

本文从理想化的循环缓冲区基本概念开始讲解,之后逐一列举实际应用中的种种约束,最后描述在保持数据连续性的情况下,两种版本的无锁环形缓冲区设计和实现。
本文描述了关于无锁环形缓冲区两种版本的设计和实现,分别来自于苏黎世联邦理工学院博士生 Andrea Lattuada 和 Ferrous Systems 公司的 James Munns,此类缓冲区可应用于跨线程通信且性能较好。如果你觉得这一连串形容词看起来有点吓人,别担心,我们会从最基本的概念开始解释。
如果你对“安全第一”的并发机制、系统编程和编写高效系统软件的各类酷炫方法抱有浓厚兴趣,本文对你再适合不过。如果您从未编写过线程安全的数据结构,那么本文或许能为你提供一个很好的入门解读!
循环缓冲区
BipBuffer是一个双向的循环缓冲区,它总是支持写入一个连续的数据块,而不是在跨越缓冲区边界时将写操作分成两个块。
循环缓冲区是线程间或线程内异步通信的一种常见基本概念。让我们先从一个非常抽象、理想化的循环缓冲区接口开始讲解,之后逐一列举实际应用中的种种约束,最后描述我们针对 BipBuffer 的设计和实现。
理想化的无限缓冲区
在理想情况下,写入器(数据生产者)和读取器(数据消费者)在通信过程中,能够访问相同的、连续的、并且是无限的数组。写入器和读取器各自保存一个书签,分别指向数组中其写和读的位置,即与之对齐的“写”和“读”指针开始进行操作。
当写入器想要发送数据时,它会将数据追加到“写”指针后面的位置,之后将指针移动到新写数据块的末尾。而读取器在空闲时异步地检查“写”指针。当朝向指针移动方向,“写”指针比“读”指针位置更靠前时,读写器可以对已有数据进行读取操作。完成之后,读写器将“读”指针向前移动,以跟踪记录已经处理至缓冲区的哪一部分。

读取器永远不会试图读取超过“写”指针位置的数据,因为不能保证那里有有效的数据,即写入器在那里写入了东西。这也意味着“读”指针永远不能超过“写”指针。目前为止,我们假设这个理想内存系统总是连贯一致的,也就是说一旦执行了写操作,数据可以立即地、顺序地进行显示。
有界的循环缓冲区
而现实中计算机并没有神奇的无限缓冲区。我们必须分配有限的内存空间,以供写入器和读取器之间进行或许无限的通信。在循环缓冲区中,“写”指针可以在抵达缓冲区末尾时跨越缓冲区的边界回绕到缓冲区的开始位置。
当“写”指针接近缓冲区末尾并且又有新数据输入进来时,会将写操作分成两个数据块:一个写入缓冲区末尾剩余的空间,另一个将剩下的数据写入缓冲区开头。请注意,如果此时“读”指针位置接近缓冲区开头,那么这个写入操作可能会破坏尚未被读取器处理的数据。由于这个原因,“写”指针在被回绕后不允许超过“读”指针。
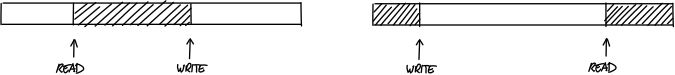
这样下来,可能会得到两种内存配置情况:
“写”指针在前面,“读”指针在后面,即在指针移动方向上,“写”指针超前于“读”指针,已写入但未被读取器处理的有效数据位于“读”指针和"写"指针之间的缓冲区内;
“读”指针在前面,“写”指针在后面,即在指针移动方向上,“读”指针超前于“写”指针,有效数据开始于“读”指针,结束于缓冲区末尾,并回绕到缓冲区开头直至"写"指针位置。
请注意,在第二种情况下不允许“写”指针和“读”指针位置重合,因为这会引发歧义:虽然原则上“读”指针可以赶上“写”指针的位置,但是这里规定在回绕之后,“写”指针位置必须落后于“读”指针一步,以表明此刻处于上述内存配置情况 2 而不是情况 1。
在循环缓冲区中,不断地从内存配置情况 1 进行到内存配置情况 2,又从 2 再回到 1,如此循环往复,当“读”指针到达缓冲区的末尾时,也回绕到缓冲区开头继续进行读取。
以保持数据连续性的方式进行读/写操作
以上设计看上去挺好,但是,如果在写入缓冲区时有一些数据块需要在内存空间中保持连续性,那又该怎么处理呢?比如下面这个例子,需要写入一条新消息,但“写”指针之后的剩余缓冲区空间已经不足以容纳它了。
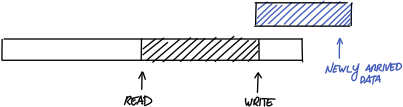
不管出于什么原因,假设这个写操作不允许把数据块分成两截,这时就会遇到困境。也许我们可以等待“读”指针向前移动,并将新数据放在缓冲区开头的一整块内存中?事实上,这样是可行的。但当心!这里要特别小心!
