

我们曾翻译过《聊天机器人 vs 移动应用:未来属于谁》,该文认为聊天机器人将是未来所属。看上去,聊天机器人的风头一时无两。但是,聊天机器人的实际表现却让人有些失望。Facebook 曾在聊天机器人领域进行过大量的尝试,然而著名的“助理 M”对话式机器人最后还是难逃被关停的命运。不过,Facebook 并没有就此放弃,反而在这方面付出了更多努力。近日,Facebook官方博客发布了一篇有关对话机器人进展的文章,首次全面的展示了 Facebook 在该领域的发展情况。
对话研究是构建下一代智能代理的重要组成部分。虽然聊天机器人在单域对话(single-domain dialogue)方面已经取得了一些进展,但如今的智能体还远远不能进行跨多个主题的开放域对话(open-domain conversation)。在我们的日常生活中,能够以人们彼此交谈的方式与人类交谈的智能体将会让人们感到更容易、更愉快,而不仅仅是播放一首歌曲或预约约会这样简单的任务。
要在对话中做出连贯、迷人的回应,需要一系列细微的对话技巧,包括语言理解和推理。Facebook AI 在对话研究方面取得了科学的进步,从长远来看,对话研究是构建更迷人、更有人情味的人工智能系统的基础。在本文中,我们将描述新的开源数据集、算法和模型,它们改进了当今开放域聊天机器人的五个常见弱点:一致性、特异性、同理心、知识性和多模态理解。
