

一、推荐系统目标
推荐系统的目标主要包含两个方面:Exploitation 和 Exploration。

在 Exploitation 中最重要的是 Relevance ( 相关性 ) 的计算,其根本思想是根据用户浏览、观看和收藏的内容等用户行为数据推测该用户可能采取的行动。常见的推荐算法大多是基于针对该目标的优化而展开的。
然而用户行为数据在现实中很可能过少、不足以全面地体现用户的兴趣。这一现象在冷启动等场景中很常见。此时推荐系统还有责任挖掘用户尚未表现出的兴趣,并且避免由于现有行为数据过少而导致推送内容相似性过高的情况。这就需要引入 Exploration。
Exploration 主要有三个方面:
覆盖度:被推荐给用户的内容占全部内容的比例应该较高,特别是新的内容能够有机会展现给用户。
惊喜:推荐的内容并不与用户之前的行为明显相关,但又是用户所喜欢的。这能很大程度提升用户体验,但却难以给出衡量指标。
多样性:在短时间内不要过多地向同一用户推荐同一类型的内容,而是混合各种类型的内容推荐给用户。衡量这一指标主要通过三个方面,接下来将逐一介绍。
二、如何衡量推荐内容的多样性?
2.1、Temporal Diversity ( 时间的多样性 )

推荐结果应随着时间的迁移发生改变,其衡量的指标是在固定的时间间隔内推荐不同类的内容的个数。比如一个推荐系统在一段时间内给用户推荐了 10 个内容,那么这 10 个内容中属于不同类别的个数,即可衡量推荐系统的多样性。
对于这个指标的提升主要有三个方式来提升这个指标:
第一个类似于 Item-based CF 的思想,预先根据所有用户的历史偏好数据计算内容之间的相似性,然后推荐与该用户的喜好相类似的内容。
第二个是针对用户的行为做一个时间上的衰减,这样能够针对老用户增大他观看新类型结果的变化。
第三个是 Impression discount ( 印象折扣 ) ,统计所有推荐给用户的内容中哪些是用户没有观看的类型,降低该类型的曝光度,从而给其他类型的内容增加更多的曝光机会。
