

前言
接口自动化测试是个老生常谈的话题,基本上每个测试团队都会涉及,市面上大部分文章会从如何设计框架去讲解。但是这一次我想回归自动化的根本价值,从持续演进的解决方案出发,讲解有赞测试团队的心路历程和对于接口自动化的理解,欢迎交流。
一、价值
有赞测试团队肩负的一个使命是: 打造高效且可靠的产品交付能力 。为了完成这个使命,我们会借助各种工具,而接口自动化就是其中的一把利器。
如何让接口自动化的价值最大化,首先需要想清楚如何去评估接口自动化的质量,有赞测试团队是这样思考的:
最大化提升回归测试的效率
消灭更多的测试盲点
接下来介绍的持续演进的方案都是基于这两个方向去努力的
二、业务服务器架构
为了让大家更好地理解我们的演进思路,我先简单介绍一下我们业务的服务器架构,接口自动化的测试目标。
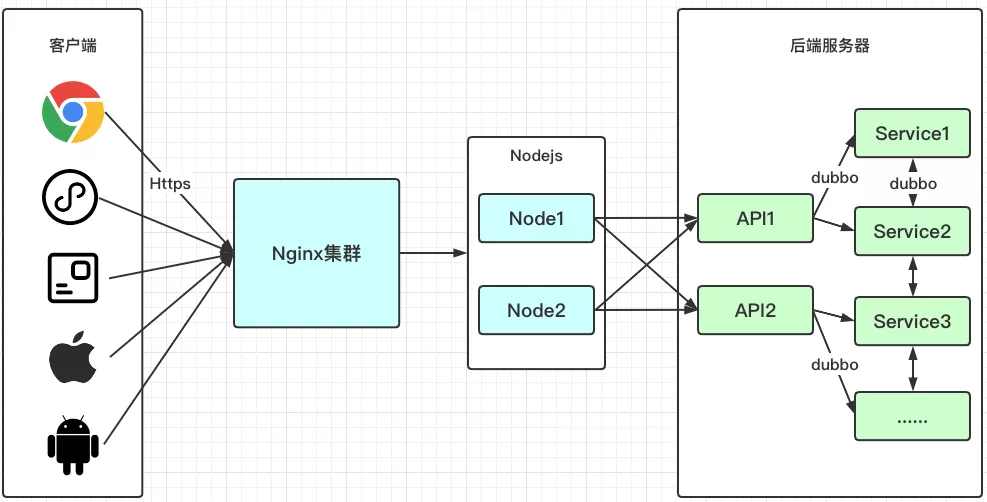
客户端:渠道较多,分 Web、H5、小程序、APP、Pad,通过 youzan.com 域名请求,统一接入到公司网关层 Nginx 集群,反向代理转发到对应业务的 Web 服务器。
Web 服务器:这一层是 Nodejs 实现,涉及逻辑主要是路由转发、登陆态校验。
后端服务器:电商系通用的 Java 微服务架构,API1 和 API2 是接入层,涉及逻辑主要是请求转发和非业务相关的通用处理。Service1 这一层才是真正的业务逻辑层,大概有 30 多个微服务应用,互相之间使用 dubbo 协议通信。