保持一致性
开发有人情味的聊天机器人的第一步是确保它们能够在没有失误的情况下(如前后矛盾之类)做出适当的响应。前后矛盾、不一致是聊天机器人常见的问题,部分原因是大多数模型既缺乏明确的长期记忆,也缺乏语义理解。例如,在下面的例子中,模型说, “I have 2 cats”,但又说, “I do not have any pets.”
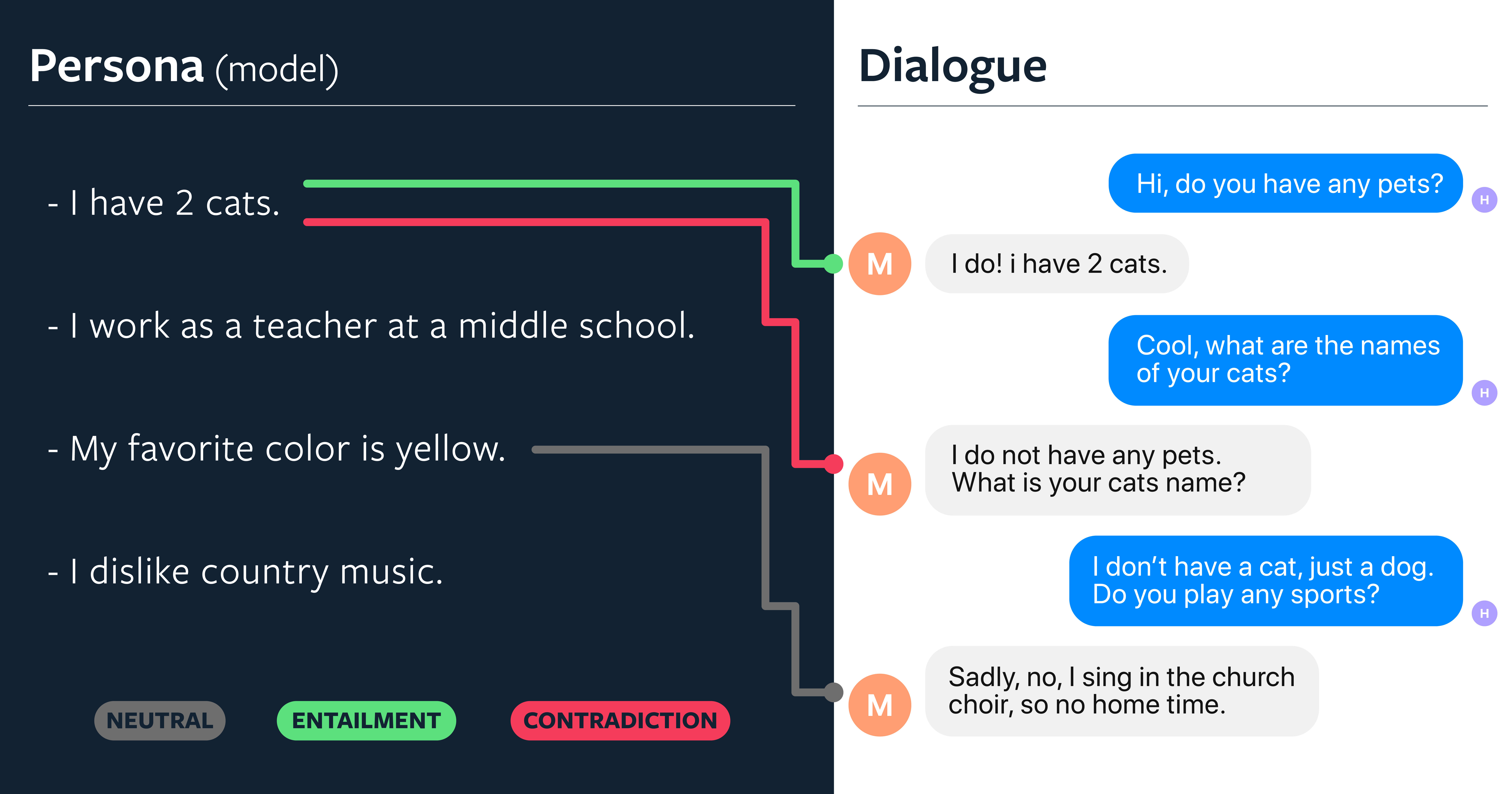
最近,我们与纽约大学的同事合作,开发了一种新的方法,将对话智能体的一致性构建为自然语言推理,(natural language inference,NLI),并创建一个新的 NLI 数据集,名为 “Dialogue NLI”,用于改进和评估对话模型的一致性。在 Dialogue NLI 中,我们分别将对话中的两个话语作为前提和假设。每一对都进行了标记,以表明前提是否与假设相关,或者是否与假设矛盾,还是中立。
我们在这个数据集上训练一个 NLI 模型,并使用它对模型的响应重新排序,以包含先前的对话,或者保持与它们的一致性,从而提高对话智能体的整体一致性。在我们的三个测试集中,我们发现,矛盾现象平均减少了三倍。人类注释者也认为这些模型更加一致,不怎么前后矛盾了。
