

一、背景
1、线上问题回顾
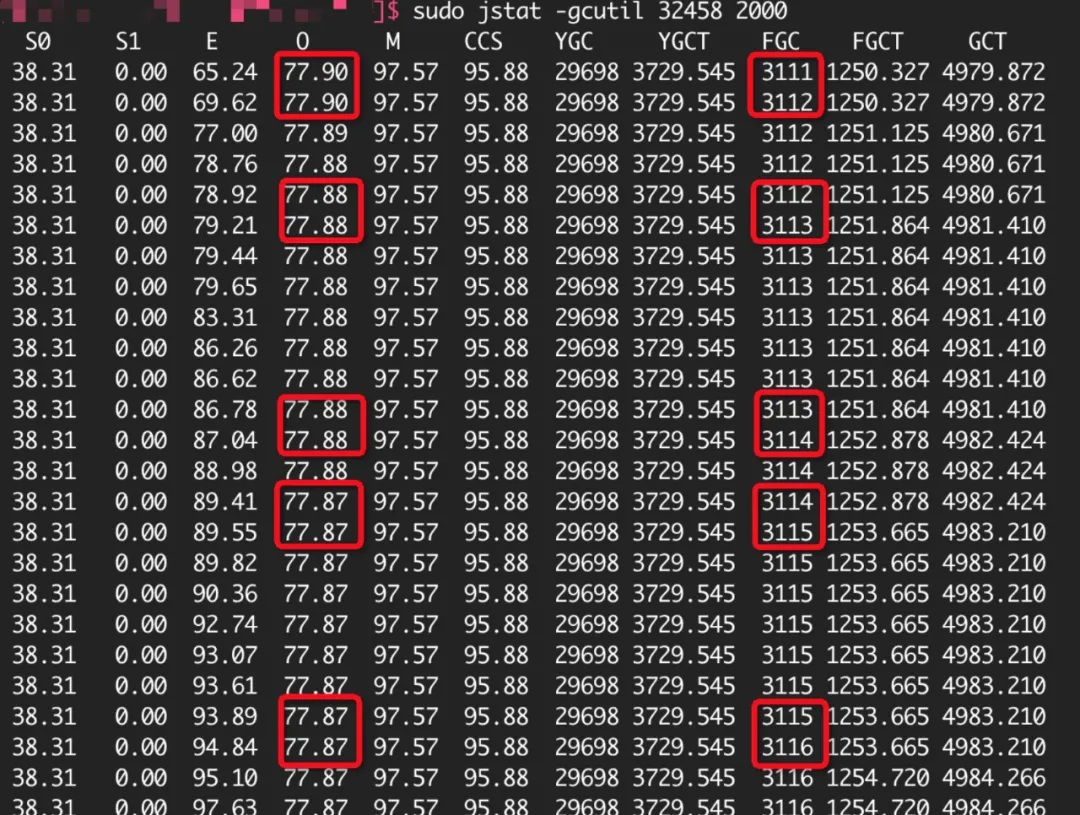
2019 年 8 月某天,那时我刚入职还不到一个月,遇到一个特殊的线上问题:某报价应用个别机器连续 FGC 不停(准确的说是 FGC 几乎没任何效果),这些机器重启后不久继续开始不停的 FGC。当时特意留了当时现场的 jstat 数据截图,这也是我头一次遇到连重启应用都解决不了 FGC 的场景。最终,通过删除一些无用字段等手段让 FGC 问题得到缓解。
之后,我认真的梳理了这个应用的核心接口逻辑及总体架构设计,最后对这个“有状态"架构设计(准确的说,是分布式的数据懒加载架构带来的压力及内存不均衡)有了清晰的认识,也萌发了对这个设计进行“大手术”的念头,本文的重点也是对这种架构进行的优化。
2、涉及的核心接口说明
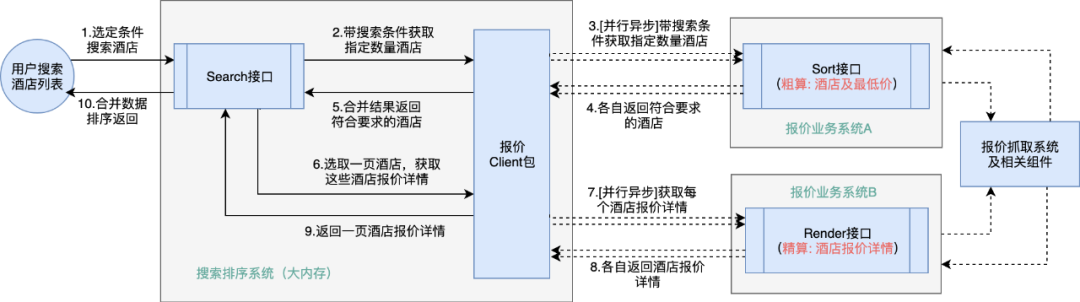
首先做一下相关名词解释:酒店排序算法通常分为全局排序(粗排)和部分酒店二次处理(精算),全局排序阶段涉及酒店量大,而且特征影响因素很多,报价的具体精确值对排序结果影响不大,之后部分二次处理是因为需要选择部分做页面展示,需要对展现的那些少量酒店按身份、参与的活动等精确计算。
接下来具体介绍一下这个应用提供的核心接口:Sort 接口。这个接口主要完成的就是对用户搜索酒店列表时的“粗排”,具体来说,是根据城市等参数返回满足条件的酒店排序,同时返回最低价等一些报价信息。这个“粗排”完成之后,上游的搜索排序系统结合一些特征因素选择出需要展示的部分酒店,继续调用其他应用的 Render 接口完成对指定酒店的“精算”,这时会得到实际的酒店最低价及参加的活动、优惠等详细报价信息。总结一下,Sort 接口完成的是酒店的筛选及基础的排序,最终每个酒店的报价详细信息是来自于其他应用的 Render 接口完成。
我们这里实际要做的就是对 Sort 接口的优化。
