

背景介绍
金融系统网络,从业务层到交易层,需要若干系统间协同处理,相互支持,相互依赖,共同完成一笔看似简单的业务处理。风控在这其中是被若干系统同步调用的叶子节点,并发量高而且要同步实时完成逻辑复杂的风险判断,给出风险决策。
老交易风控完全依赖关系型数据库,响应速度慢,抗高并发能力差;内部系统间数据耦合严重,不易扩展改造;
不断增加的业务量,持续增长的规则数,越来越慢的响应速度……亟待系统升级改造,一年前我们开始了系统优化之路……
具体优化措施
一、数据层
1、内部系统流水数据解耦和
风控系统用到的数据大体分 3 类:实时业务流水数据;离线风险特征数据;配置类数据。其中实时业务流水数据是无边界且数据量极大的数据,也是我们优化的重点,这类数据从使用者的角度,主要分:
实时决策系统(从现在往前n段时间即可)
风控运行系统,供案件分析,人工审核用(需要历史全量数据)
分析师风险分析用(虽然不需要历史全量数据,但是比实时系统需要更长的有效数据)
其他非实时系统。
老系统数据架构:
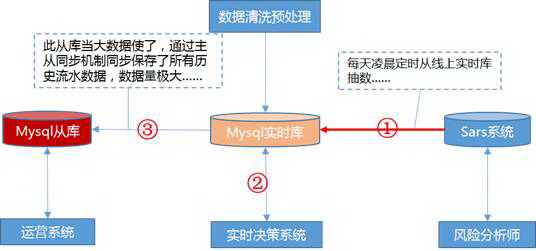
如上图所示,线上实时库数据与各类内部系统存在耦合关系:
Sars系统每天凌晨抽数抽到实时系统性能下降;
Mysql从库当大数据用了,定时炸弹随时引爆;
实时决策强依赖Mysql,性能差待优化。
所以首先要做的就是:各内部系统数据解耦合。
解耦整体思路:对实时系统接入的所有流水数据做完数据清洗、预处理后,MQ 异步方式发出来,其他内部系统来订阅,根据自己系统的特点选择不同的存储方案。
优化后数据架构:
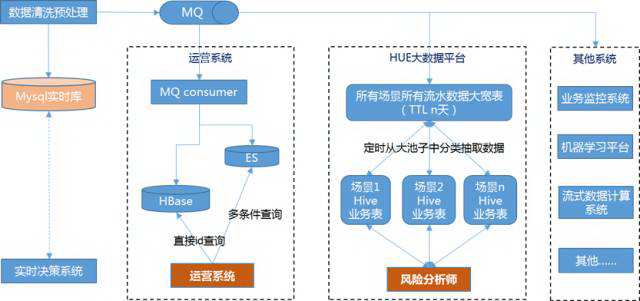
数据解耦后,就可以放心大胆的进行实时系统的优化改造。目前改造的效果:新接入场景所有数据基本不需要再写入关系型数据库。
2、风控实时系统:去关系型数据库,全面缓存化
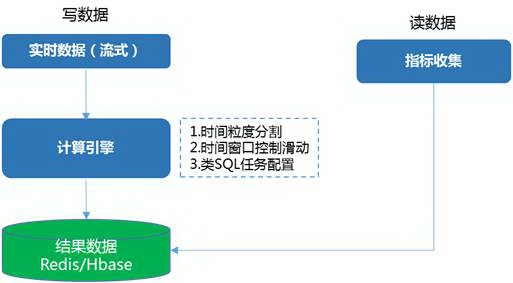
流水数据
流水数据聚合统计指标是对 mysql 影响最大的,也是我们去关系型数据,全面缓存化最有难度的改造。
目前系统用到的方案有两种,二者相互补充,基本做到大场景所有聚合类统计全部缓存化。
方案一:清洗流水数据,缓存明细,解析聚合 SQL 转化为代码逻辑结合缓存数据实现聚合统计。