平衡特异性
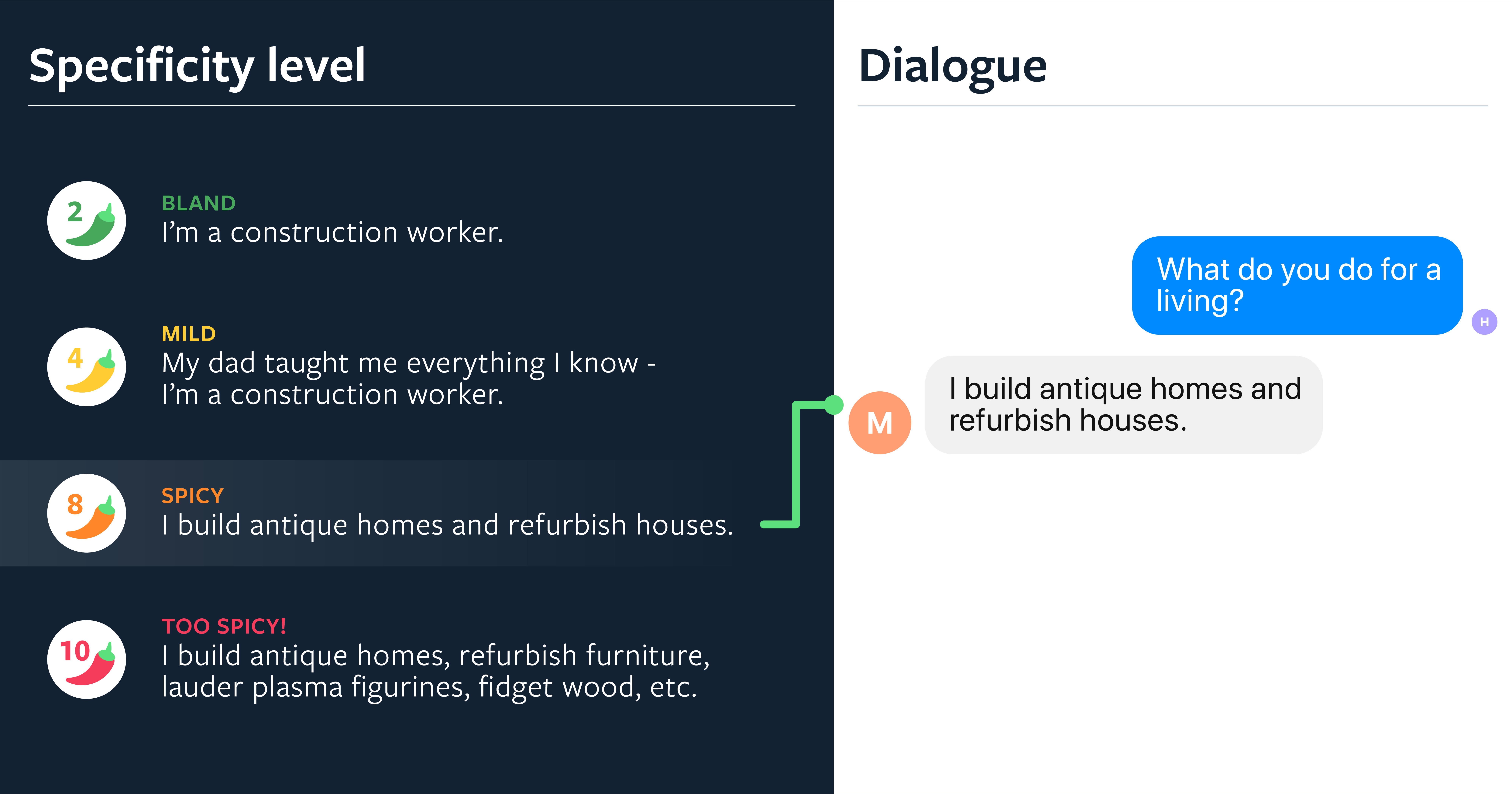
生成式对话模型经常默认使用通用的、安全的响应,比如 “I don’t know”。在与斯坦福大学人工智能研究员 Abigail See 的合作中,我们研究了如何通过控制一些会话来解决这个问题,比如特异性水平。当人们参与一个交谈时,我们发现他们明显更喜欢更具体的回应,而不是一般的回应。人类注释者对我们的特异性控制模型是这样评价的:在迷人方面,我们的模型比基线模型要高 28%,在人情味方面则要高出 32%。多样性是交谈的“调味品”。
但是,过于具体的模型可能会导致过于狭隘的专注和 “驴唇不对马嘴” 的对话伙伴。在一项实验中,我们根据角色信息对机器人进行了条件设置,并询问它:“What do you do for a living?” 典型的聊天机器人会用通用语句 “I’m a construction worker.” 作为回应。通过控制方法,我们的聊天机器人提出了更具体、更有吸引力的响应,如 “I build antique homes and refurbish houses.”。
