


本文最初发布于 scottrogowski.com 网站,经原作者 Scott Rogowski 授权由 InfoQ 中文站翻译并分享。
在现代技术公司(无论大小)的架构中,微服务已经无处不在。但是,它们真的比以前的开发模型更优秀吗?在这篇文章中,我将揭穿工程师们关于微服务所讲述的七大谎言,以及为什么它可能是一种反模式。
免责声明 1:我不是架构师,也没假装自己是架构师。本文内容只是我多年来作为软件开发人员/经理所做的观察总结。我曾见证两家公司在微服务架构的压力下陷入泥潭。由于很少有人深度质疑这种新生范式,因此我想表达自己的声音。不过,我经验有限,所以也欢迎反馈意见。
免责声明 2:互联网上也有其他标题相似的演讲/文章,这里就不纠结这种相似度了。
单体架构和微服务之间有何区别?
开始研究谎言前,我们先来定义一下术语。后端软件架构可以分为单体和微服务两种。单体架构指的是由一台或多台服务器运行单个应用程序,其通常从单个存储库中部署。使用多台服务器时,这些服务器将运行相同的代码。从 90 年代到 2000 年代,多数情况下这都是默认的架构。
随着互联网的发展,大型公司开始面临单体架构的局限。为解决这一问题,公司开始将其代码分割成在不同服务器上运行的多个组件。例如,一家公司可能会有运行日志记录的服务、调用外部 API 的服务以及管理数据库的服务。亚马逊 AWS 在这一风潮中扮演了重要角色,因为它让部署服务器和管理基础设施的工作变得非常容易。
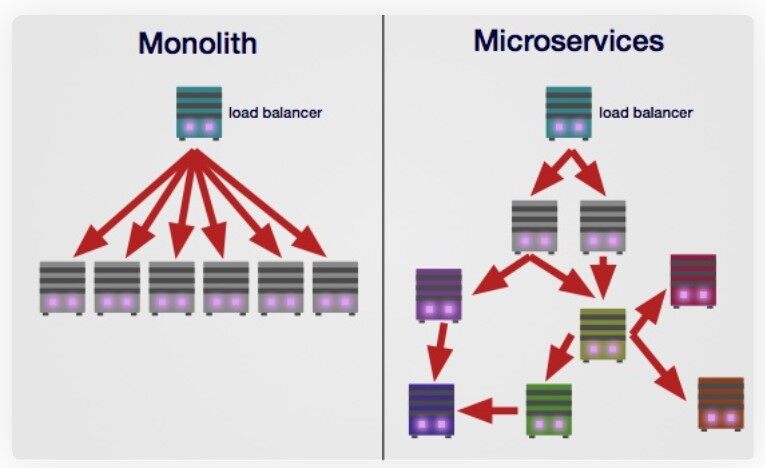
随着时间流逝,中小型公司也开始接受这种新的发展范式。很快,一个围绕微服务的产业发展壮大起来,它逐渐成为寻求扩展的企业默认架构。不幸的是,现在有许多公司由于这种选择而掉进了各种之前想不到的坑里。
谎言 1:跨服务的关注点分离降低了复杂度
“[关注点分离]”指的是在不相关的代码间应存在隔离墙。当不相关的代码需要协同工作时,应该使用抽象良好的接口并尽量减少状态共享。很多入门编程课程都将其视为标准的软件开发公理。你的代码对其他代码的了解,越少越好。同样,一个函数执行的功能越多,你就越需要考虑运动部件之间的复杂关系(即复杂度)。而且,我们作为合格的工程师就应该努力降低复杂度。
我坚信这一公理。从逻辑上讲,分离关注点的最佳方法是否就是让你的无关代码运行在不同的服务(服务之间以 API 沟通)中呢?
