
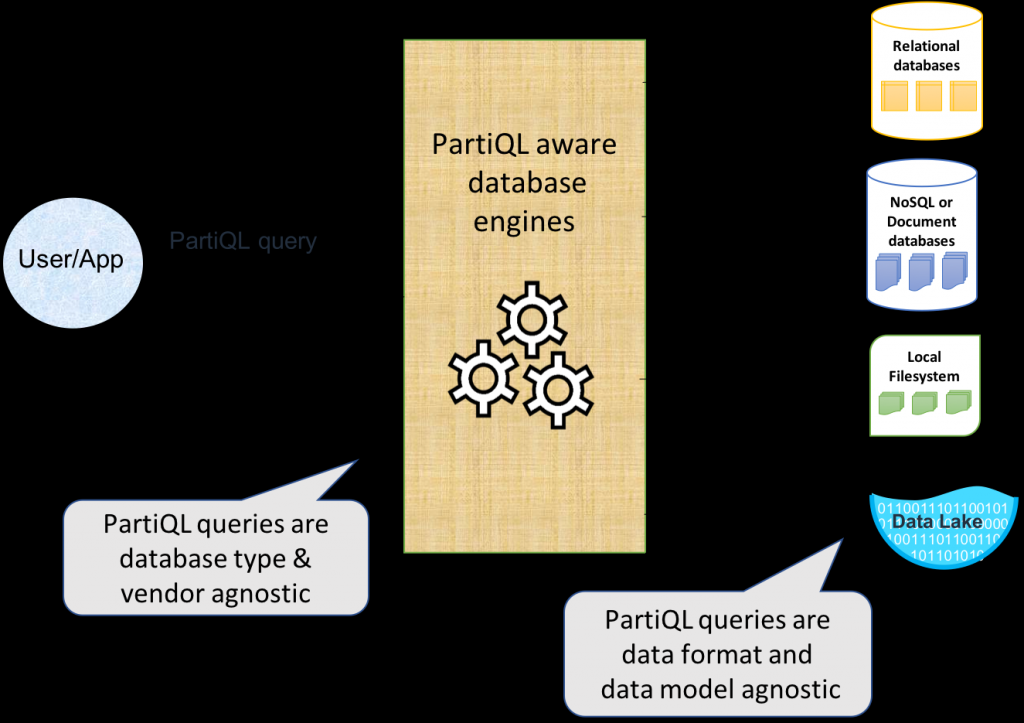
数据正以前所未有的速度被收集和创造,但组织中不到一半的结构化数据被积极用于决策。问题的根源在于,有些数据可能是高度结构化的,并存储在 SQL 数据库或数据仓库中。其他数据可能存储在 NoSQL 引擎中,包括键值存储、图形数据库、分类帐数据库或时间序列数据库。
正文
数据正以前所未有的速度被收集和创造。这些数据大多旨在推动业务结果,但根据《哈佛商业评论》报道:“……平均而言,组织中不到一半的结构化数据被积极用于决策……”
问题的根源在于,数据通常分布在关系数据库、非关系数据存储和数据湖的组合中。有些数据可能是高度结构化的,并存储在 SQL 数据库或数据仓库中。其他数据可能存储在 NoSQL 引擎中,包括键值存储、图形数据库、分类帐数据库或时间序列数据库。数据也可能驻留在数据湖中,可能以没有模式的格式存储,或者可能涉及嵌套或多值(例如Parquet、JSON)。每种不同类型和风格的数据存储可能适合特定的用例,但是每种存储都有自己的查询语言。其结果是查询语言和数据存储格式之间的紧密耦合。因此,如果你想将数据更改为另一种格式,或者更改用于访问/处理该数据的数据库引擎(这在数据湖领域并不少见),或者更改数据的位置,你可能还需要更改应用程序和查询。这对于有效使用数据湖所需的敏捷性和灵活性是一个非常大的障碍。
今天,我们很高兴地宣布了PartiQL,这是一种与 SQL 兼容的查询语言,使用它可以轻松高效地查询数据,无论数据存储在何处或以何种格式存储。只要你的查询引擎支持 PartiQL,你就可以处理关系型数据库的结构化数据(事务和分析),开放式数据格式的半结构化和嵌套数据(如 Amazon S3 数据湖),甚至无模式的 NoSQL 或文档数据库中允许不同行具有不同属性的数据。我们在 Apache2.0 许可协议下开源了 PartiQL教程、规范和该语言的参考实现,这样每个人都可以参与、贡献和使用,从而推动这种统一查询语言的广泛采用。
PartiQL 开源使开发人员可以很容易地在自己的应用程序中解析和嵌入 PartiQL。该实现支持用户将 PartiQL 查询解析为抽象语法树,应用程序可以分析或处理这些抽象语法树,它也支持直接解释 PartiQL 查询。
PartiQL 解决了我们在 Amazon 中遇到的问题。它已经应用于 Amazon S3 Select、Amazon Glacier Select、Amazon Redshift Spectrum、Amazon Quantum Ledger Database(Amazon QLDB)和亚马逊的内部系统。同时,Amazon EMR将 PartiQL S3 查询下推到 S3 Select。更多的 AWS 服务将在未来几个月增加支持。在亚马逊之外,Couchbase 也期待着在Couchbase Server中支持 PartiQL 服务器。
我们期待数据处理引擎的创建者深入 PartiQL,并加入我们一起解决一个影响到所有用户数据、所有行业的问题。
我们为什么构建它
我们开发 PartiQL 是源于 Amazon 自己需要查询和转换大量多样化数据的需求——不仅仅是 SQL 表格数据,还有嵌套和半结构化数据——这些数据以各种格式存储在各种存储引擎中。亚马逊的零售业务已经有了巨大的半结构化数据集,通常以lon格式存储。亚马逊的零售业务,由 Chris Suver 负责,希望有一种类似于 SQL 的查询语言。多个 AWS 服务,比如QLDB,验证了模式可选的面向文档的数据模型所带来的好处,但也想利用现有的 SQL 知识和工具。最后,AWS 关系型数据库服务,比如Redshift,以及许多现有的 SQL 客户端,都需要扩展为可以访问数据湖中的非关系型数据,同时与 SQL 保持严格的向后兼容性。同时,数据库研究社区(使用类似 UCSD SQL++查询语言)显示,可以设计出简洁、有充分依据且非常接近 SQL 的查询语言,同时还具有处理嵌套和半结构化数据所需的能力。