方案二:接入流式实时数据计算系统。
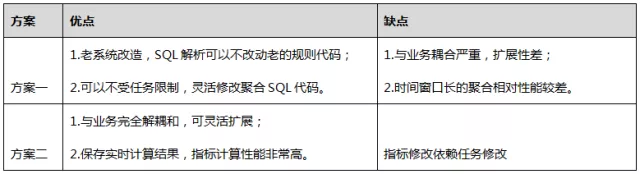
方案对比:
离线风险数据
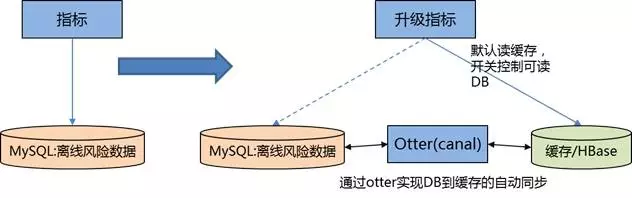
这类数据的使用特点:查询相对简单,没有复杂聚合统计。整体思路:最底层(无需业务层感知)实现关系型数据库与缓存的数据同步。
3、写库优化
Mysql 目前架构是通过 cds 实现的主从读写分离,老业务接入的数据还是要写 MySQL, 单点主库在高并发情况下出现写库瓶颈。
优化方案:
MQ异步降级(大部分聚合统计都已经切缓存,入库延迟对整体系统业务影响不大)。
业务层合并、批量入库,减少IO。
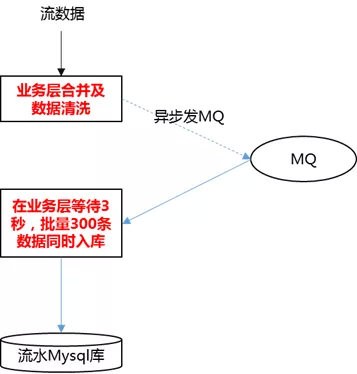
优化后,618 大促峰值,比去年双 11 量大的情况下,异步写库无任何积压,无任何入库延迟!
二、引擎 Drools 版本升级、JVM 调优
引擎采用支持热部署的 Drools,随着规则及业务量的增加,引擎 java fullGc 频繁,yongGc 耗时过长,尝试调整各类参数都无法解决问题。
如下优化项完成后,java 虚拟机各类 GC 表现正常,TP999 优化效果非常明显:
Drools升级到最新7.0版本,session采用无状态替代原有有状态session。
Jvm升级到1.8,采用java8默认垃圾收集机制。
三、交易风控 3.0– 风控引擎业务模型升级优化
2.0 到 3.0 演进
**
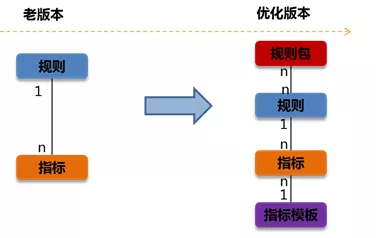
1、引入规则包的概念
通过规则包前置条件,可以将规则划分到更小的规则包,使每条规则能够更精确的处理自己应该处理的业务请求,提高系统性能。
2、引入指标模板的概念(通过 Rhythm 模板引擎实现)
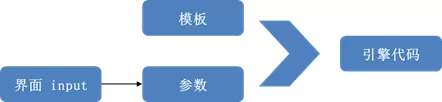
解决问题:
多规则间,指标重复配置,复用性差。
相同指标重复收集,浪费系统资源,影响系统效率。
分析师可直接通过界面灵活配置规则。研发负责开发指标模板即可,一劳永逸,节约研发成本。
其他改造方案
1、网关代码重构:通过模板模式、工厂模式,将不同场景间的定制处理解耦和;拆分场景也便于系统性能监控。
2、自降级方案:系统一旦出现问题,系统可以自降级,及时给上游返回结果,流水数据会存下来,后面异步再跑引擎。
……
优化改造效果
1、从系统性能角度
在规则数量翻 2 倍,业务请求量翻 3 倍的情况下,全场景系统响应 TP99 降低到原来的 1/5,性能提升显著。过去两个大促,全部顺利经受住考验……
2、从研发人力角度
随着交易风控 3.0 及洞察系统的上线及稳定运行,之前专门设立的都需要 1 个研发人力支持的:规则开发接口人、线上值班接口人,都已经取消。
后续…
目前系统还有优化空间,优化改造之路,我们将持续不断走下去……

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论