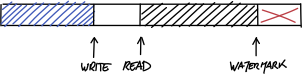
这里其实破坏了前面内存配置情况 2 中的属性:因为“读”指针和缓冲区末尾之间的内存其中有一段不包含任何有效数据。如果我们不加以任何处理,读取器将继续依次读取数据,不断向前移动“读”指针,而忽略这样一个事实:在某个时候,它将读取缓冲区中不包含任何有效信息的部分。
硬件相关插曲
之前我们问:如果在写入缓冲区时有一些数据块需要在内存空间中保持连续,该怎么处理呢?
但是,什么时候有以连续的方式读取或写入数据的实际需求呢?
DMA——直接存储器访问
在微控制器嵌入式系统中,通常使用单核 CPU。虽然没有多核 CPU,但这样的系统通常有一组内存映射外围设备。这些外围设备充当了特定行为的硬件加速器,例如从串口发送或接收数据。
为了尽量减少在 CPU 控制下将数据从一个位置复制到另一个位置所消耗的时间,可以将这些外围设备配置为完全自动地执行操作,使数据流从 CPU 上的一段内存中流入或流出。这种硬件直接读写内存的操作称为 DMA,或直接存储器访问。
这样 CPU 就不需要每次读取或写入一个字节到串口,而是可以直接让串口设备打开传输,当传输完成时,再一次性地处理一大块数据。这让 CPU 等待时间变得更少,通常而言是处理数据更有效的方法。
DMA 被称为 DMA 事务的一个典型用法,其流程描述如下:
CPU 分配 N 个字节的内存用于 DMA
CPU 指示外围设备,如串口,接收 N 个字节的数据,并将这些字节放至步骤 1 中分配的内存空间
一旦配置了外围设备,CPU 将继续执行其他操作,并且串口在接收到数据时开始将数据填充到内存缓冲区
当串口接收了 N 个字节的数据请求后,通知 CPU,并停止接收数据
CPU 现在可以处理所有 N 字节的请求,如果需要,从步骤 1 重复整个过程
虽然我们通常在大多数微控制器系统中只有单核 CPU,但是我们可以把这些执行 DMA 访问的操作视为设备各自的线程。它们能够独立于主 CPU 的操作,并根据自己的需要读写内存。在这些微控制器系统中,可以有数十或数百个这样的硬件操作,而且所有这些操作都是并行运行的!
无堆栈操作
在上面 DMA 事务流程的第 1 步中,提及了分配 N 个字节的内存。在非嵌入式系统上,这通常是通过在堆上分配空间来实现的,例如在 Rust 语言里使用 box,在 C 语言中使用 malloc()。在轻量级或实时性强的嵌入式系统中,通常不使用堆。取而代之的方式是,所有内存必须以静态方式分配,或者通过使用堆栈来分配。
在这些系统中,可以使用诸如循环缓冲区之类的数据结构来绕开这些限制。先为使用预留一块固定的内存空间,并在该固定空间的最大区域内使用动态数据量来模拟动态内存区域。
遗憾的是,DMA 事务并未引入循环缓冲区的概念。一般的 DMA 操作中仅仅知晓指向内存区域起始位置的指针,以及从起始指针应该使用多少字节。这意味着在数据区域可以回绕的普通循环缓冲区并不能直接用于 DMA 传输。
为何 DMA 如此重要?