2.2、Spatial Diversity ( 空间的多样性 )
它的衡量指标是单个推荐列表中物品之间的差异程度,可以通过计算在同一个推荐 list 中两两 Item 之间的相似度的平均值来进行衡量。
接下来我们将详细介绍该方面内容:
首先我们为什么关注这样一个指标呢?这是因为在推荐系统中我们只关注准确性指标的话,那么会导致推荐出来的内容大部分都相似。
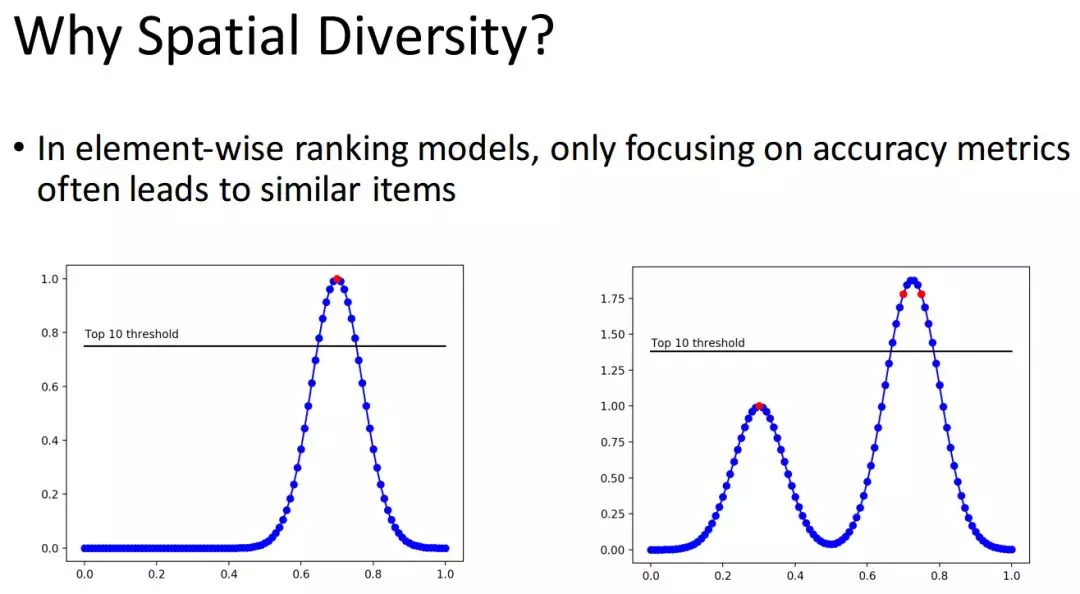
在上面这幅图中,每一个点代表一个 Item ,横坐标表示物品之间的相似性,横坐标越近表示物品的相似性越高,纵坐标表示推荐系统对 Item 的打分。
在左图中有个用户观看了一个 Item 用红点表示,那么推荐系统会根据这个行为推荐 10 内容给用户,那么这 10 个内容和这个 Item 相似度非常高。
在右图这个例子中,一个用户观看了三个内容,其中 Item1 和 Item2 的相似度非常高,和 Item3 的相似度非常低,那么推荐系统根据用户的行为推荐 Top10 的内容的话,会发现这 10 个内容都与 Item1 和 Item2 相似。这是个很常见的例子,比如一个用户很喜欢看漫威的电影,也喜欢看一些文艺类的电影,其中用户观看漫威的电影比较多一些,看文艺类的电影少一些,那么推荐系统很容易造成推荐的时候只推荐漫威类的电影。
用户多样性的问题也已经被广泛研究过。传统上使用启发式的方法,它会在多样性和相关性之间用一个加权平均的方法来获得一个总体的优化目标,然后两两之间比较当前推荐的差异性,然后试图最大化这个总的平衡了之后的优化目标,用穷举的方法。

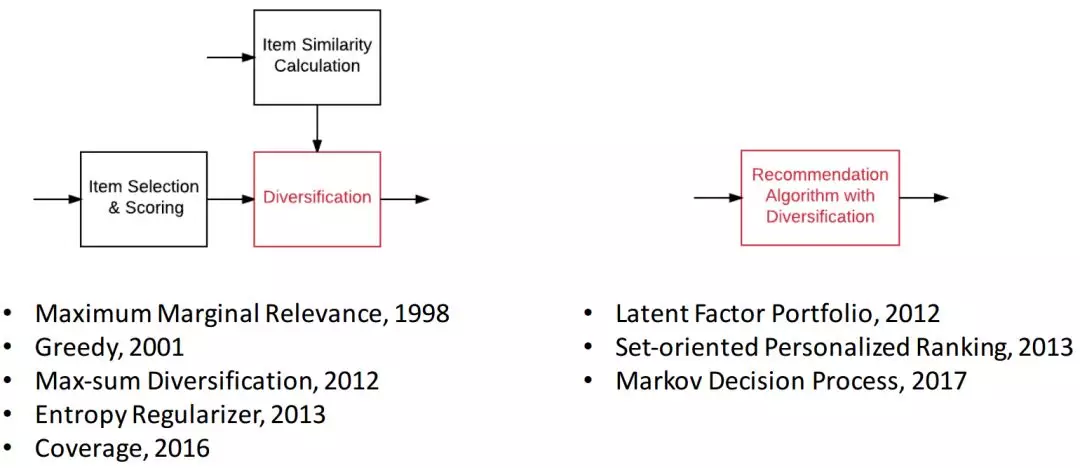
提升推荐系统多样性的方式主要有两类。第一类主要是依靠 Item 相似度模型和 Item 排序模型。如图 5 左侧所示。另一类主要是直接去修改推荐算法,使得这个推荐算法推荐出来的 Item 尽可能的不相似,如图 5 右侧所示。
三、行列式过程推荐多样性提升算法
DPP 的构造