所以,接口自动化面临 2 种选型:
模拟客户端进行 HTTP 请求, 优势是能快速覆盖用户场景,劣势是需要构建大量的数据,后期维护成本高。
基于 dubbo 协议进行请求, 优势是能 Mock 依赖数据,劣势是前期脚本编写成本高,且不支持预发执行。
该如何选择呢?小朋友才做选择题,成年人我们都要了,两者互相结合,扬长避短。
三、如何提升回归测试效率
这里需要从三个阶段来看:回归测试前、回归测试中、回归测试后。
回归测试前,我们通过 2 个事情来提升效率:
1、精准定位自动化测试覆盖范围
最原始的范围依据是根据功能测试用例来,但这不是客观合理的,我们从对外暴露的接口数和后端 Service 层应用的代码覆盖率去评估。
我们基于 JaCoCo 进行二次开发实现增量代码覆盖率统计,可以拿到每次执行自动化后的指令级覆盖(Instructions,C0coverage),分支(Branches,C1coverage)、圈复杂度(Cyclomatic Complexity)、行覆盖(Lines)、方法覆盖(non-abstract methods)、类覆盖(classes)。通过这些信息我们可以对我们的自动化进行查漏补缺。
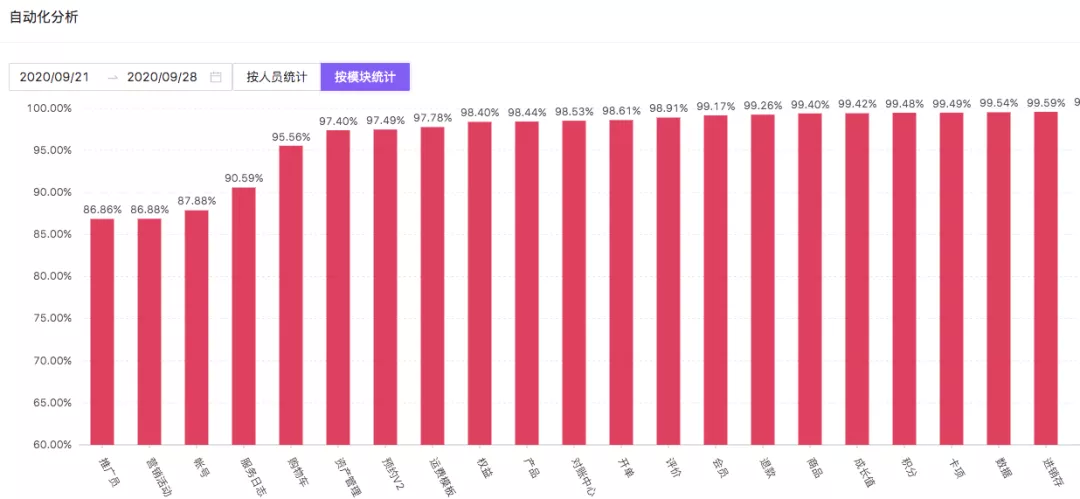
通过解析前端路由文件,获取线上正在使用的接口数,作为基准,对比自动化执行请求的接口数,可以快速告诉各个模块负责人覆盖盲点。
2、高效编写自动化脚本