3、“有状态”架构说明
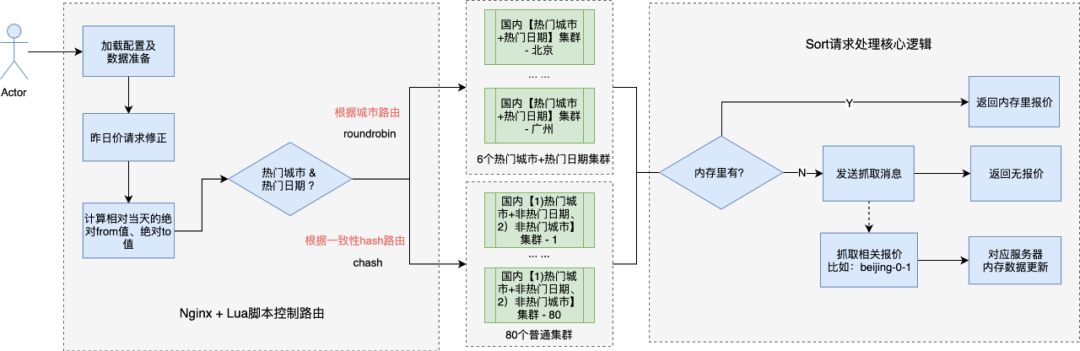
通过下图可以看出,Sort 接口在 Nginx(之后切换到 OpenResty)层有负责的路由逻辑,在路由层根据多个请求参数借助一致性 hash 等路由策略将整个应用拆分了将近 90 个集群!不同的集群的内存里缓存了不同的数据。这一切,标志着 Sort 接口的设计是个复杂的“有状态”架构设计。
暂时先不说“有状态”架构设计的优劣,单独为每个集群准备 1 台服务器,线上就需要将近 90 台服务器,而实际中我们需要保证每个小集群都自成一个独立完整的集群,那么每个集群至少需要 2 台服务器(否则发布时某个集群就可能没机器在线了),这样线上就至少需要将近 180 台服务器了。再加上一些对北上广深等热门城市需要重点保证高可用,每个热门集群会冗余部署 10 几台甚至 20 几台服务器,还要考虑跨机房部署等各种情况,最终这个应用实际在线服务器将近 340 台。
Sort 接口架构设计额外需要补充的是,当请求进到指定服务器上进行处理时,如果内存里没有数据命中,同步流程会直接返回无报价,同时会异步抓取相关报价,借助一条链路的“有状态”设计(比如发送和消费的消息带 ip 地址),最终相关的报价会写到指定的服务器内存里。这样下次有相同的请求进来时就可以命中内存了,这种设计带来的是每个请求都会牺牲第一个用户的体验。
( 说明:热门日期指的是出发日期、到达日期相对今天都在 3 天以内,即 T+0、T+1、T+2、T+3 ,比如 beijing03 走的是专门的热点集群,而 beijing04 由于日期不热门,走的是普通集群 )。
二、调整前架构利弊分析
接下来,具体看一下当前“有状态”架构结合现有业务场景表现出来的优缺点。
1、优点
1)绝大部分请求可以精确命中内存,数据处理极快;