行列式点过程 ( Determinantal Point Process , DPP ) 是一种性能较高的概率模型。DPP 将复杂的概率计算转换成简单的行列式计算,并通过核矩阵的行列式计算每一个子集的概率。DPP 不仅减少了计算量,而且提高了运行效率,在图片分割、文本摘要和商品推荐系统中均具有较成功的应用。
DPP 通过最大后验概率估计,找到商品集中相关性和多样性最大的子集,从而作为推荐给用户的商品集。
行列式点过程刻画的是一个离散集合 Z={1,2,3…,M} 中每一个子集出现的概率。当给定空集合出现的概率时,存在一个由集合的元素构成的半正定矩阵 ,对于每一个集合 Z 的子集 Y ,使得子集 Y 出现的概率 ,其中,LY 表示由行和列的下标属于 Y 构成的矩阵 L 的子矩阵。可以看看下面的例子:

由于矩阵 L 是半正定的,因此存在矩阵 B ,使得 ,并且
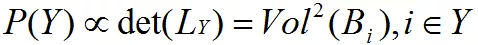
这是因为行列式为方阵中的各个列向量张成的平行多面体体积的平方。
为了将 DPP 模型应用于推荐场景中,考虑将每个列向量 Bi 分解解为 ,其中:ri 为 item i 与 user 之间的相关性,且 ;
为 item i 与 item j 之间的相似度度量,且 ;
那么:
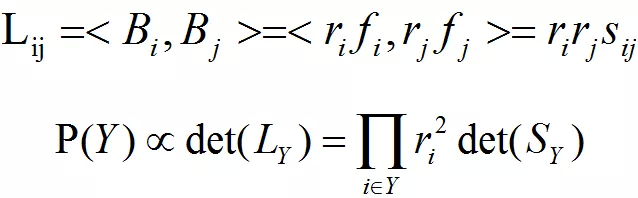
从矩阵 L 的构造可知,商品与用户之间相关性越大,且商品之间多样性越丰富,则矩阵 L 的行列式越大。因此,我们可以建立如下最优化问题:
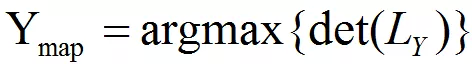
但是,直接求解该优化问题是 NP 难的,陈拉明团队则利用贪婪算法,提出了一种能加速行列式点过程推理过程的方法。
首先,DPP 取 Log 后的函数是满足次模函数的:
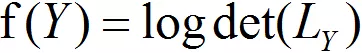
次模函数是一个集合函数,随着输入集合中元素的增加,增加单个元素到输入集合导致的函数增量的差异减小。即,对于任意
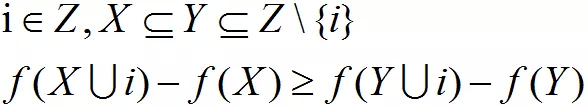