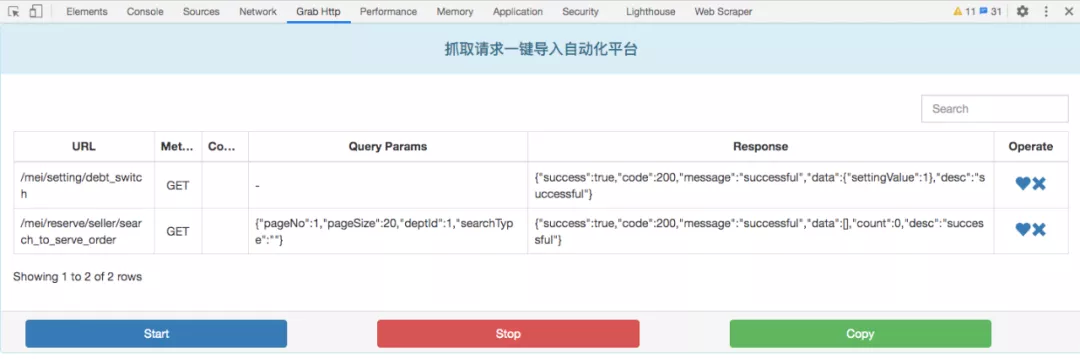
我们需要通过抓包工具来获取请求信息,这里面涉及到请求过滤、数据格式化、拷贝、顺序调用等工作,我们做了一个 Chrome 插件来代替这些大量的重复性工作,以提升自动化编写效率。
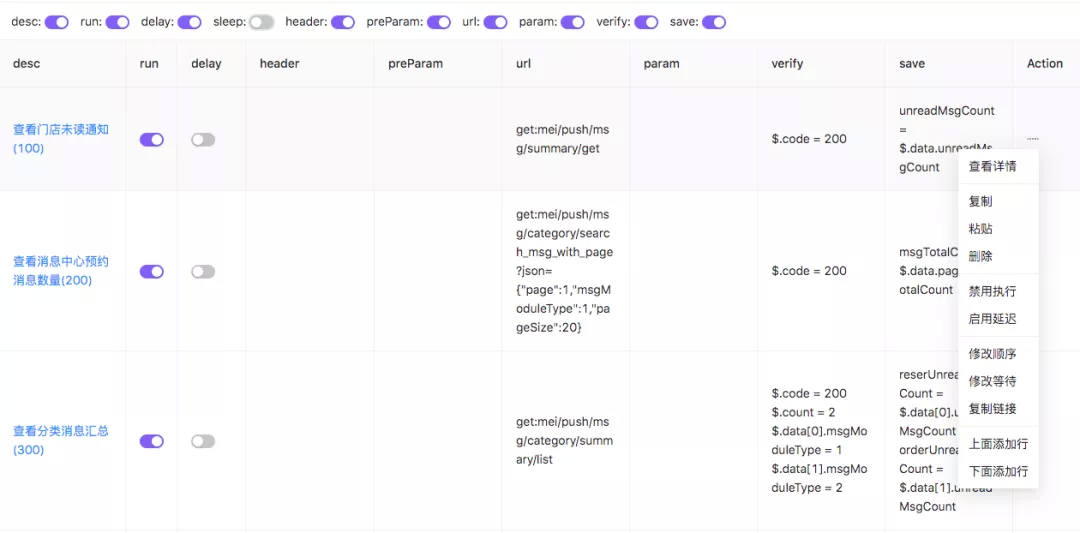
依下图所示,先 Start 开始抓包,操作被测页面,Stop 停止,列表会过滤显示符合条件的 XHR 类型请求,请求信息自动格式化,支持手动单条删除 or 拷贝,点击 Copy 调用接口批量上传到自动化测试平台,是不是大大简化了前期获取原生数据的工作。
在我们测试平台进行用例的二次编辑,全部支持界面化。
回归测试中,只需要关注一个事情:执行时间。随着业务不断壮大,线上接口数接近 2000+,对应的自动化接口请求数 10000+,每次全量执行时间需要 1 个多小时,这样的速度是无法接受的,为了在 10 分钟之内解决战斗,我们做了 3 个事情:
1、延迟队列
废除了 Sleep 方式,将数据有延迟的校验放置到延迟队列中,支持自定义在一级模块 or 二级模块后再校验。
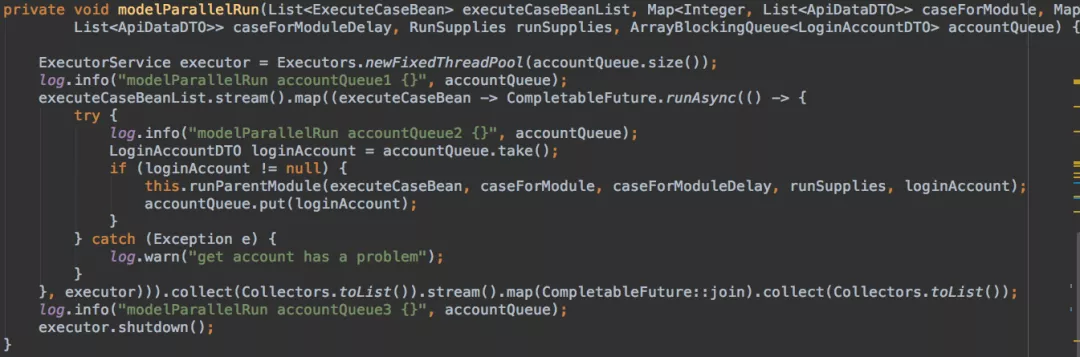
2、多级模块支持并发执行
我们采用官方的 CompletableFuture 异步线程类实现执行逻辑,Executors 线程池管理,和业务账号池关联起来,一个线程对应一个执行账号资源,项目实际多模块并发的代码如下:
合理的使用线程池能够带来以下明显的好处:
可以自定义指定线程池,例如大小,超时等等
降低资源消耗:通过重用已经创建的线程来降低线程创建和销毁的消耗
3、数据清理采用命令模式
每一项测试数据的清理,都是一个任务类,所有的任务类都继承了一个抽象类,在 action 方法里定义了数据清理的接口请求
在每次创建数据后,实例化任务类,然后添加到队列里
所有测试用例执行完成后,afterTest 里遍历队列依次数据清理

采用这个方式的优势:
自动化测试任务中途异常退出结束了,也可以清理掉已创建的数据
支持多份的同样数据清理,数据之间不受影响
无需用完立刻删除,统一清理,且支持并发,高效
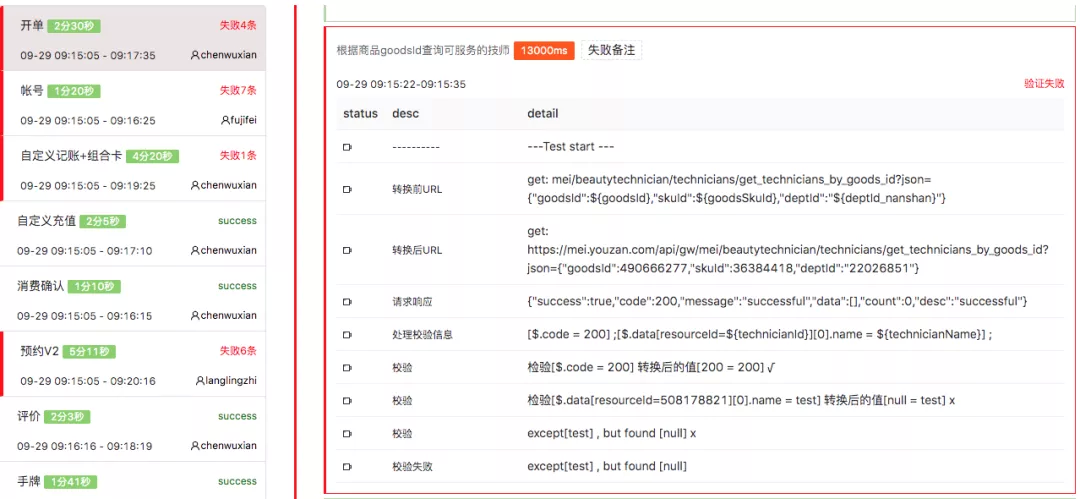
回归测试完成后,当然要去分析结果了。一个信息全面,交互良好的测试报告可以让自动化结果分析效率大大提高。
四、消灭更多的测试盲点
有赞测试团队会定期分析线上漏测 BUG,从后端 BUG 的分析结果来看,主要原因集中在偶现的数据不一致和复杂用户场景覆盖两个方面,反映出组装接口请求进行自动化测试覆盖的局限性。如何消灭这 2 个盲点,成为了我们演进的一个方向,我们将接口自动化测试场景转战到生产环境。
1、线上业务自动化校验
在公司越来越复杂的分布式架构下,难免会出现远程调用失败,消息发送失败,并发 bug 等问题,最终会导致系统间的数据不一致。传统的接口请求方式是无法发现这类问题的,我们需要借助 BCP 业务校验平台。
