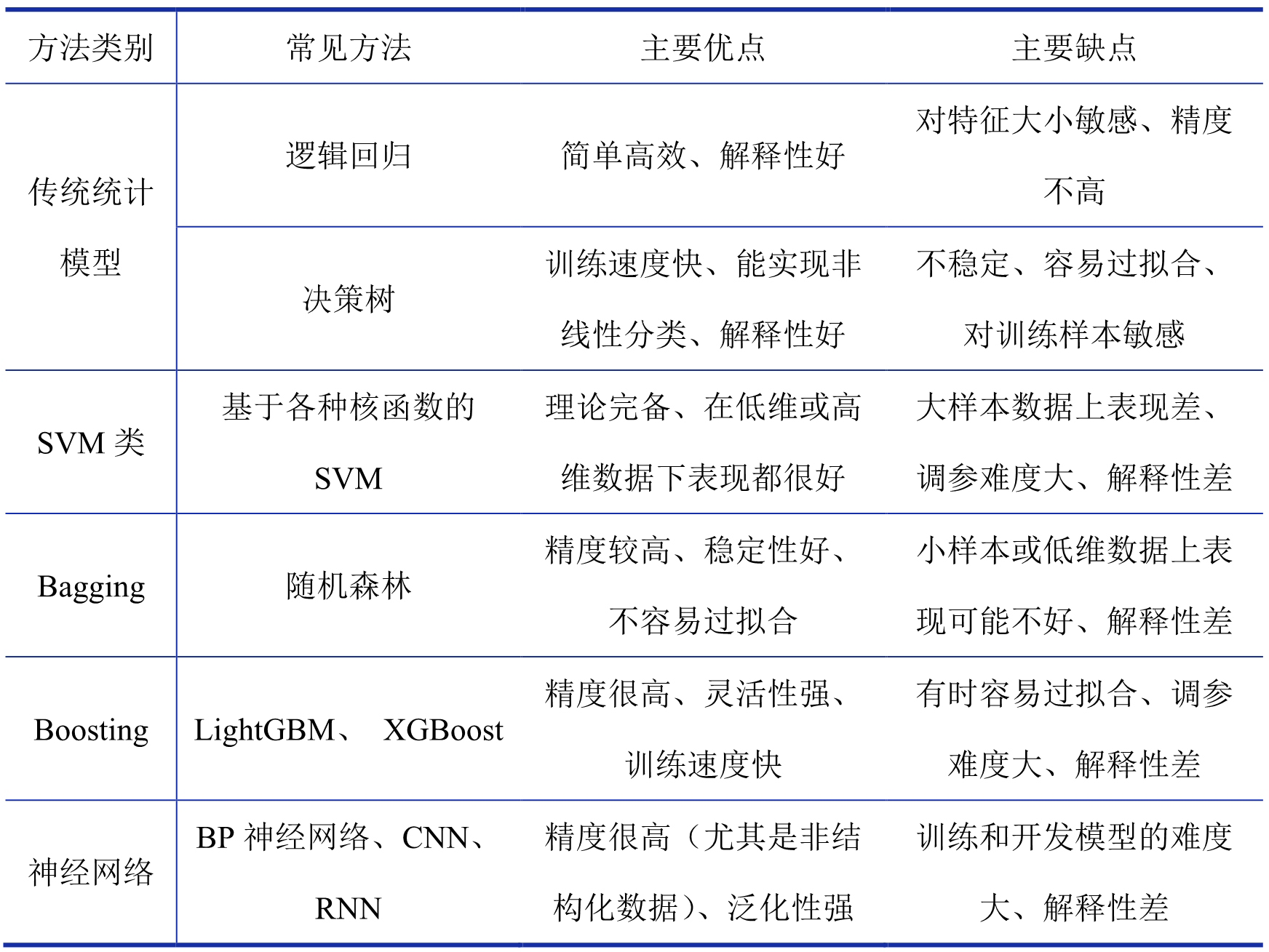
在大数据时代的银行的业务场景中,数据往往呈现出高维和量大的特点,为了保证模型的精度和计算效率,我们更推荐使用 XGBoost 和 LightGBM 这两种算法作为流失预警模型。
需要注意的是,在流失预警的场景中,我们通常更关注模型对流失客户的识别效果,即流失客户中有多少能被模型识别出来,识别效果可以通过召回率(Recall)来评价,Recall 越高,识别效果越好。当模型的 Recall 较低时,可以使用加权损失函数来训练模型:在模型的损失函数中,将流失客户误判为不流失客户这种情况的误判权重变大。
除逻辑回归和决策树以外的常见机器学习模型普遍都存在可解释性差的问题,即“黑盒模型”问题。使用这些模型虽然能获得很高的精度,但我们却难以从业务上对模型结果进行解释,在流失预警的业务场景中表现为,虽然这些模型能很好捕获到客户即将流失的信号,但是难以得到客户流失的原因,从而挽留措施不够有针对性,营销效果不够好。所以我们将在下一节流失归因部分介绍一些可解释算法,将可解释算法与流失预警模型结合进行流失归因,再根据流失原因制定有针对性的挽留措施,提高营销效果。
3.2 基于 SHAP 的流失归因
本文的流失归因主要是通过一些可解释算法实现的,我们先使用可解释算法 SHAP 完成流失归因的第一步。索信达公司的 AI 创新中心之前发布的《可解释机器学习研究报告》对包括 SHAP 在内的多个可解释算法进行过详细的介绍,我们这里只简要介绍 SHAP 的基本原理,同时重点关注 SHAP 在流失归因中的应用。
SHAP(SHapley Additive exPlanation)是一种事后可解释算法,最早起源于加州大学洛杉矶分校的 Lloyd Shapley 教授(2012 年诺贝尔经济学奖获得者)在博弈论领域提出的 Shapley Value 的思想,后续的一些学者基于这一思想提出了适用于机器学习领域的事后可解释算法 SHAP。SHAP 的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释,SHAP 理论完备,表达直观,还能展示特征间的交互作用,下面我们以举例的方式简要说明 SHAP 的基本原理:
例如,对于某项任务,现在共有 3 个人(X、Y、Z)可以被安排完成该任务,且已知:
① 将该项任务单独或以任意组合的形式分配给这 3 个人时,各种情况下的产出 C(Contribution):