直观解释为,小集合和大集合增加同样一个元素,小集合带来的收益大于大集合的收益。
因此,可以将上述优化问题转化为贪婪的形式:
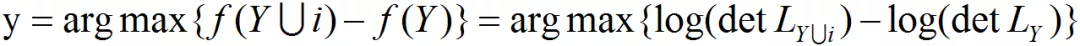
即,每次选择收益最大的 item ,直到满足条件为止。
DPP 模型求解
求解该优化问题时,每次迭代的计算复杂度来源于行列式的计算,而求行列式的计算复杂度与该行列式长度的三次方成正比,即 ,这一结果显然不适用于实际线上实时性较高的场景。下面,叙述论文中所做的改进:
首先对子矩阵 做 Cholesky 分解,使得:
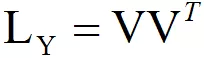
其中,V 是一个下三角矩阵。对于任意 ,对子集 Y 添加一个元素 i 之后的子矩阵做 Cholesky 分解,使得:
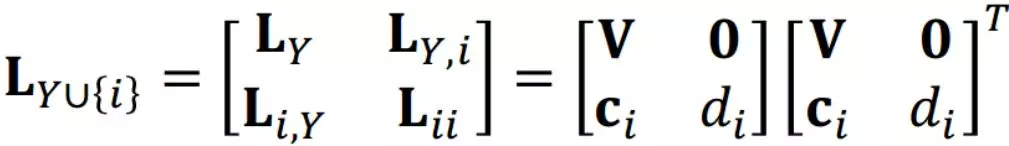
其中,有以下等式成立
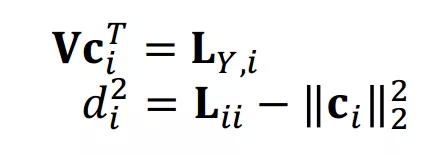
两边取行列式后再取 log ,可得:
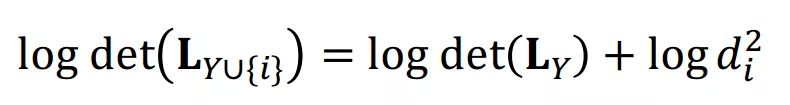
应用 Cholesky 分解后,每次迭代只需要计算 即可。而为了得到 ,先需要求解线性方程组:
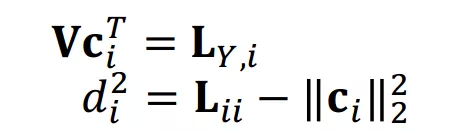
求解得到
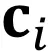
后,再带入 得到 。此过程的计算复杂度来源于求解线性方程组,虽然求解线性方程组的计算复杂度也是三次方,但是系数矩阵 V 是下三角矩阵,因此,每次迭代的计算复杂度可降到二次方。
即使计算复杂度降到了二次方,但是相比于目前主流的算法,可能依然没有优势。因此,作者又考虑每次迭代也用增量的方式更新 和 ,从而避免了求解线性方程组带来的计算复杂度。具体过程如下:
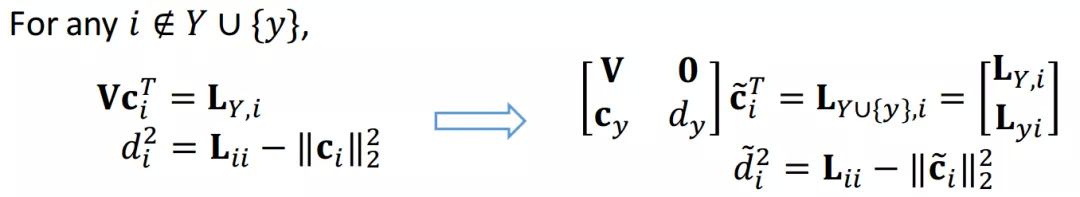