2)热门城市+热门日期对应的集群是稳定的,也承担了绝大部分核心的请求压力;
3)非热点集群如果出问题,影响较小,请求量也小。前面的问题回顾里,实际影响是很多非热门的城市的请求,虽然个别集群在一直 FGC,但一个非热门集群占比很低,对总体影响并不大。
2、缺点
1)采用有状态设计,增大了分布式系统的复杂性,运维成本较高,扩展性差一些,不能轻易做横向扩展;
2)路由层很难调整,且调整的风险较高。如果调整,还需要考虑内存及 redis 里已有数据的处理,并且出现短时间的数据命中率变低;
3)非热门集群请求不均衡(单个集群内是均衡的),这是一致性 hash 策略带来的,最终导致不同集群处理的请求量差别很大;
4)非热点集群间使用内存差别较大。通常一级节点为"城市 FromTo",主要看城市下酒店的数量及酒店报价情况,不同城市差别巨大,因此会出现有些服务器内存紧张、有的服务器内存使用很少的情况;
5)为了控制缓存的数据量,非热点集群一级节点有上限,这就容易出现一些重要的请求没有被缓存。比如上限的 100 个节点满了,之后 beijing04 这种请求就无法放入内存,而之前有 xxx04 可能一直占着内存节点却用不上;
6)热门日期不可变,而实际中热门日期可能会有短时间的调整,比如国庆前 beijing04、beijing05 可能变为热门日期;
7)无法确定一个非热门请求具体落在哪个集群哪个节点上,因为实际日期一变算出的绝对 From 和绝对 To 的值就发生变化了;
8)同一个集群下不同节点缓存的内存数据也是不同的,导致很难精确的知道一个请求具体会落在哪台机器上;
9)不利于压测。调权不方便,也很难控制流量单独打到指定集群,相同请求不同时间可能会打到不同的机器上。
三、去“有状态”架构规划及过程
1、核心矛盾确定与分析
核心矛盾:接口响应时间与数据存储之间的矛盾。