虽然目前的研究大多集中在下一个话语的预测问题上,但我们的工作表明,为了提高会话质量,需要从多个方面进行研究。除了特异性之外,我们还表明,平衡提问和回答以及控制我们的模型的重复程度,也会产生显著的差异。整体对话流越好,未来的聊天机器人和对话式智能体就越吸引人,越有人情味。
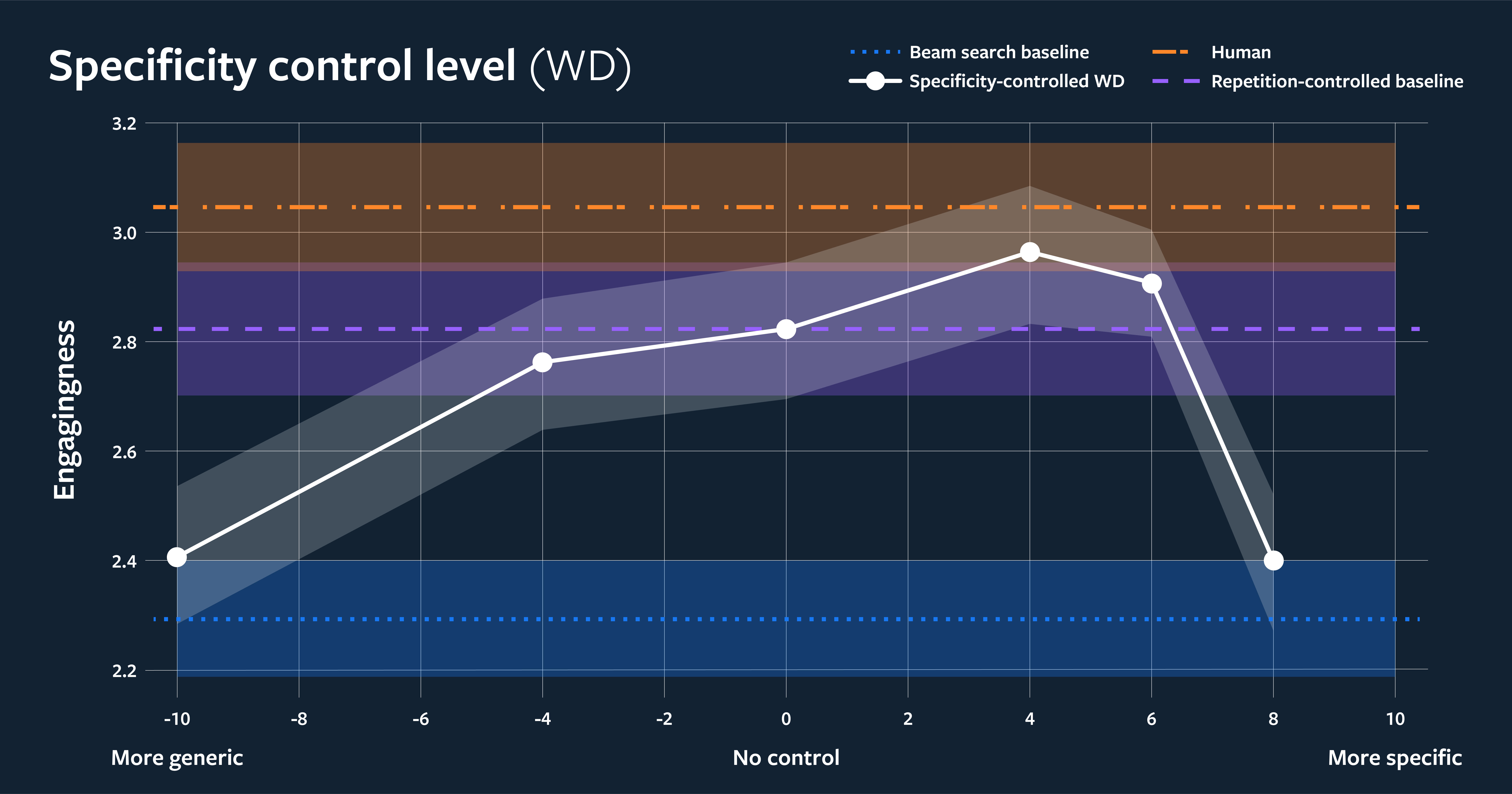
在上图中,我们根据集显和不同特异性控制设置校准了人类对吸引力的判断。
移情回应
目前,对话式智能体很难识别情感并做出适当的回应。这可以部分归因于缺乏合适的基准和公开可用的训练数据集。在最近与华盛顿大学的研究人员合作的过程中,我们引入了第一个基准任务,以特定的情感标签为中心,由人类编写的移情对话,来衡量聊天机器人表现移情的能力。除了在自动度量上有所改进之外,我们还表明,使用这些数据进行微调和作为检索候选项,可以得到被人类评估为更有同理心的回应,在三种不同的检索和生成模型上平均提高了 0.95 分(1~5 分)。
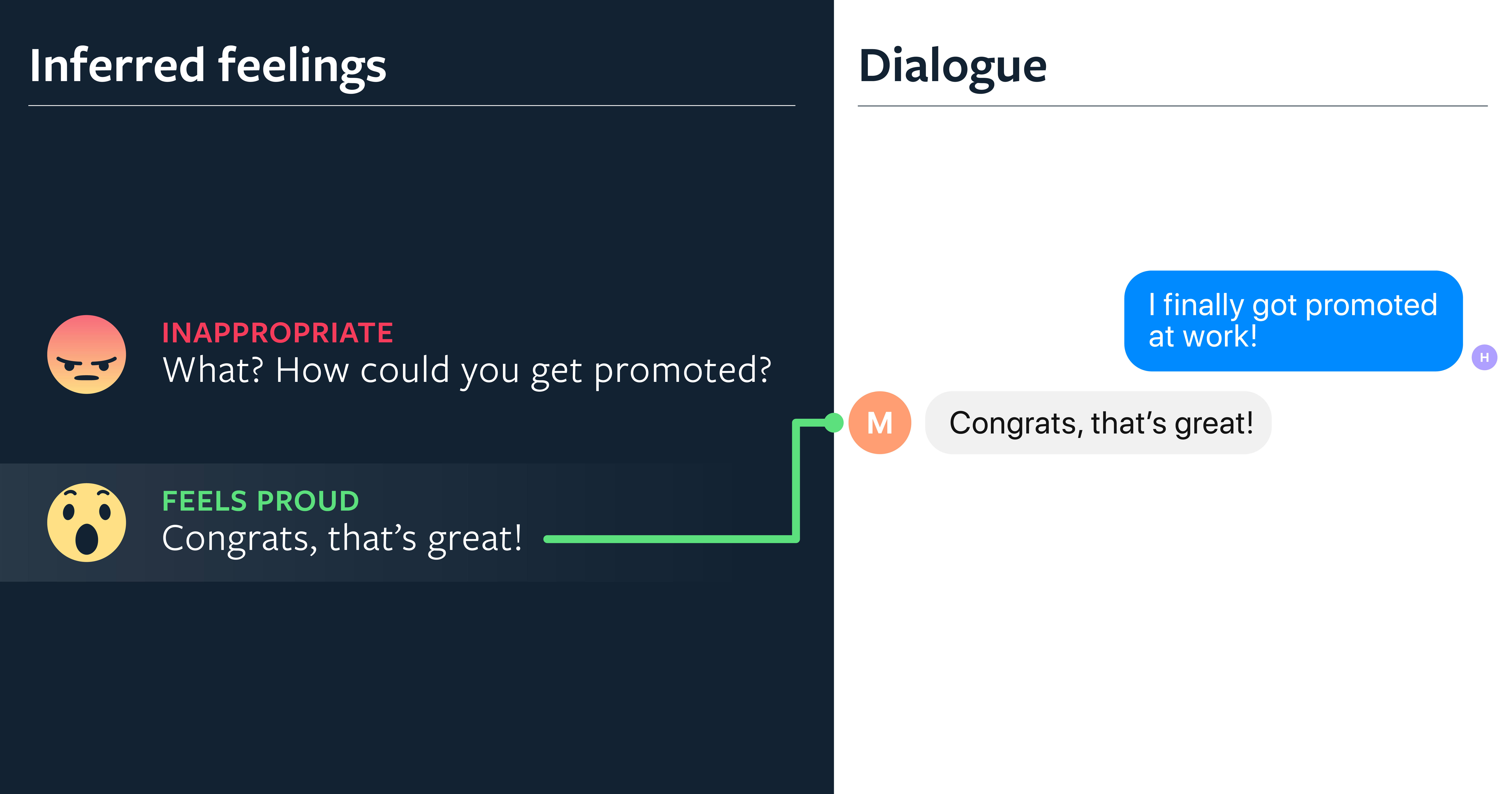
这项工作为聊天机器人中发展移情对话提供了新的研究方向。例如,下一个挑战是以移情为中心的模型,要在复杂的对话情景中表现良好,在这种情景中,智能体可能需要在共情与保持主题或提供信息之间取得平衡。
回忆知识
