
OpenAI 于 8 月 6 日开源两款大模型,主打部署成本超低和医疗能力最强。仅仅 5 天后,百川智能发布并开源了医疗增强大模型 Baichuan-M2,以更小尺寸模型并实现医疗能力反超。
M2 Model: https://huggingface.co/baichuan-inc/Baichuan-M2-32B
M2 GPTQ-4bit: https://huggingface.co/baichuan-inc/Baichuan-M2-32B-GPTQ-Int4
Huawei Ascend 8bit: https://modelers.cn/models/Baichuan/Baichuan-M2-32B-W8A8
今年 1 月,百川在行业内首发“AI 患者模拟器”,用真实数据构造上万个不同年龄性别症状的 AI 患者,模拟了数百万次诊疗过程,基于该范式开源的 Baichuan-M1,为行业首个医疗增强模型。7 个月后,百川升级患者模拟器并引入模型端到端强化学习,训练的 Baichuan-M2 在 HealthBench 等评测上取得更大突破。
Baichuan-M2 在 HealthBench 上得到 60.1 的高分,以 32B 的较小尺寸不仅反超 OpenAI 最新开源模型 gpt-oss120b(得分 57.6),更是力压 Qwen3-235B、Deepseek R1、Kimi K2 等开源大模型。
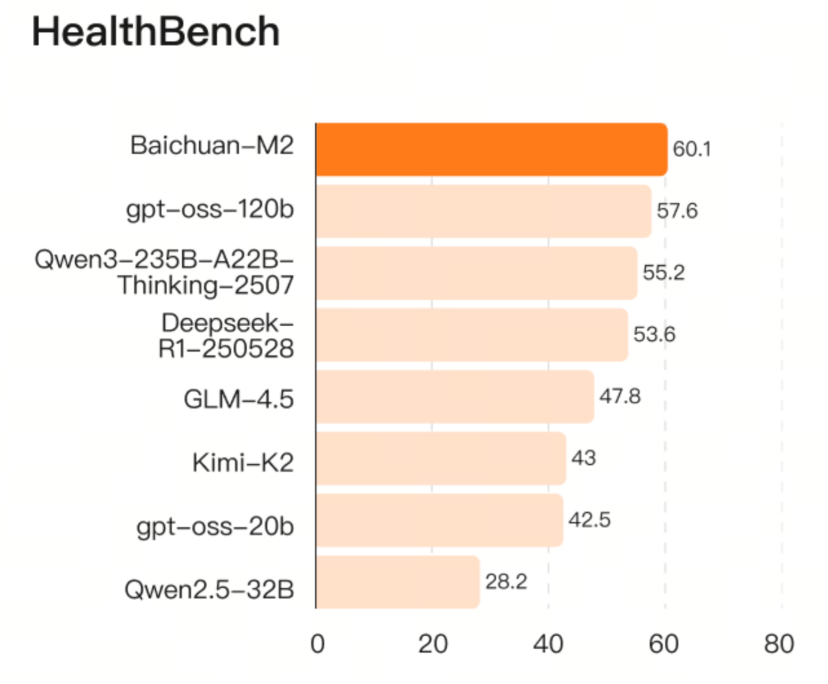
针对医疗领域用户隐私考虑下的模型私有化部署需求,百川智能对 Baichuan-M2 进行了极致轻量化,量化后的模型精度接近无损,可以在 RTX4090 上单卡部署,相比 DeepSeek-R1 H20 双节点部署的方式,成本降低了 57 倍。针对国产主流芯片的开发和适配,多数医疗机构可利用现有硬件条件既可实现快速部署。
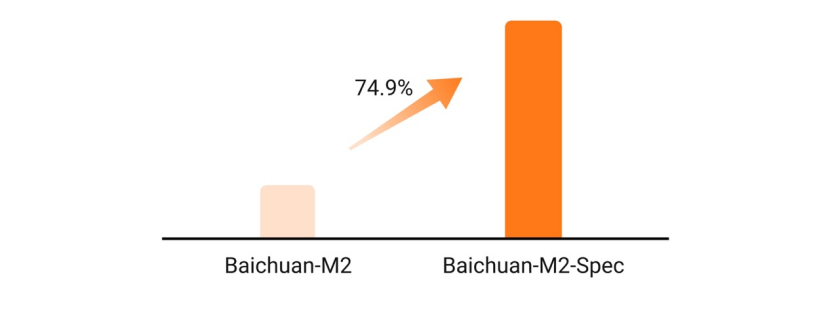
此外,面向急诊、门诊等对于交互速度要求更高的场景,基于 Eagle-3 架构优化的 Baichuan-M2 MTP 版本在单用户场景下实现了 74.9%的 token 速度跃升。
据介绍,头部大模型企业主要用数学和代码数据进行强化学习,百川是首个将医疗数据用作强化学习的中国团队,同时也验证了高质量医疗数据对于模型通用能力的增长具有较高价值。通用能力方面,M2 模型在数学、指令遵循、写作等通用核心性能上不降反升。