具体说一下,从用户体验出发,接口响应时间要越短越好。接口响应时间要短,数据的存储就非常关键(获取数据时间:内存 > 分布式缓存 > DB),这里要保证接口尽可能快,就会考虑使用内存。但是放在内存的话,就会出现数据量级太大,普通虚机可能存储不下的情况,就会引出目前”有状态“架构的方式进行存储。
如果能通过优化让单台机器完全缓存下来相关报价数据,那么“有状态”架构就可以理论上废弃掉了,这时需要考虑机器启动时数据拉取及启动后的数据变更处理,也会涉及到数据压缩存储、实际报价落地(本质上说是单日价落地)、实际报价变更的处理,这时就既能满足接口响应时间短的需求,又能保证数据存储没问题。
2、去“有状态”架构方案调研
本质上我们是期望既要保证接口响应时间尽量短,又要保证数据存储合理。我们专门做了相关方案的调研,以及去其他同行业公司去做经验交流,最终我们明确了一些结论和注意事项:
1)做酒店搜索排序时,主要依靠专门的搜索排序服务完成,而不是业务团队来完成,会借助搜索引擎来完成搜索和排序;
2)数据做好压缩存储,实体机是可以存放全量酒店维度的报价数据的;
3)如果使用实体机做全量数据缓存,需要处理好启动时全量数据的拉取,以及启动之后增量变更数据的同步;
4)需要考虑大内存机器 FGC 时间长的问题;
5)国内酒店报价都是按天给出的,多日价很少,可以忽略(这一点对数据存储特别关键)。
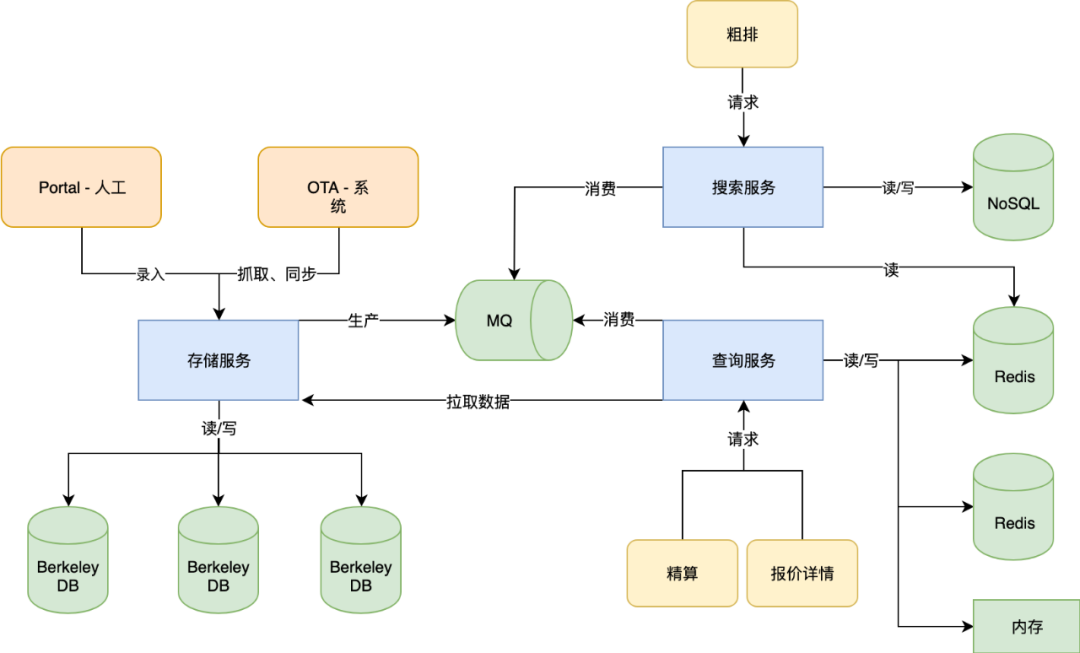
下图是一个典型的同行业公司的报价业务整体架构设计:
1)存储服务:接受来自 portal 管理台人工录入和同步 ota 系统相关数据,将其保存到 DB 中,并广播变更信息;
2)搜索服务:消费相关消息,写入 nosql 中,提供列表页粗排;
3)查询服务:消费相关消息,写入 redis 和内存中,提供列表页精算及详情页报价。
3、去“有状态”架构方案确定