人们很自然地将知识融入到与其说话伙伴的对话中,但开放域的对话式智能体却往往很难利用现有的知识。当前最先进的对话建模方法包括序列到序列模型,这些模型缺乏对对话历史之外信息的访问。为了解决这个问题,需要在这些模型中使用更直接的知识记忆机制。
最近,我们已经提高了对话式模型展示知识的能力,方法是通过从 Wikipedia 收集直接基于知识的对话的数据集,并创建新的模型架构来检索知识、读取知识,并在此基础上设置它们的响应条件。
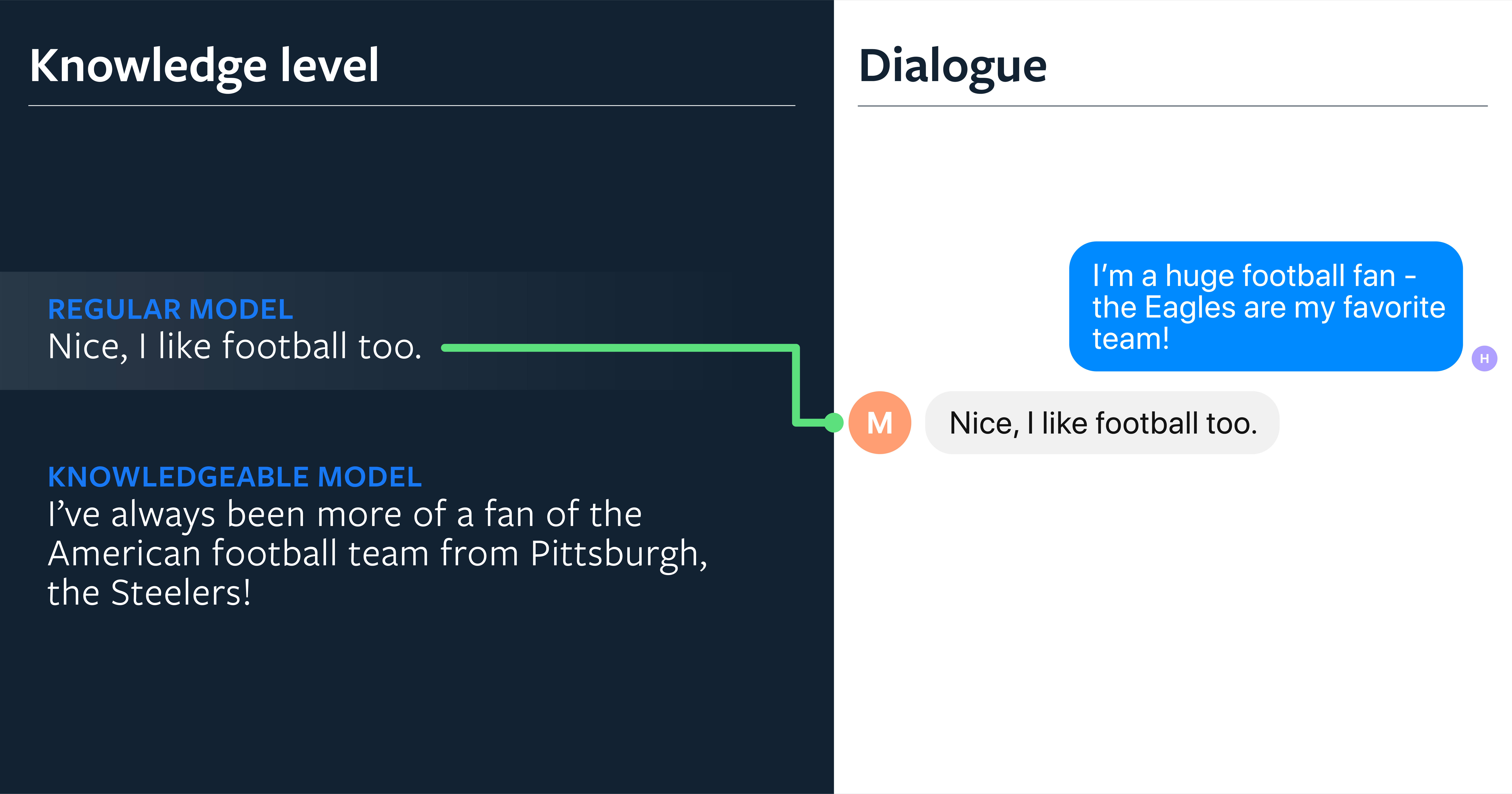
这种新的架构,称为 Transformer 记忆网络,产生了更有知识的智能体,性能优于那些不使用记忆架构的系统,用于在自动度量和人工评估中存储知识。我们的生成模型变体产生了最明显的改进,并且被人类评价为:相较于那些没有知识的同类,参与度平均提高了 26% 。
对图像的理解
为了与人类交往,智能体不仅应该能够理解对话,还应该能够理解图像。当人们彼此交流,谈论他们周围的事物时,他们不会做出中立的观察,而是表达自己的观点。对图像进行评论的机器学习方法通常侧重于图像里的字幕,这种字幕在语气上是真实的、中立的,就像 “fireworks in the sky.”。在我们的研究中,我们关注的是通过融入个性为人们带来吸引力的图像字幕。