Don Chamberlin 是 SQL 语言规范的创建者,他说:“随着 JSON 和其他嵌套和半结构化数据格式的重要性日益增加,对于面向这些数据格式的查询语言的需求变得越来越清晰。将 SQL 用于这个目的的好处在于可以利用行业在 SQL 技能、工具和基础设施上的投资。Yannis Papakonstantinou 博士的 SQL++提案,以及基于 SQL 的语言 PartiQL,表明查询半结构式数据所需的 SQL 扩展相当少。我希望这些小的语言扩展将有助于促进新一代应用程序处理 JSON 和其他格式灵活的、有或没有预定义模式的数据。”
因此,我们开始创建一种语言,提供了严格的 SQL 兼容性,以最小的扩展实现嵌套和半结构化处理,将嵌套数据作为一等公民,允许可选模式,并独立于物理格式和数据存储。
其结果是 PartiQL,它提供了一种简单一致的方式跨多种格式和服务查询数据。这让你可以跨数据源移动数据,而无需修改查询。它与 SQL 向后兼容,提供多值、嵌套和无模式数据扩展,与标准 SQL 的联合、过滤和聚合功能无缝融合。
PartiQL 设计原则
以下设计原则概括了我们的设计目标,是 PartiQL 的基础:
兼容 SQL:PartiQL 通过保持与 SQL 兼容来促进应用。现有的 SQL 查询将可以继续在(也就是说,他们将维持它们的语法和语义)经过扩展提供 PartiQL 支持的 SQL 查询处理器中运行。这就避免了对现有 SQL 进行任何重写,使开发人员和业务智能工具更容易利用 PartiQL。
嵌套数据作为一等公民:数据模型将嵌套数据视为数据抽象的基本部分。因此,PartiQL 查询语言提供的语法和语义可以全面、准确地访问和查询嵌套数据,并且可以与标准的 SQL 特性自然地组合。
可选模式与查询稳定性:PartiQL 不需要在数据集上预定义模式。按照设计,它可以用于有模式的数据库引擎(写时模式或读时模式),也可以用于无模式的数据库引擎。从技术上讲,模式是加到现有的数据上,只要数据本身是相同的,一个查询的结果就不会改变。因此,更容易为多个存储提供一致的访问,而不用管所涉及的引擎的不同模式假设。
最小扩展:最小化 PartiQL 对 SQL 的扩展。这些扩展容易理解,实现高效,彼此之间以及与 SQL 本身都可以很好地组合。这可以在结构化、半结构化以及嵌套数据集的组合上实现直观的过滤、联合、聚合和窗口。
格式独立:PartiQL 的语法和语义并不绑定到任何特定的数据格式。底层数据可以是 JSON、Parquet、ORC、CSV、Ion 等格式,编写的查询是相同的。查询在映射到不同底层格式的综合逻辑类型系统上运转。
数据存储独立:PartiQL 的语法和语义并不绑定到特定的底层数据存储。得益于其表达能力,该语言适用于不同的底层数据存储。
过去的语言已经解决了这些原则的子集。例如,Postgres SQL 兼容 JSON,但是未将嵌套的 JSON 数据作为一等公民。半结构化查询语言将嵌套数据作为一等公民,但允许偶尔不兼容 SQL,或者甚至不像 SQL。PartiQL 是解决这一整套原则的第一种语言。
从它的设计原则就可以预料到,对于 SQL 用户而言,PartiQL 简单而熟悉。自 2018 年以来,它已经被 Amazon Redshift Spectrum 的多个客户使用:
Annalect是 Omnicom 的全球数据和分析部门,提供专门的、可扩展的解决方案,使数据可操作,它是 Omnicom 革命性精准营销和见解平台 Omni 背后的驱动力。“PartiQL 让我们能够利用 Amazon Redshift Spectrum 直接在 Amazon S3 中查询嵌套数据而不必展开(un-nesting),也将使我们能够使用标准化语言轻松地把嵌套数据从 Amazon S3 转移到 Amazon Redshift 本地表中,”Annalect 高级工程师和架构师 Eric Kamm 说。John Briscoe 是 Annalect 的数据和业务主管,他补充道:“我们也很兴奋,它将为我们提供跨数据平台一致的查询语法,让我们更容易开发多数据平台应用程序和进行新员工开发培训”。
Yelp软件工程师 Steven Moy 说:“PartiQL 弥补了多存储环境中缺失的关键部分——一种可以跨多个领域特定的数据存储的高级声明式语言。在 Yelp,我们利用多种 AWS 数据存储(Redshift、S3、DynamoDB)技术将本地最好的企业提供给用户,并使本地企业主能以最好的方式找到本地受众。借助 Amazon Redshift Spectrum,Yelp 能够使用八倍的数据量来帮助我们的开发者社区根据数据做出决定,我们期待借助 PartiQL 使这种伙伴关系更进一步,让 Yelp 的开发者把时间集中在创造愉快的用户体验上,而不是掌握一种新的查询语言或解决传统的一致性问题。”
与传统的 SQL 不同,PartiQL 查询语言也满足 NoSQL 和非关系型数据库的需要。PartiQL 已经被Amazon Quantum Ledger Database(QLDB)采用作为查询语言。
Andrew Certain 是 AWS 高级首席工程师兼Amazon Quantum Ledger Database(QLDB)架构师,关于选择 PartiQL,他说:“QLDB 需要一种灵活的、面向文档的数据模型,这样用户可以很容易地存储和处理结构化和半结构化数据,而没有定义和改进模式的负担。与此同时,QLDB 希望从 SQL 广博的知识中获益。PartiQL 很好地满足了这两个目的。它用于访问嵌套和半结构化数据的扩展很少,但很强大,也非常直观。”QLDB 目前尚处于预览模式,它是采用 PartiQL 的 AWS 服务之一。
Couchbase Server利用基于 JSON 的、面向文档的数据模型,它也希望采用 PartiQL:
Ravi Mayuram 是Couchbase的高级工程副总裁兼首席技术官,他说:“三年多前推出 N1QL 时,他们是将 SQL 带给 JSON 的先锋,Couchbase 认为,面向关系数据库的 SQL 赖以创建的基础同样适用于 JSON 数据模型和数据库。在这种融合中,PartiQL 迈出了令人愉快的下一步,我们期待对它的支持。”
PartiQL 参考引擎
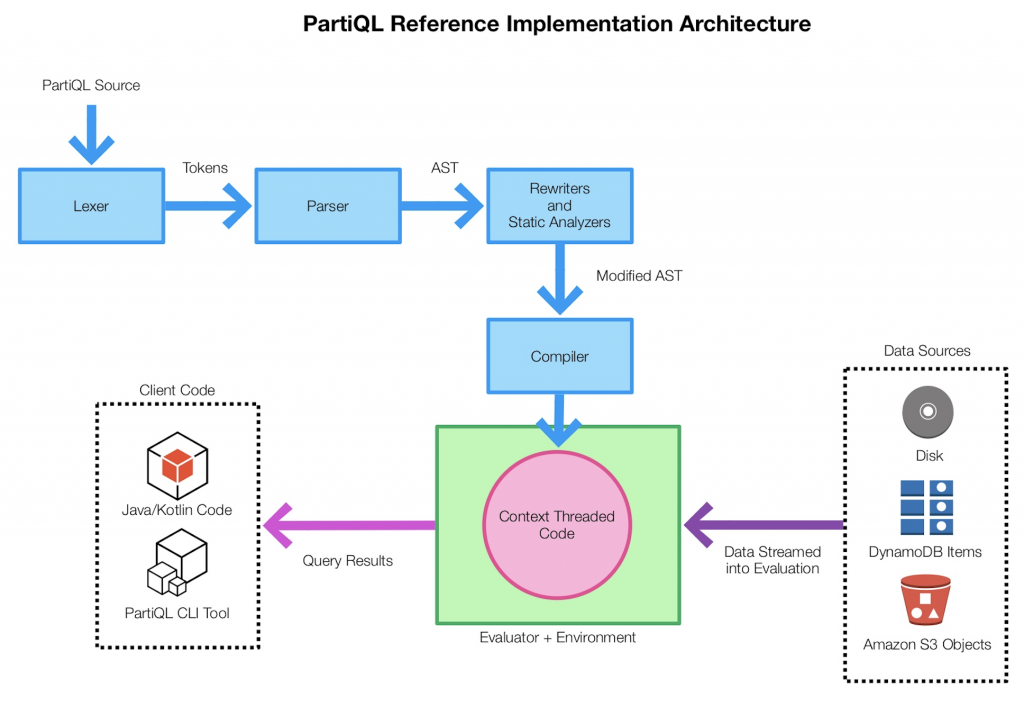
这张图表从一个非常高的层面上展示了 PartiQL 的参考实现。我们开源了 PartiQL 查询表达式的词法分析程序、解析器和编译器。我们提供了一个库,可以嵌入或作为独立的工具用于运行查询。用户可以使用这个库简单地验证 PartiQL 查询,或者在他们的系统中嵌入 PartiQL 求值器用于处理数据。这个库提供了一个数据接口,可以绑定到应用程序中可能存在的任何数据后端,并对 Ion 和 JSON 提供了开箱即用的支持。
准备开始
PartiQL 开源实现提供了一个交互式 shell(或 Read Evaluate Print Loop ,缩写为 REPL),允许用户编写 PartiQL 查询并对其求值。
前提条件