在做了大量的调研和探讨后,我们制定了最终的架构调整方案。方案的核心是去掉 Sort 接口,【粗排】相关字段通过拉取及消息变更放到上游的搜索排序系统里,需要准确的字段借助 Render 接口【精算】来保证。这样,Sort 接口的“有状态”架构设计及复杂的路由层逻辑就都可以去掉了。
最终的架构形态如下图所示:
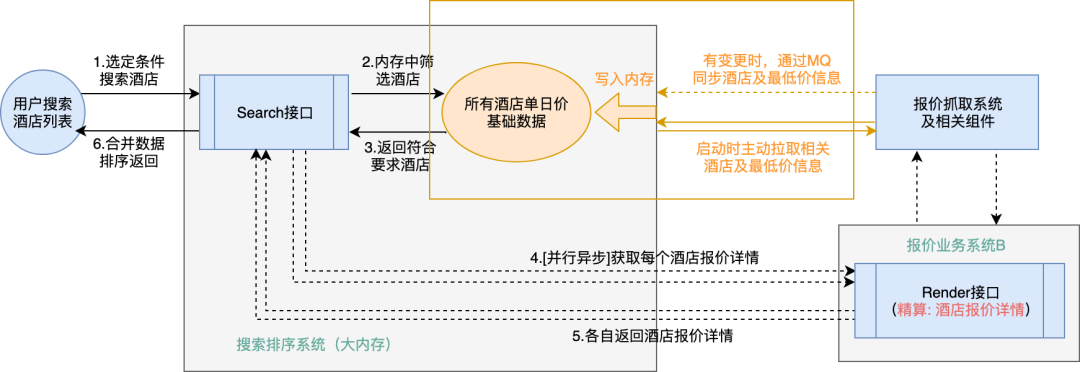
为了完成上图中橙色部分的数据处理和逻辑调整,我们复用了之前酒店分销业务已经落地的报价数据,通过增加处理变价消息等手段,将相关数据存储到相关的 Redis 里去适配本次架构调整,并且将报价数据以消息的方式同步到上游搜索排序系统。搜索排序相关的服务器在启动时主动拉取相关数据到内存中,并且处理相关的变化消息来保证内存中数据是最新的。这里实际调整很大,涉及的逻辑也比较复杂,具体可参考下图:
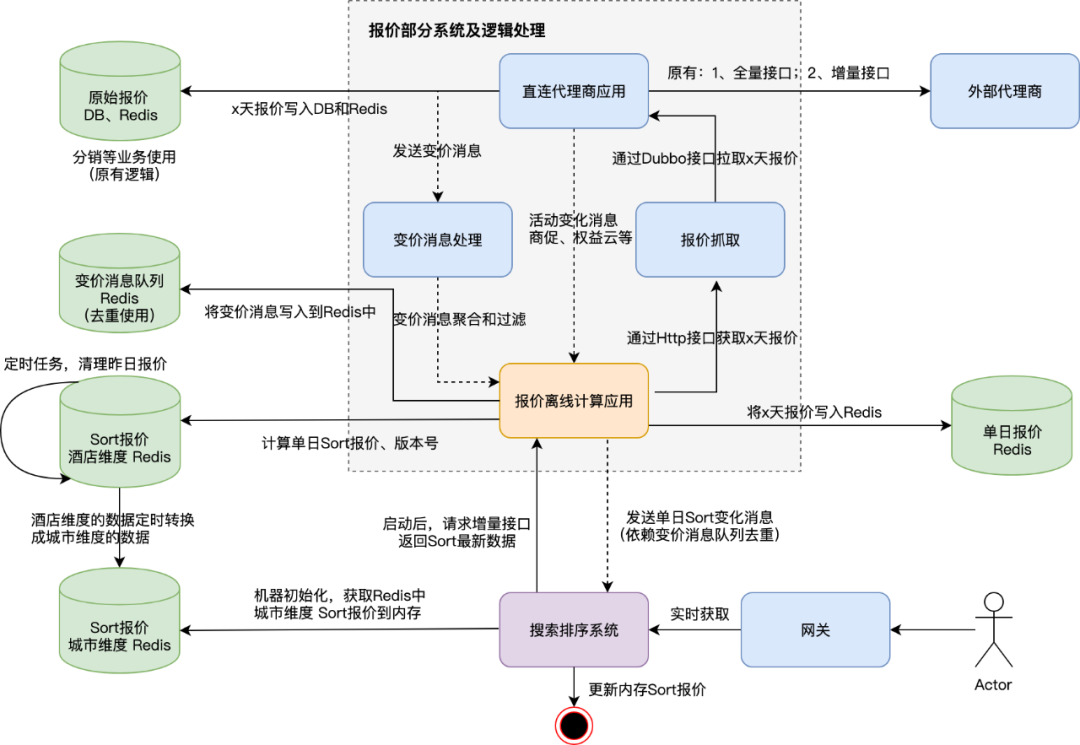
4、实际落地规划与风险控制
1)报价侧调整底层存储,接收分销业务已有的单日价变更消息(本次新增),存储相关数据到 Redis 中;
2)报价侧获取单日价的变化,去重后通知给搜索排序系统;
3)搜索排序系统处理通知,把数据放入内存(这是在确认了实际报价数据能在内存中全放下才确定放到大内存里的);
4)搜索排序系统将原 Sort 请求调整为查本地内存,不再调用 Sort 接口,逐渐放量验证,关注数据的覆盖程度、准确性、整个流程涉及应用的性能;
5)不断的优化请求处理,直至【粗排】完全查搜索排序系统本地内存;
6)原有 Sort 接口在最终全部切换前保持不动,作为实际切换出问题时的整体兜底策略;
7)搜索排序系统完成【粗排】全量查本地内存数据后,原 Sort 接口走下线流程。
四、预期收益