对于使用 DMA 的操作,字节传输的速度通常比 CPU 本身的操作慢很多个数量级。对于 32 位 ARM CPU,从 RAM 复制 4 个字节只需要一个 CPU 周期。而在 64MHz 的 CPU 中,复制 4 个字节仅仅需要 15.6 纳秒。
一个典型的串口速率配置是“115200 8N1”,意思是以 115200 波特传输,即每秒在线传输 115200 原始比特,无奇偶校验,带一个停止位(stop bit)。这意味着每发送一个数据字节,就会有 8 个数据位、1 个未使用的奇偶校验位和 1 个停止位,用来表示通过网络发送一个字节完毕。
即是说,为了在线接收 4 个数据字节我们将需要 40 比特数据。以每秒 115,200 比特的速度传输,这意味着接收相同的 4 个字节需要 347,220 纳秒,这是我们的 CPU 复制相同数量数据所需时间的 22,222 倍!
但采用这样的传输方式就能让硬件来自行管理简单的发送和接收过程,而不是让 CPU 去白白浪费等待的时间,这就可以让 CPU 要么去处理其他重要任务,要么进入休眠模式,从而节省电能或电池寿命。
从嵌入式系统到数据中心
为数据中心级服务器编写高性能应用程序的人早就意识到,对于他们使用的高等级、耗电量巨大的 CPU 而言,类似的节约也是必要的。
同样的,现代高效的服务器网络栈使用类似 DMA 的技术将此类简单的数据传输工作转移到网卡上,这样就可以将宝贵的 CPU 时间花在运行处理海量数据的应用程序上。
一个分岔路口
回到原始的 BipBuffer,该设计旨在维护两个有效数据出现的“区域”,一个在缓冲区的开头,一个在缓冲区的末尾,这样它就可以追踪记录缓冲区的哪些部分包含有效数据。可以阅读一下 CodeProject 网站上关于的 BipBuffer 的博客文章,了解其工作原理。
这种基于两个区域的设计在单线程环境中可以运行良好,只需要在缓冲区最右边的区域耗尽时交换对两个区域的引用。然而,在没有加互斥锁机制进行显式锁定,写入器和读取器驻留于不同线程的情况下,这还是很棘手的。
我们的用例是两个并发的控制线程之间的通信,要么是两个正在运行的的 OS 线程,要么是嵌入式或设备驱动程序中的一个控制主线程和一个中断处理程序。我们的设计灵感源自 BipBuffer,但在分岔路口上选择了另一个方向走下去。
并发性设计
为了减少写入器、读取器两个线程之间需要发生的协调,一种常见策略是,将每个协调变量(指针)与对它具有独家写访问权的单个线程关联起来。这也简化了并发性设计中的逻辑推理,因为谁负责更改哪个变量总是很清楚。
那么,让我们从一个简单的循环缓冲区开始,它具有原始的”写“指针和”读“指针。唯有写入器能更改”写“指针,而唯有读取器能增加”读“指针。
目前为止一切顺利。每个线程只关心对一个变量的写操作,和对另一个变量的读操作。
数据的“水位线”
现在,让我们重新回头来看写入的数据可能需要保持连续的要求。如果缓冲区末尾没有足够可用的空间,则写入器将回绕到缓冲区开头处并写入整个连续的数据块。
正如我们所看到的,我们需要一种方法来告诉读取器缓冲区的哪个部分包含有效数据,以及为了能够一次写入单个连续数据块而跳过了缓冲区中哪一部分。实际上我们是希望跟踪缓冲区中有效数据最高处的”水位线“,那么何不为写入器回绕到缓冲区开头并在末尾留下空白时写下一个”水位线“指针呢?