将工作单独分配给 1 个人时,单个人的产出 C(X)=20,C(Y)=10,C(Z)=20;
将工作分配给 2 个人合作时,任意 2 人的合作产出 C(X,Y)=30,C(X,Z)=50,C(Y,Z)=60;
将工作分配给 3 人合作完成时,3 人合作的产出是 C(X,Y,Z)=100。
② 当 3 人的合作顺序为 X→Y→Z 时,可以计算此合作顺序中 3 人的边际贡献 MC(Marginal Contribution):
MC(X)=C(X)=20;
MC(Y)=C(X,Y)-C(X)=30-20=10;
MC(Z)=C(X,Y,Z)-C(X,Y)=100-30=70。
③ X、Y、Z 这 3 个人的合作顺序共有 6 种,X→Y→Z 只是其中的一种,我们按照同样的方法计算所有顺序下 3 个人各自的边际贡献及其平均值,结果如表 7 所示:
表 7 SHAP 值原理举例表
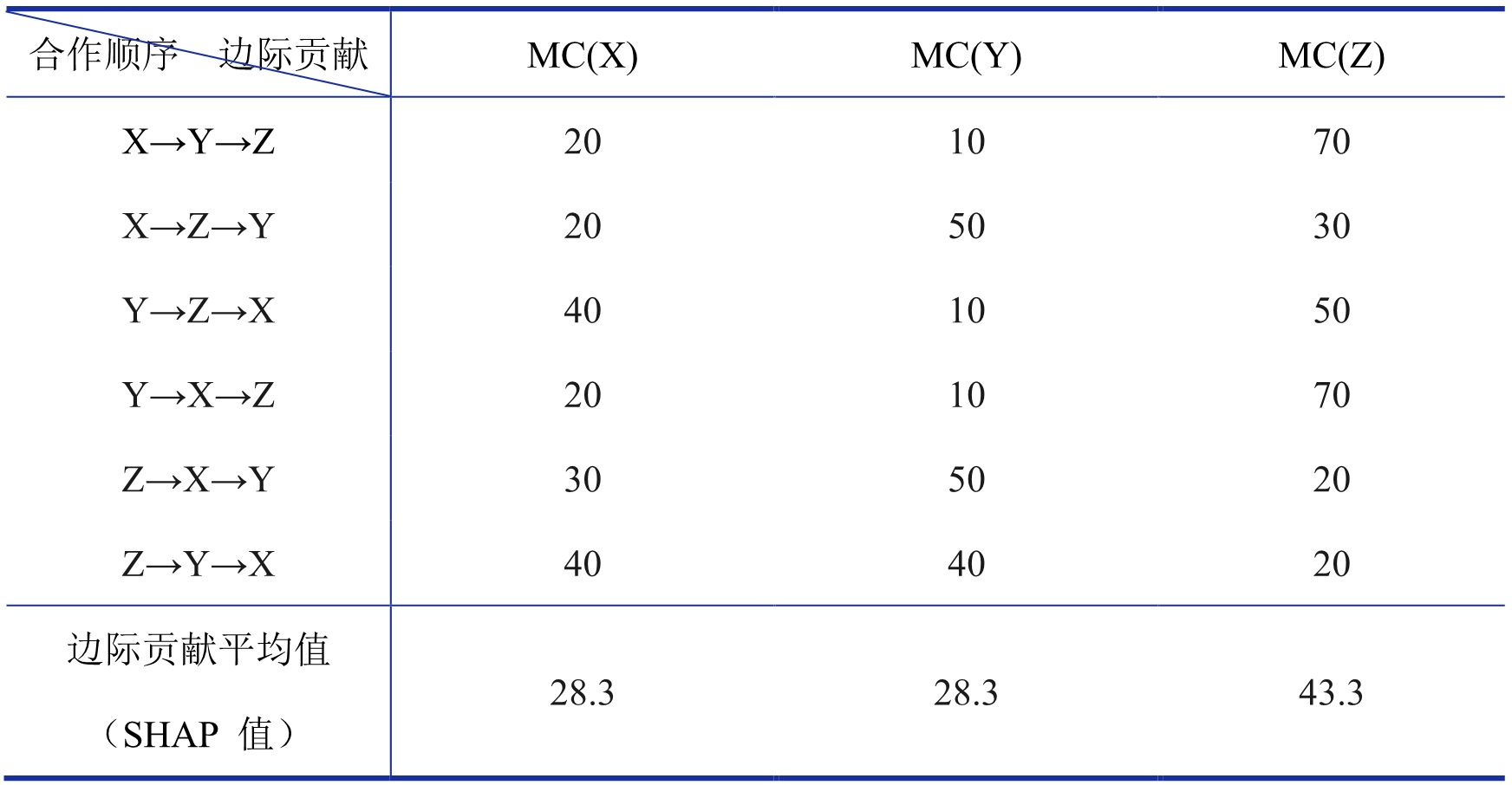
我们可以按照上述案例的思路来简单理解 SHAP 的基本原理:①可以将案例中的参与者 X、Y、Z 视作建模用到的特征;②将参与者的合作视作一次建模;③将参与者合作的产出视作模型的输出值;④从而每个参与者的边际贡献平均值就是每项特征对应的 SHAP 值。并且可以从总体和局部两个层面计算每项特征的 SHAP 值:总体层面得到的 SHAP 值类似于“树模型”中的特征重要性,这可以用于衡量特征在该模型的重要程度;局部层面得到的 SHAP 值可以对每个样本计算每项特征对模型输出的影响,这可以用于解释每个样本预测结果是由哪些特征如何导致的。
本文流失归因的目标是想要分析每个被预测为流失的客户为什么会流失,可解释算法 SHAP 的局部解释可以解释每个样本的预测结果是由哪些特征如何导致的,所以我们可以先使用 SHAP 分析每个客户被预测为流失时各个特征的影响程度。Python 的 SHAP 库对每个样本预测结果的归因解释具有很好的可视化效果,如图 3 所示:
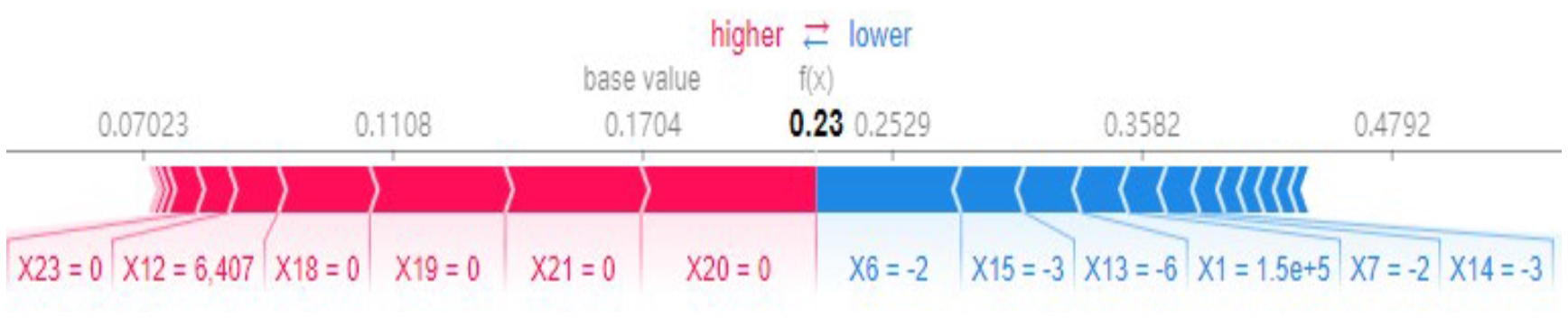
图 3 SHAP 对单个样本预测结果的归因解释图