不,并非如此。
经典的单进程关注点分离之所以有效,是因为它可以最小化并简化不相关代码之间的接口。在设计良好的程序中,此接口可以只有带 return 语句的单个函数调用。不相关代码之间的边界本质上是复杂的,而简单的接口有助于管理这种复杂性。
相比之下,在微服务中,函数调用被替换为网络请求。这种新的服务间障碍严格来说更加复杂且更不可靠。首先,每个网络调用都需要一定数量的样板。其次,工程师现在需要默认任何服务随时会失效。相反,在单体中,当代码失败时整个服务都会失败。尽管这听起来很糟糕,但由于现在只有一种故障情况,因此它更易于管理。
在实践中更糟
左下方的图表是几年前 Uber 的微服务架构。它很简单,很容易理解。右边是 Uber 的实际服务地图。
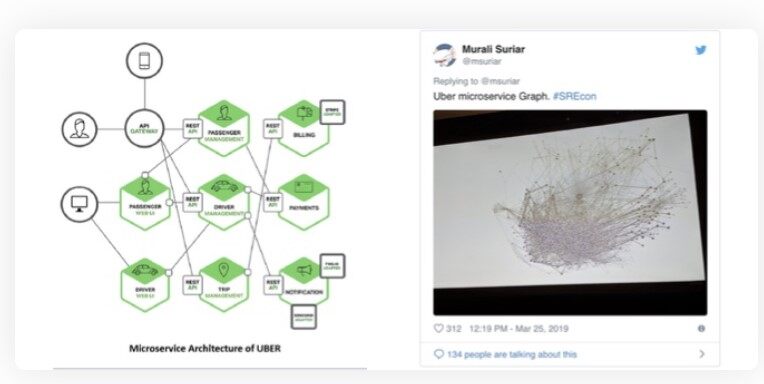
我敢说 Uber 的任何人都不知道这个架构是如何工作的。曾在使用微服务架构的大型公司工作过的人都知道,Uber 的经验并不是特例。
模型与现实之间存在这种差异的原因有两个。首先,这些图表通常过于简化。架构师设计这些图表是为了交流,而非完美反映现实。但因为它们隐藏了复杂性,也就容易误导决策。如果 Uber 的技术领导者知道自己的架构会变成什么样,他们还会走这条路吗?
其次,一旦你投身于微服务,随后的所有技术决策都将受其影响。因此,开发新功能时总要启动新的服务。架构图很快就会变得非常复杂,膨胀成上图那种密密麻麻的网状结构。
谎言 2:微服务提高开发速度
当你采用“关注点分离”公理并将其应用在开发人员头上时会发生什么?你会得到一些孤立的团队,他们之间各自独立。从表面上看这似乎是有益的。如果团队只需要操心自己的服务,那将减轻他们的认知负担,并提高他们的生产力。现在,工程师无需担心基础架构中其他部分的复杂性了。
问题在于,大多数新功能都需要一些跨多个服务的补丁。
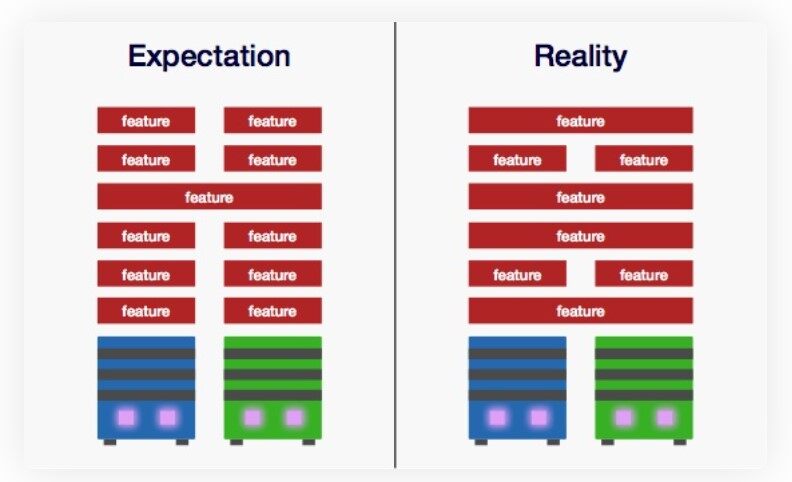
许多功能需要在两个或多个服务上开发
开发多服务功能需要在具有不同优先级和能力的团队之间安排大量会议。考虑到他们从事的多个不同项目,这些团队可能需要异步协作。你现在还需要交付经理来分配工作和管理迭代。
从技术角度来看,实现多服务功能可能需要编辑多个存储库。至少,它需要一种方法来测试在多个服务上运行的代码。
对许多公司而言,这种多服务测试的需求是事后才会意识到的。架构师在设计技术栈时会假设大多数开发工作都将在单个服务上进行。多服务功能将很少见。你如何手动测试多服务功能?你需要在机器上启动多个容器,并仔细设置每个容器的状态。那单元测试呢?你将在哪里对多服务功能进行单元测试?是仓库 A 还是仓库 B?文档写好了吗?部署往往会破坏未调整好的服务。很容易想象,数据流中的一个小错误会破坏多个下游服务。我们应该期望工程师理解所有可能依赖其代码的下游服务吗?