PartiQL 需要你在机器上安装 Java 运行时(JVM)。你可以从OpenJDK、OpenJDK for Windows或Oracle获得 Java 运行时的最新版本。
按照说明安装JDK软件并将JAVA_HOME设置为Java运行时的安装路径。
下载 PartiQL REPL
PartiQL的每个版本都有一个归档文件,其中包含 PartiQL REPL 的 zip 压缩文件。
你可能需要点击 Assets 来查看 zip 和 tgz 归档文件。把最新版本的 partiql-cli zip 归档文件下载到你的机器上。归档文件名称后面的部分是 PartiQL 的版本,如 partiql-cli-0.1.0.zip。
在你的机器上解压归档文件,会产生下面的文件夹结构(… 省略的文件/目录) :
根文件夹 partiql-cli 包含一个 README.md 文件和三个子文件夹:
bin 包含启动脚本:partiql 用于 macOS 和 Unix 系统,partiql.bat 用于 Windows 系统。执行这些文件以启动 REPL。
lib 包含运行 PartiQL 所需的所有 Java 库。
Tutorial 包含 pdf 和 html 格式的教程。子文件夹 code 包含三种类型的文件:
扩展名为.env 的数据文件。这些文件包含我们可以查询的 PartiQL 数据。
扩展名为.sql 的 PartiQL 查询文件。这些文件包含教程中使用的 PartiQL 查询。
扩展名为.output 的样例查询输出文件。这些文件包含在适当的数据上运行教程中的查询的样例输出。
运行 PartiQL REPL
在 Windows 上
运行(双击)particl.bat 应该会打开一个命令行提示符,并启动 PartiQL REPL,界面如下:
在 macOS(Mac)和 Unix 上
打开一个终端,并导航到 partiql-cli 文件夹。该文件夹的名称以 PartiQL 的版本号作为后缀,即 partiql-cli-0.1.0.
输入./bin/partiql 并回车启动 REPL ,界面如下:
测试 PartiQL REPL
编写一个简单的查询验证 PartiQL REPL 是否正常。在 PartiQL>后面输入以下查询:
按两次回车。输出类似下面这个样子:
恭喜!你已经成功安装并运行了 PartiQL REPL。PartiQL REPL 现在正在等待更多的输入。
退出 PartiQL REPL:
在 macOS 或 Unix 系统上按下 Control+D
在 Windows 系统上按下 Control+C
或者关闭终端/命令行窗口。
从文件加载数据
将所需数据载入 REPL 的一个简单方法是在启动 REPL 时使用-e 开关,并提供包含数据的文件名称:
你可以使用专门的 REPL 命令!global_env 查看 REPL 的全局环境中加载了什么数据,即:
如何参与 PartiQL
PartiQL 是在 Apache2.0 许可协议下完全开源的。我们欢迎你在进一步扩展规范、构建技术和增加其在用户社区的采用和份额方面做出贡献。了解更多关于PartiQL的信息。
你可以向good first issue通过发送 pull 请求来为项目做出贡献。如果存在 Bug 或缺少特性,则请提交问题。阅读本教程了解 PartiQL 语法、如何扩展 SQL 和分步演练。想了解 PartiQL 的每个细节吗?请通读规范。
英文原文:Announcing PartiQL: One query language for all your data

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论