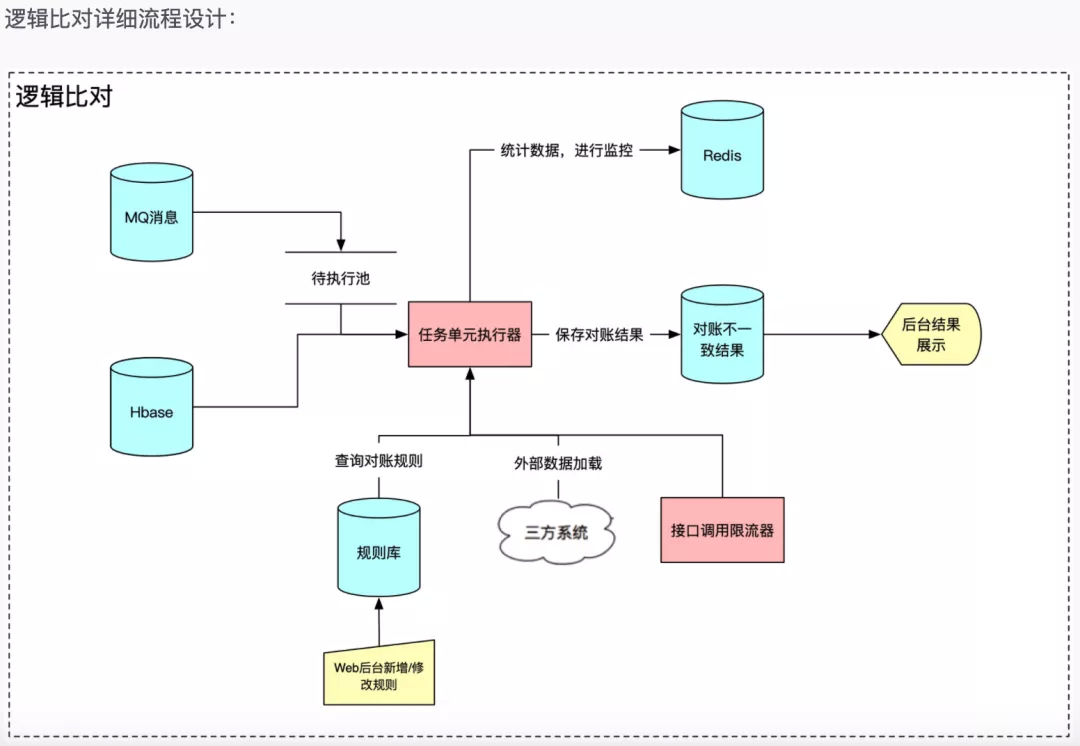
举个实际 BUG 场景:买家在有赞商家店铺购买商品参与了满减送,但是赠送的优惠券迟迟没有送达。我们来讲讲如何覆盖这个场景的:
在对应的后台应用上找到购买商品的 Topic A
在 BCP 平台建立一个监听 A 广播消息的 Channel B
消费 A 的广播消息时触发接口请求,查询买家的权益信息,检查是否对于的优惠券信息
接口请求回来的数据和 A 广播发出的消息体,作为对账规则的数据来源
在规则库创建好对账规则,进行线上每一笔数据的校验
这样能做到,用户购买商品产生的每一笔数据,都会经过我们自动化校验,确保每一笔数据的一致性,偶现的 BUG 是不是无处遁形
2、流量录制回放
前面提到的传统接口自动化解决方案,无论优化到什么程度,对于用户场景覆盖和效率提升,都是有一定的局限性的。
所以,为了不断演进我们需要引入新方案,有赞测试团队引进的流量录制回放,基于阿里开源的 JVM AOP 的能力,通过对被测应用进行挂载 Sandbox,进行字节码注入,从而达到在线上录制流量和测试环境回放流量的目的。
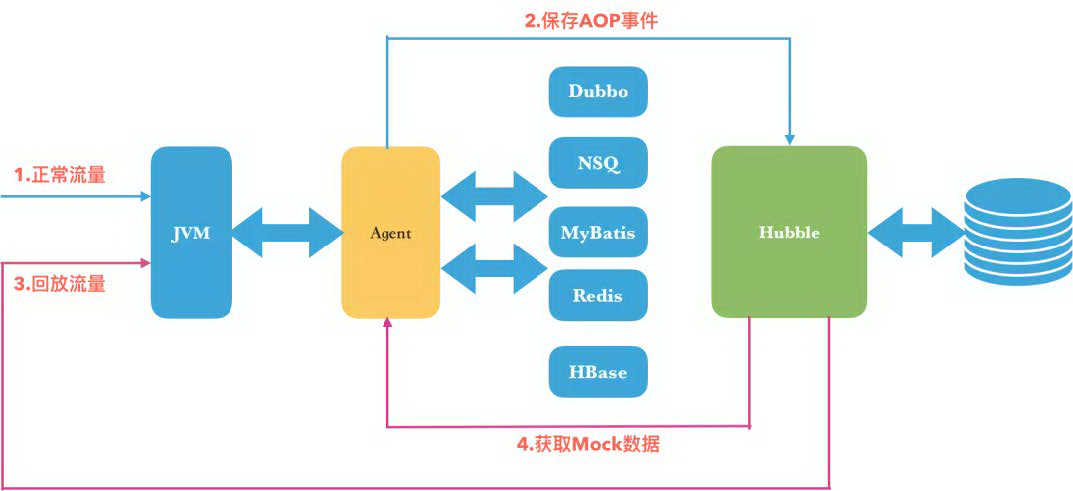
上图是有赞流量录制回放平台的架构图,一次完整的流量录制回放是这样的:
Agent 包括阿里开源的 Sandbox 和我们开发的插件,插件里实现了流量抓取、保存和回放的逻辑。以 Java Agent 的方式挂载到生产环境的机器,就可以开始采集流量了