如果你的组织没有投入大量的工程资源来构建多服务测试流程,那么除了最常见的功能之外,开发新功能的速度会像蜗牛般缓慢。如果没有质量测试框架,看似简单的任务(例如“添加分页”)也可能会变成历时数月、跨多个团队的工作。
谎言 3:部署众多小型服务比部署整个应用更安全
“回滚”是现代软件工程需要面对的现实。作为工程师,当你部署的代码会破坏某些功能时,必须回滚部署并还原提交。没有人想要回滚——尤其是部署代码的工程师。但是,好的公司知道错误的部署总有可能出现,因此必须对其进行管理。
微服务架构的一个观点是,部署多个独立服务比部署整个应用更安全。当一项服务中断时,其他服务还有回退可用。整个应用程序将继续运行,客户不会有什么感觉。
这种方法存在多个问题。
首先,这要假设你的服务可以容忍其他任何服务的随机消失。这是 Netflix 的“Chaos Monkey”方法。但是,将其构建到服务中并非易事,测试它需要资源,并且除非这是工程的最优先事项,否则实践中人们多大程度上会遵守这一要求就不一定了。
其次,部署多服务功能时,服务的上线时间会有所不同。在一段时间里,你的那些服务将有不同的版本。对此有多种处理方法。你是否在半夜部署?你是否并行维护不同的 API 版本?你是否使用托管流?所有解决方案都需要额外的工程资源。如果部署意外破坏了(甚至不是部署的一部分)服务中的状态,会发生什么情况?你是否有针对任何意外情况的预案?
虽然单体部署也会出错,但是有多种方法可以缓解这种情况(蓝色/绿色、金丝雀等等)。虽然这些方法也可用于微服务,但是设置和管理安全部署并非易事,应对一项服务总比应对多个服务要容易些。
谎言 4:分开扩展服务通常是有利的
在每个应用程序中,都有经常运行的部分和很少运行的部分。很少运行的部件比频繁运行的部件需要的资源要少一些。那么分开扩展这些部件是否有意义?
从根本上讲,扩展软件的原因是因为你的软件需要更多的核心资源。这些资源可能是 CPU 周期、内存、磁盘空间或网络。例如,当 CPU 以 100%运行时,可以启动另一个服务来减轻压力。
对于大多数应用,水平扩展(克隆单体)就足够了。水平扩展的复杂度较低,许多云服务都可以用很少的配置来做到这一点。
相比之下,选择分开扩展许多微服务有两个常见原因。首先,如果你的代码具有实质上并行的部分,则在某些情况下将计算块分配给不同的“worker”可能会有些意义。重要的是,相对于每个任务的总计算量,数据传输和加速的开销必须够低。因此,将十个计算块(每个计算耗时 10ms)发送到服务器,开销却为 100ms 就没有并行的价值了。因为顺序执行耗时是 10x10ms=100ms,而并行却是 10ms+100ms=110ms。但是,如果每次计算都花费 100 毫秒,则将它们并行化就能节省时间。
其次,如果资源需求在整个请求中出现变化,则单独扩展各个微服务可能是有意义的。例如,如果一个请求在开始时是受内存限制的,而在结束时是 CPU 限制的,那么就可以将请求的开始部分放在高内存服务中,将结束部分放在高 CPU 服务中。即便如此,除非你是独角兽级别的企业,否则分开扩展服务带来的财务优势可能也无法抵消额外的复杂性。
另外,你试图省钱的做法可能会适得其反:

快乐的云客户
谎言 5:微服务架构性能更高
我在学校学到了一些经验法则。
读取内存所需的时间是读取二级缓存的 10 倍
读取硬盘驱动器所需时间是读取内存的 10 倍。
从网络读取所需的时间是从硬盘读取的 10 倍。
这些数字是粗略的近似值。我们来看一下数据中心中的网络通信与从内存读取之间的实际差异:2009 年,从内存中顺序读取 1MB 的耗时估计为250000ns;2019 年,在 AWS 数据中心中,两个 EC2 实例之间的通信速度可以达到5Gbps。