图 3 的样本预测为正的概率为 0.23,取预测概率的阈值为 0.5 时,该样本预测结果为负。SHAP 库将各个特征对预测结果的影响用使用加性的方式来表示:图 3 左边的红色部分表示对预测结果有正向影响的特征,右边的蓝色部分表示对预测结果有负向影响的特征,白色的箭头是各个特征之间的分割线,特征的长度表示其影响大小。我们可以看到取值为 0 对该样本具有最大正向影响,取值为-2 对该样本具有最大负向影响,其他特征也如此分析,最后在所有特征的共同作用下得到预测结果为 0.23。
理论上,我们可以使用图 3 这样的单个样本预测结果的归因解释图对每个流失客户进行分析,但实际操作中银行的客户数量(哪怕是重点客户)通常都比较多,其中流失的数量可能也不少。由于数量过于庞大,按照图 3 的方式逐个进行分析在实际操作中很难实现。
从图 3 可以看到,有些特征对预测结果的影响程度很大,有些特征对预测结果的影响程度很小,为简化分析,我们可以用一部分影响程度最大的特征代替全部特征。这里可以先计算每个流失客户 SHAP 值取值为正的各个特征的占比并按降序排序(取值为负的 SHAP 值表示其导致客户不流失,这里只用取值为正的),其中每个流失客户的第 i 个特征的 SHAP 值占比)。然后再计算每个流失客户按 SHAP 值占比降序后前几个特征的占比之和,保留使 SHAP 值占比之和达到 90%(或以上)时数量最小的前几个特征作为导致其流失的重要特征,其余特征的影响程度比较小,忽略不计。
至此,我们完成了流失归因的第一步,我们使用可解释算法 SHAP 得到了每个流失客户被预测为流失时影响最大的几个因素。但我们还不清楚每个因素的不同取值对预测结果的影响程度,接下来我们将使用 woe 来分析各个特征的不同取值对流失的影响,再在基于 SHAP 得到的导致客户发生流失的几个重要因素中进行匹配,从而量化客户发生流失是由于他们在某些影响流失的重要特征上的取值达到多少。
3.3 基于 woe 的流失归因
我们已经通过 SHAP 得到了导致每个流失客户发生流失最重要的几个特征,接来下我们将使用 woe 分析每个因素的不同取值对预测结果的影响程度,进一步完成流失归因。
Woe(weight of evidence)是信用评分模型常用的一种编码方法,其基本原理为:对于某个离散特征(连续特征先分箱,推荐使用卡方分箱或者基于决策树的分箱),有:
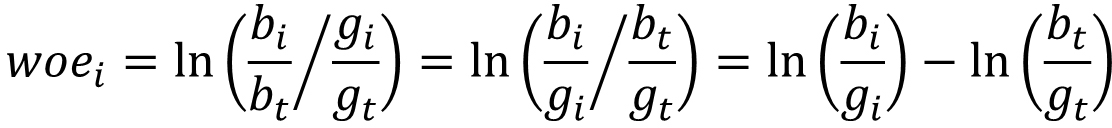
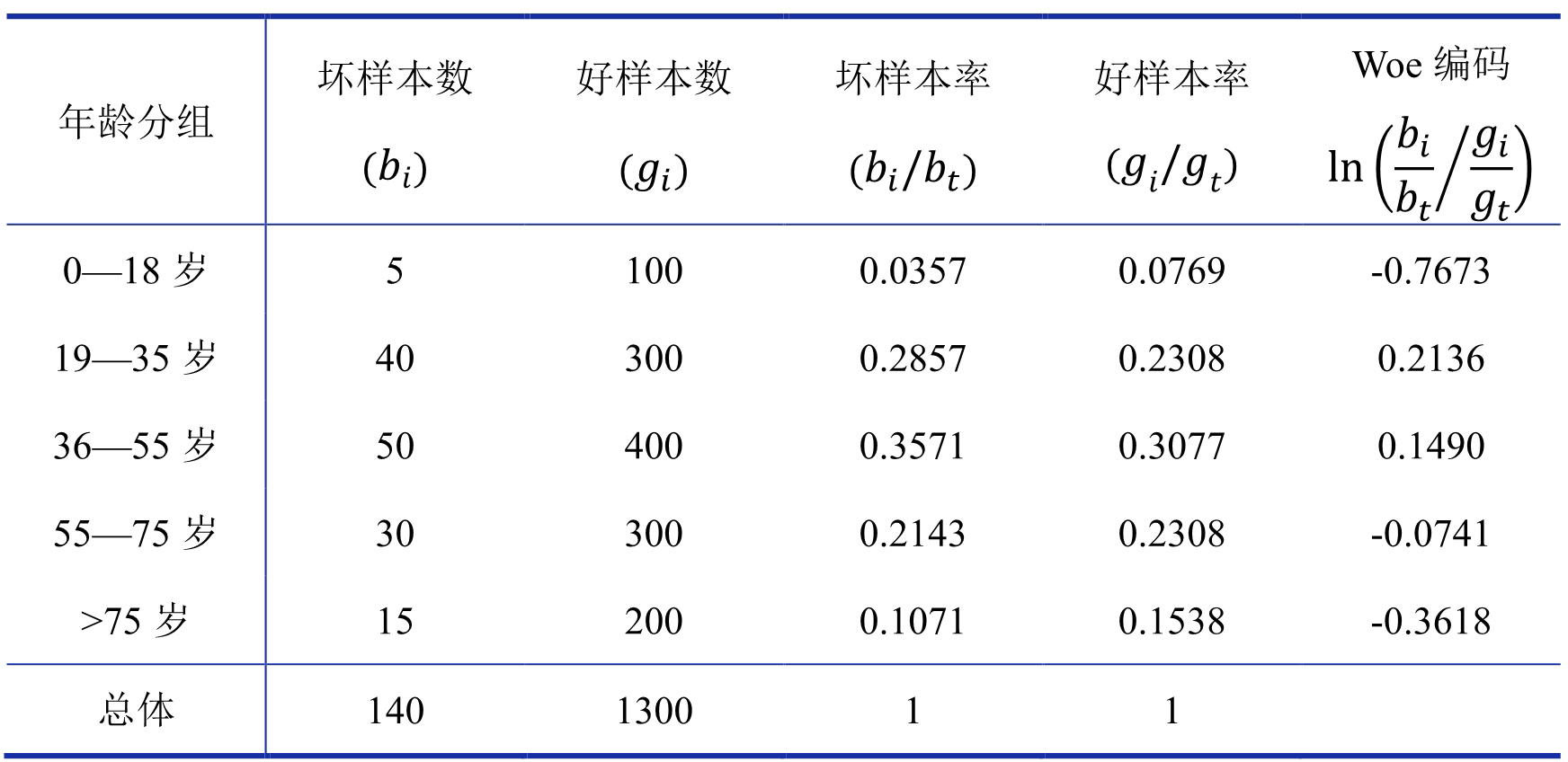