一次流量录制包括一次入口调用和若干次子调用(Dubbo、NSQ、MyBatis、Redis、HBase),通过 traceid 将入口调用和子调用绑定成一次完整的记录,监听 BEFORE、RETRUN、THROW 事件机制获取每次调用的传参和返回

每一个完整流量的 traceid 和调用链路,会生成一个 MD5 值,判断是否有重复,若有,测试用例热度+1,若无,创建新的测试用例保存
测试环境部署被测代码,也挂载上 Agent,创建任务执行线上流量保存下来的测试用例,支持 Mock dubbo consumer 和中间件调用
执行返回的 response 和线上采集的进行 Json diff,分析差异化判断是否是 BUG。下图是我们项目实际的使用流程:
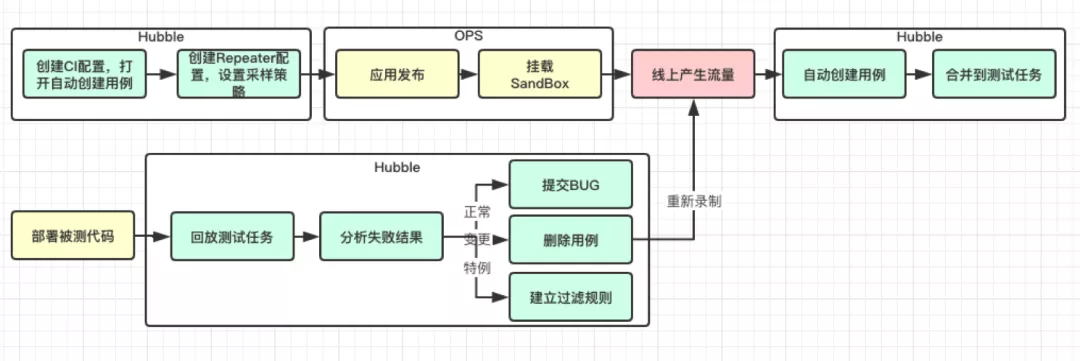
由此看来,对比传统接口自动化,流量录制回放有如下优势:
线上流量采集,还原真实用户场景,覆盖率高
自动分析生成测试用例,省去手动编写和后期维护工作,大大提升效率
支持自定义 Mock,将后端服务隔离,进行模块化测试,代替单元测试的完美方案
以上拙见,希望能起到抛砖引玉的作用,欢迎各位测试同仁一起来交流分享。
本文转载自公众号有赞 coder(ID:youzan_coder)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论