简单算一算:
2009 年的内存:0.25 毫秒内 1 兆字节
2019 年的数据中心:1 秒内 5Gbit=1 秒内 0.625GBytes=0.64 秒内 1 兆字节
觉得差距不算大?可我们要意识到:
上面的网络速度是最好的情况
我们正在对比 2009 年与 2019 年的指标
要通过超高速的 AWS 网络发送这一兆数据,我们仍然需要从内存中读取它。
假设你只有一个依赖项,那么这也意味着几千倍的速度差距。实际情况中这一差距还会大得多。
难怪我们现在使用字节流来让每个请求快那么几毫秒。当然,对于字节流来说,调试服务间通信也是需要工具的。
谎言 6:管理多个服务并不难
软件工程师喜欢自欺欺人。也许你以前听过,什么“不需要很长时间”“请给我几个小时”或“我可以在周末完成任务”,诸如此类。优秀的项目经理会理解这一点,并将工程师的估算值乘以四(或四十……)。
使用微服务的决策也会有同样的乐观情绪。这项工作并不是"为所有人获取 AWS 证书并移动一些代码"那么简单。实践中会有大量意外开销。下面是你需要的一些人员和工具类别:
架构师。你需要一些人来绘制美观且过于简化的图表并做演示。
发布管理。现在,你需要协调各个部署并管理多个 pipelines。这种协调工作将需要通用工具链,还要有团队来维护这一工具链。
DevOps。“常规”工程师既没有专业知识,也没有意愿来正确配置他们的服务。他们也很难正确处理安全性问题。
数据工程师。如果你很幸运能够按照这些建议来成功分解数据存储,那么你现在需要一个团队来将这些数据提取到一个地方进行分析。
配置文件。虽然一些额外的 YAML 文件听起来并不那么糟糕,但这里会出现最危险的错误。它们也难以测试和调试。
你不仅需要支付所有这些额外人员的薪酬,而且还指数级增加了工程组织中的沟通渠道数量。这会拖慢所有人的步伐。
谎言 7:如果你从头开始精心设计微服务,它们将会起作用
这里我引用一段文字:
正常运作的复杂系统一定是从一个正常运作的简单系统演变而来的。从头开始设计的复杂系统永远无法正常工作,也无法靠打补丁来正常运作。你必须从一个简单系统起步。——Gall定律
总结
既然有这么多如此明显的缺点,为什么微服务还这么受欢迎呢?
我相信大多数工程师(包括我本人)都有一定程度的自我能力否定倾向。很多时候,我们需要面对自身能力不足以应付的状况,却依旧要跨过眼前的障碍。在这种情况下,依靠他人的成果和“最佳实践”是更安全的。但是,我们很快就认为这些“最佳实践”是经过深思熟虑的,或肯定适用于我们的问题。当你启用更多服务时,云供应商会受益。微服务倡导者在你购买他们出的书时也会赚钱。他们俩都有动力向你兜售你本来用不到的技术。
不管怎样,我认为在某些情况下微服务可能是正确的选择。如果你是谷歌或 Facebook 那样的企业,并且要应对数十种产品上数以十亿计的活跃用户,那么单体架构肯定是不够的。如果你有大量可并行化的任务,那么只用单体也是不行的。
我的目的是要告诉大家,后端服务设计是非常重要的,没有哪种选择是银弹。无论我们是在谈论微服务还是单体,SQL 还是 NoSQL,Python 还是 Node,本质都一样。任何技术都不可能完美适应所有用例。
因此,你应该认真思考各种想法,质疑所有假设并清醒地做出架构决策。你的选择可能会成就或拖垮你的公司。
英文原文:
The seven deceptions of microservices

技术是文明进步的力量

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 9 条评论