将带入上式中,推导可得:
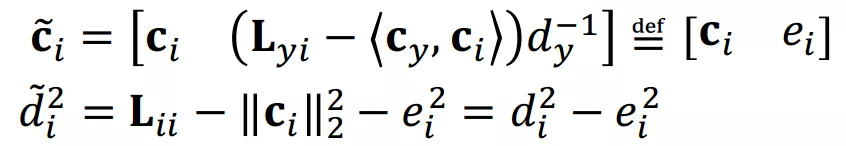
因此,每次迭代的计算复杂度进一步降低至一次方。
四、实验结果
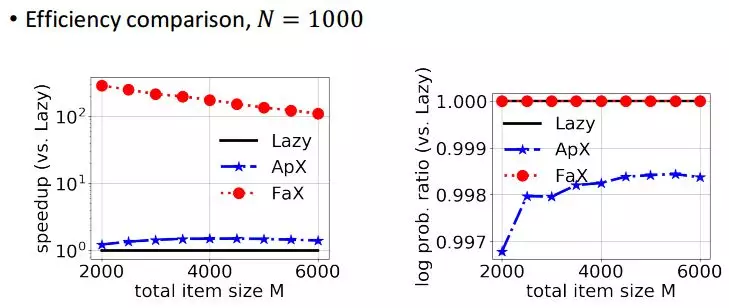
我们假设给用户推荐 1000 个内容,假设物品的数据是从 2000 到 6000,我们可以看到我们的加速效果可以达到 100 倍量级,并且没有任何性能损失。
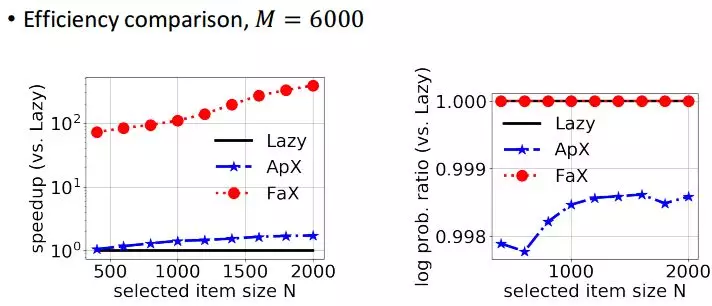
另外一个是我们固定总的 item 数到 6000,来变化 N 从 500 到 2000,加速效果也是在百这个量级,性能损失也是没有的。

这个是我们另外的一个实验,在俩个数据集上跑我们的模型,并且对比 MRR、ILAD、ILMD 三个指标。
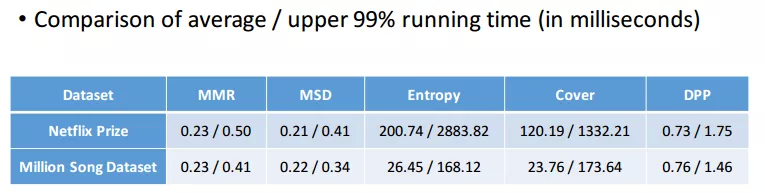
上图为各算法在运行时间上的对比。
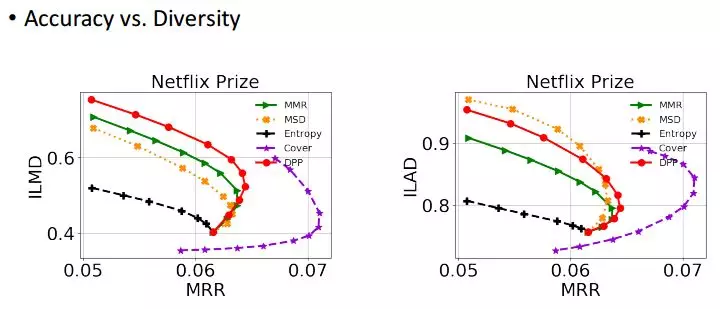
横坐标代表相关性,纵坐标代表多样性,在这个数据上我们的算法优于其他三个算法,而 Cover 的性能是表现最好的。
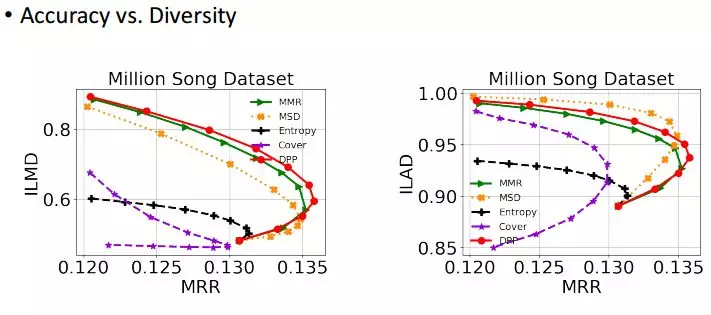
而在这个数据集上 Cover 算法性能又非常差,而我们的算法在这个数据集上表现还是不错的。
五、总结
基于行列式点过程的推荐多样性提升算法使用贪婪算法推理最优的行列式点过程,并利用 Cholesky 加速行列式点过程的推理。该算法在推荐领域具有较好的应用,在丰富推荐多样性和相关性的同时,大大提升了计算速度。
作者介绍:
陈拉明,2016 年加入 Hulu 推荐算法研究团队,现任高级研究员职位。
本文来自 DataFun 社区
原文链接:
https://mp.weixin.qq.com/s/oLG3f0mw1L5i2qMnHLugZA

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论