值得注意的是,HealthBench 医疗健康评测集是今年 5 月 OpenAI 发布的,研究团队招募了 262 位医生,来自 60 个国家、涉及 26 个医学专科、精通 49 种语言,他们生产了 48562 条评价标准,其中 86%是实例特定标准(针对单个对话由医生撰写),14%是共识标准。OpenAI 从 HealthBench 整体数据中选出 1000 个特别困难的复杂问题作为 Hard 子集,用于验证模型多维度、全景化解决疑难复杂医学问题的能力。
医疗方向越来越受到重视。OpenAI 自 2024 年下半年起将医疗作为模型能力提升的首要方向,投入大量人力、算力和精力。
开源 gpt-oss 系列模型过程中,OpenAI 首次将医疗作为第一重要的评测标准。GPT-5 发布时 OpenAI 特别强调,其是 HealthBench Hard 评测全球唯一超过 32 分的模型,发布时请到现场的唯一使用者是抗癌患者。Baichuan-M2 以 34.7 分成为全球第二款超过 32 分的模型。
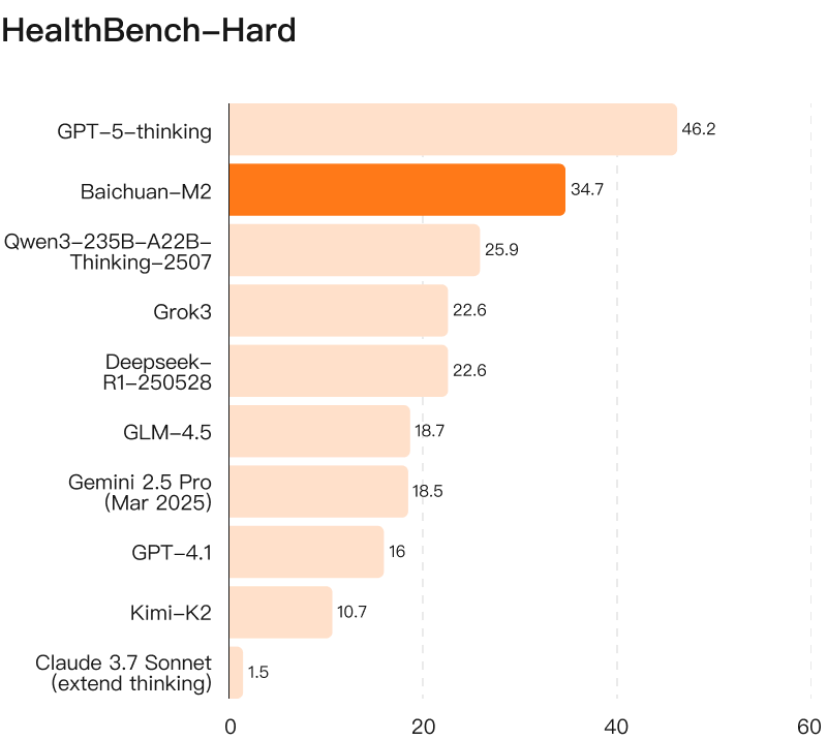
尽管真实医疗场景中还存在大量 HealthBench Hard 评测尚未包含的因素,但至少已经证明在多数医疗场景上的问答质量,GPT-5 和 Baichuan-M2 已经超越资深医生,特别是在知识更新速度和全面性上,可以给人类医生强大支持。相比 GPT-5,Baichuan-M2 免费开源。
AI 患者模拟器“立功”
据介绍,百川技术团队在大型验证系统(Large Verifier System)、端到端强化学习、AI 患者模拟器、多类型医疗数据用于深度推理等 4 个方面的创新探索,是 Baichuan-M2 模型取得飞跃式进步的关键。
过去一年,可验证奖励强化学习(RLVR)方法被头部大模型企业广泛使用,在数学、代码领域显著提升了模型性能。百川技术团队在这一过程中认识到,提高复杂现实问题的可验证性是进一步提升模型性能的关键。由此,他们构建了大型验证系统,在通用验证器之外还设计了一套全面的医学验证系统。
如果将未经过医疗强化学习的大模型比作一位医学实习生,这个系统则像一个要求极高、异常挑剔的医疗专家。它会从医疗正确性、完备性、安全性以及对患者的友好性等多个维度,细致地评估模型的输出,指出其不足并引导模型改正,使其思维方式更贴近专业医生。
在这个强大验证系统的基础上,团队采用多阶段强化学习策略(Multi- Stage RL),将复杂的强化学习任务分解为几个易于管理的、分层的训练阶段,逐步引导模型能力演变。