其中,表示当前组的坏样本数,表示当前组的好样本数,表示所有样本中的坏样本数,表示所有样本中的好样本数。表示当前分组(第 i 组)中坏样本和好样本的比值与所有样本中这一比值的差异,woe 值越大表示种差异越大,从而该分组内的“坏样本/好样本”比平均水平越高,该分组内的坏样本可能性更大。我们以年龄为例,展示 woe 对特征进行编码的计算过程,结果如表 8 所示:
表 8 woe 编码计算举例表
我们可以对每个流失客户导致其发生流失最重要的几个特征进行 woe 编码,某个特征经 woe 编码后,某区间内的 woe 值越大,表示该特征取值落在该区间内越可能导致流失。我们可以据此分析出哪些重要特征的取值达到哪些范围有可能导致流失,从而量化流失原因。在实际操作中,还需要把量化后的流失原因转化成符合业务逻辑的语言,得到适用于实际业务场景的流失原因。
在得到具体的流失原因后,我们再根据流失原因来建立有针对性的挽留措施,从而提高营销效果,流失归因方法具体的应用将在下一节的案例部分进行展示。
4 案例展示
本节将以案例的形式展示第 3 节流失预警及归因方案所介绍的方法在实际业务场景中的应用。为说明本文流失预警及归因方案在银行业务场景中的应用效果,本章案例使用的是银行真实场景中的数据。出于保密性,案例中的数据不能公开,建模结果在隐藏了需要保密的信息后再进行介绍和分析。
本案例中某银行的 VIP 客户流失严重,原有挽留措施的营销效果不好,使用本文介绍的流失预警及归因方案来解决这一问题:先使用精度很高的流失预警模型来捕捉有流失信号的客户,再使用可解释算法分析每个客户的流失原因,最后根据流失原因建立有针对性的挽留措施,提高营销效果。
4.1 数据准备
4.1.1 流失定义
本案例中,AUM 流失比例大于或等于 50%的客户被定义为流失客户(目标变量),否则为不流失客户(目标变量)。
4.1.2 数据获取
取某个时间点为观测点,取观测点前 6 个月为观察期,取观测点后 3 个月为表现期,取观察期和表现期内的客户相关数据作为本案例的原始数据。
4.1.3 缺失值处理
结合数据的实际意义,本节案例使用了两种方法来填充数据:对于像“客户购买理财产品金额”这类数据,因为缺失在业务上意味着没有购买,所以这类特征的缺失值填 0;对于像“理财产品未来到期时间”这类数据,因为缺失也意味着没有购买,如果填 0 则表示当天到期,这与实际业务含义不符合,所以这类数据直接填一个非常大的数表示缺失,如填 99999。
4.2 流失预警及归因
4.2.1 流失预警模型