我们收集了大量基于图像的人类评论数据集,并训练了最先进的模型,使其能够与特定任务讨论图像,这使得系统对于人类来说更有趣。人们有 64.5% 的情况更喜欢基于个性化的字幕,而不是传统的字幕。
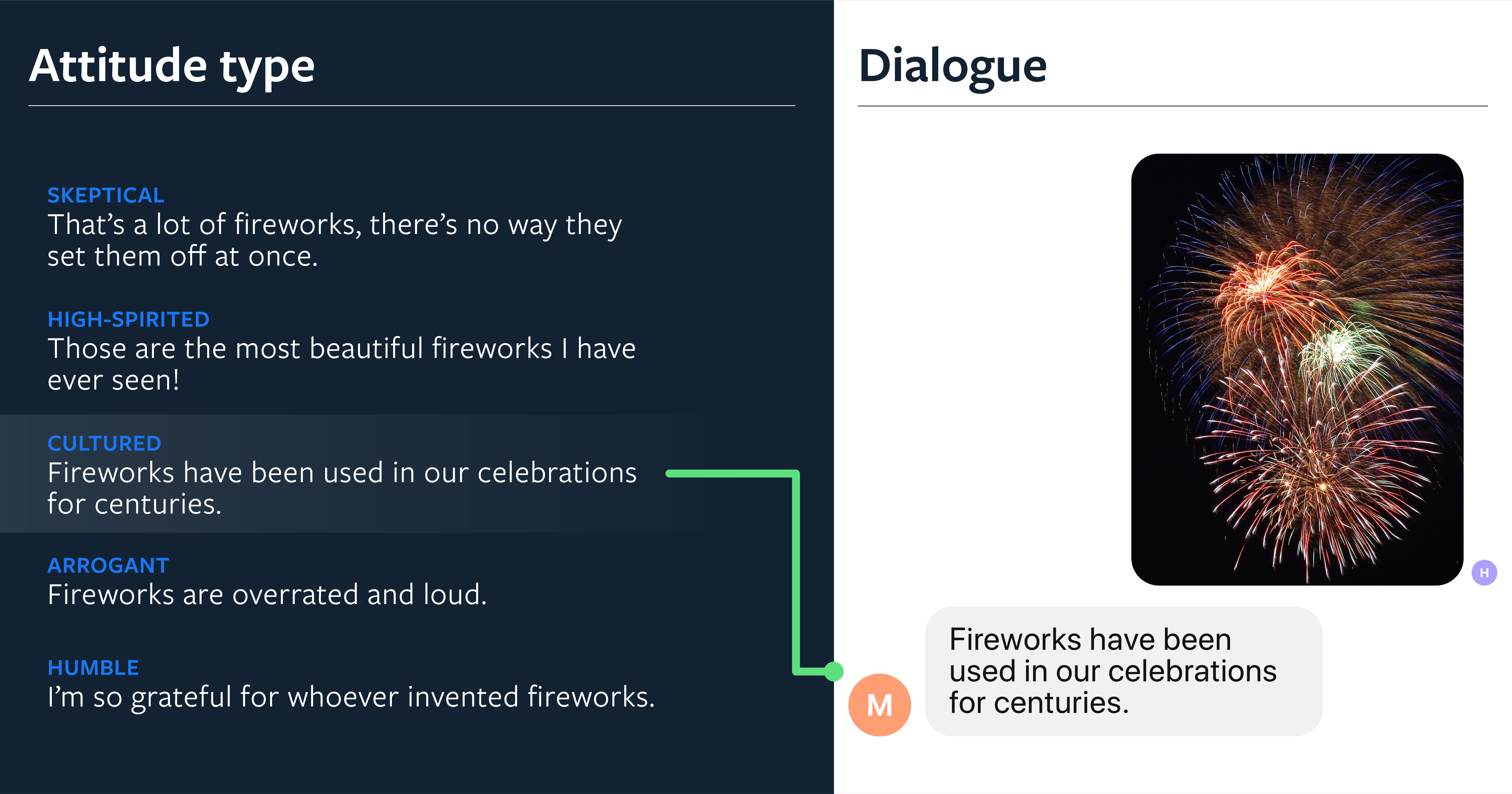
为了构建强大的模型,我们同时考虑了检索和生成变体,并利用来自视觉和语言领域的最新模块。我们定义了一个简单但功能强大的检索架构,命名为 TransResNet。它的工作原理是使用图像、个性和文本编码器在同一空间中投射图像、个性和标题。我们证明了,最好的系统能够生成在参与度和相关性方面接近于人类表现的字幕。事实上,人类注释者在 49.5% 的情况下更喜欢我们的检索模型起的标题,而不是人们写的标题。
展望未来:交互式学习的智能体
今天的对话研究几乎完全是建立在人们相互交流的大量监督学习的基础上,这些通常是通过众包或在互联网上公开获取的。这些数据在分布上可能与部署聊天机器人的环境有很大的不同。为帮助研究人员进一步探索和推动对话研究,重要的是在现实世界中让智能体真正与人类对话。
为此,我们发布了一个新的数据收集和模型评估工具,一个基于 Messenger 的 Chatbot 游戏,名为 Beat the Bot,允许人们直接与机器人和其他人实时互动,创建丰富的例子来帮助训练模型。