人类医生在听取患者描述病情时,很容易分辨患者描述中的逻辑漏洞、从含混不清的表达中辨别出真实病因。现实中患者几乎无法全面准确表达自己的症状,仅基于静态的病例、指南等医疗数据训练,模型无法掌握人类医生的这一能力。为了突破这一瓶颈,百川技术团队升级迭代了今年初首创的 AI 患者模拟器。这个模型器是使用真实病例构建的 AI 系统,能够模拟千差万别的患者、症状、表达,特别是包含错误噪声的表达,最大程度还原了真实医疗场景。
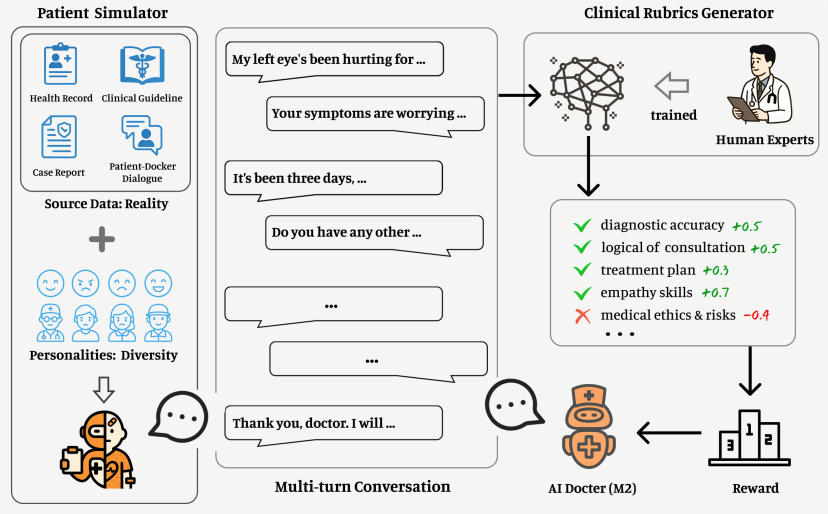
在强化学习的多轮对话中,AI 患者与 AI 医生快速生成数百万条贴近真实的交互信息,验证器充当裁判实时打分评估,根据打分结果模型策略动态优化,形成了一个具有规模化可监督信号的训练闭环,让训练过程与效果如“飞轮”般效率倍增。
百川智能还构建了一个以天为频率更新的权威医学数据库,涵盖病例、论文、文献、指南、药学、生物学、合成数据等。为防止综合能力退化,采用医学数据、通用数据、数学推理数据 2:2:1 的比例,并引入领域自我约束训练机制,确保模型是一个具有通识、推理等综合能力的高水平医生,避免成为只会医学知识考试的高分低能者。
更多技术创新点详见:https://www.baichuan-ai.com/blog/baichuan-M2
更符合中国临床诊疗场景
医疗大模型能否将全球医学知识、医学证据转化为符合本地优势特长的临床决策,也是为医生和患者提供切实服务能力的关键,百川从中国医学指南对齐、医疗政策适配和患者需求洞察等多个维度进行了深度优化。
官方表示,在中国临床诊疗场景的问题评测中,对比 gpt 系列模型,Baichuan-M2 展现出更明显的可用性优势。
据悉,中外患者人群特点不同、医疗服务资源与优势有所差异。例如,对于肝细胞肝癌,中国以乙肝相关肝癌为主,西方更多是酒精或丙肝相关患者,不同类型患者的的手术风险不同;加上中国外科手术经验丰富、手术期管理成熟,因此,在同一疾病遇到多种治疗方案时,中西方指南对于优选哪种治疗方案存在差异。
在一个具体的真实案例中,针对 CNLC IIa 期(BCLC B 期)的肝细胞肝癌患者,Baichuan-M2 首推在具备手术条件的情况下进行解剖性肝右叶切除手术(或根据肿瘤具体位置,可考虑扩大右半肝切除、右三叶切除等),目标是 R0 切除。在国家卫健委最新发布的《原发性肝癌诊疗指南》(2024 版)中,肝切除术是潜在根治性治疗,可提供最佳的长期生存获益,Baichuan-M2 严格遵循这一方案。
同一病症 gpt-oss-120b 则建议首选经动脉化疗栓塞术(TACE),理由是符合 BCLCB 期治疗指南。

临床医学专家认为,类似的情况还有很多。仅就这个案例来说,手术切除或 TACE 都是可选方案,只是中西方指南不同,不是医学上的高下之分,而是基于本地患者特点、医疗资源与当前医学发展水平权衡之下的最优解。