为了保证模型的精度和计算效率,本节案例使用 LightGBM 作为预测客户是否流失的二分类模型,同时使用 AUC、KS 和 Recall 来评价模型。模型在观察期测试集数据上和表现期数据上的精度都很不错,而且在表现期的精度只略低于观察期测试集的精度,说明该模型稳定性也很好,具体结果如表 9 所示:
表 9 流失预警模型精度表

4.2.2 基于 SHAP 寻找导致流失的重要因素
在流失预警模型精度达到要求后,先使用可解释算法 SHAP 寻找导致每个客户流失的重要因素。这里使用 3.2 小节介绍的方法先计算每个流失客户 SHAP 值取值为正的各个特征的占比并按降序排序,保留使 SHAP 值占比之和达到 90%(或以上)时数量最小的前几个特征作为导致客户流失的重要特征。出于数据的保密性和篇幅限制,这里以 3 个客户为例,展示导致这 3 个客户流失的重要特征,具体结果如表 10 所示:
表 10 导致客户流失的重要特征举例表
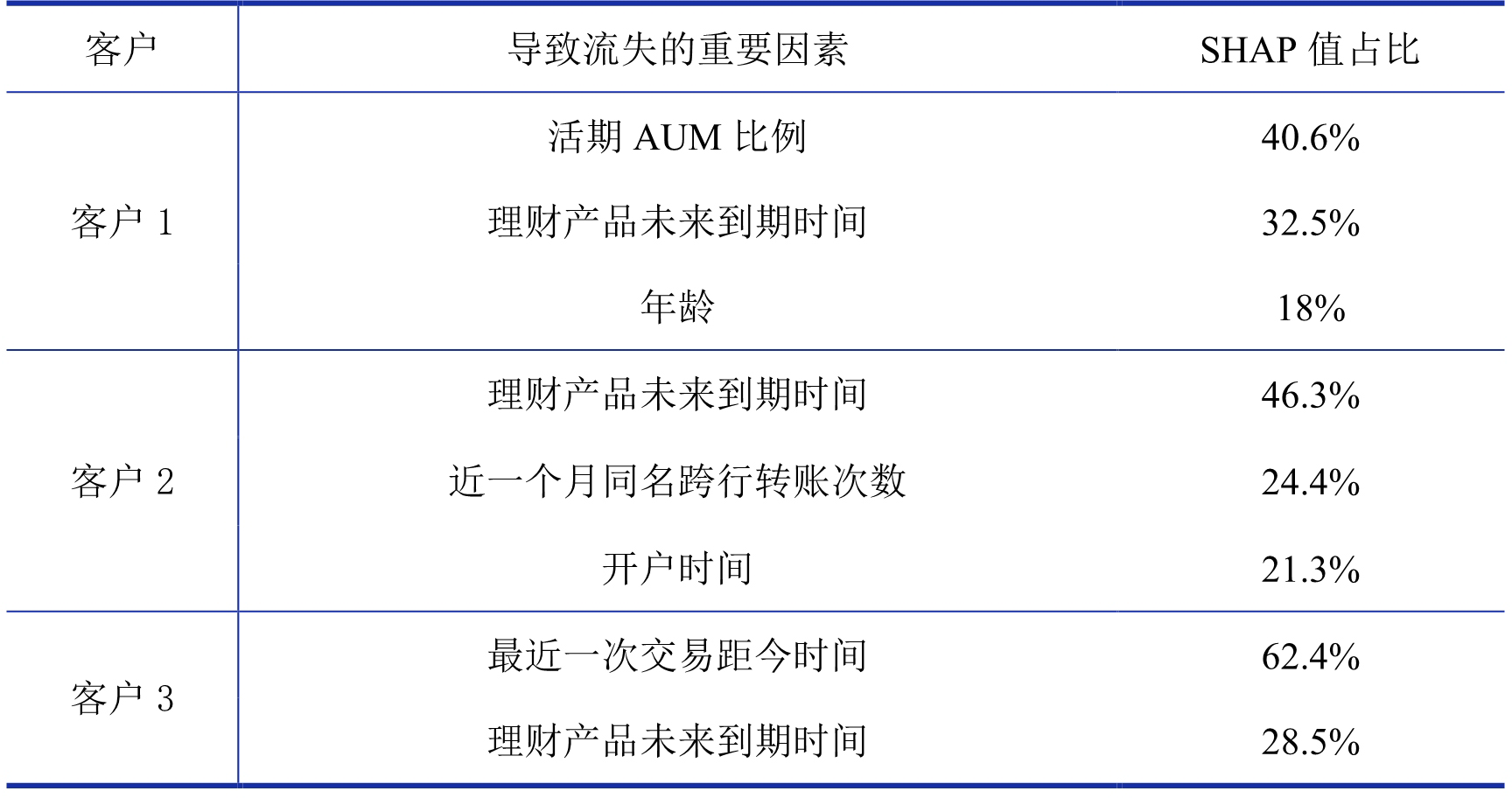
表 10 中的第二列(导致流失的重要因素)中,以时间结尾的特征的取值单位都是“天”。其中,理财产品未来到期时间表示客户拥有的理财产品在未来到期的时间距离现在的天数,如理财产品未来到期时间=3,表示 3 天后有理财产品到期。
本案例保留下来的导致每个流失客户发生流失的重要特征为 2~6 个。需要注意的是,为减小计算量,从业务层面看,只需要对被预测为流失的客户进行流失归因,而不是每个客户。
4.2.3 基于 woe 量化特征的不同取值对流失的影响
在使用 SHAP 寻找到导致流失的重要因素后,我们再使用 3.3 小节介绍的基于 woe 的方法来量化特征的不同取值对流失的影响,进一步完成流失归因。
出于数据的保密性和篇幅限制,这里我们以案例中的 3 个特征为例,展示其经 woe 编码后如何量化流失原因和如何将量化结果转化成符合业务逻辑的语言,具体分析结果如表 11 所示:
表 11 woe 编码转化为流失原因举例表
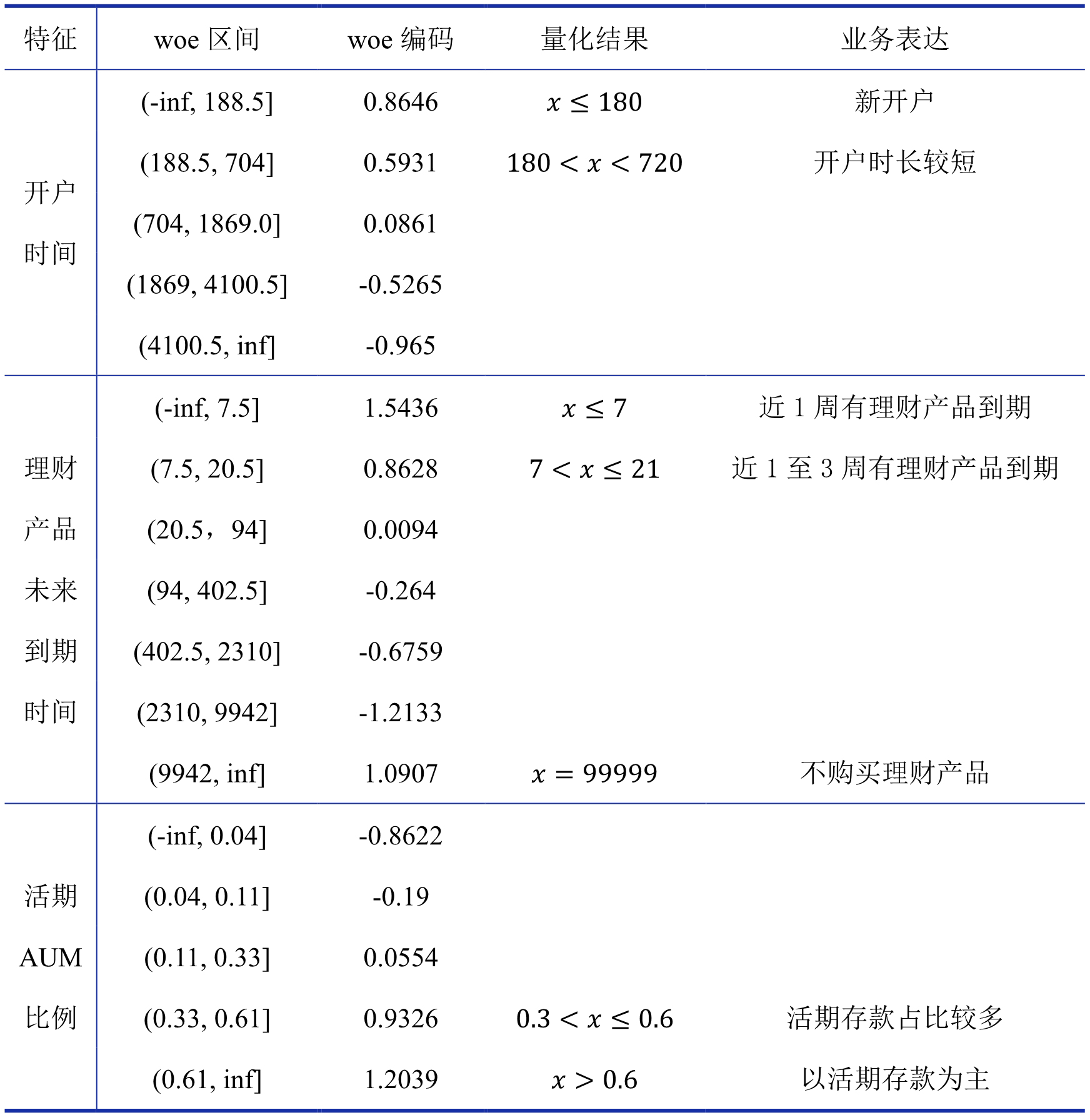
从表 11 可以看到,开户时间越小的区间对应的 woe 编码越大,这表明开户时间越小的客户越可能流失,而开户时间越长的老客户越不可能流失;理财产品未来到期时间也是越小的区间对应的 woe 编码越大、缺失值所在的区间(4.1.3 小节有介绍该特征缺失值填 99999,对应区间为(9942, inf])对应的 woe 编码也很大,这表示理财产品到期时间越近和当前没有购买理财产品的客户越容易流失,而理财产品到期时间还很久的客户不容易流失;活期 AUM 比例越大的区间对应的 woe 编码越大,由于活期 AUM 的转出门槛比定期 AUM 和理财产品低,所以活期 AUM 比例越大的客户越容易流失,活期 AUM 比例越小的客户越不容易流失。