我们分享这个新工具的目的是为研究人员提供来自实时交互的高信号数据,而不是固定的语言数据。我们计划不断增强这个工具的能力(例如,添加图像理解),以帮助改进我们最新的对话模型,并进一步探索对话研究。
Beat the Bot 目前正处于活动状态:如果你向这个页面发送消息,你将与机器人和其他人匹配。对于你发送的每一条消息,你和对方都会看到两条回复,一条来自你的人类伙伴,一条来自机器人。你可以选择哪个回复更好,然后从那继续对话。这样做的目的是让你的人类会话伙伴比机器人更频繁地选择你的信息。这允许在两个方面进行监督:它提供了人与人之间的对话转换,以及人类对于机器人何时不能与人类的表现相匹配的评估。我们要求用户在游戏中扮演一个与其个人信息完全无关的角色。在游戏开始时得到用户许可后,收集的数据将是开源的,以便为整个社区提供新的研究方向。
此外,在探索聊天机器人如何从部署后的对话中学习的方面,也有一些尚未开发的机会。我们在从这些对话中提取训练信号方面取得了一些进展。在与斯坦福大学的合作中,我们已经证明,通过从与人类的对话中提取训练数据,改进部署的对话智能体是有可能的。
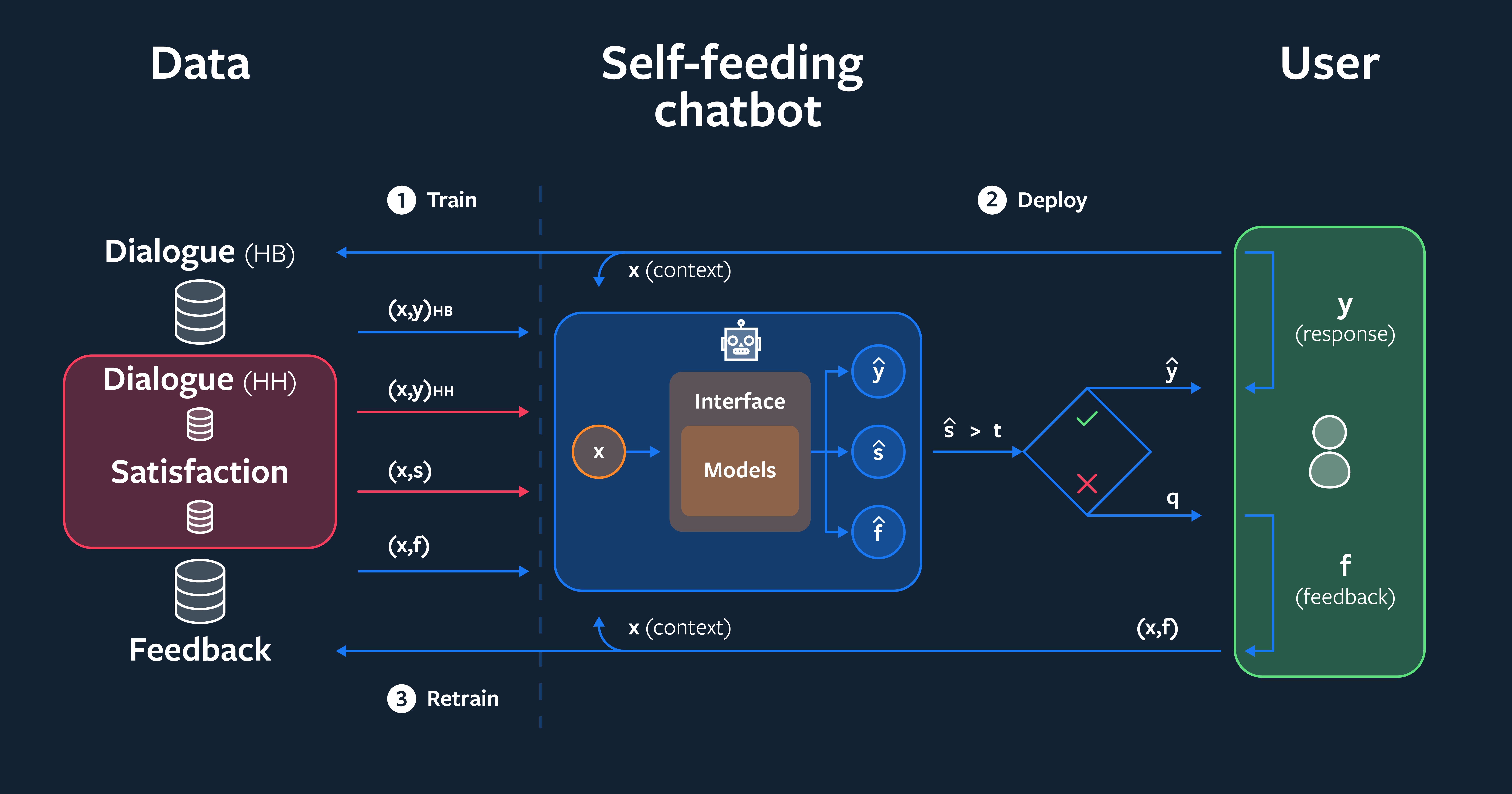