回到我们之前设想的理想化的无限缓冲区,看起来应该是这个样子的。只要数据有效区域没有被分割成位于物理缓冲区开头和末尾的两个部分,我们就像以前一样简单地使用”写“指针和”读“指针进行记录即可。另一方面,当有效数据回绕到缓冲区开头时,我们在“无限缓冲区”中人为地留下一个“洞”。”水位线“让我们追踪记录这个“洞”的开始位置,而物理缓冲区的末尾标志着”洞“的结束。
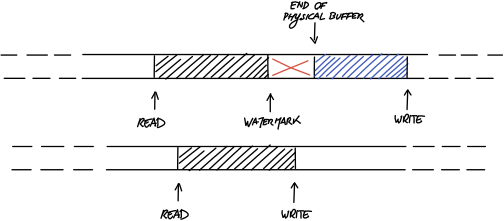
实现
现在我们已经集齐实现非阻塞式缓冲区所需的所有元素了。一开始,“写”指针和“读”指针都对齐物理缓冲区开始位置,而”水位线“指针对齐物理缓冲区末尾位置。

我们使用 AtomicUsize 让两个线程读取和更新指针时兼顾并发性和安全性。写入/发送线程负责“写”指针和“水位线”指针,读取/接收线程负责“读”指针。这点很重要!对于 CPU 的缓存一致性协议来说,处理来自多个线程对同一内存位置的写操作争用冲突要困难得多,而且还会增加延迟和降低吞吐量。并且,如果每个共享指针都由其“所有者”线程负责写入,那么推导这些并发协议的正确性也会变得更容易。
写操作
当长度为 write_len 的新数据到达时,只要在物理缓冲区末尾之前有足够的连续缓冲区空间,写入/发送线程会将“写”指针向前移动,以表示缓冲区内的一个新数据块现在是有效的,可以读取了。
当新数据输入且“写”指针接近缓冲区末尾时,写入/发送线程将”水位线“指针移动到当前位置,然后进行回绕到缓冲区开头,并写入数据。和前述一样,如果“读”指针仍然靠近缓冲区开头,那么这时的写入可能会破坏尚未被读取器处理的数据。由于这个原因,“写”指针不允许在回绕之后超过“读”指针。
您可能已经注意到,当缓冲区末尾有空间时,写入器也会将”水位线“指针随着“写”指针向前推动。我们这样做的原因是我们可能已经把”水位线“指针从上一次回绕移回来,以避免读取器现在将其误解为一个标记,认为缓冲区末尾有一个“洞”。
读操作
这样,我们又得到了两种可能的内存配置情况:
“写”指针在前面,“读”指针在后面,即在指针移动方向上,“写”指针超前于“读”指针,已写入但未被读取器处理的有效数据位于“读”指针和"写"指针之间的缓冲区内;
“读”指针在前面,“写”指针在后面,即在指针移动方向上,“读”指针超前于“写”指针,有效数据开始于“读”指针,结束于”水位线“指针,并回绕到缓冲区开头直至"写"指针位置。

这使得读取/接收线程的逻辑很简单:读取到“写”指针或”水位线“指针,然后相应地更新“读”指针。
关于内存排序的说明
有些人可能已经注意到,以上所有进行加载(load)的调用都不带参数,而要进行存储(store)的调用只带一个参数,即 AtomicBool 类型的新值。当然,这不是有效的代码。真正的函数签名会加入另一个参数:Ordering: Ordering。这将指导 llvm 编译器设置正确的内存栅栏和同步指令,以驱动内置于 CPU 中的缓存一致性和同步机制。
这里安全的做法是始终选择 Ordering::SeqCst,即“顺序的一致性”,它提供了最有力的保障。在 x86 系统上,由于硬件架构设计的原因,除了 Ordering::Relaxed 之外,其他任何选项实质上都等同于 SeqCst。在 ARMv7/v8 系统上,事情变得更加复杂。
我们建议阅读一下你所选用平台的技术文档和 rust 文档中关于内存排序的内容。就本文而言,假定各处都使用了 Ordering::SeqCst。在实际开发中,这通常已足够好,而切换到较弱的 Ordering 选项仅仅是为了压榨出最后一点性能。
在 Andrea 实现的无锁环形缓冲区spsc-bip-buffer代码中,为了提高性能,有些内存排序被配置得更宽松。这样做的缺点是,它可能会引入一些只出现在某些平台(例如 ARM)上的微妙的并发性 bug,因此为了确保一切正常,Andrea 在 x86 和 ARM 上都进行了持续集成测试。
对嵌入式系统的支持
在 James 实现的无锁bbqueue中,为环形缓冲区的静态分配实例提供了方便的接口。队列可以分为生产者和消费者两部分,允许在中断的上下文中使用队列的其中一部分,而在与之通信的非中断(或另外一个中断)的上下文中使用队列的另一部分。
查看英文原文:
https://ferrous-systems.com/blog/lock-free-ring-buffer/
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论 2 条评论