需要注意的是,表 11 中 woe 编码接近 0 表示落在该区间内的特征值对流失的影响很小,woe 编码小于 0 表示落在该区间内的特征值对流失有负向影响(不流失),所以表 11 中的量化结果和业务表达只选取了 woe 编码比 0 稍大一些的区间,woe 编码接近 0 或小于 0 的区间不进行导致客户流失的归因分析。
我们对每个流失客户导致其流失的重要因素都按照表 11 的方式进行 woe 编码,并将量化结果转化成符合业务逻辑的语言后,可以得到符合业务逻辑的流失原因。下面在表 10 的基础上列举的 3 个客户的流失原因,如表 12 所示:
表 12 客户流失原因举例表

至此,我们已经分析了每个客户的流失原因,接下来将针对每个客户的流失原因给出对应的挽留营销建议。
4.3 营销建议
我们已经使用可解释算法得到每个流失客户发生流失的原因,接下来我们将针对这些流失原因给出相应的营销建议。这里以表 12 列举的流失客户为例给出相应的营销建议。
对于客户 1:该客户的流失原因是①以活期存款为主、②不购买理财产品、③年轻客户。我们先对该客户进行简单的客户画像:该客户的存款以活期居多,而且还比较年轻,可能是因为年轻人的理财意识比较弱,所以没有购买理财产品。针对这样的客户,我们建议向他推送一些理财的科普文章,也可以安排销售人员通过电话或者手机银行 APP 线上客服的方式向他介绍一些理财知识和简单的理财产品,先提高其理财意识;再介绍一些风险低的理财产品,进一步培养客户的理财兴趣和忠诚度,将活期存款逐步转化为理财产品或其他金融产品的形式。
对于客户 2:该客户的流失原因是①近一周内有理财产品到期、②近一个月同名跨行转账超过 5 笔、③新开户。我们也对该客户进行简单的客户画像:该客户是新开户,近一个月有频繁的同名跨行转账,说明该客户近期将资金从本银行转到了他名下其他银行的账户中,再加上最近一周有理财产品到期,我们推测他很有可能在这笔理财产品到期后也会将到期的资金转出。针对这样的客户,可能他开户时间不久,对本银行的理财环境还不熟悉,购买的理财产品收益率没有达到预期,所以他才把资金转到其他银行。我们建议查看他近期理财产品的收益率是否太低,向他推荐收益率更高的理财产品。