自助式聊天机器人会评估它的对话伙伴对它在互动过程中做出的反应的满意度。当对话智能体认为自己犯了错误时,它可以要求反馈。学习预测这样的反馈有助于模型随着时间的推移而改进。当它相信自己没有犯错时,可以使用标准的监督学习技术来代替。最终,我们发现,无论传统监督的数量多少,通过与自助式聊天机器人的对话学习,都能显著提高性能。当初始训练集很小时,这种改进最为显著:在这种情况下,我们看到对话任务的正确率提高了 9.4 个百分点,相比基线提高了 31%。
下一代聊天机器人
我们的研究表明,训练模型来改善当今聊天机器人的一些最常见的弱点是有可能的。随着时间的推移,我们将通过缩小并最终弥合与人类表现的差距,努力将这些子任务合并到一个统一的智能代理中。在未来,智能聊天机器人将能够以一种人性化、一致性、同理心和吸引人的方式进行开放域的对话。
作为 Facebook AI 对更广泛的研究社区的贡献的一部分,我们在开源对话研究平台 ParlAI 中分享我们的新模型、训练代码和数据集。我们希望这一平台将继续促进整个研究领域的研究进展,并推动对话研究向前发展。
作者介绍:
Emily Dinan、Jason Weston,供职于 Facebook AI 的研究科学家。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论