本次调整完成之后,Sort 接口移除,路由层的配置移除,原有 Sort 接口所在应用部署的将近 340 台机器几乎全部下线回收(可能会留 2-4 台处理剩余的非核心请求,QPS 很低),而上游的搜索排序系统由于本身内存放得下,不需要额外增加机器,同时也能更合理的使用大内存服务器的内存优势。当然,这些调整会增加对分布式缓存 Redis、消息队列的使用,这部分资源成本的消耗可在 Sort 接口下线后,通过回收之前链路占用的资源来抵消。
总结一下:
1、酒店搜索排序服务可用性增强:去掉了对 Sort 接口的依赖;
2、酒店搜索排序流程总体时间缩短,用户体验得到提升:使用内存已有数据代替并发请求 Sort 接口获取数据;
3、节省 Java 应用 300+台线上虚拟机:本质上是 Sort 接口占用的机器几乎可以全部节省下来了;
4、酒店整体架构趋于完善、统一,系统边界清晰:搜索排序团队负责筛选出酒店,报价业务团队则负责完成对实际酒店报价的精算;
5、开发人员日常运维成本降低:减少一个重型 P1 系统的日常运维,查问题效率可以得到提升;
6、OPS 运维压力减轻:Sort 接口路由层复杂的配置可以直接干掉。
五、未来规划
去“有状态”架构的事情我们还会持续去做,Sort 接口的“有状态”架构设计被优化掉以后,配合完成“有状态”架构的还有一个完整的回路,之后可以继续沿着数据写入方向,倒序将整个回路里的“有状态”设计优化掉。这些整体上也符合“降成本”的方向。
除了去“有状态”的优化方向外,我们还会继续考虑对整体架构进行合理化和简单化。报价业务相对复杂,只有架构做简单和合理了,才能在实际中完成我们期望的“工作提效”和“降成本”。
作者介绍:
郑吉敏,2019 年 8 月加入国内酒店报价中心团队,主要负责报价相关系统开发及架构优化。对高并发高可用有浓厚兴趣,有日订单千万分布式系统高可用建设经验。喜欢钻研算法,acmicpc 程序设计大赛两次进入亚洲区预选赛。曾在 Qunar 首届 Hackathon 大赛中获得一等奖。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论