对于客户 3:该客户的流失原因是①近半年没有交易、②不购买理财产品。我们同样对该客户进行简单的客户画像:该客户最近半年都没有发生过交易,属于不活跃客户,而且没有购买理财产品,这会进一步导致他不活跃。针对这样的客户,我们建议把近期的优惠活动优先推送给他,先吸引他提高活跃度;再评估其理财偏好,根据理财偏好的结果给他推送相应的理财产品提高用户粘性。
5 扩展思考
5.1 个体解释与客群解释
为说明我们探索的流失预警及归因方案的应用价值和提高流失客户的挽留效果,我们对每个流失客户的流失归因进行了解释(个体解释),再针对不同流失原因制定针对性的挽留措施。但是在实际的业务场景中,除了模型的效果,还需要考虑实际的营销成本。
在营销成本充足的情况下,我们建议对每个客户进行流失归因和挽留,这样有针对性地挽留,营销效果会更好。但是当营销成本不足时,比如负责营销的工作人员难以“一对一”维护大量的客户时,由于很多客户之间的流失原因可能存在一定程度的相似性,我们可以将客户进行分群,再在各个客群内使用可解释机器学习算法分析不同客群的流失原因(客群解释),为每个客群制定相应的挽留措施,最后对每个客群的客户统一进行营销,这样可以节省营销成本。
5.2 流失归因 SHAP 结合关联规则
表 12 给出了导致每个流失客户发生流失的原因。我们尝试换个角度看待这个问题:可以将流失客户视作在超市购物的人员,导致其流失的因素就是每个客户的购物篮,那么表 12 的结果是适用于关联规则算法的“购物篮数据”。
关联规则算法可以用于发现购物篮中的频繁项,我们也可以使用关联规则寻找流失原因中的频繁项,根据频繁项对一些未来可能出现的流失原因进行提前预防。简单的分析思路如下:
① 对流失客户进行分群,每个客群内每个客户的流失原因是一条“购物篮数据”,该客群内所有客户的流失原因视作一个超市的购物篮数据;
② 使用关联规则算法分析每个客群的“购物篮数据”,寻找每个客群的频繁项;
③ 分析和应用频繁项的结果:例如,某个客群中“近一周有理财产品到期”与“近一周跨行同名账户转出次数”这两个特征是一个频繁项,那么该客群内近一周有理财产品到期的客户有很大可能将会发生跨行同名转账的行为,即把理财产品到期的钱转出去,所以可以采取一些挽留措施对那些近期有理财产品到期的客户提前预防。
6 全文总结
本文主要介绍索信达公司将可解释算法应用于流失预警模型后进一步探索出的一套能进行单个客户流失归因的流失预警及归因建模方案。与传统的流失预警模型相比,该方案最大的特点在于它不仅精度很高,还可以对每个流失客户进行归因,再根据每个客户的流失原因制定挽留措施,从而提高营销效果。
我们首先介绍了本文的研究背景;之后介绍了定义客户流失的方法和检验定义效果的方法;再重点介绍了由机器学习算法+可解释算法组成的客户流失预警及归因的建模方案,该方案不仅有很高的精度,还能对每个流失客户进行归因;然后以一个案例的形式进一步展示了我们的方案在银行业务场景中的应用;最后进行了一些扩展思考。
参考资料
[1] Molnar, C. (2018). Interpretable machine learning: A guide for making black box models explainable. E-book at< https://christophm. github. io/interpretable-ml-book/>.
[2] 李航.统计学习方法[M].第二版.北京:清华大学出版社.2019.
[3] 索信达公司.可解释机器学习研究报告[R].2020.
[4] Erik Strumbelj,Igor Kononenko . Explaining prediction models and individual predictions with feature contributions[J]. Knowledge & Information Systems, 2014, 41(3):647-665.
[5] Scott M. Lundberg, Su-in Lee. A Unified Approach to Interpreting Model Predictions, 2016.
[6] Python 的 shap 库:https://github.com/slundberg/shap
[7] (美)Mamdouh Refaat 著.信用风险评分卡研究[M].王奇松等译.北京:社会科学文献出版社.2013:132-136.
[8] (美)Pang-Ning Tan,Michael Steinbach,Vipin Kumar 著,数据挖掘导论[M].范明,等译.北京:人民邮电出版社.2011:201-292.

中国开源发展研究分析 2022
本次报告为开发者,技术管理者,开源社区运营、市场,开源办公室工作人员带来信息上的增量以及对开源趋势、...









评论